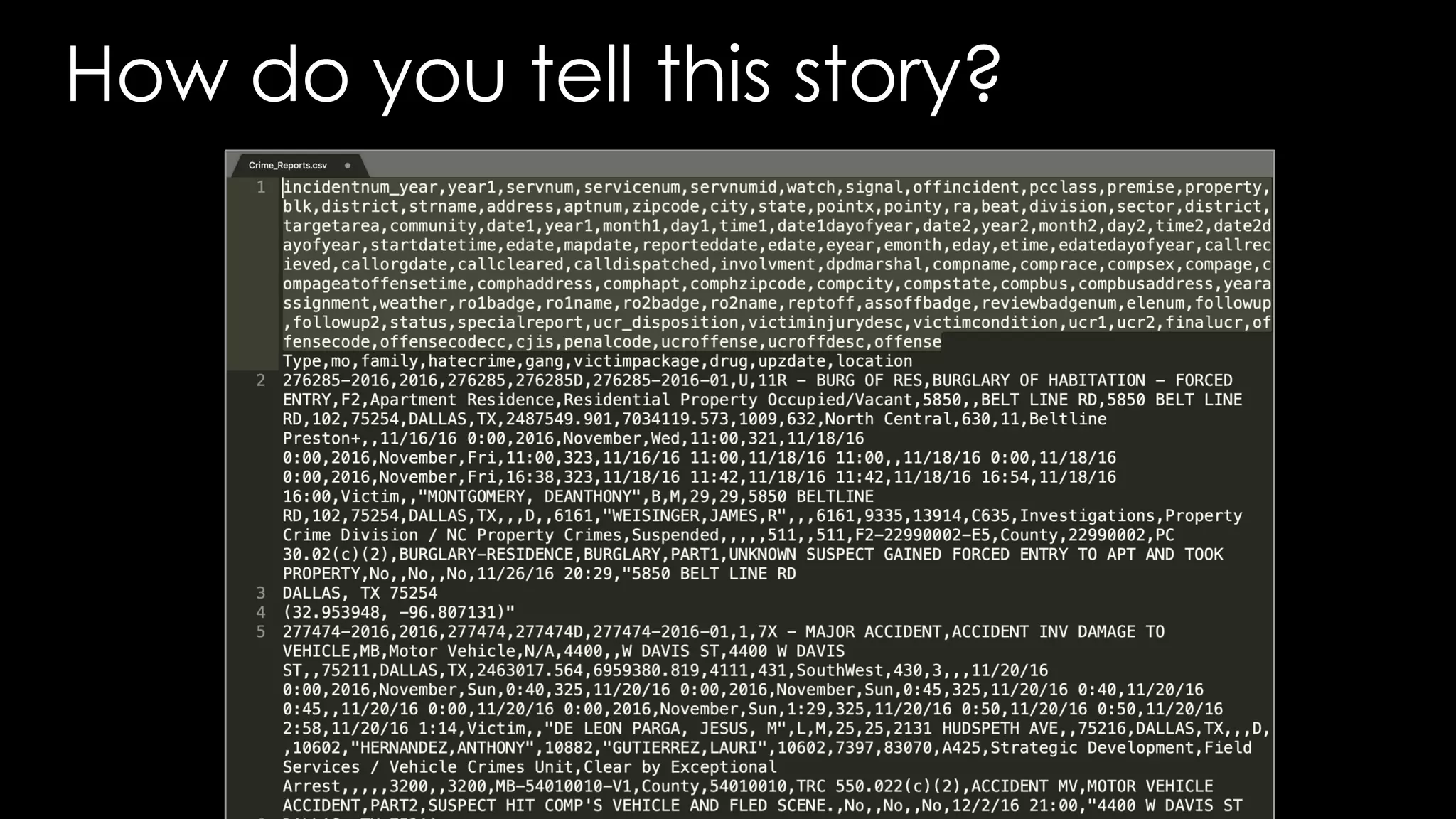
Download as PDF, PPTX











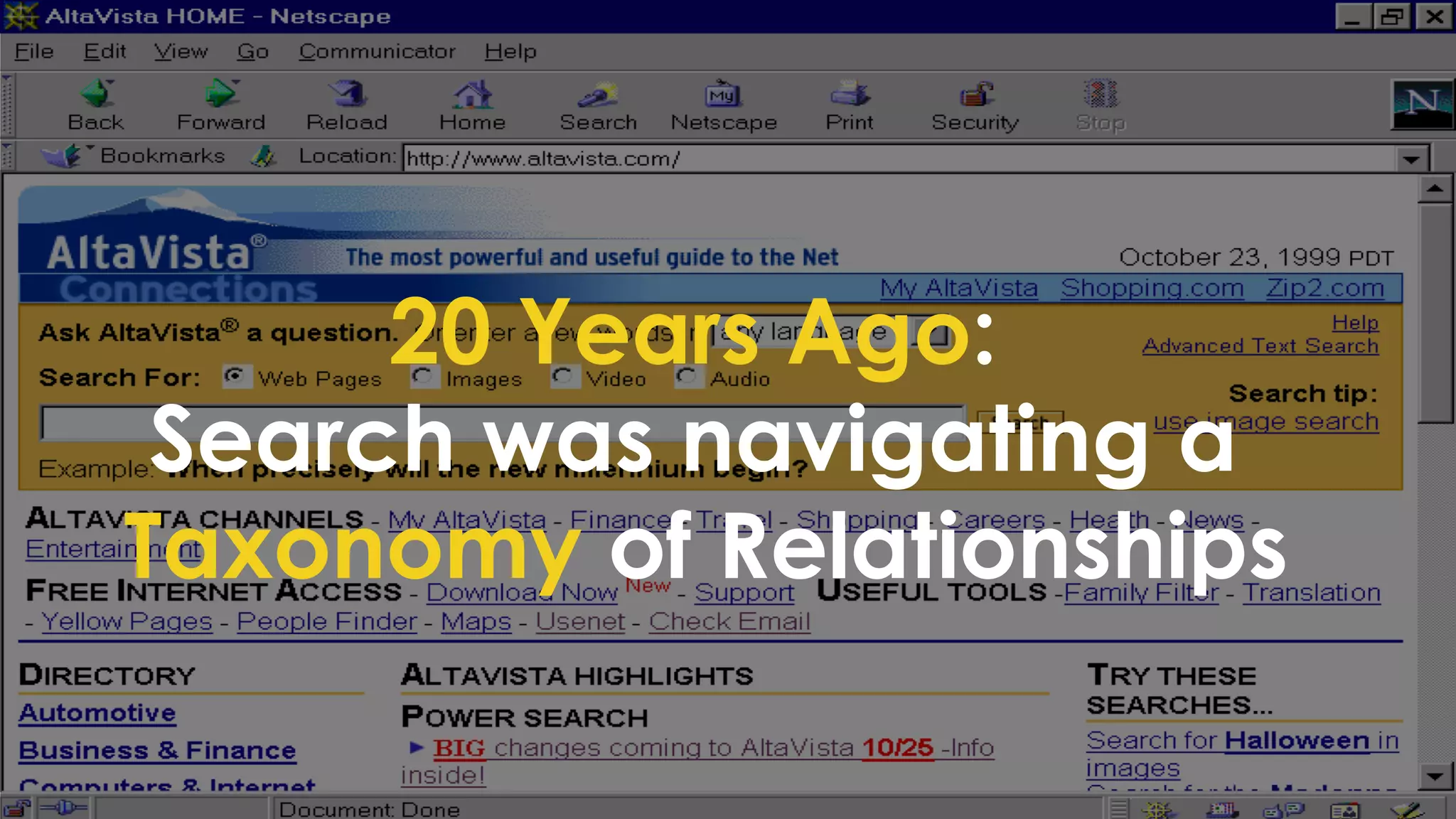










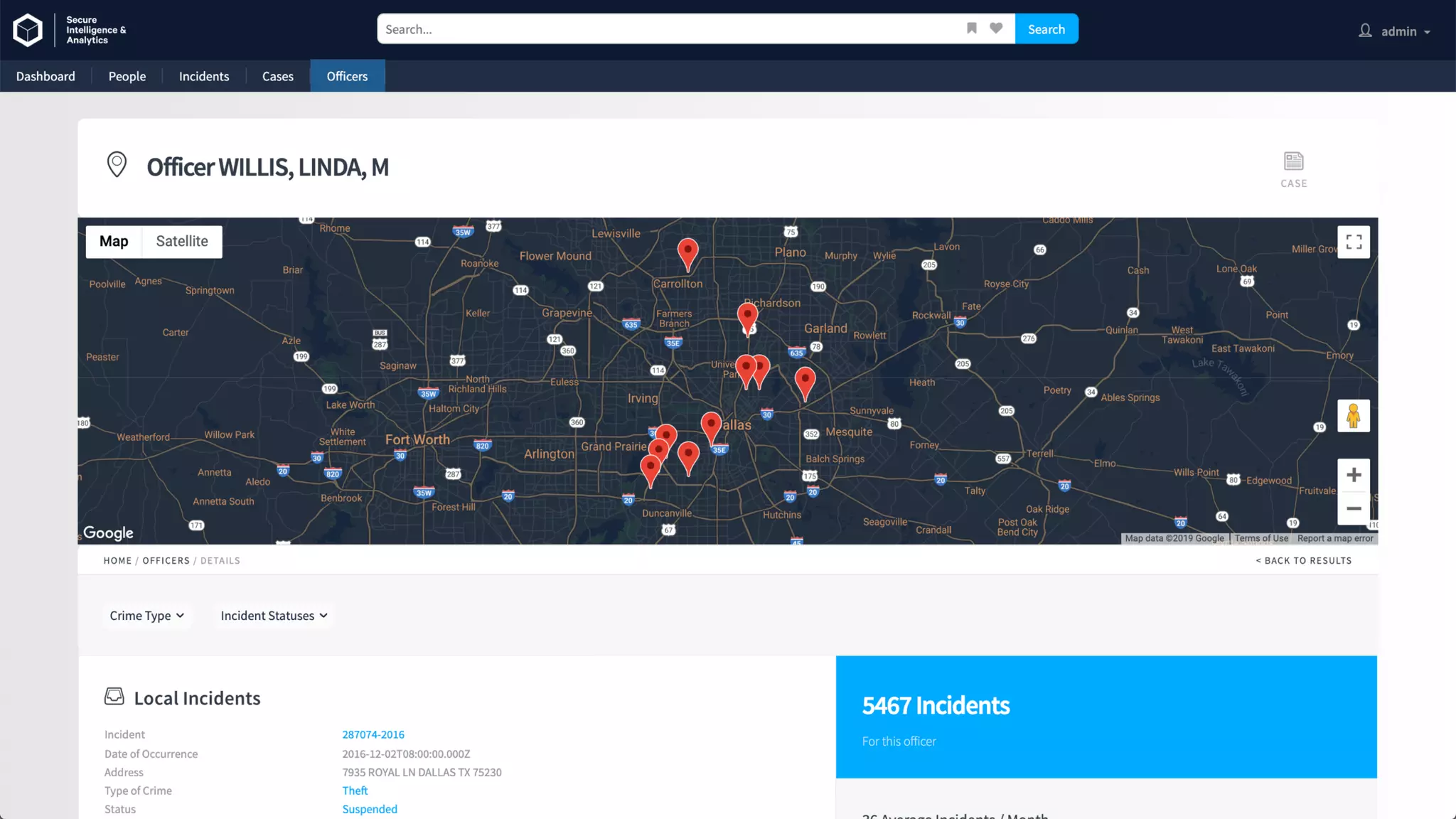



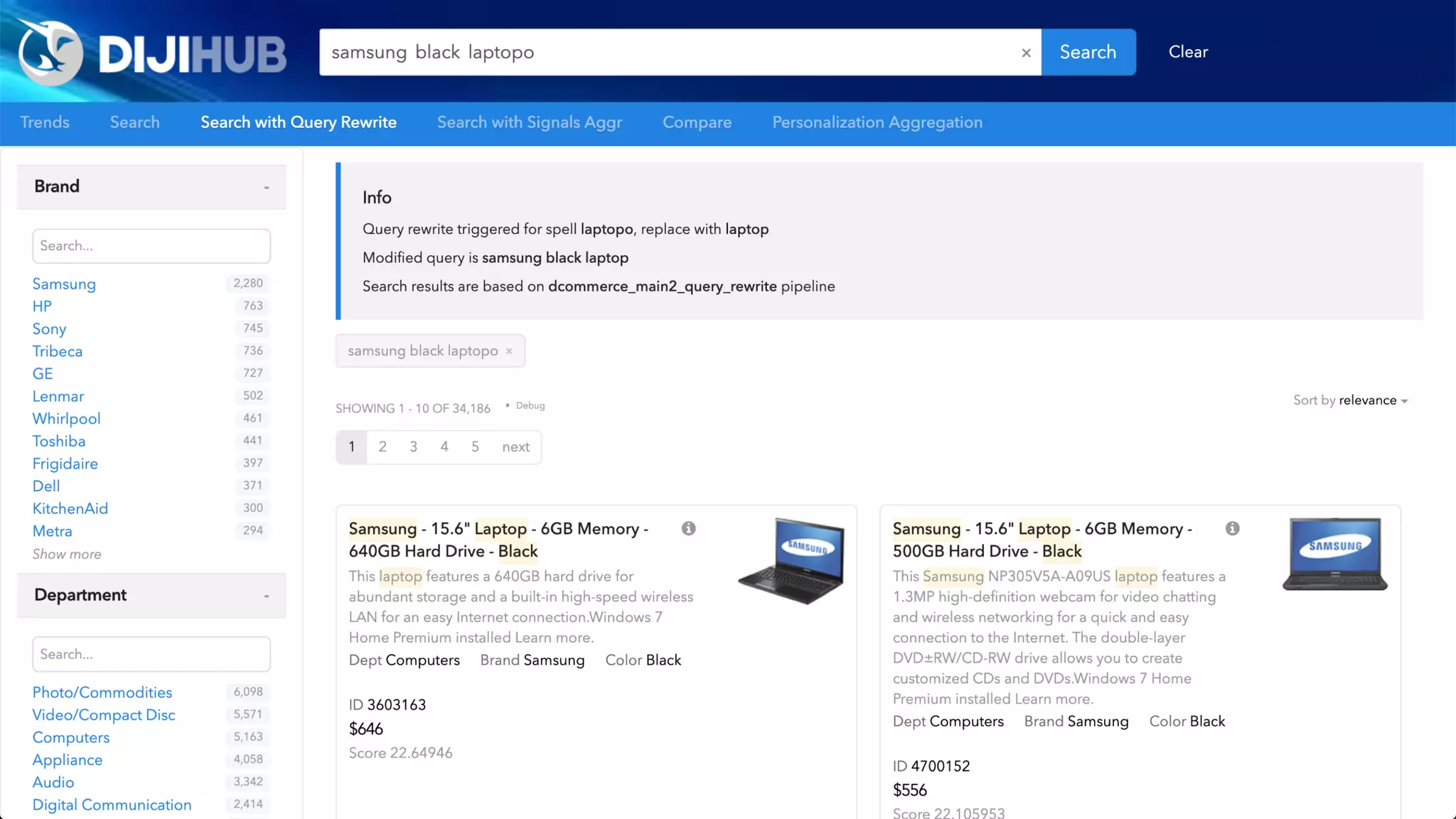
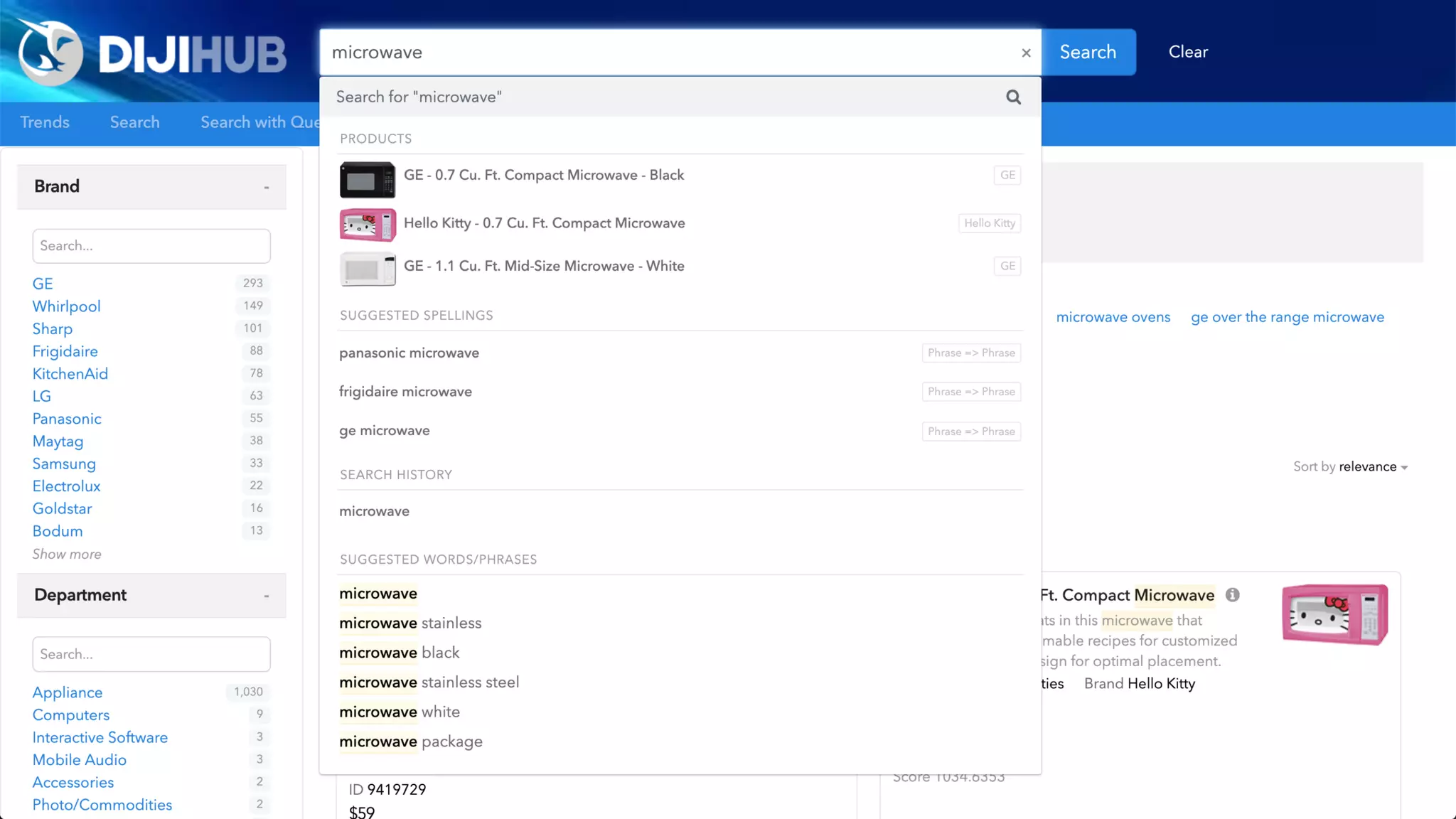


![Overly Simplistic Definitions
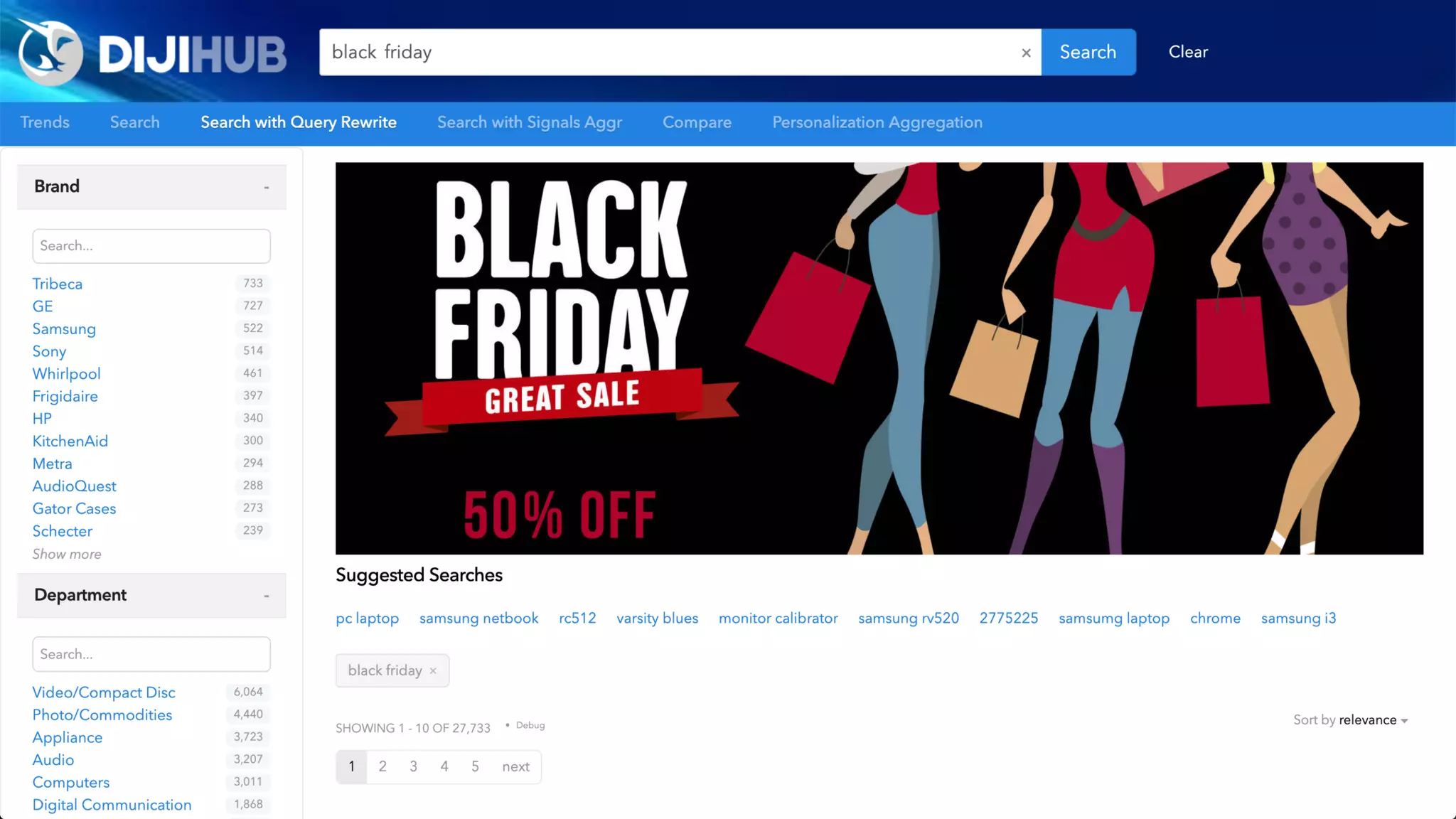
Ontology: Defines relationships between types of things
[ animal eats food; human is animal ]
Knowledge Graph: Instantiation of an
Ontology (contains the things that are related)
[ john is human; john eats food ]
Taxonomy: Classifies things into Categories
[ john is Human; Human is Mammal; Mammal is Animal ]
Synonyms List: Provides substitute words that can be used to represent the
same or very similar things
[ human => homo sapien, mankind; food => sustenance, meal ]
Alternative Labels: Substitute words with identical meanings
[ CTO => Chief Technology Officer; specialise => specialize ]
In practice, there is significant overlap…
Synonyms
List
Taxonomy
Ontology
Knowledge Graph
Alt.
