Downloaded 15 times



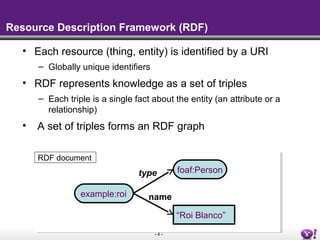
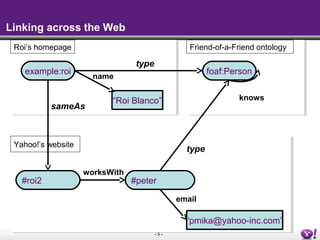


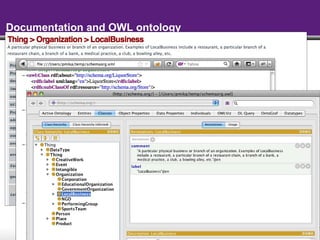







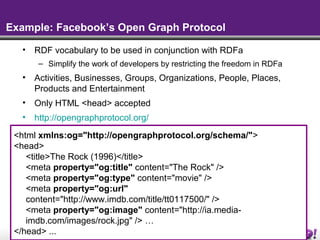

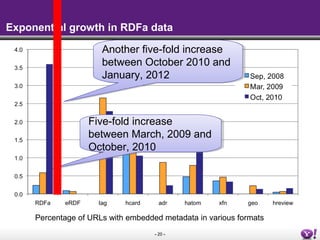





The document discusses the Semantic Web and linked data. It describes the Semantic Web as a way to publish information that is easier for machines to process by adding meaning through common formats and shared schemas. It outlines key Semantic Web standards like RDF, OWL, and SPARQL. The document also discusses how data is published on the Semantic Web through linked data, metadata in HTML, SPARQL endpoints, and feeds. It provides examples of publishing and consuming RDF data on the Semantic Web.











































