Downloaded 467 times






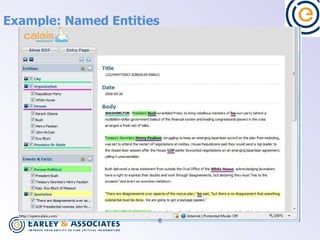
![Key concept: Ontology ontology n. A set of relationships between entities. Often these are in subject-predicate-object [triple] format. Often ontologies relate entities that exist in multiple taxonomies . Example : A food chain is a set of relationships (predator/prey) between entities (animals, plants) that exist in different taxonomies (kingdoms). The relationships are triples: Rodents eat seeds of grasses. Fox eats rodents. Kangaroo rat is a rodent. Rye is a grass. Etc.](https://image.slidesharecdn.com/duserspauldocumentstcgearleyimplementingsemanticsearch-090412145744-phpapp01/85/Implementing-Semantic-Search-7-320.jpg)
![How does semantic search work? Assess meaning of documents Identify named entities and relationships (triples) OR Categorize documents to taxonomies OR Score each document with a “signature” or “graph” “ Tag” documents for meaning (categories, entities, triples, semantic signatures, graphs, etc.) Index the documents Assess meaning of search terms Match documents to search terms via common meaning Meaning [search term] Meaning Meaning](https://image.slidesharecdn.com/duserspauldocumentstcgearleyimplementingsemanticsearch-090412145744-phpapp01/85/Implementing-Semantic-Search-8-320.jpg)


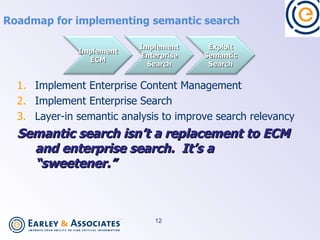
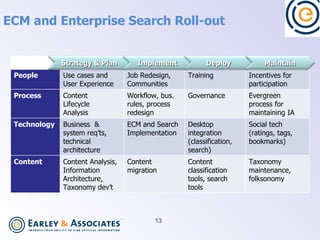

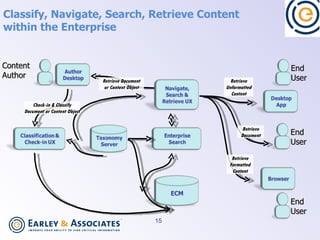

















Semantic search uses language processing to analyze the meaning of content and search queries to return more relevant results. It involves classifying content using taxonomies, identifying named entities, extracting relationships between entities, and matching these based on meaning. Implementing semantic search requires preparing content through classification, metadata, and information architecture, as well as technologies for semantic tagging, entity extraction, triple stores, and integrating these capabilities with existing search and content management systems.











































