Labels](https://image.slidesharecdn.com/reflected-intelligence-ai-search-and-disruption-of-km-191106053811/75/AI-Search-and-the-Disruption-of-Knowledge-Management-89-2048.jpg)




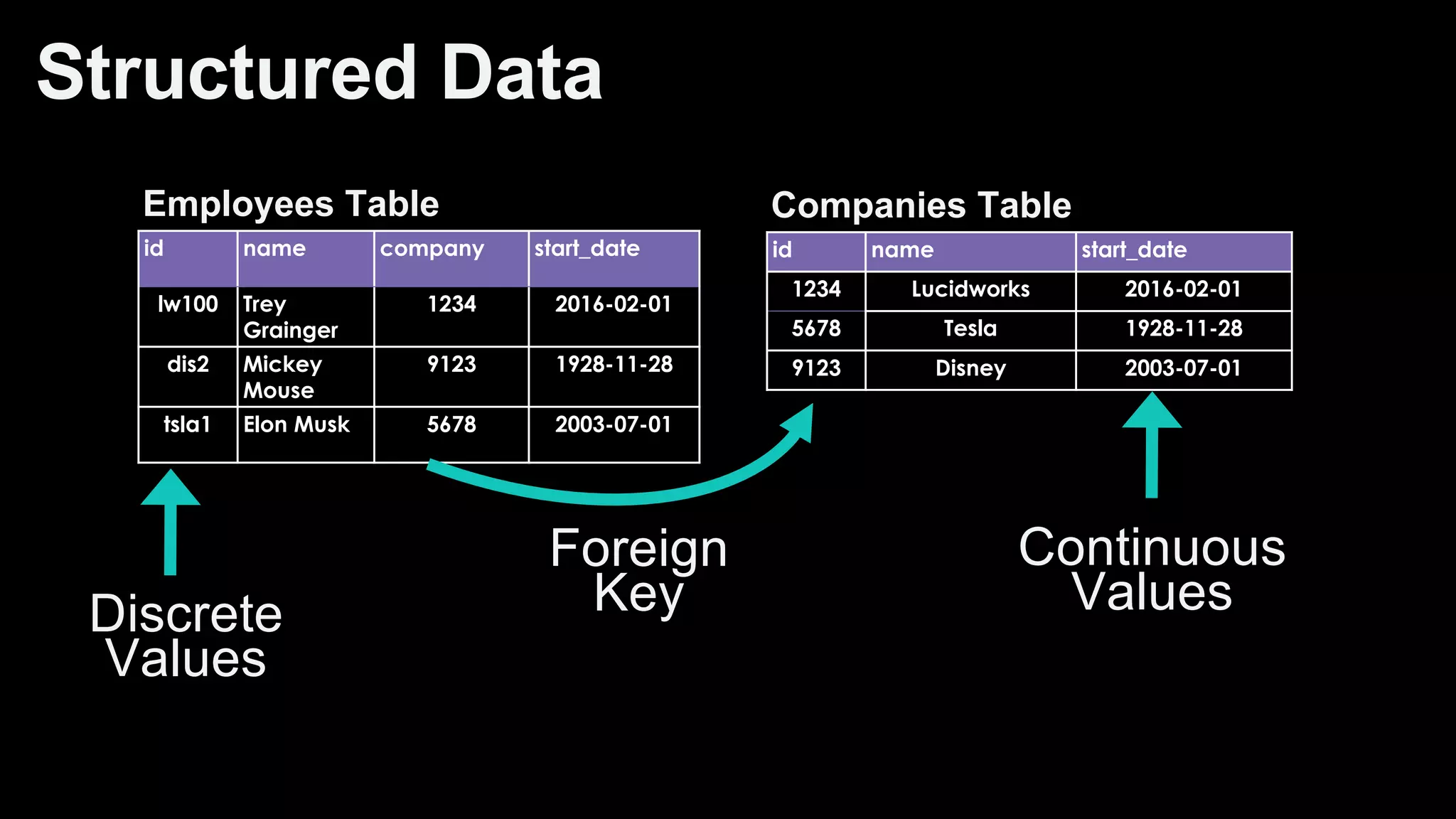




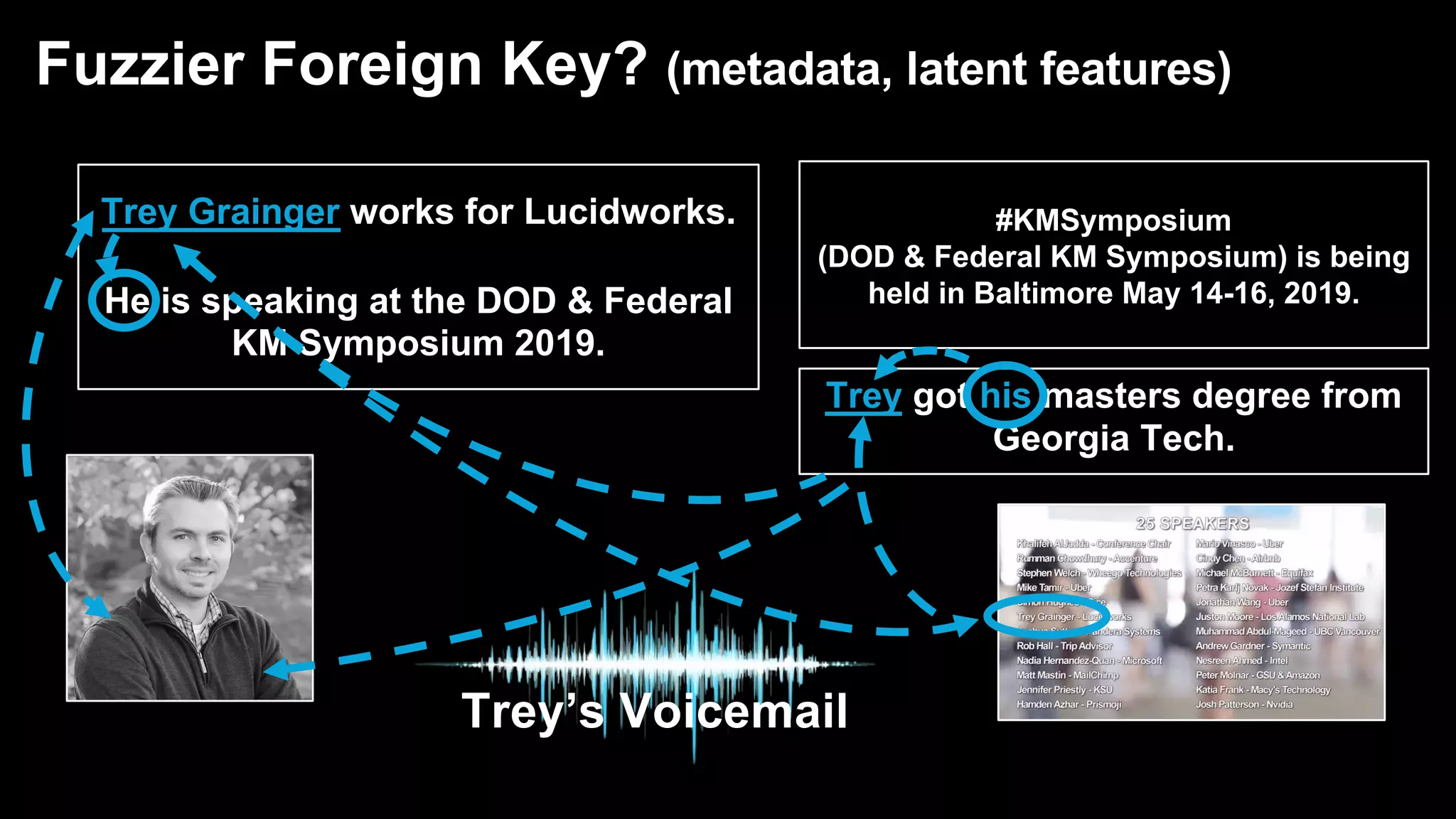

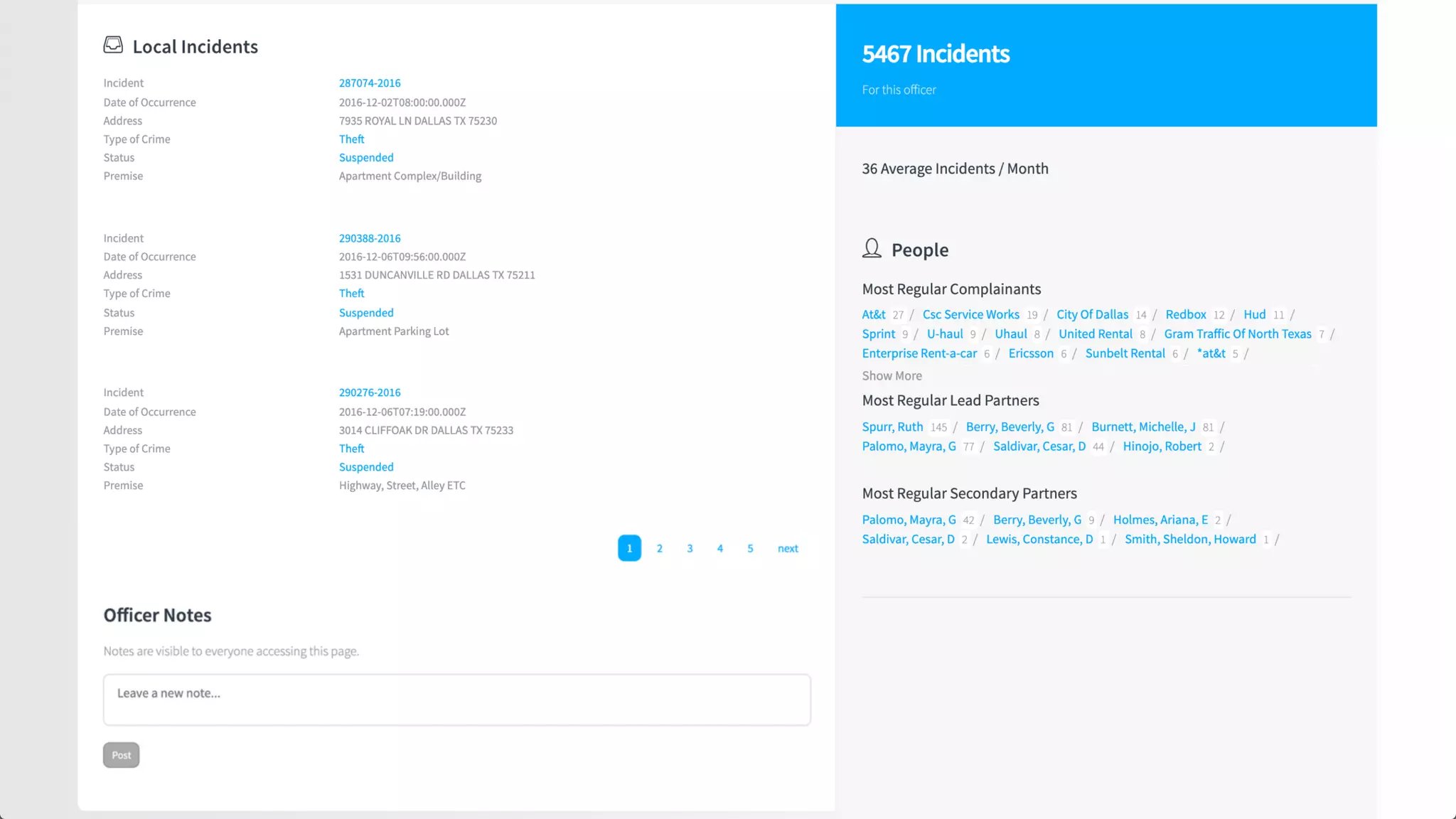
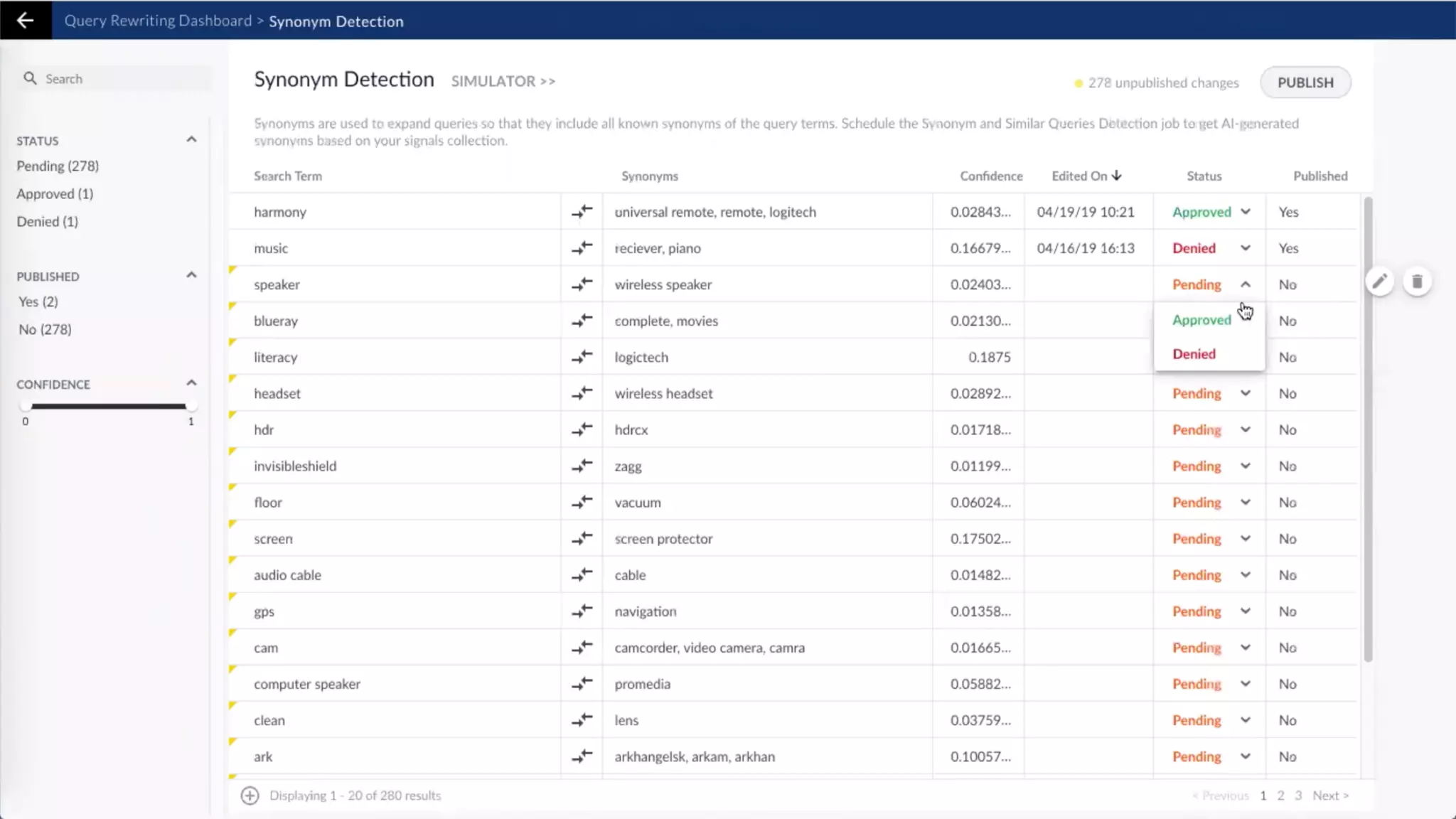
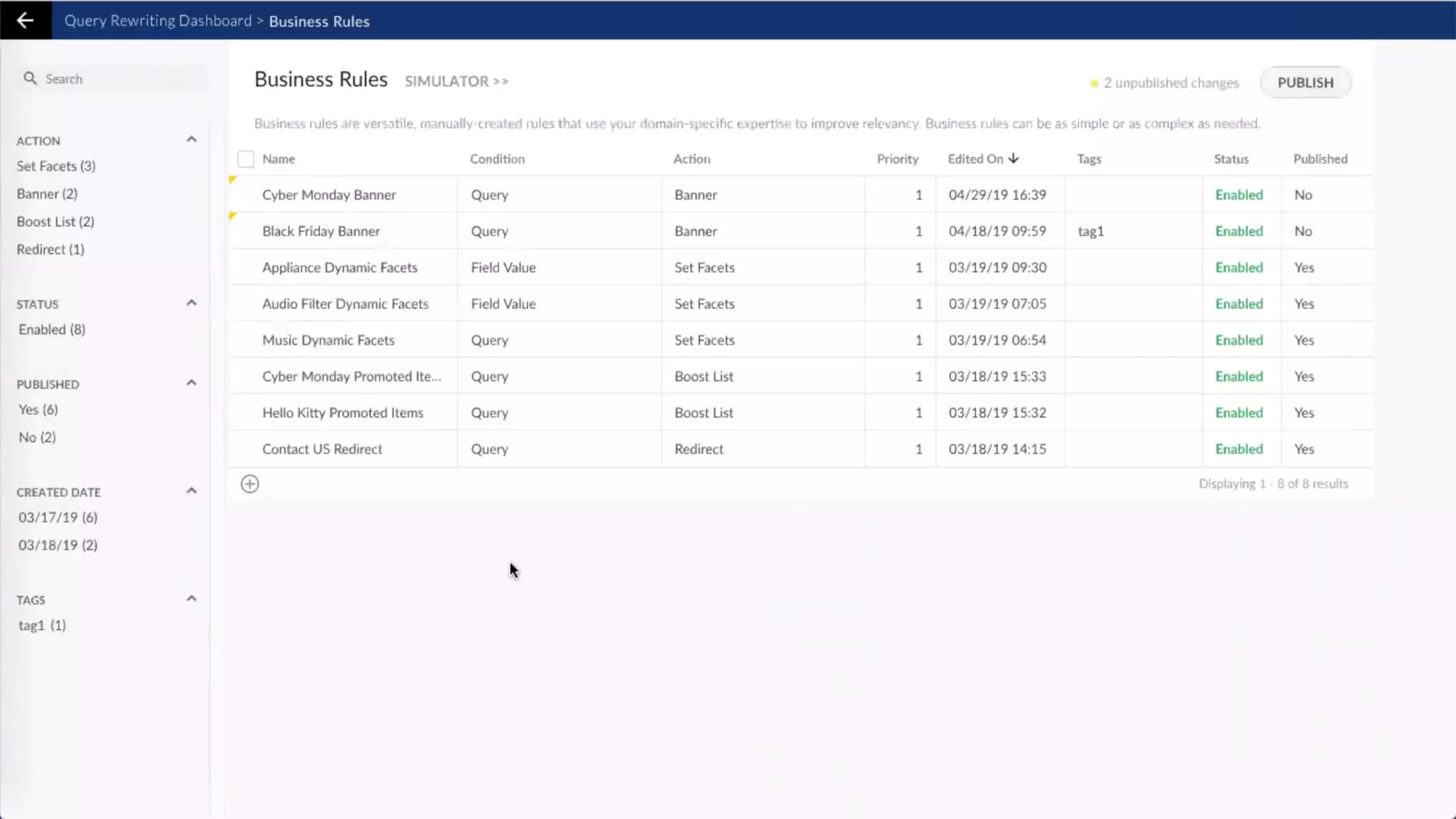
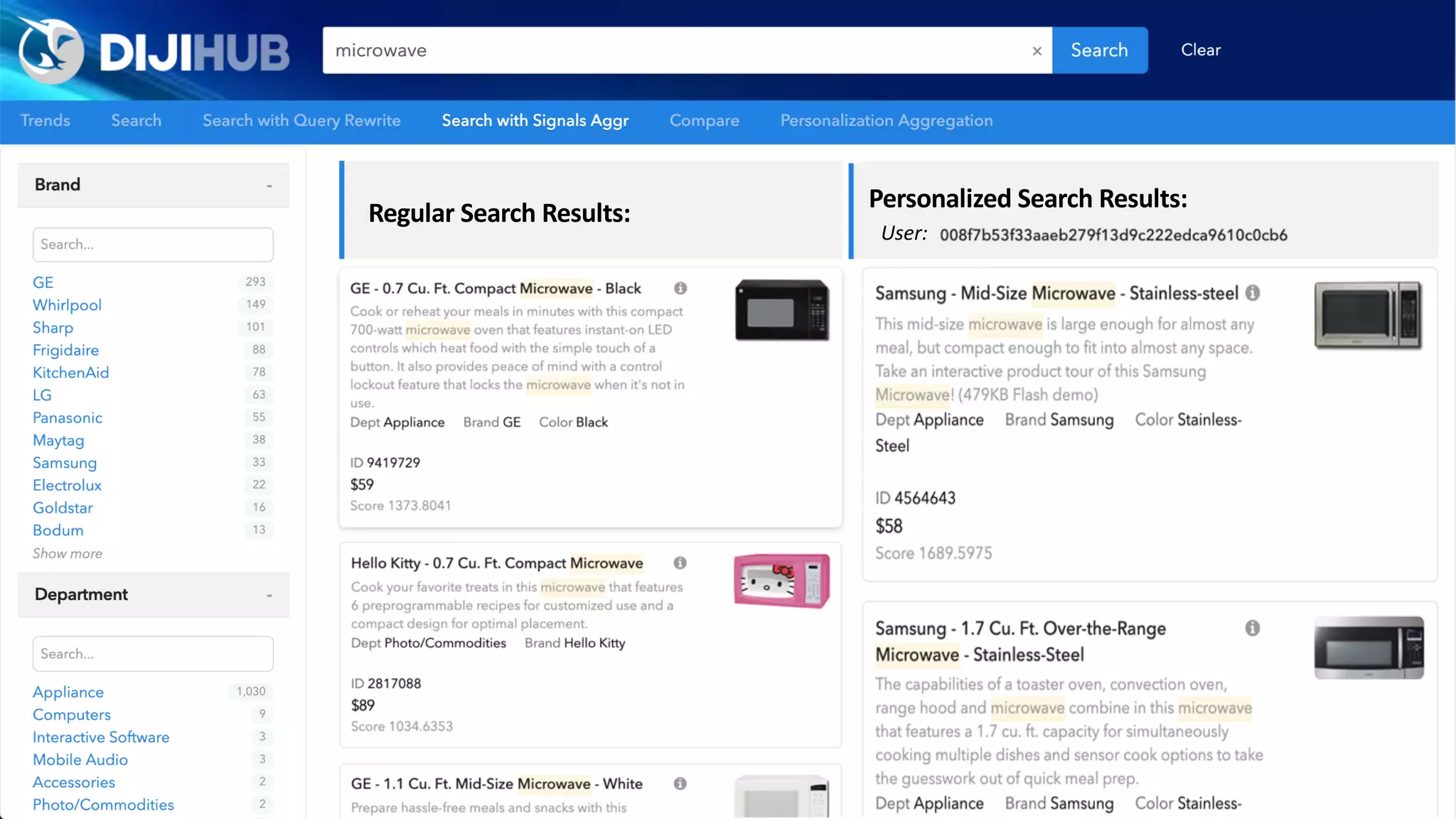
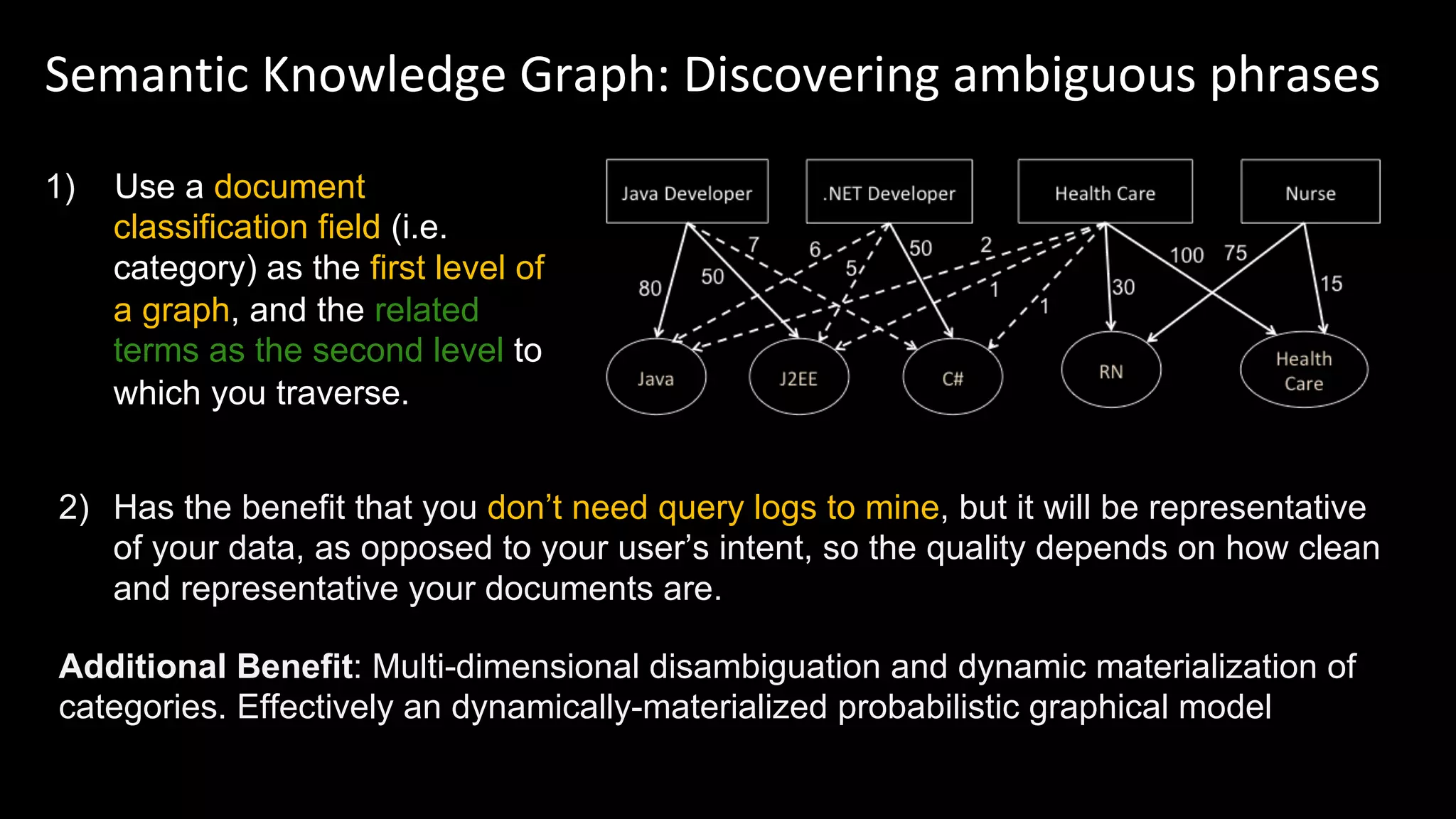
![Scoring of Node Relationships (Edge Weights)
Foreground vs. Background Analysis
Every term scored against it’s context. The more
commonly the term appears within it’s foreground
context versus its background context, the more
relevant it is to the specified foreground context.
