Downloaded 22 times


































![The End Credits to many people from Yahoo! around the world Contact me at [email_address]](https://image.slidesharecdn.com/semanticsearch-webdirections-sydney-111023063519-phpapp01/75/Making-the-Web-searchable-59-2048.jpg)

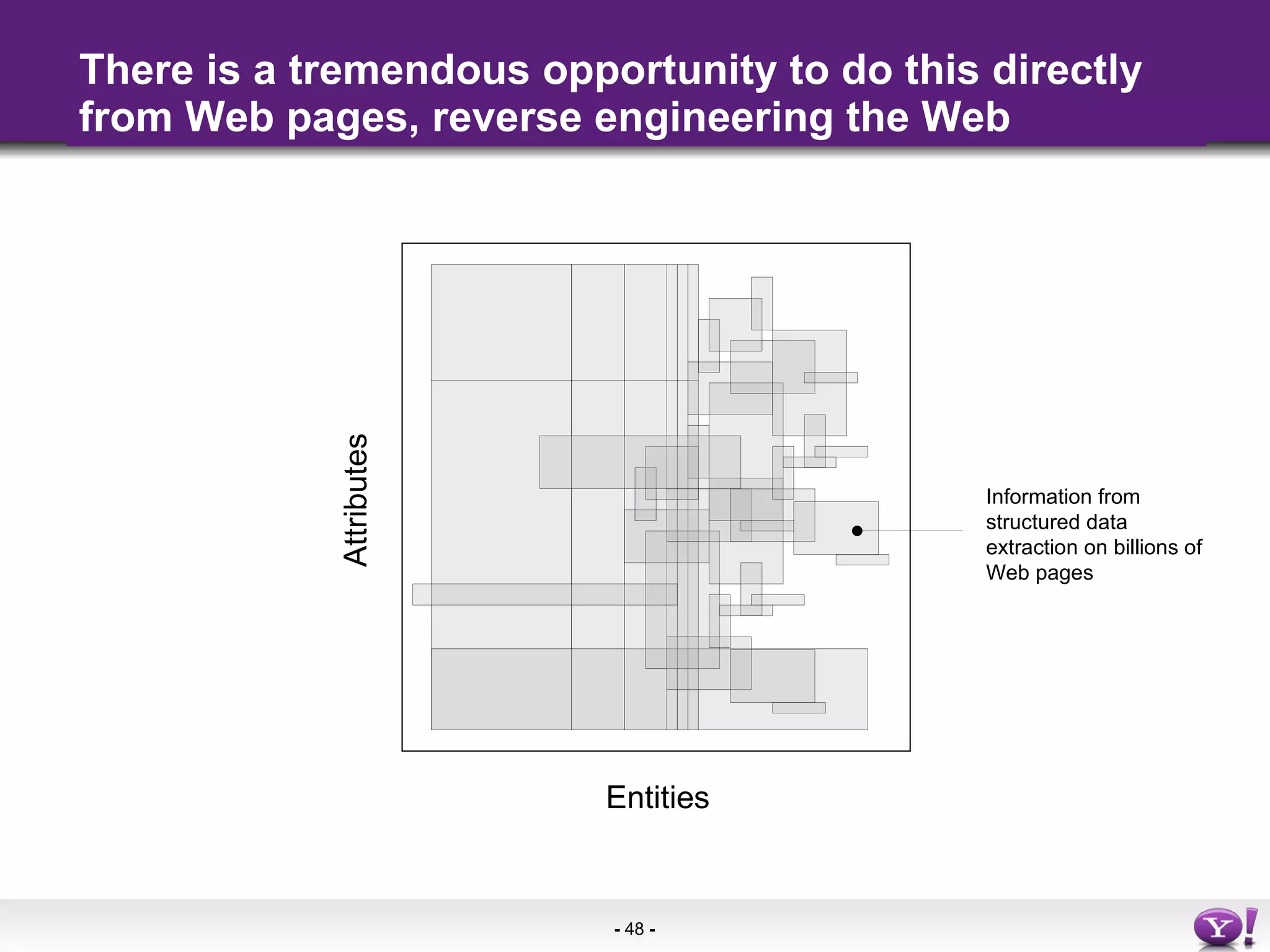
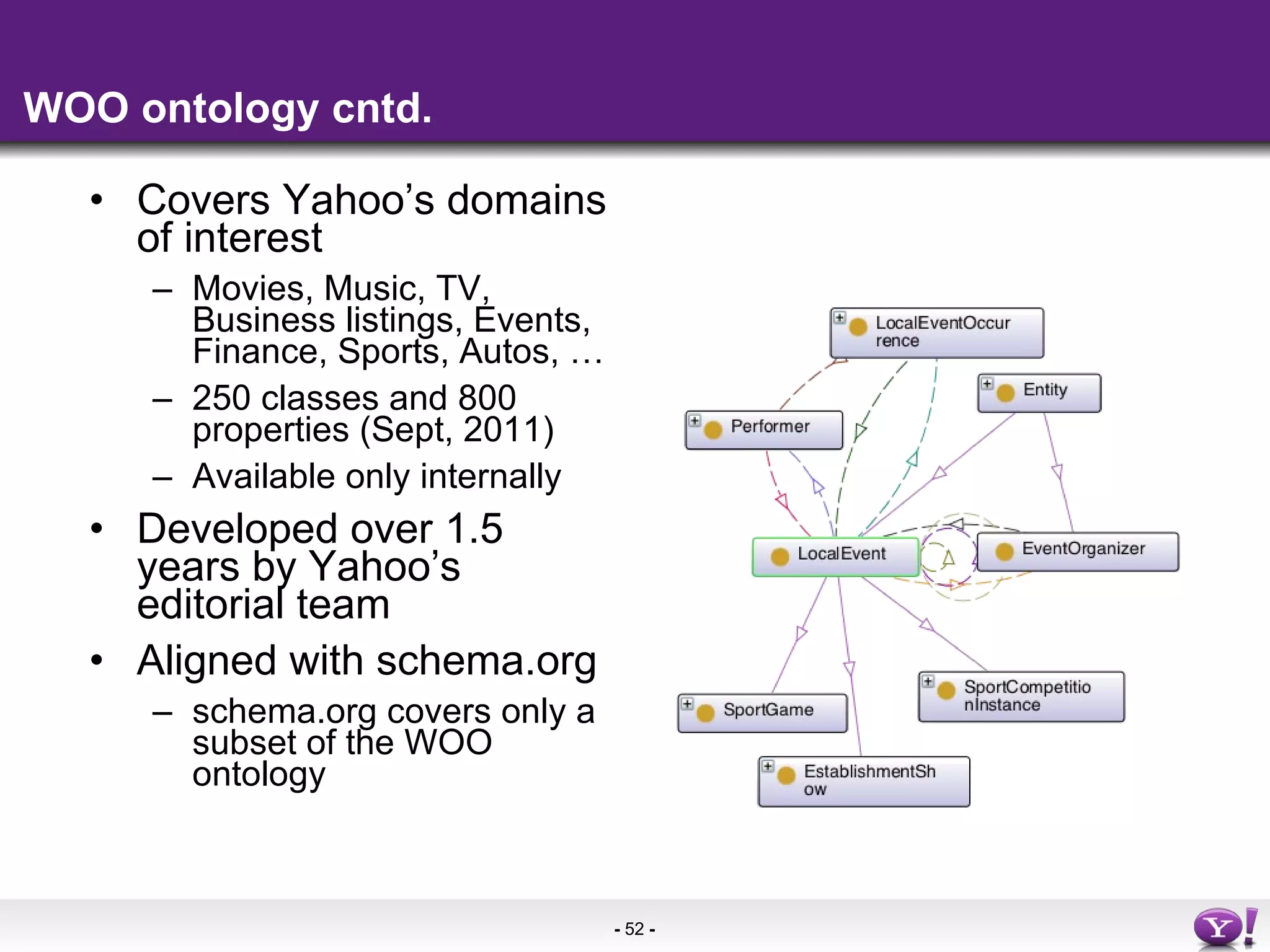
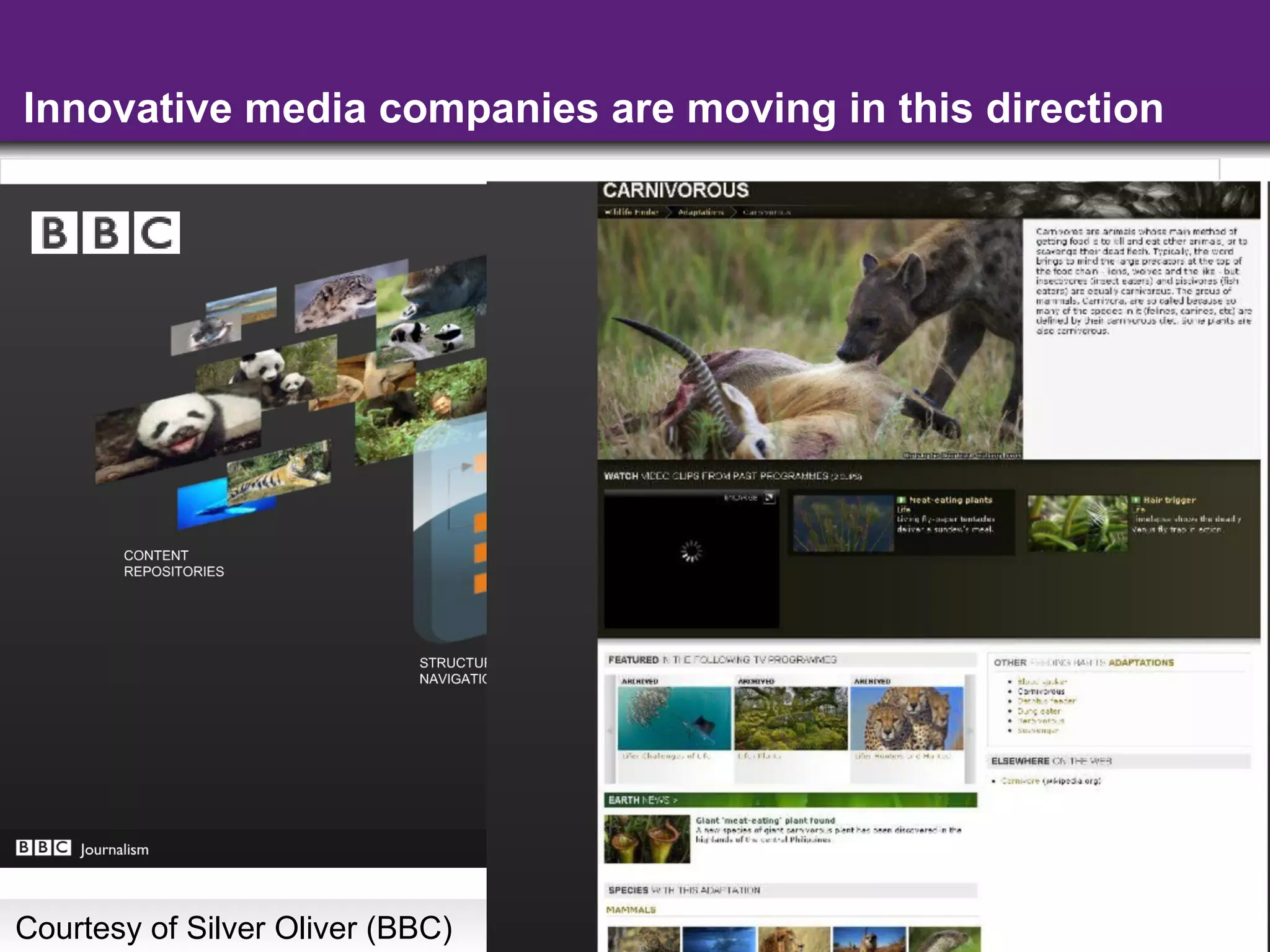
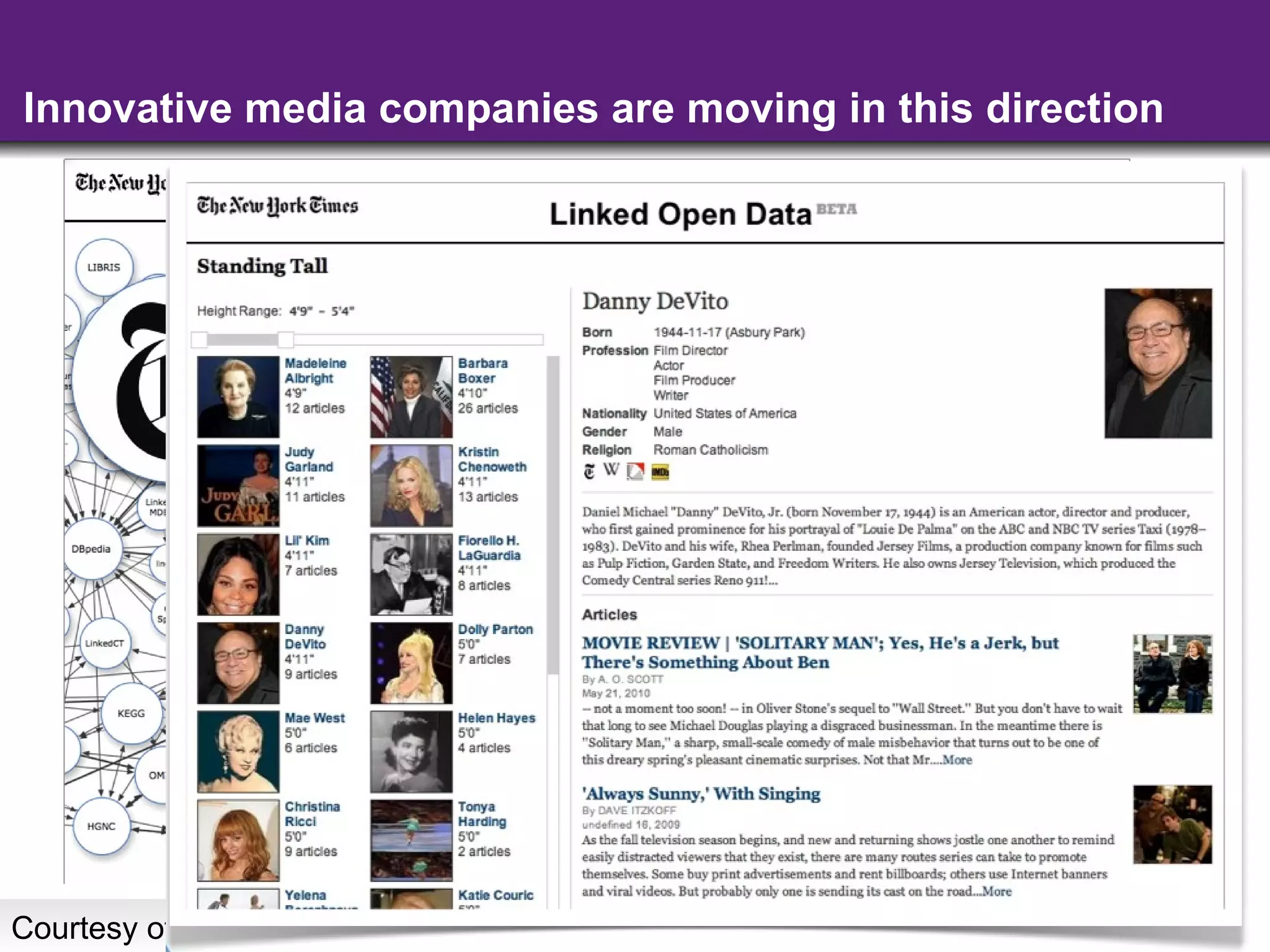
The document summarizes semantic technologies that can be used to make web search and content more intelligent. It discusses how search and online media are converging, and how semantic markup like RDFa, microformats, and microdata can be used to embed structured data in web pages. This allows search engines and other applications to better understand page content and provide more sophisticated features like entity search, personalized results, and content aggregation.












































