countFG(x) - totalDocsFG * probBG(x)
z = --------------------------------------------------------
sqrt(totalDocsFG * probBG(x) * (1 - probBG(x)))
{ "type":"keywords”, "values":[
{ "value":"hive", "relatedness":0.9773, "popularity":369 },
{ "value":"java", "relatedness":0.9236, "popularity":15653 },
{ "value":".net", "relatedness":0.5294, "popularity":17683 },
{ "value":"bee", "relatedness":0.0, "popularity":0 },
{ "value":"teacher", "relatedness":-0.2380, "popularity":9923 },
{ "value":"registered nurse", "relatedness": -0.3802 "popularity":27089 } ] }
We are essentially boosting terms which are more related to some known feature
(and ignoring terms which are equally likely to appear in the background corpus)
+
-
Foreground Query:
"Hadoop"
Knowledge
Graph](https://image.slidesharecdn.com/reflected-intelligence-ai-search-and-disruption-of-km-191106053811/75/AI-Search-and-the-Disruption-of-Knowledge-Management-108-2048.jpg)

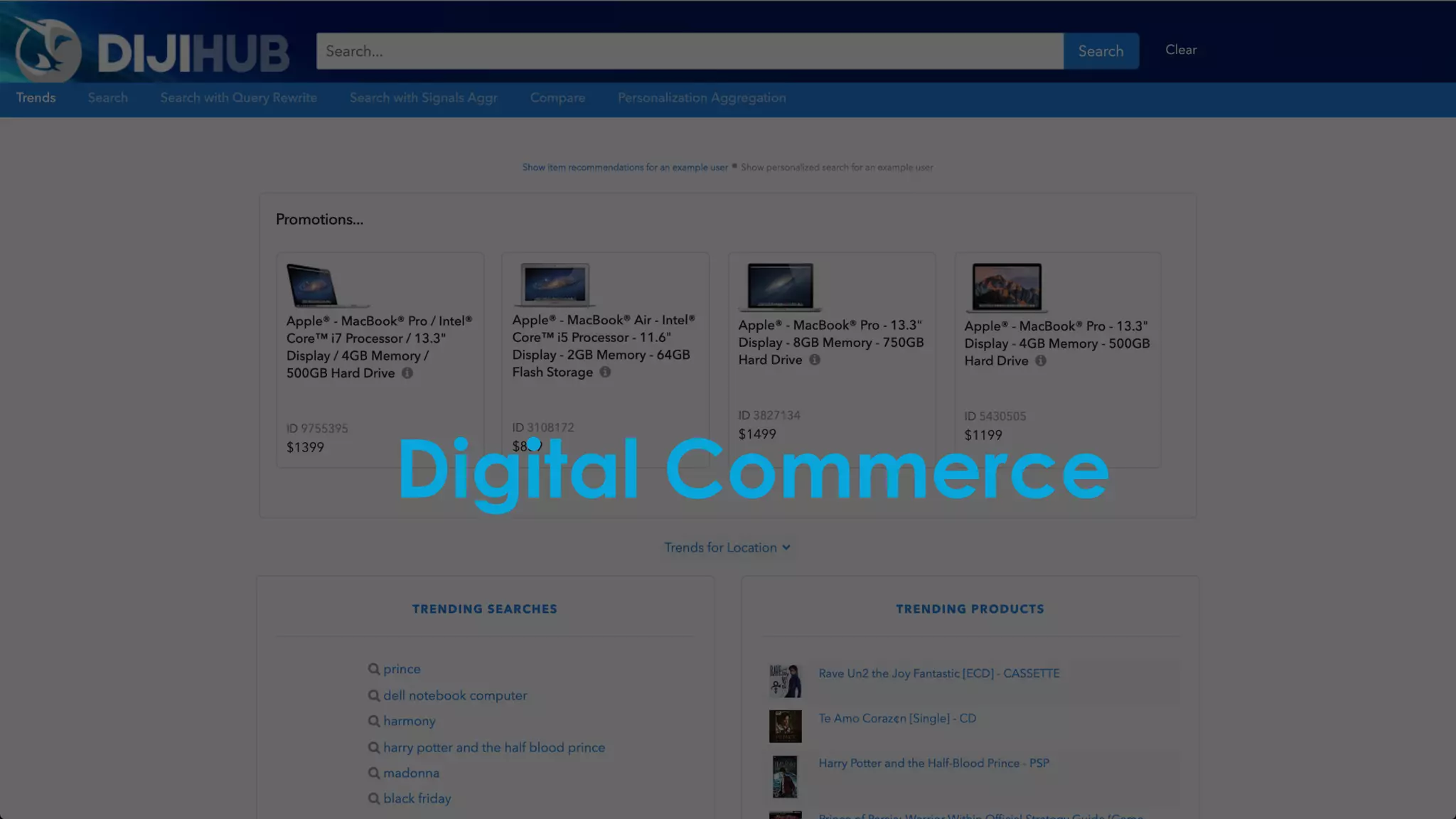
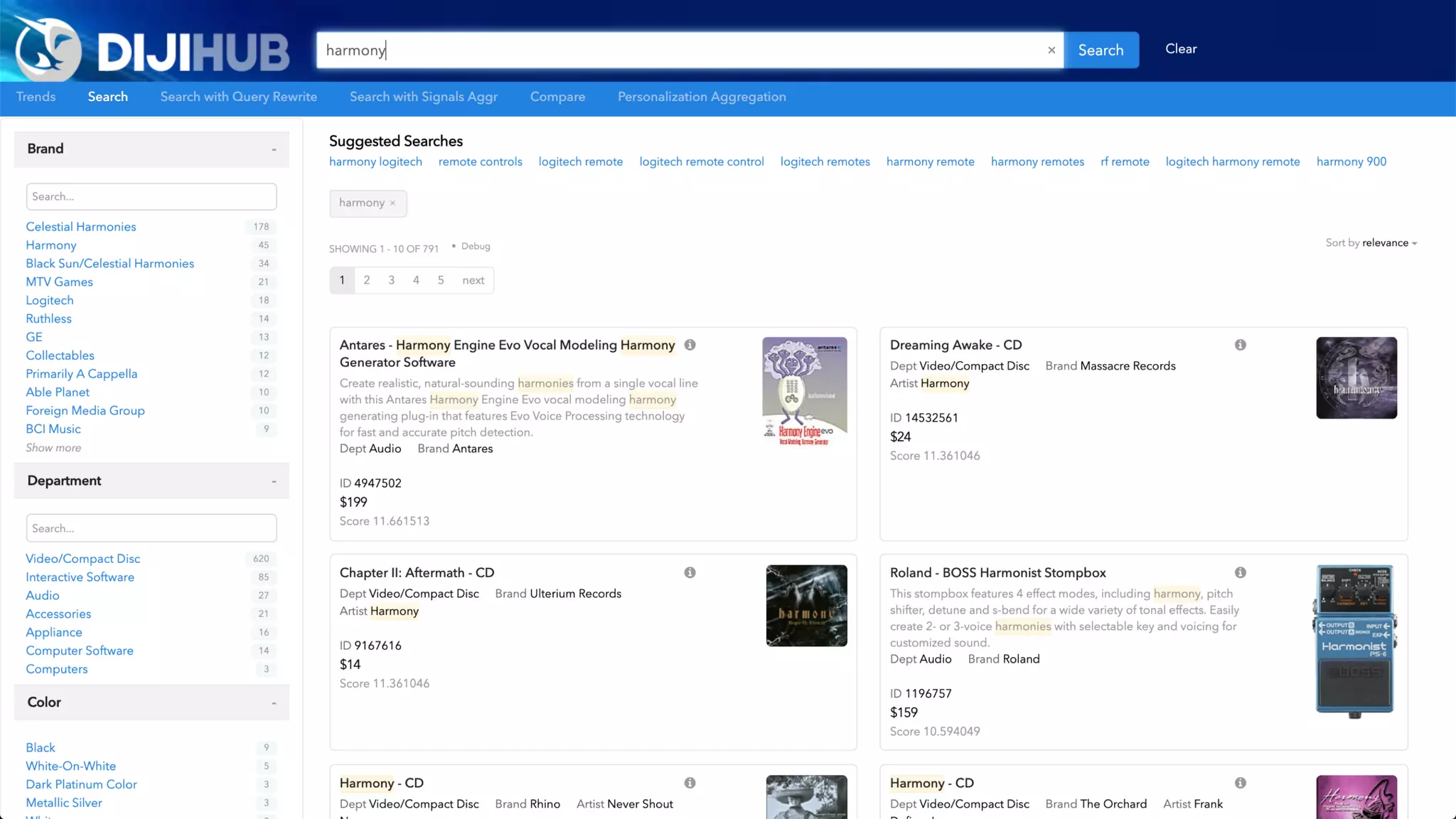
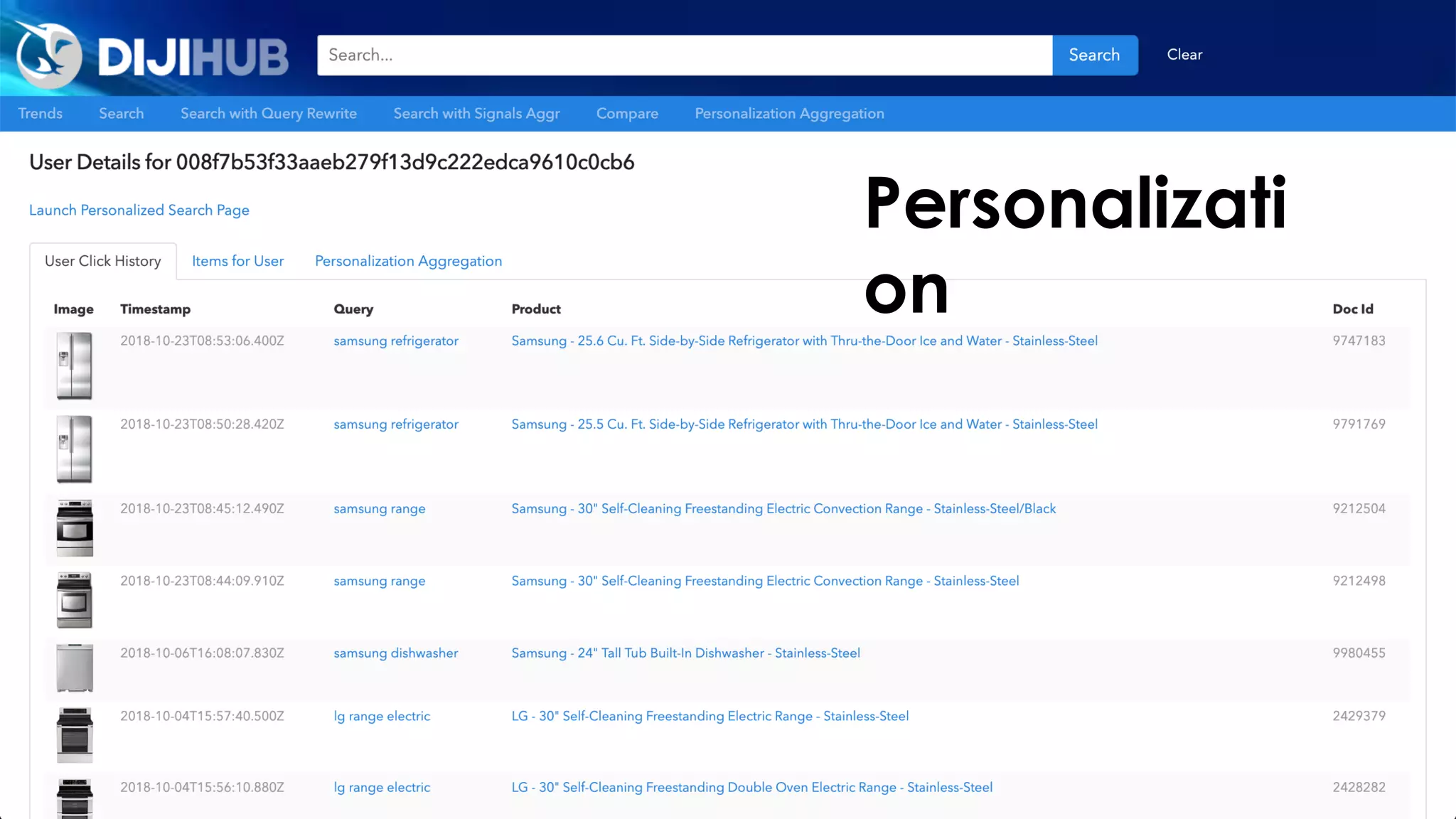
![NER automatically translates…
Barack Obama was the president of the United States of America. Before that, Obama was a
senator.
into…
<person id="barack_obama">Barack Obama</person> was the <role>president</role> of the
<country id="usa">United States of America</country>. Before that, <person
id="barack_obama">Obama</person> was a <role>senator</role>.
In the search engine, this would become:
text: Barack Obama was the president of the United States of America. Before that, Obama was a
senator.
person: Barack Obama
country: United States of America
role: [ president, senator ]
Named Entity Recognition (NER)](https://image.slidesharecdn.com/reflected-intelligence-ai-search-and-disruption-of-km-191106053811/75/AI-Search-and-the-Disruption-of-Knowledge-Management-114-2048.jpg)















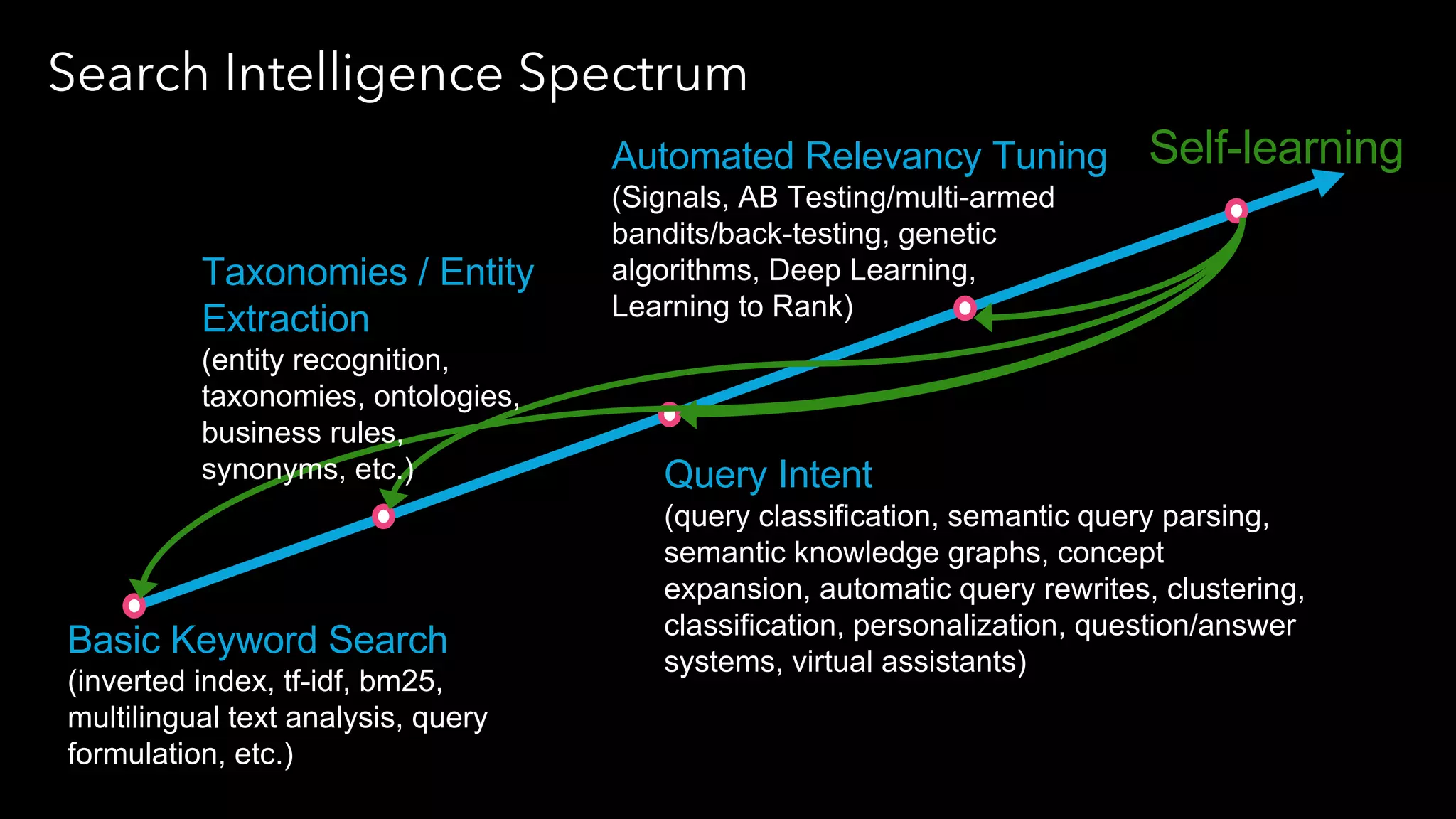




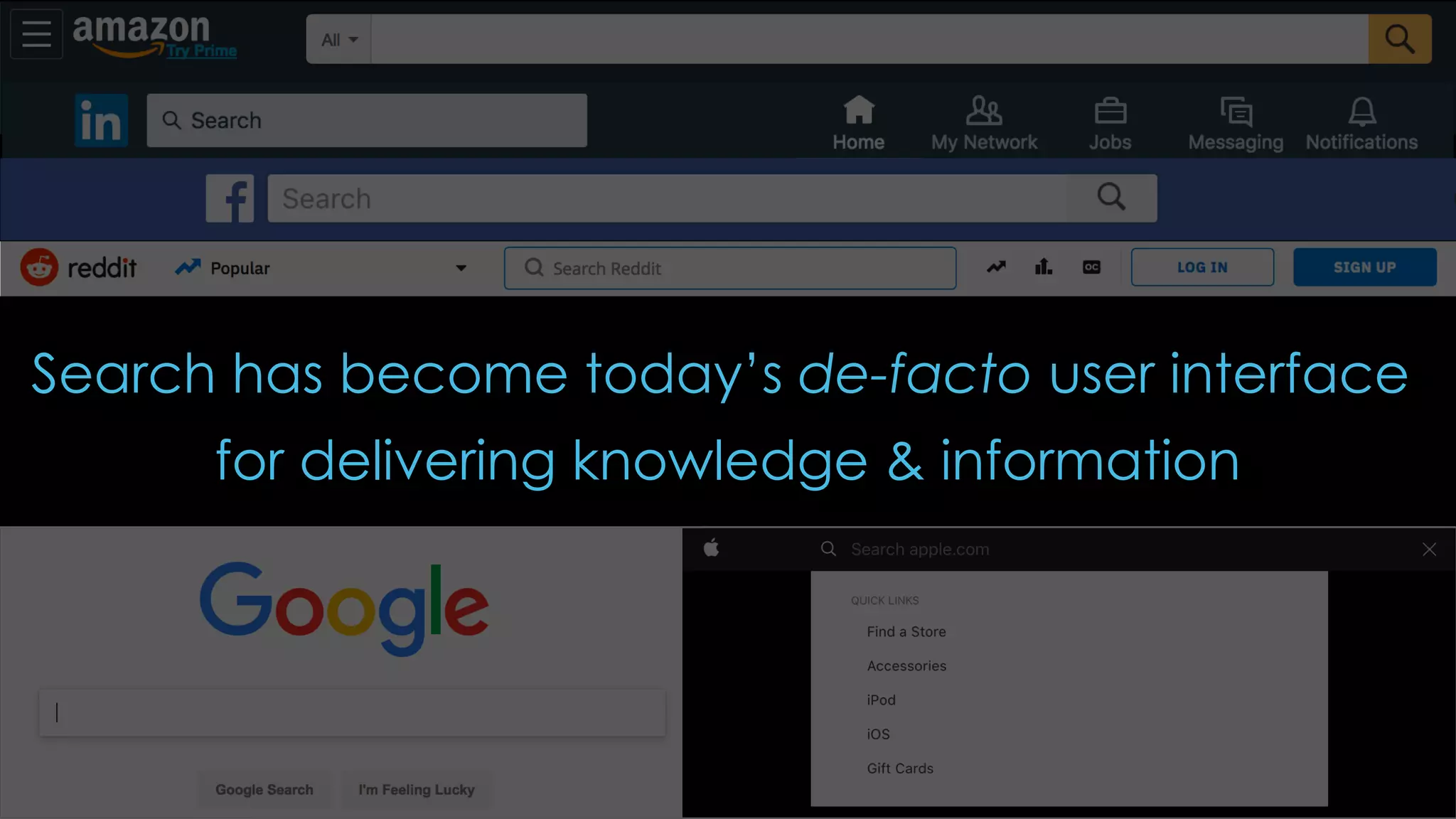
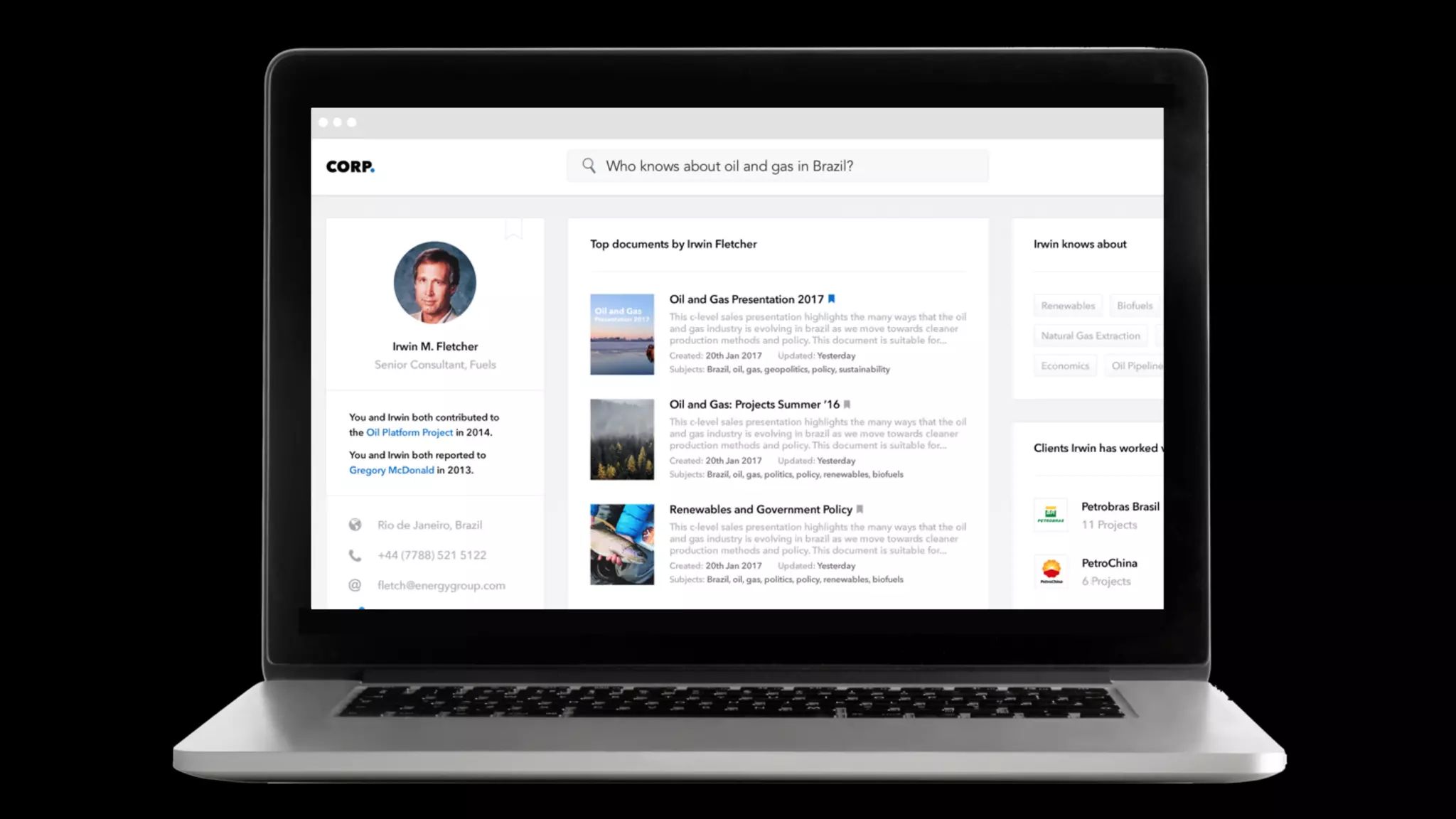
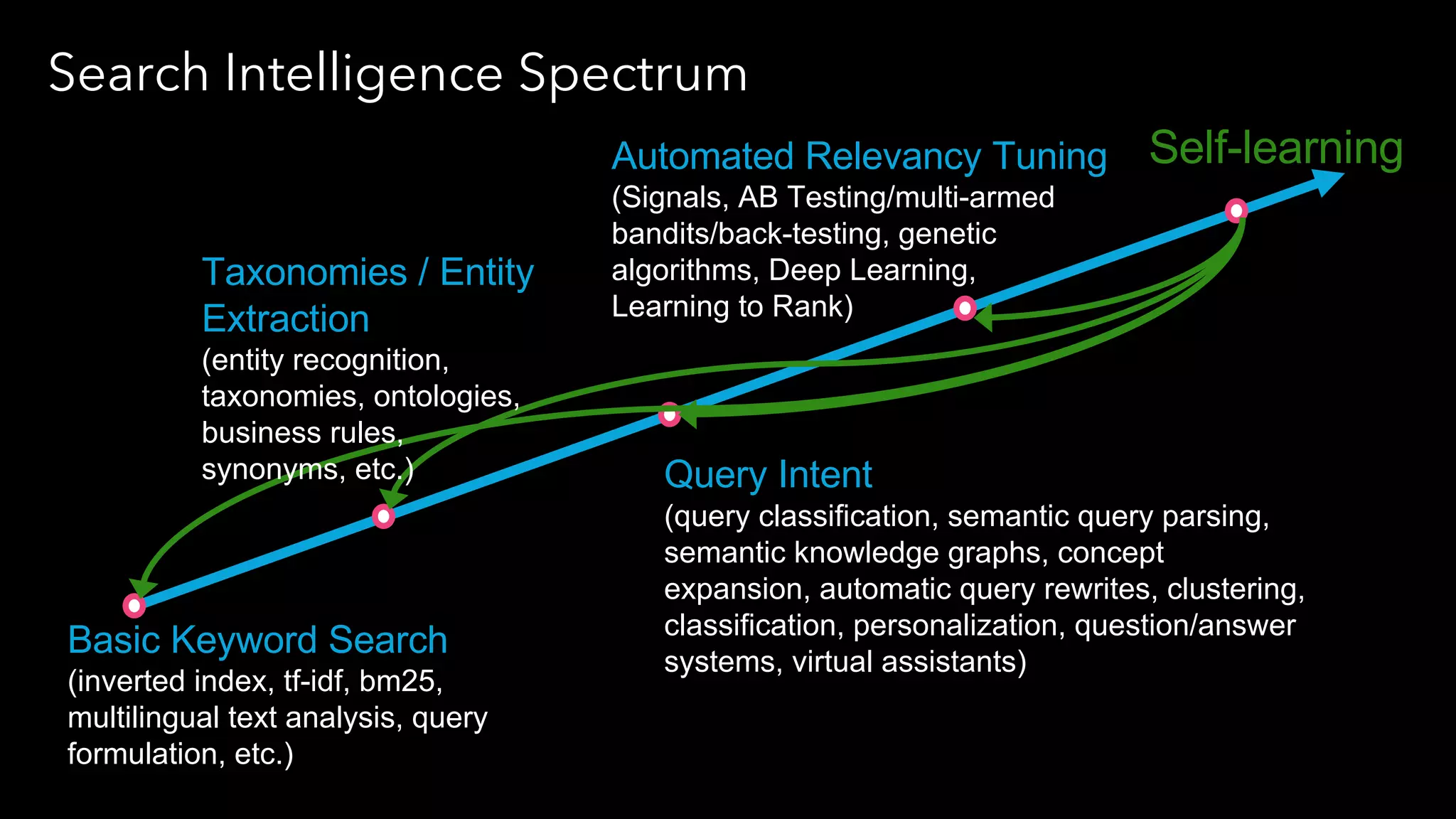
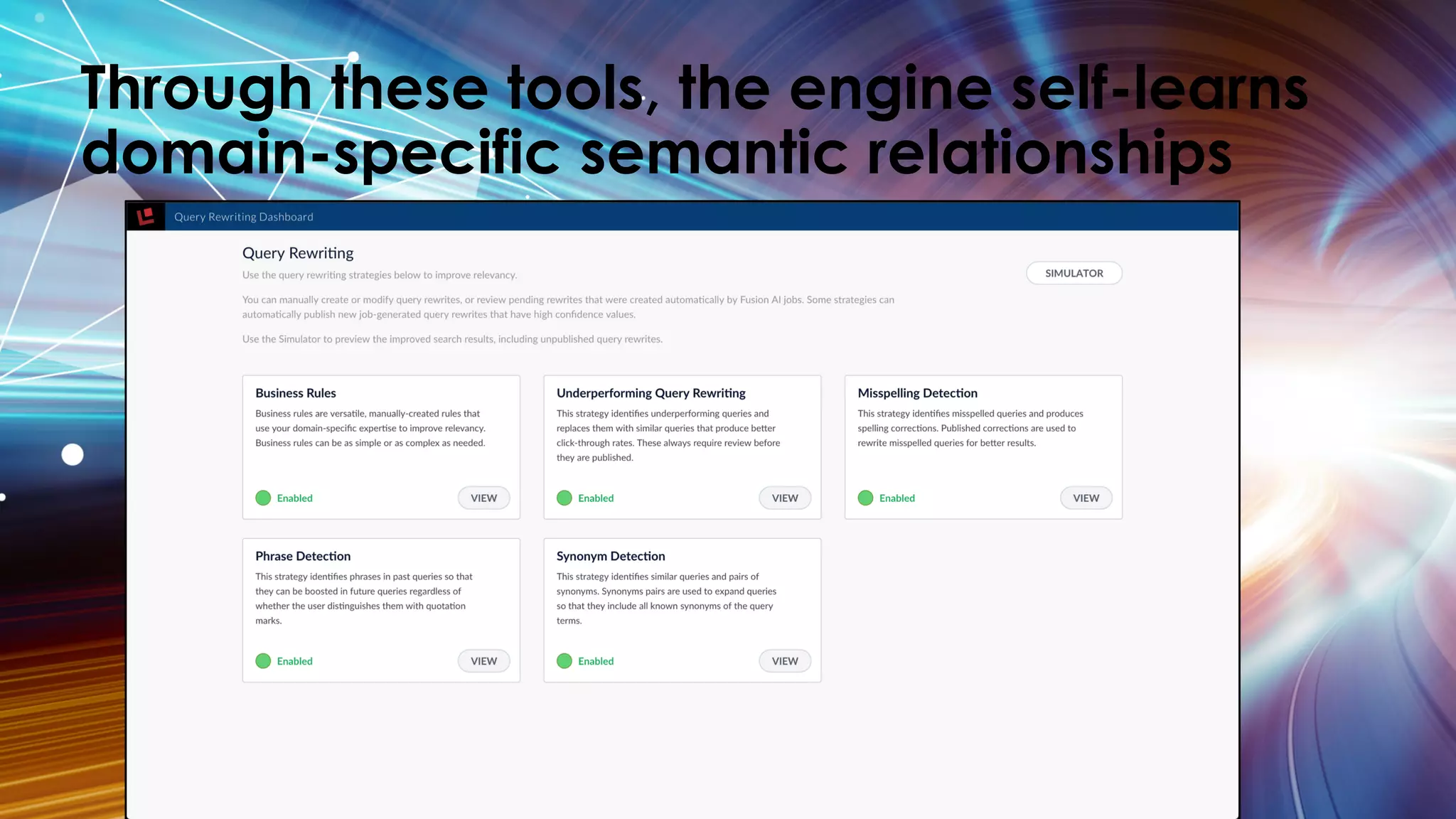
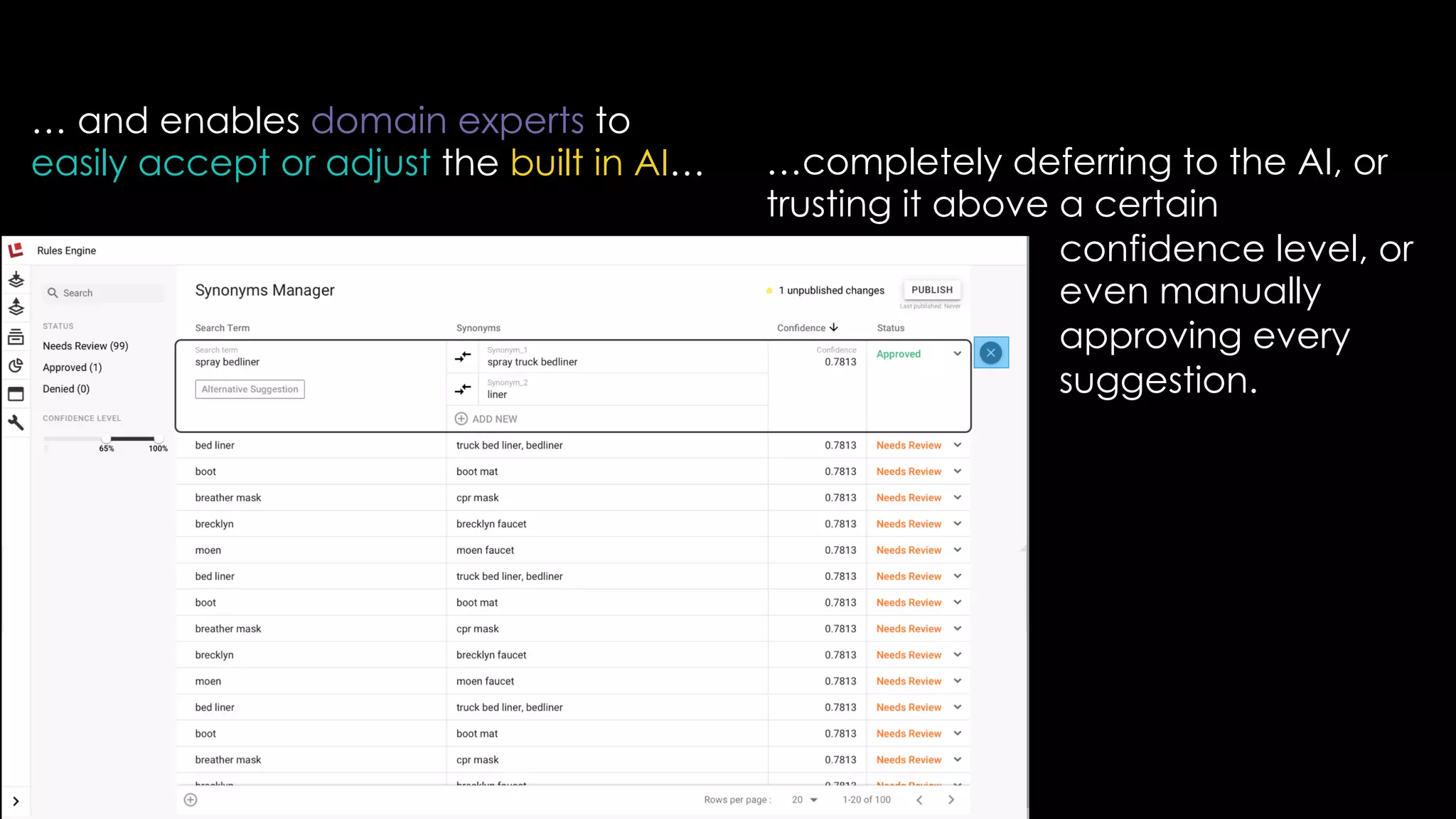
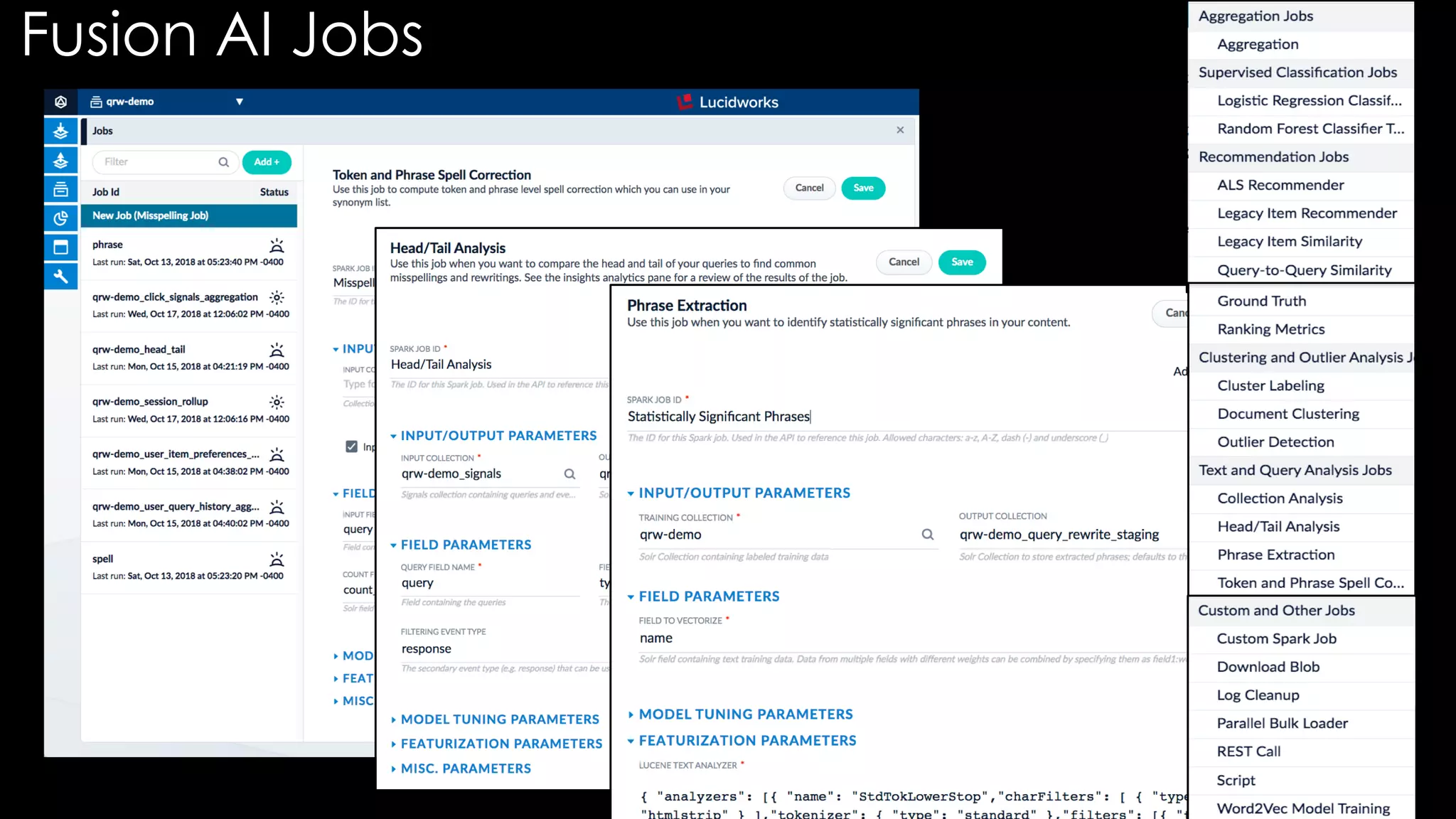
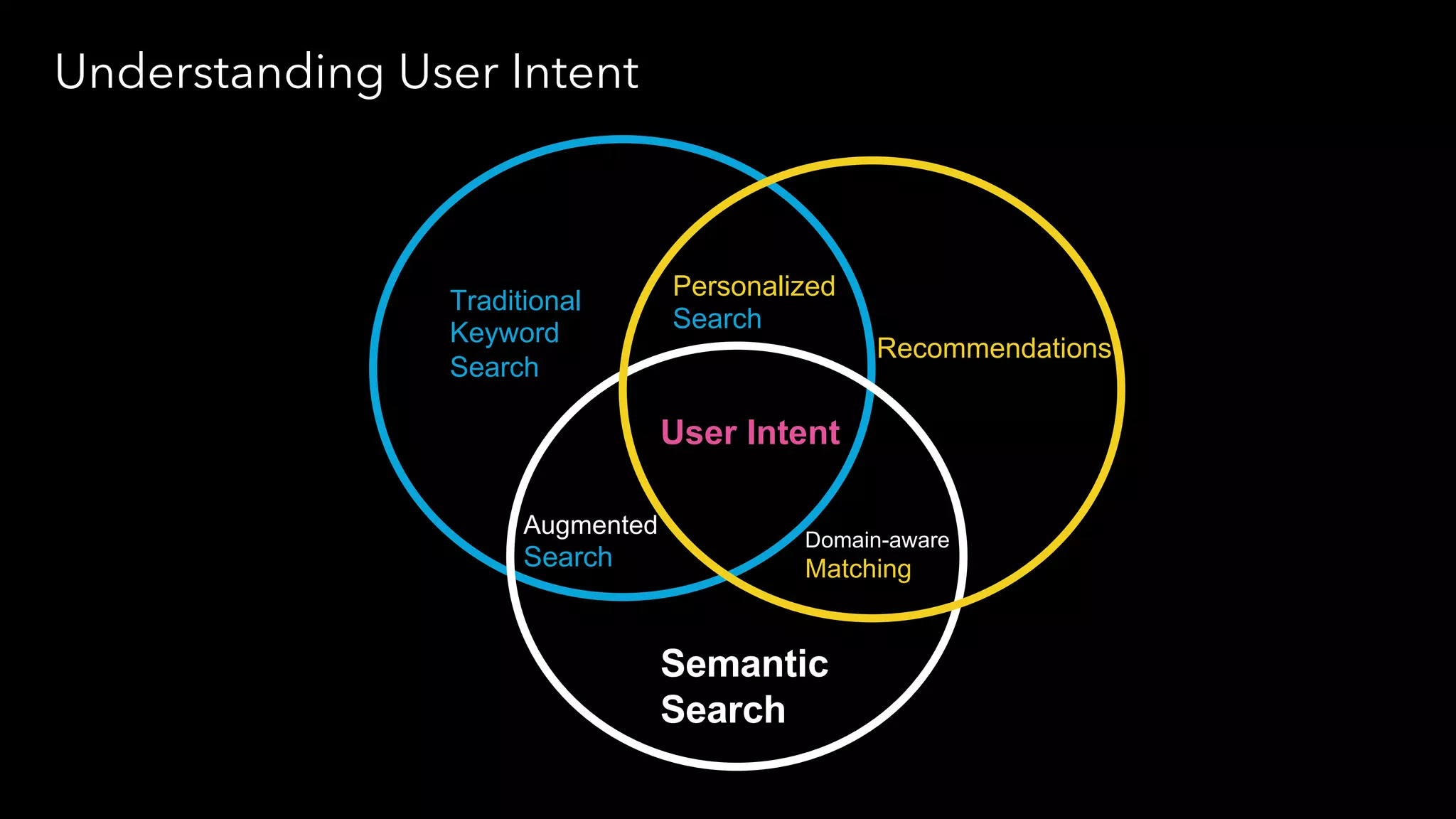
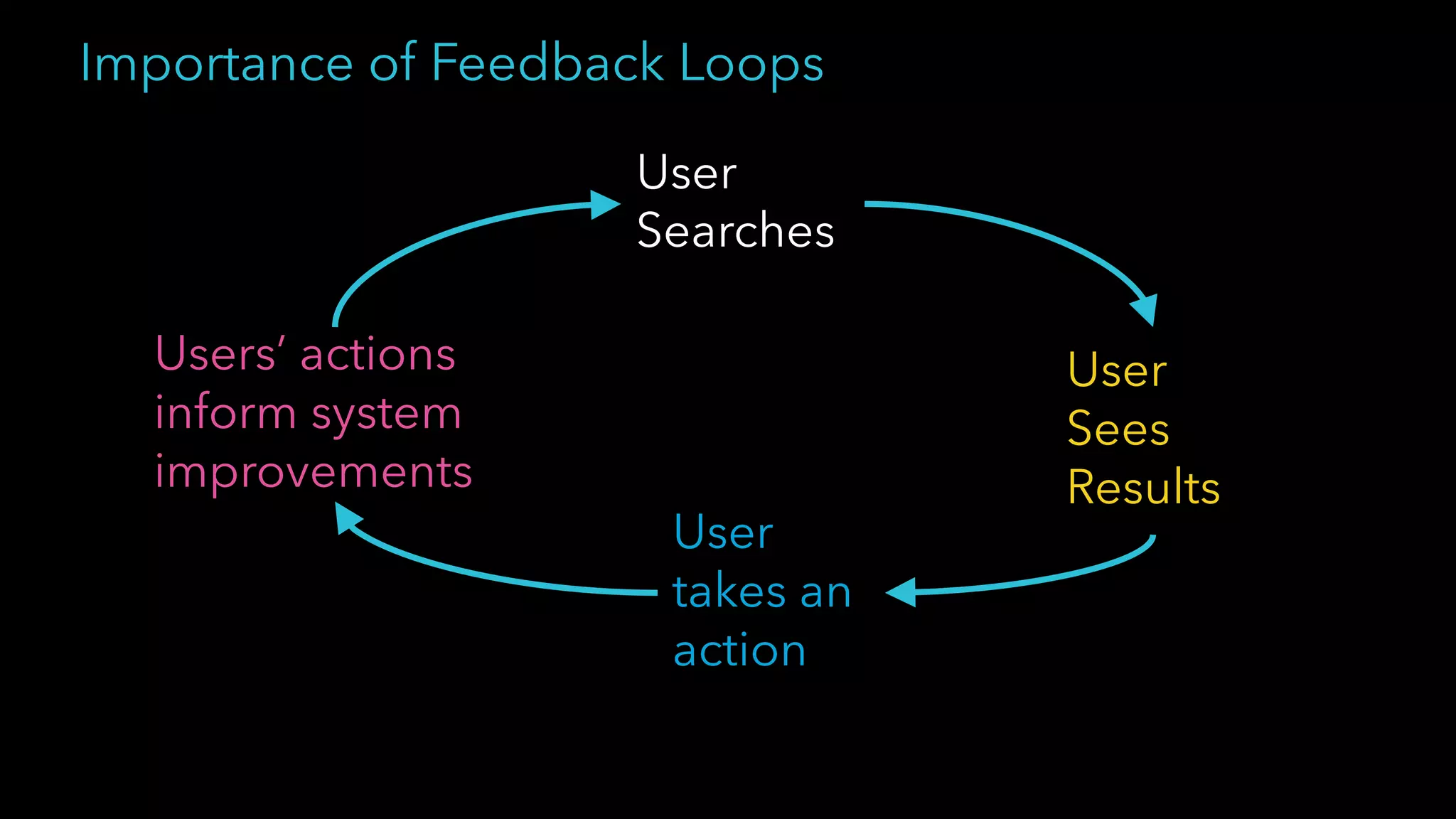
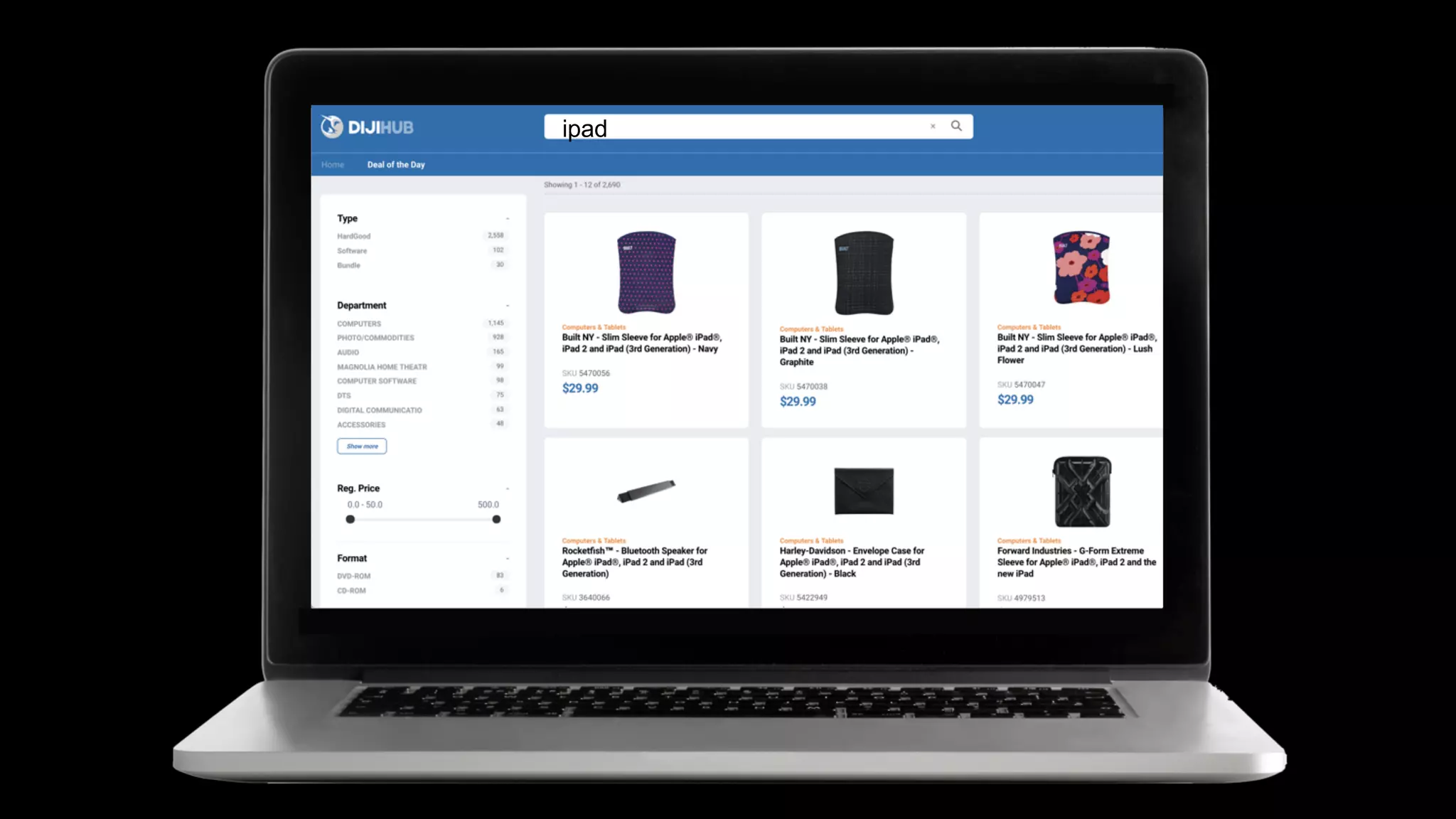
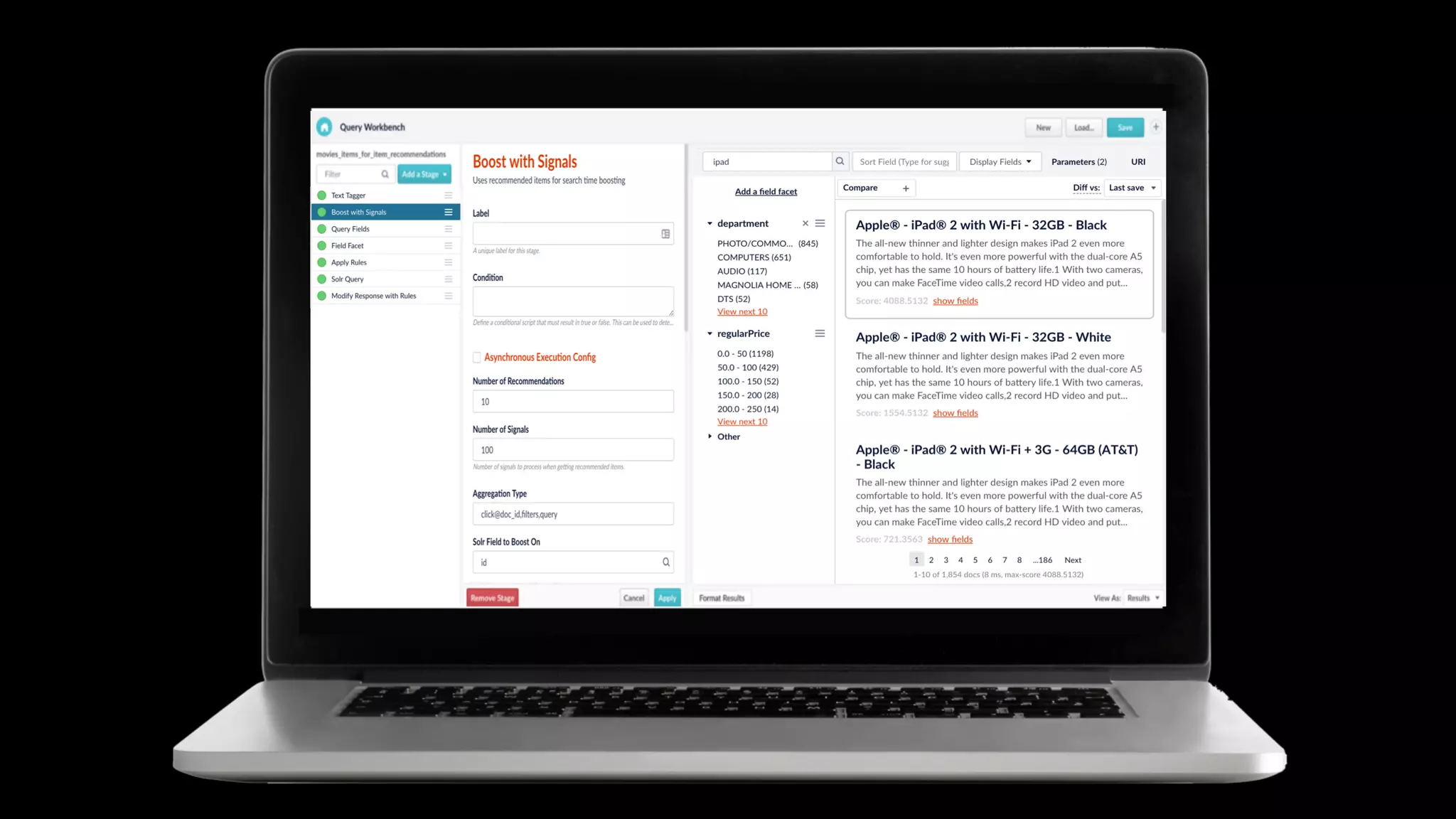
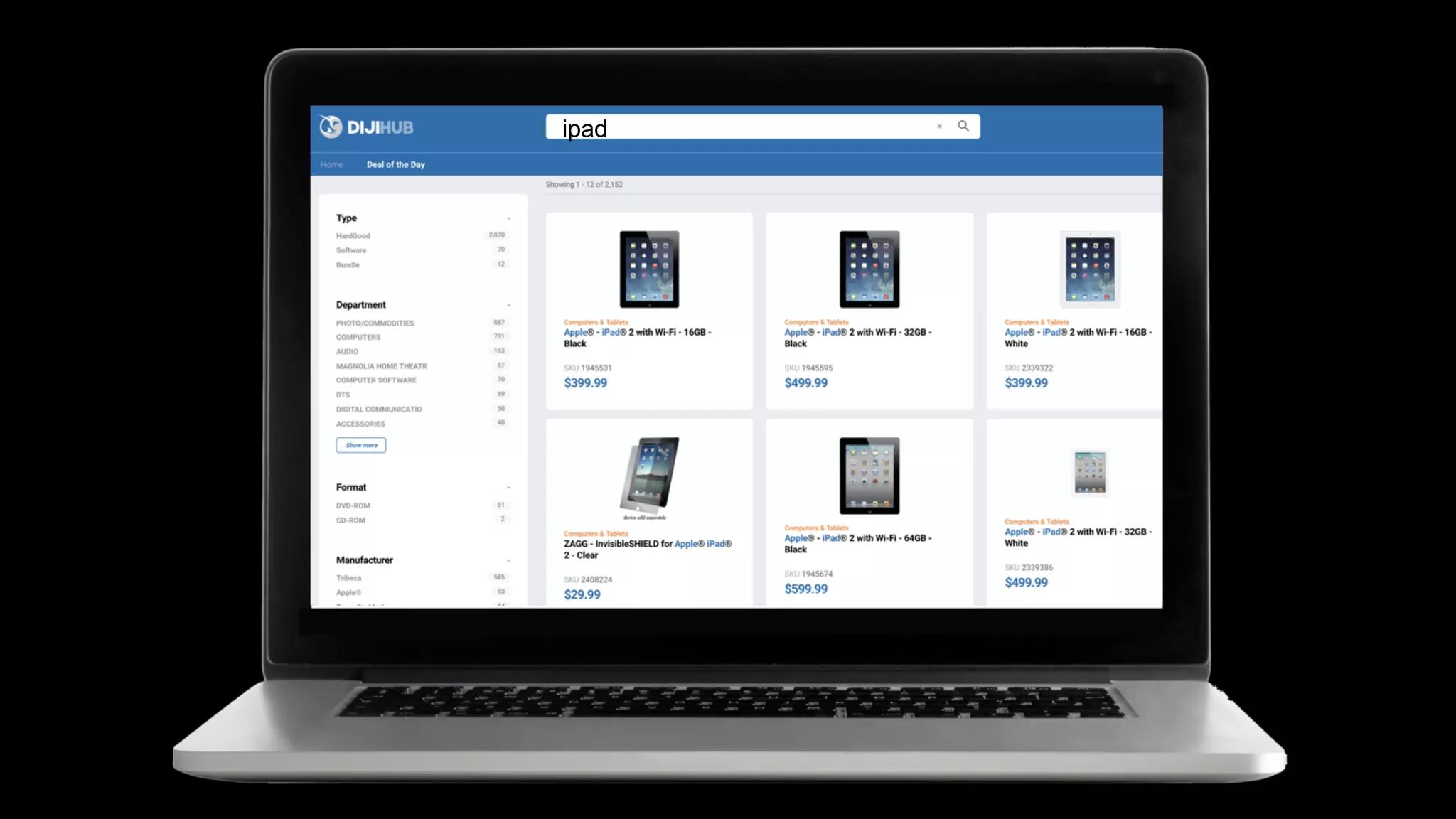
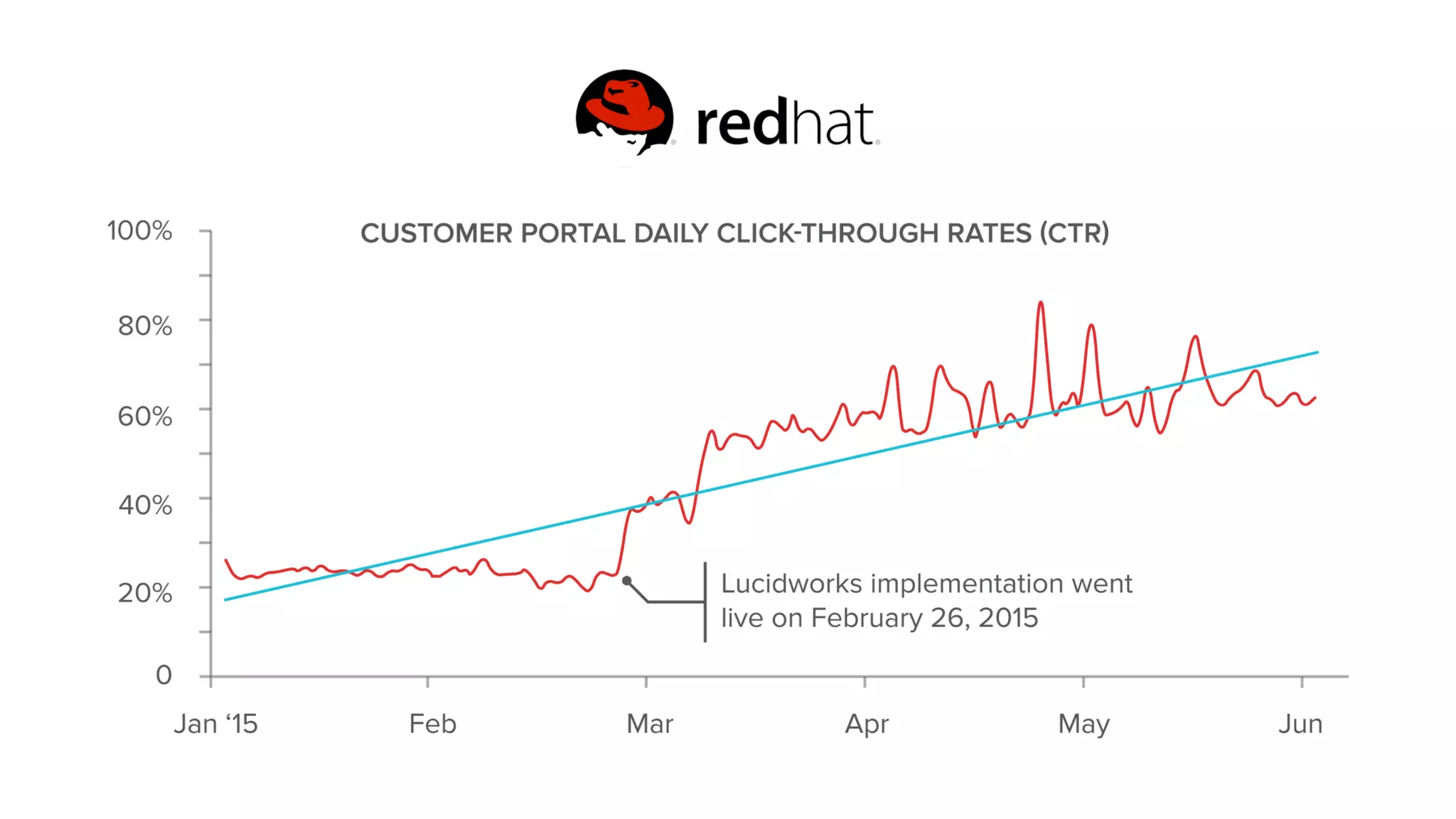
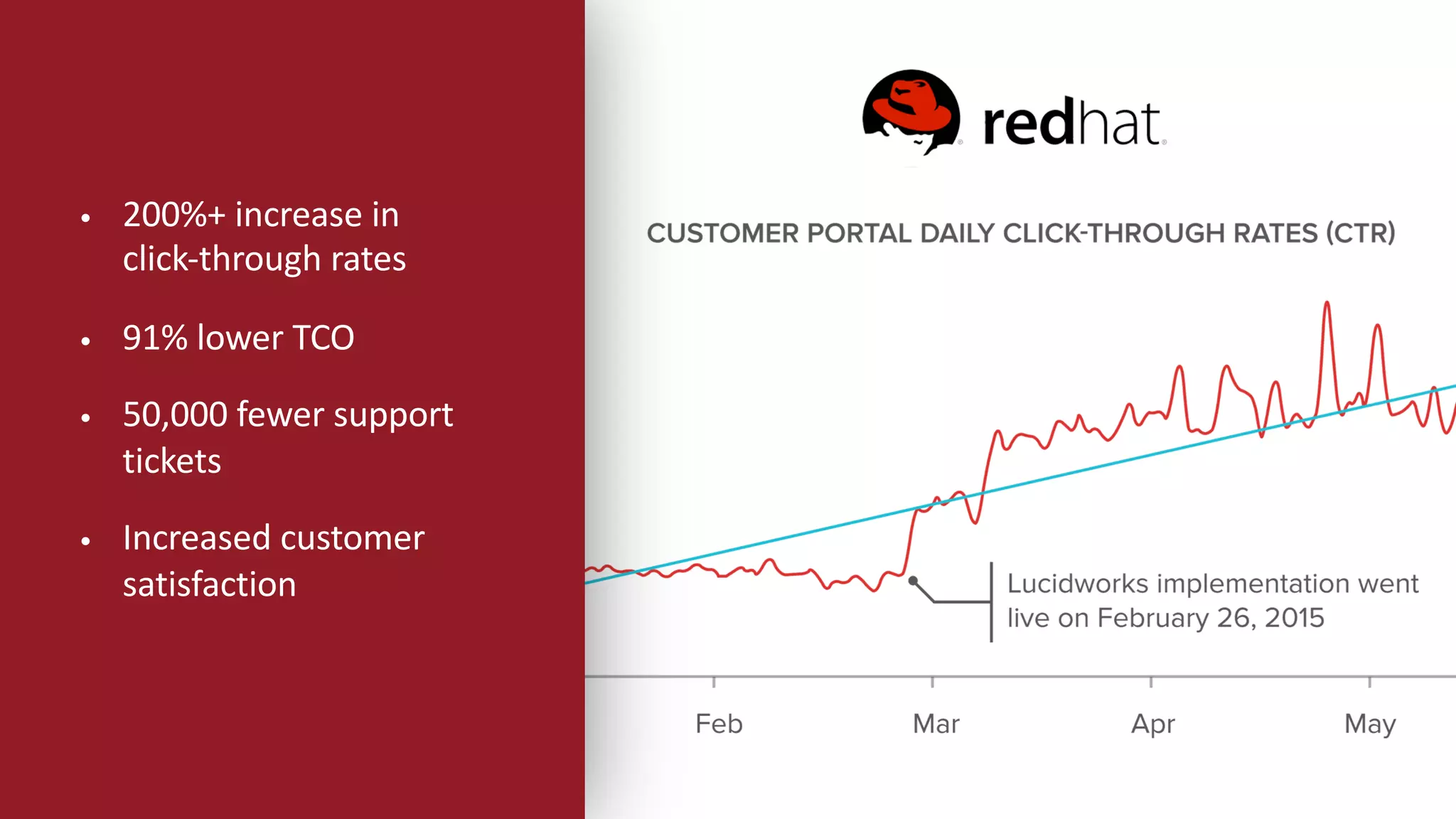
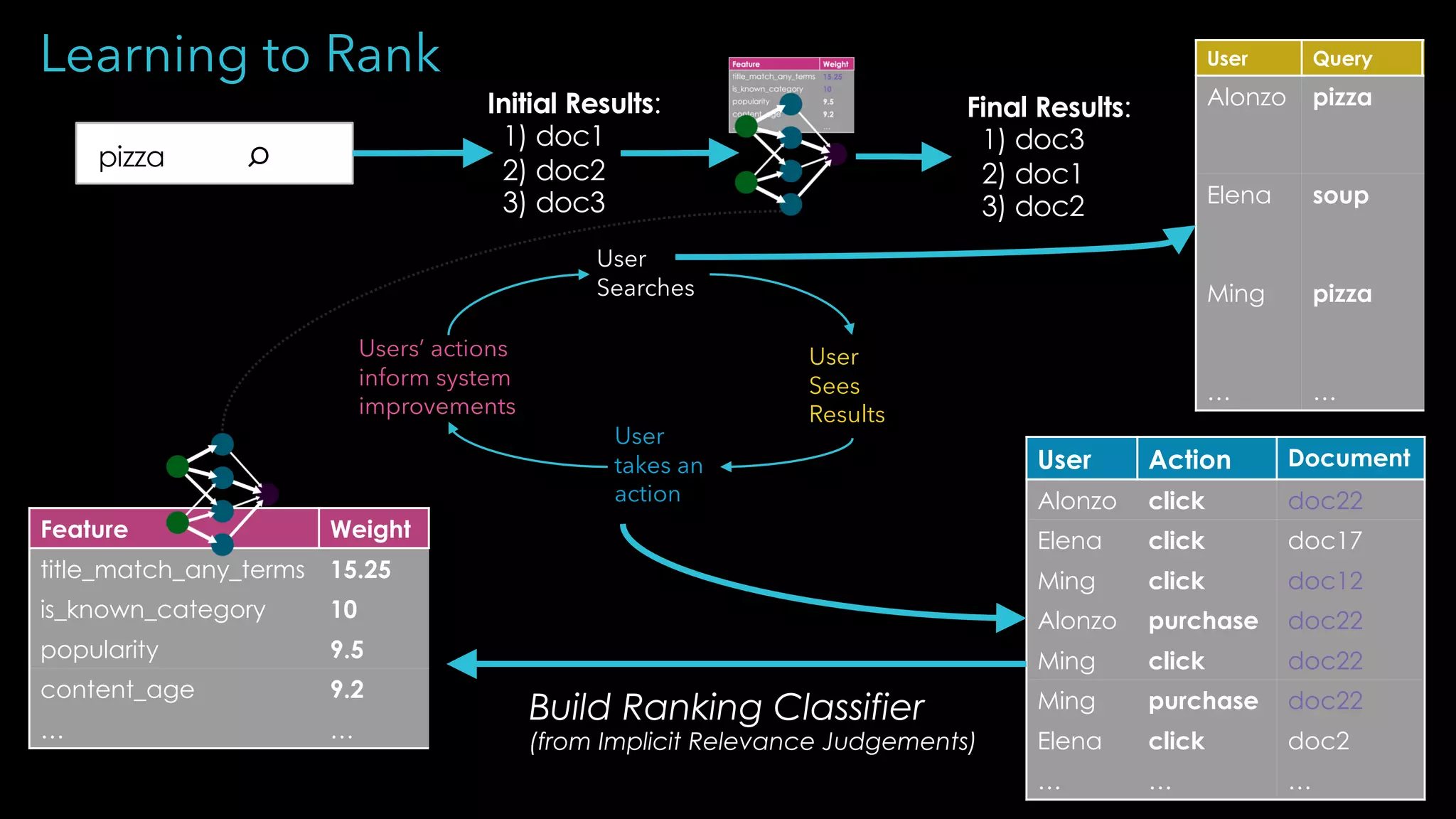
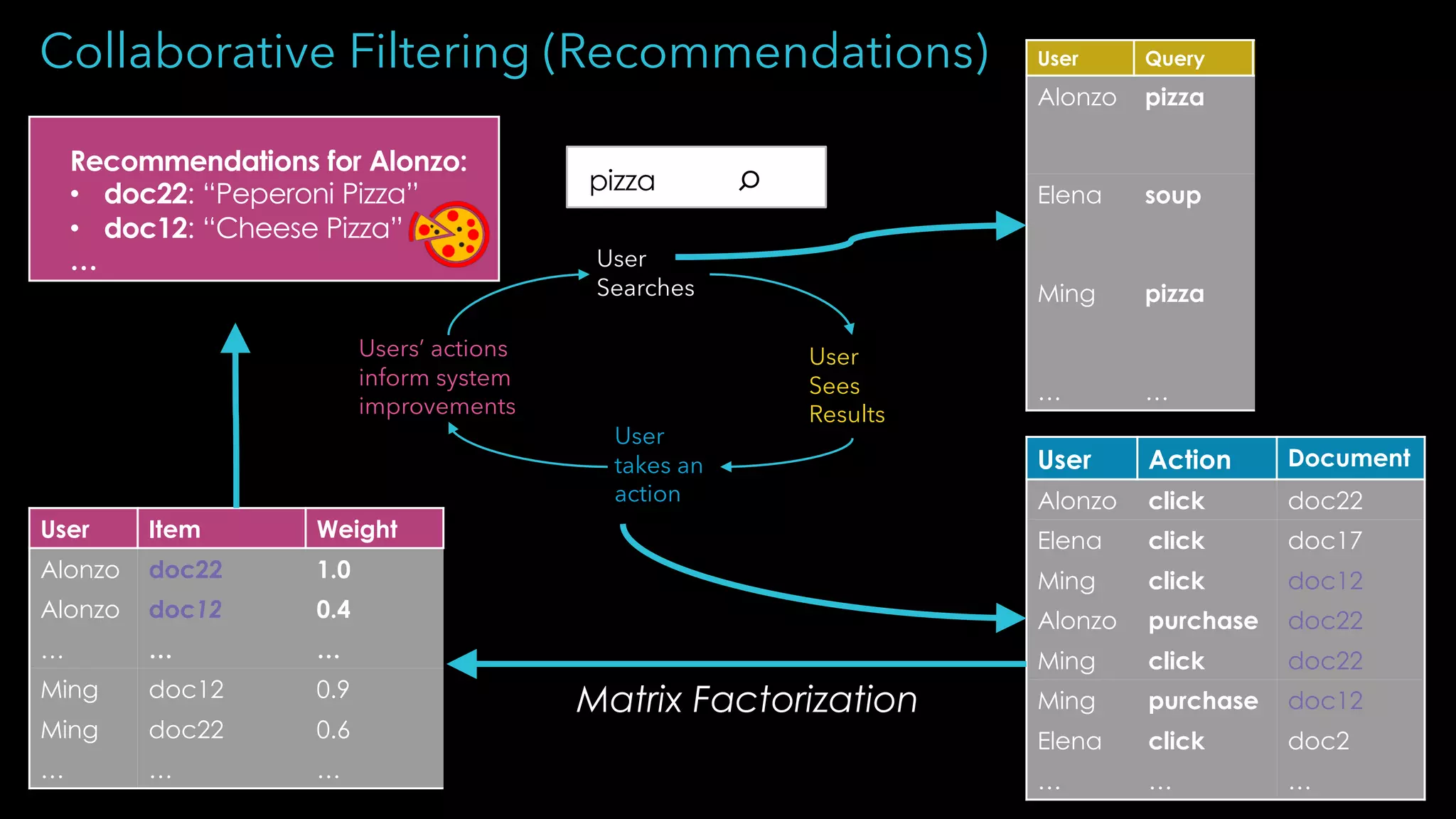
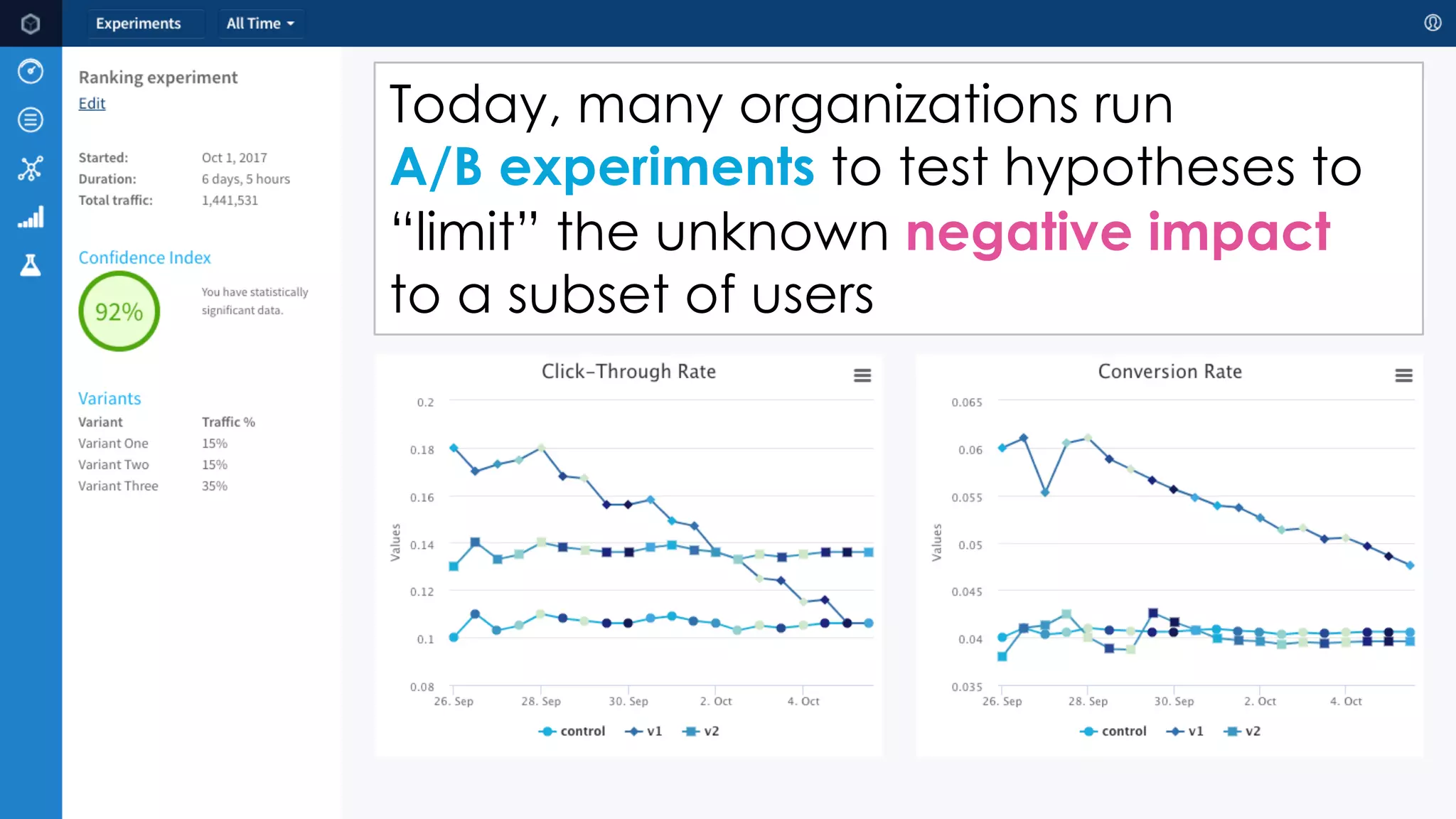
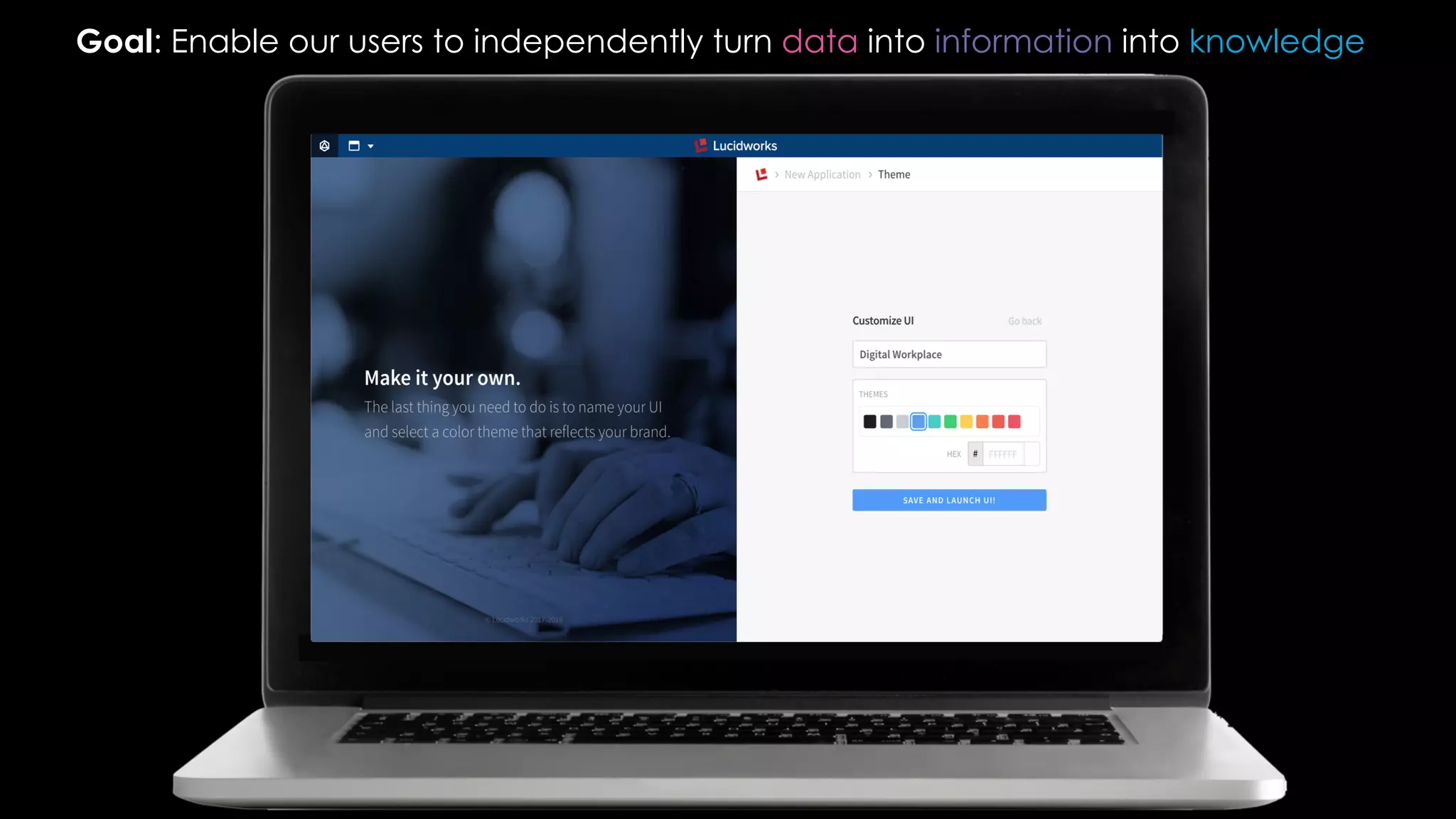
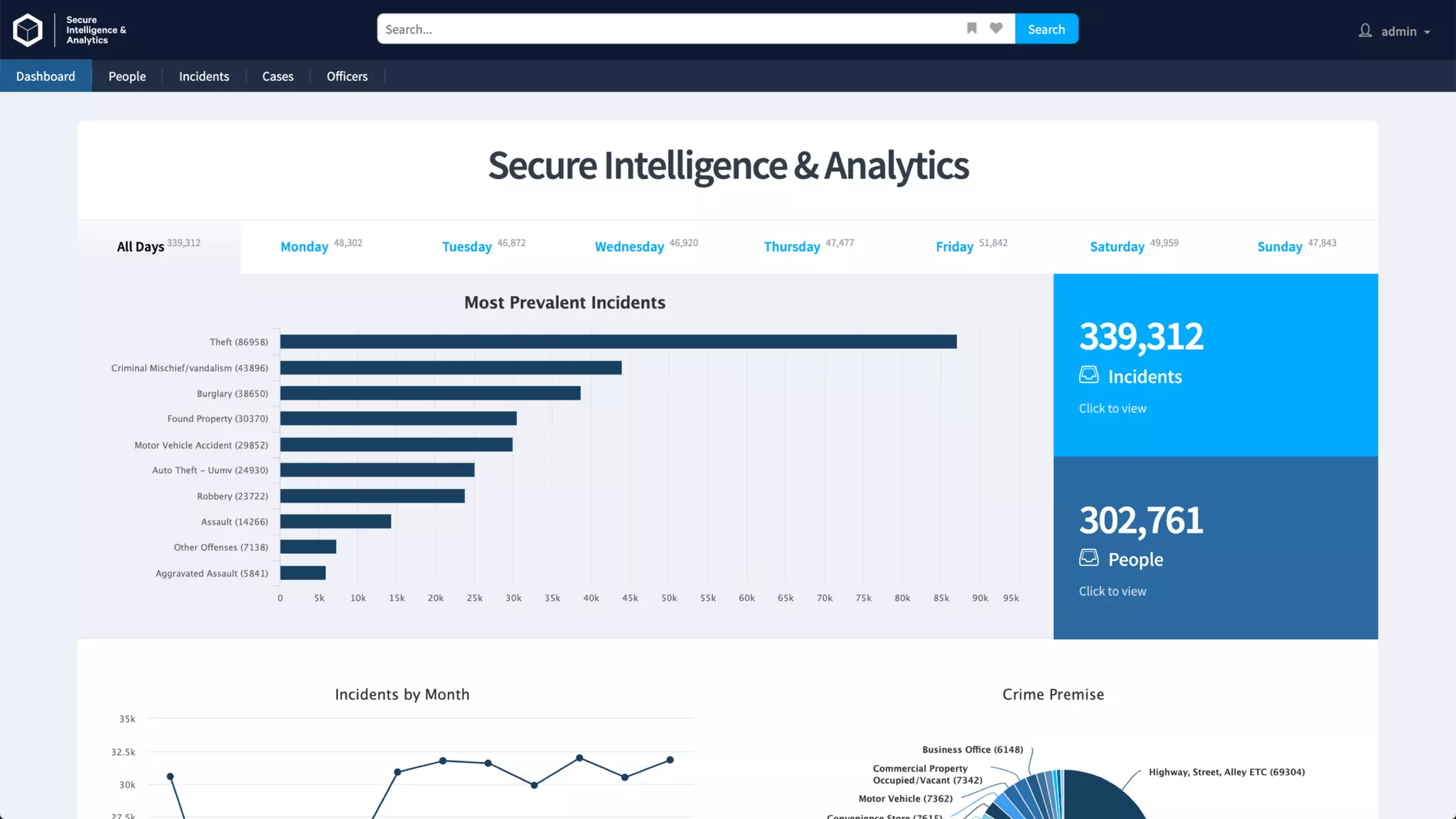
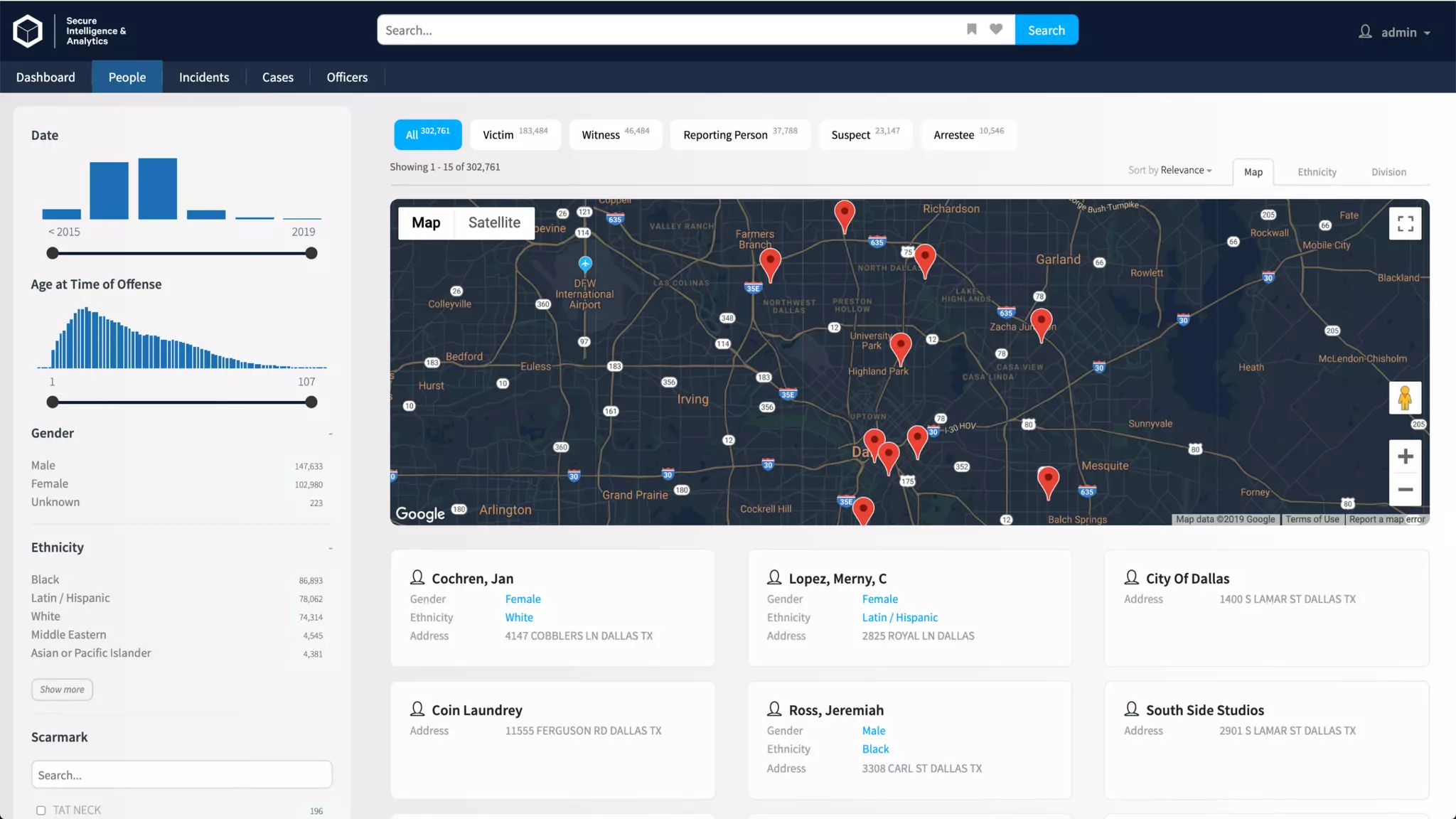
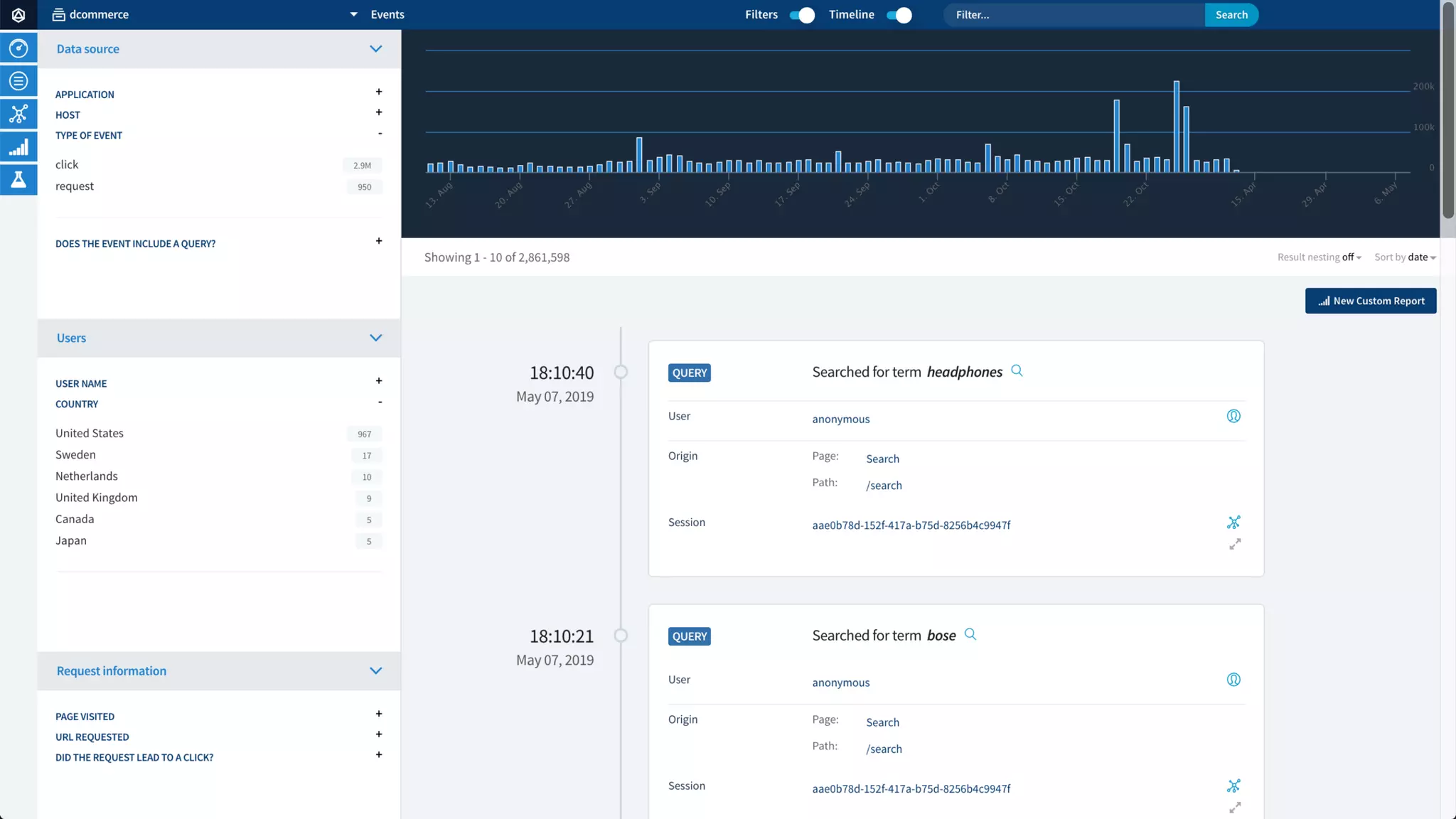
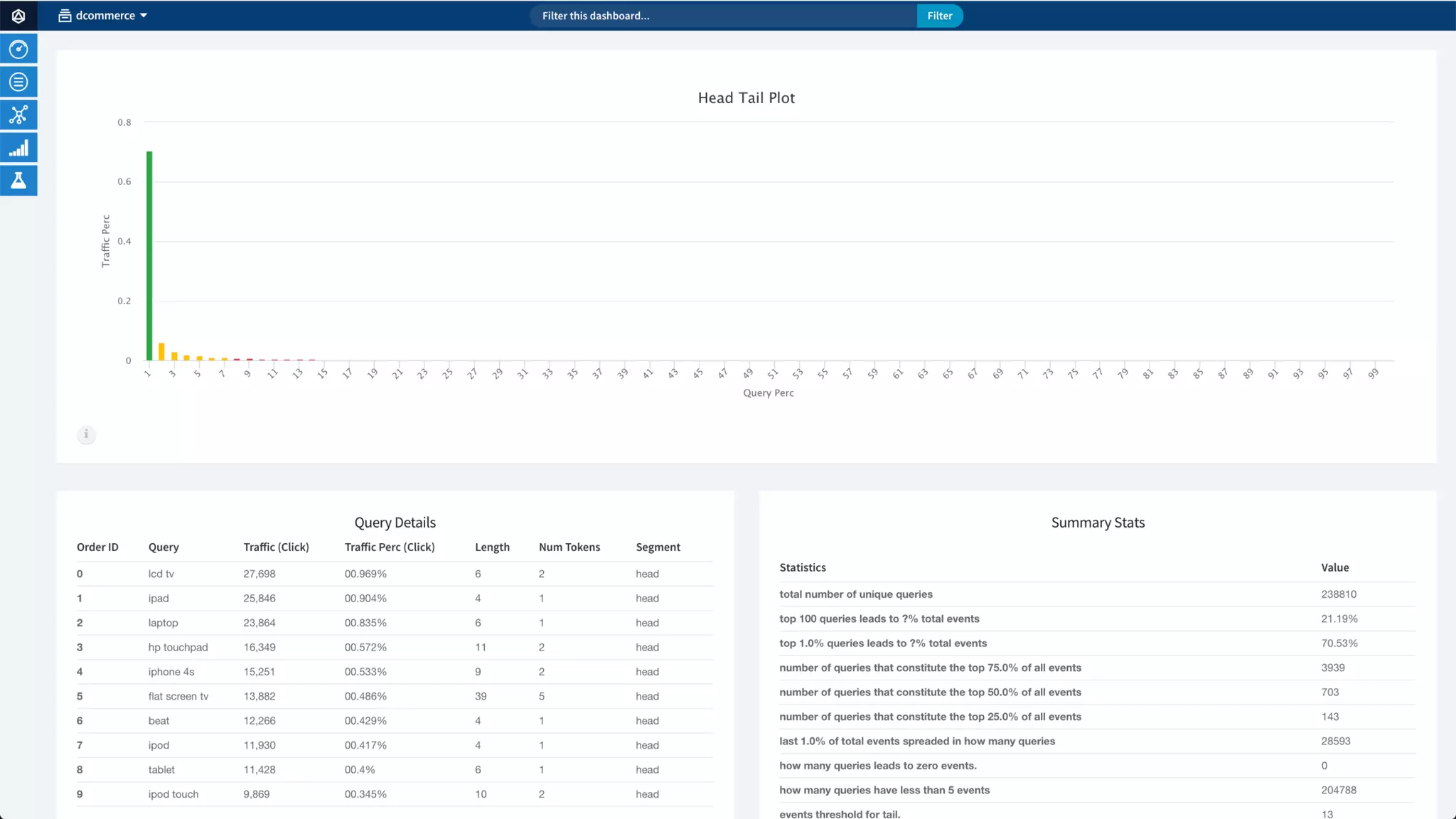
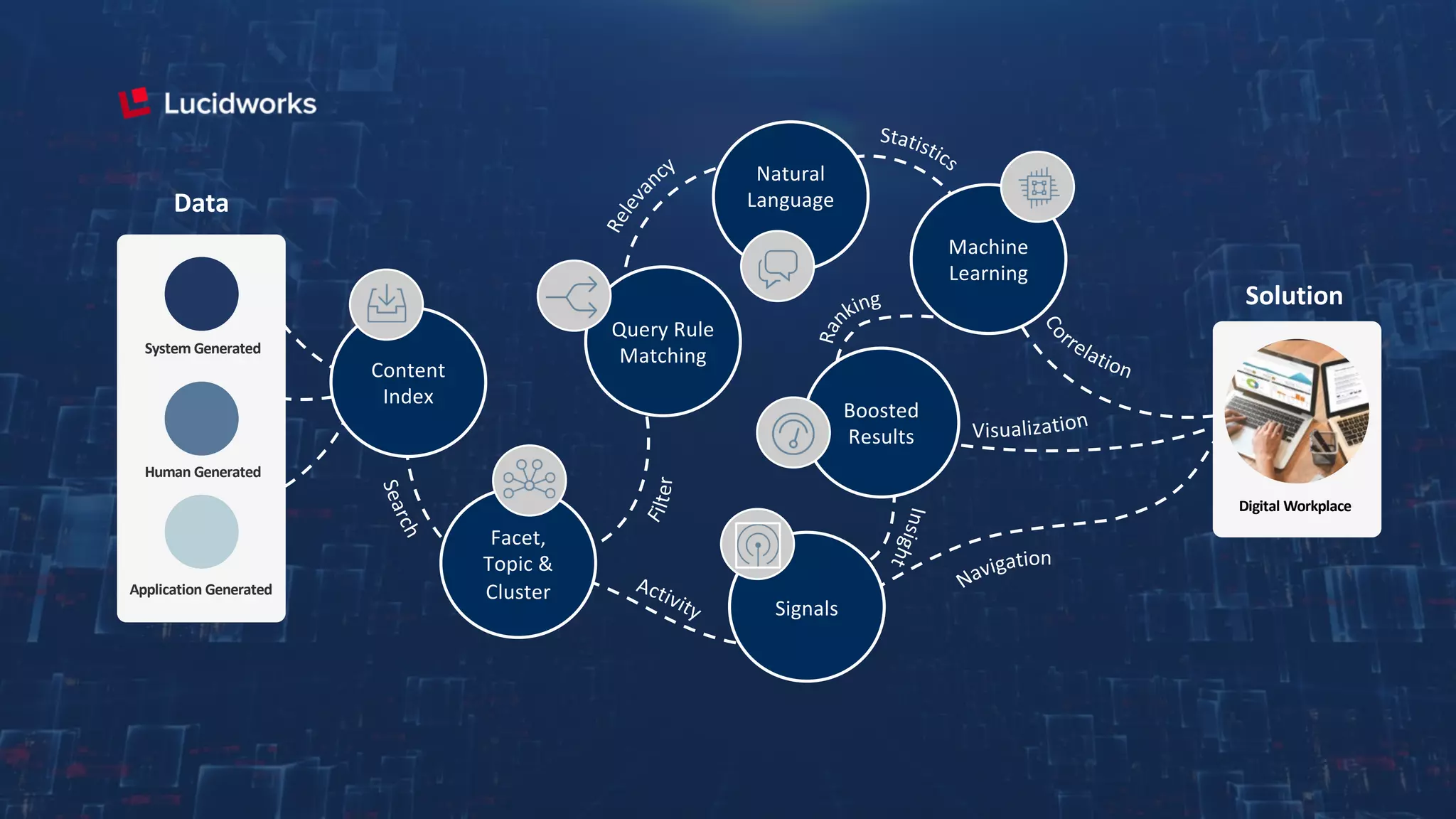
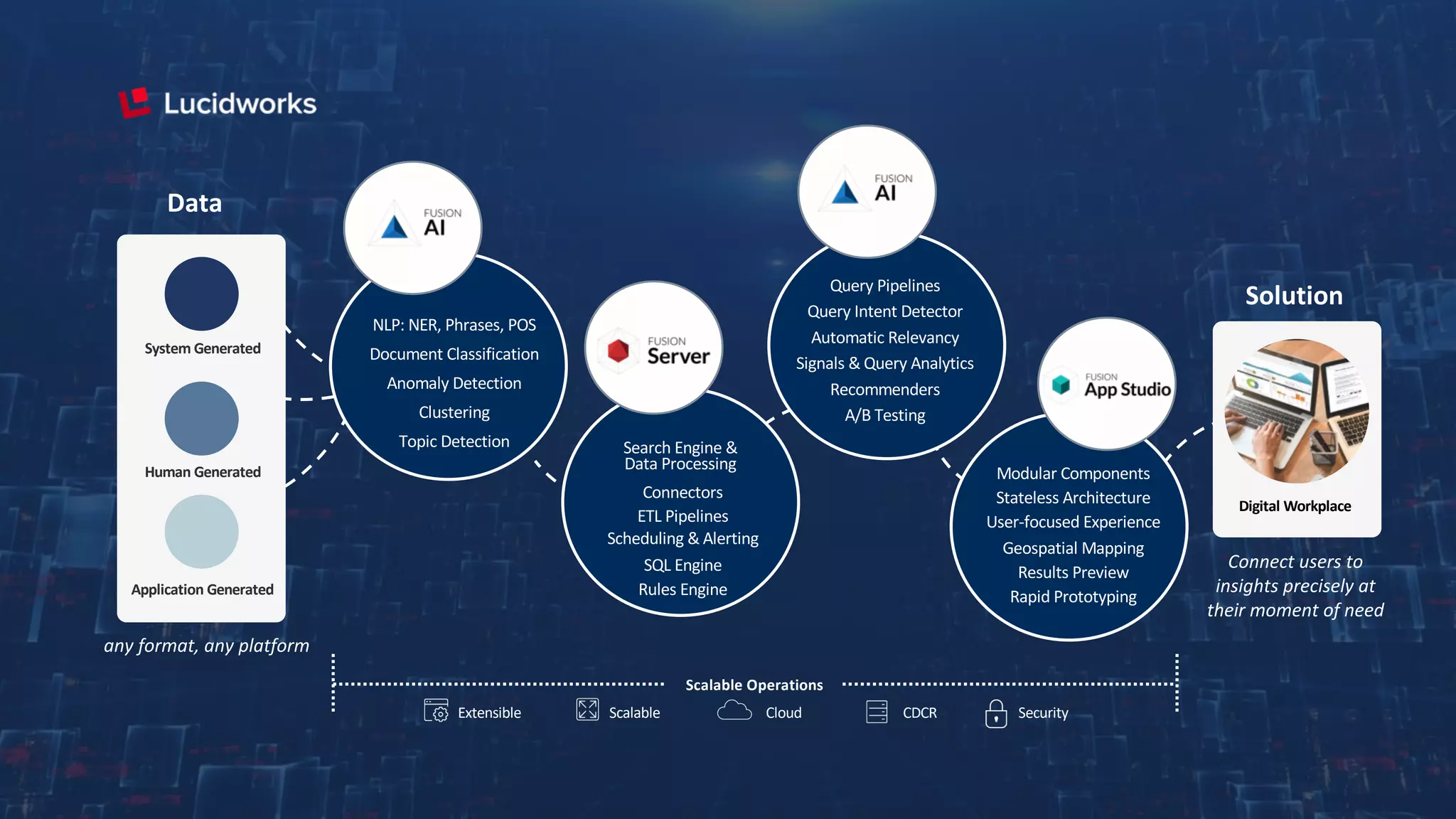
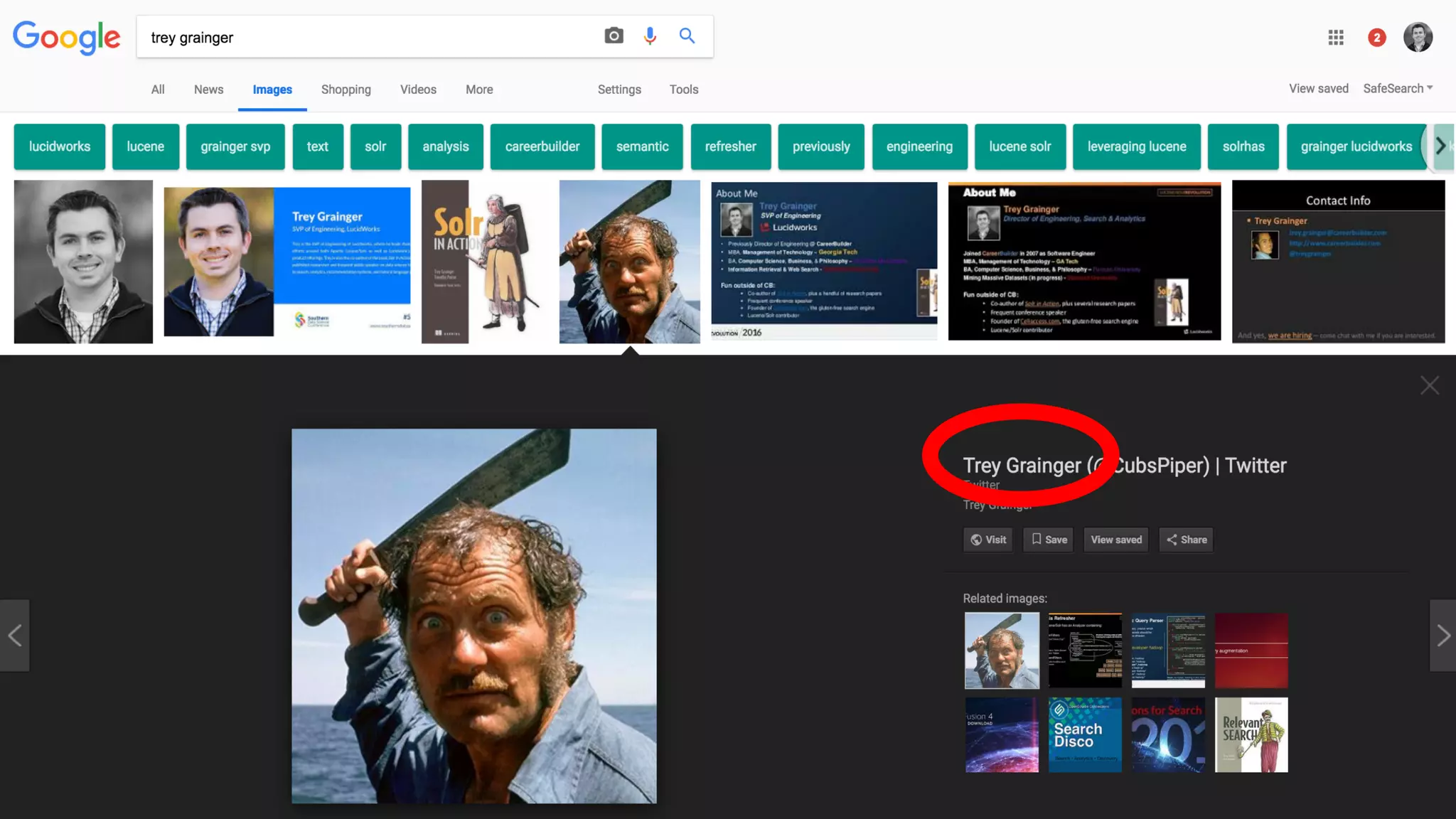
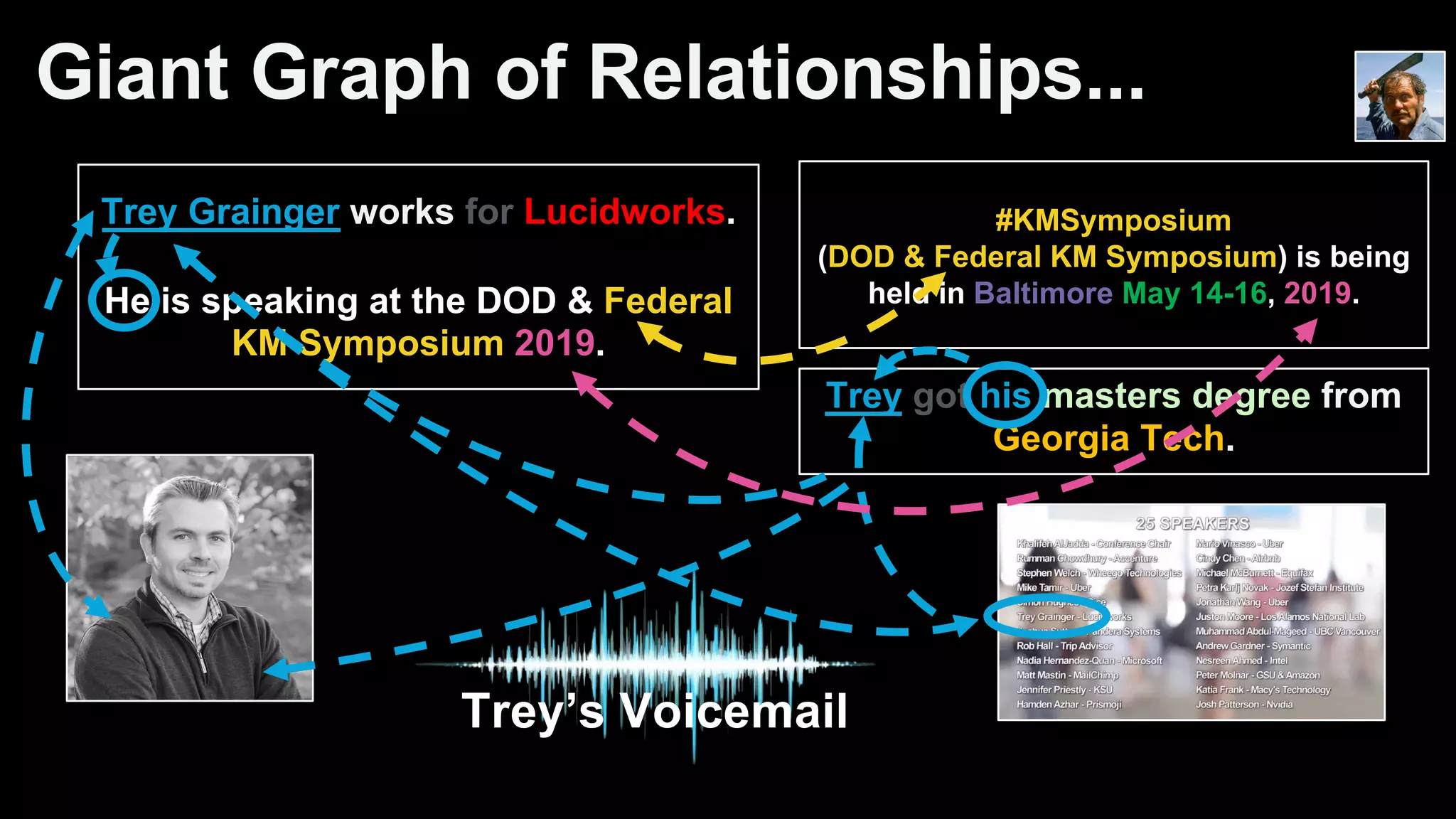
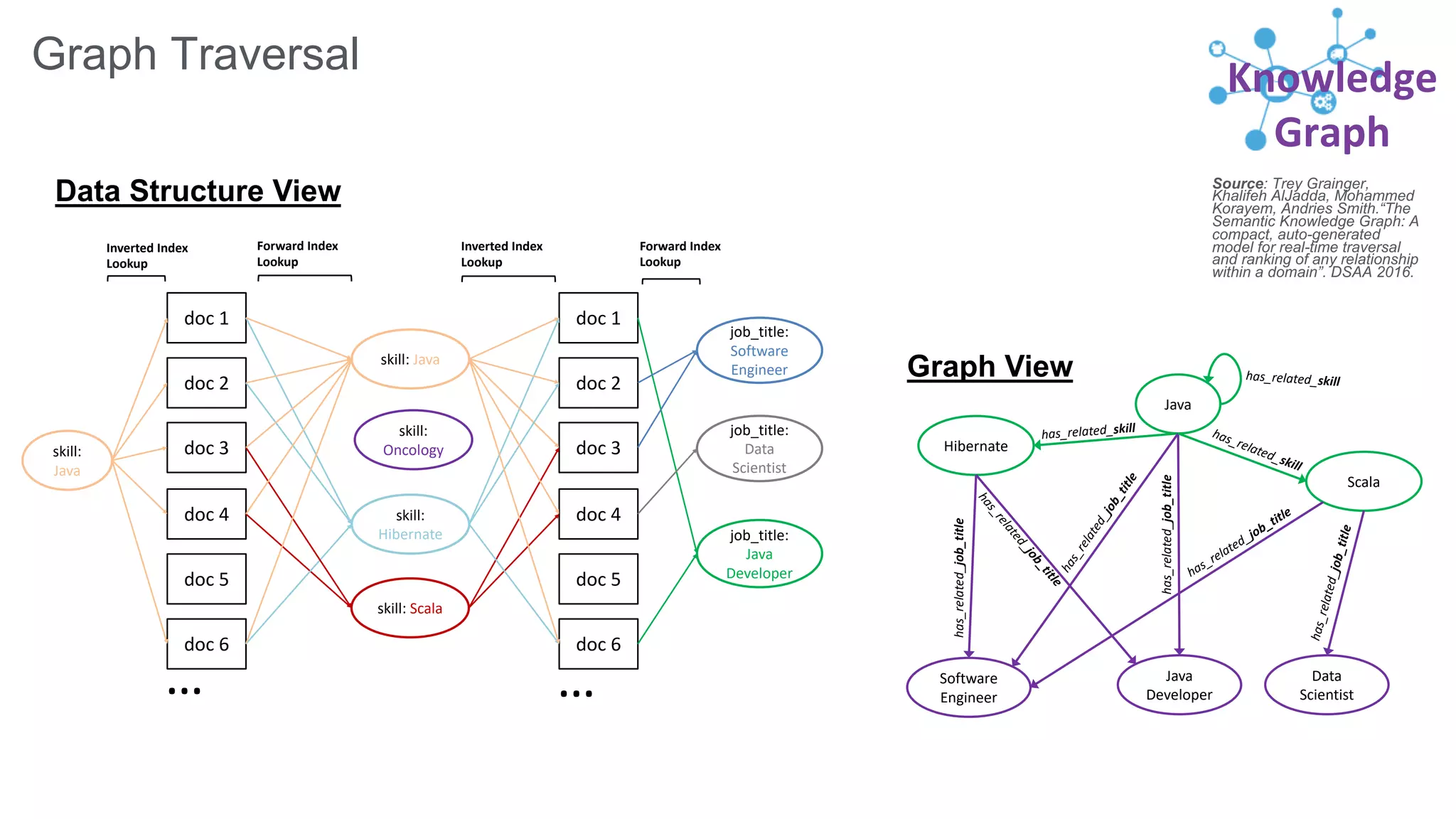
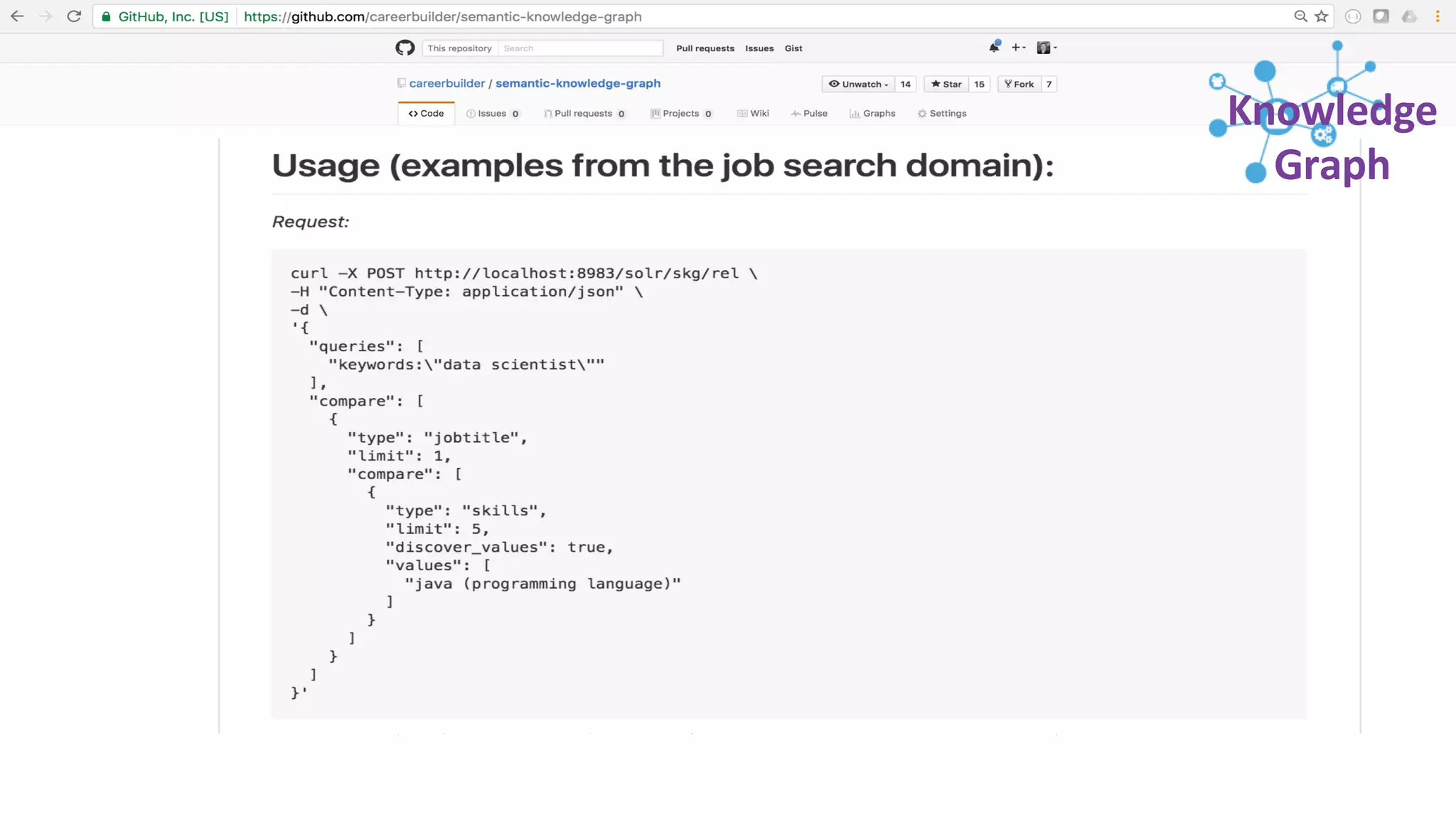
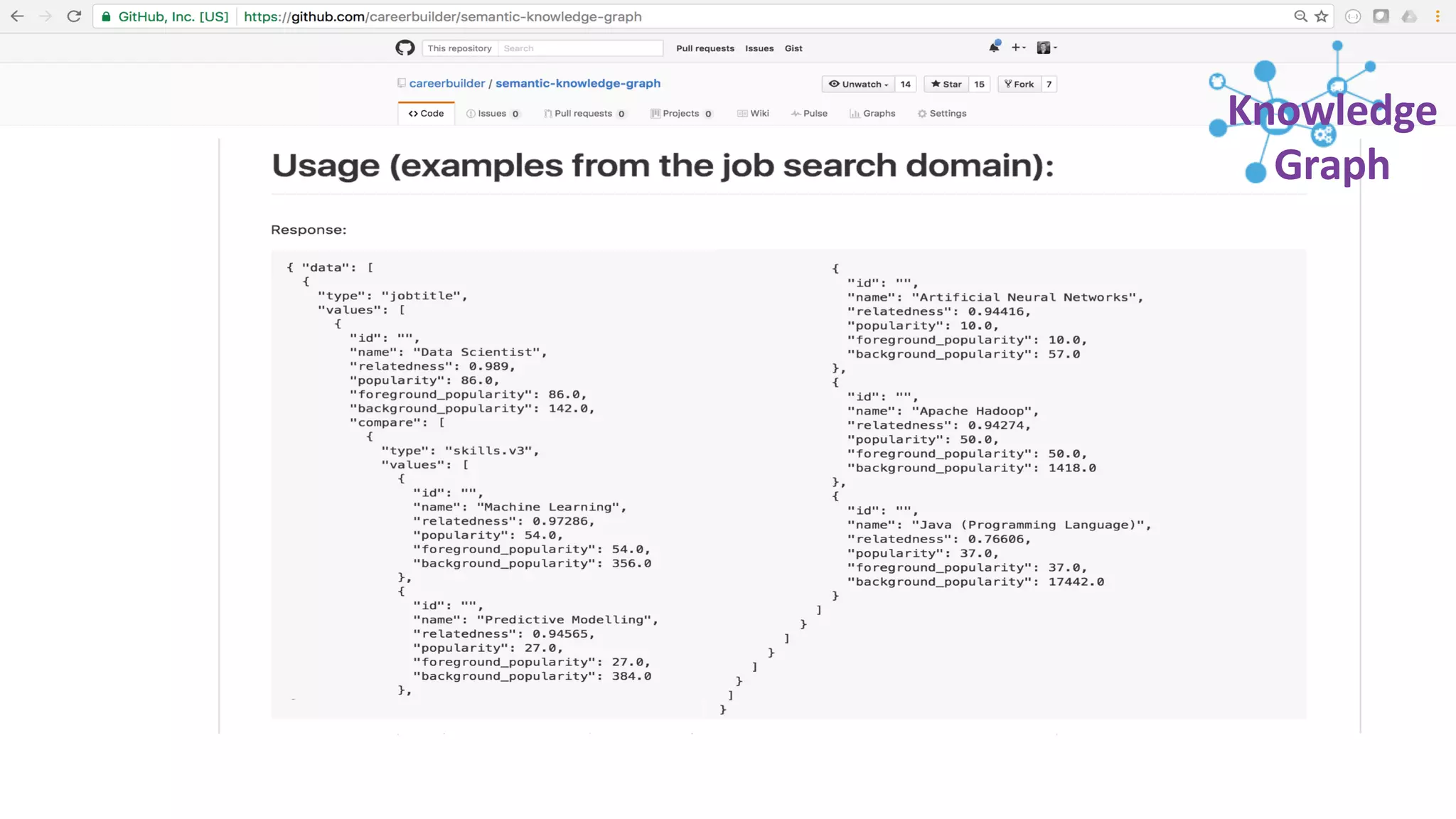
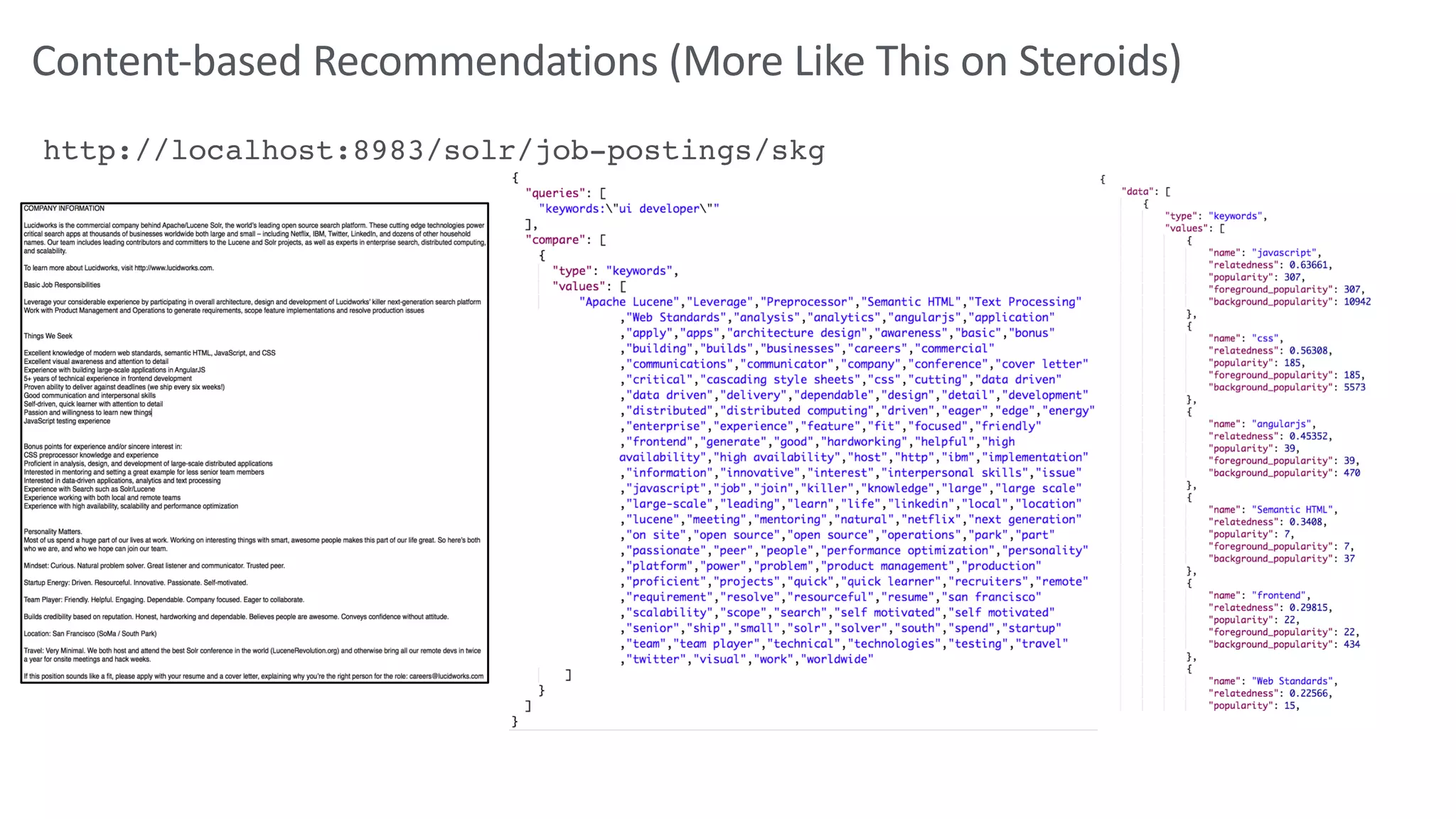
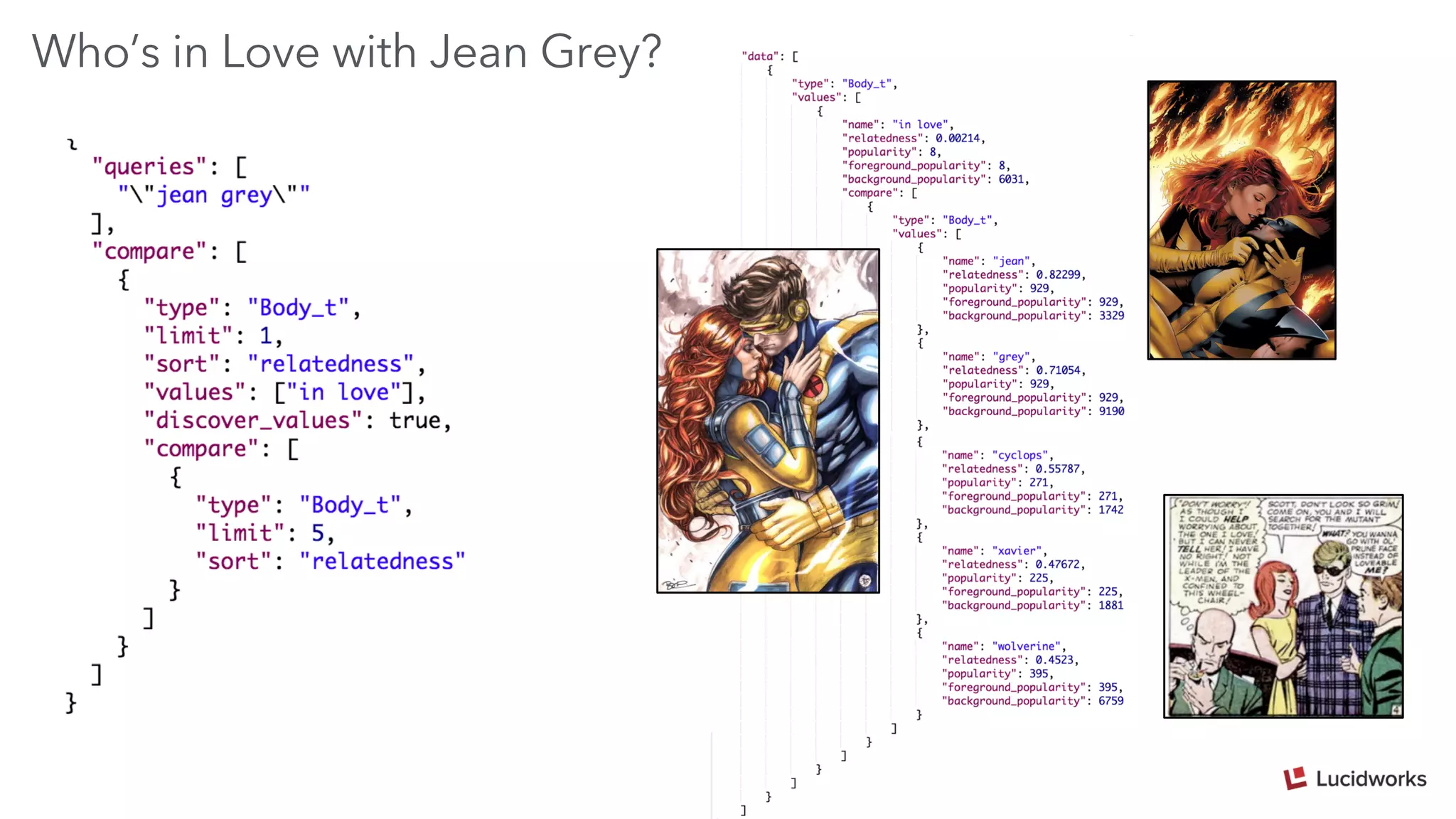
Trey Grainger discussed how search has evolved from basic keyword search to more advanced capabilities like understanding user intent, providing personalized search, and augmented search using machine learning and AI. He explained the concept of "reflected intelligence" where user interactions with search results are used to continuously improve search quality through techniques like signals boosting, learning to rank, and collaborative filtering. Grainger also outlined how knowledge graphs can help power semantic search by modeling relationships between entities to better understand queries and provide more relevant results.



















































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)











