Downloaded 21 times





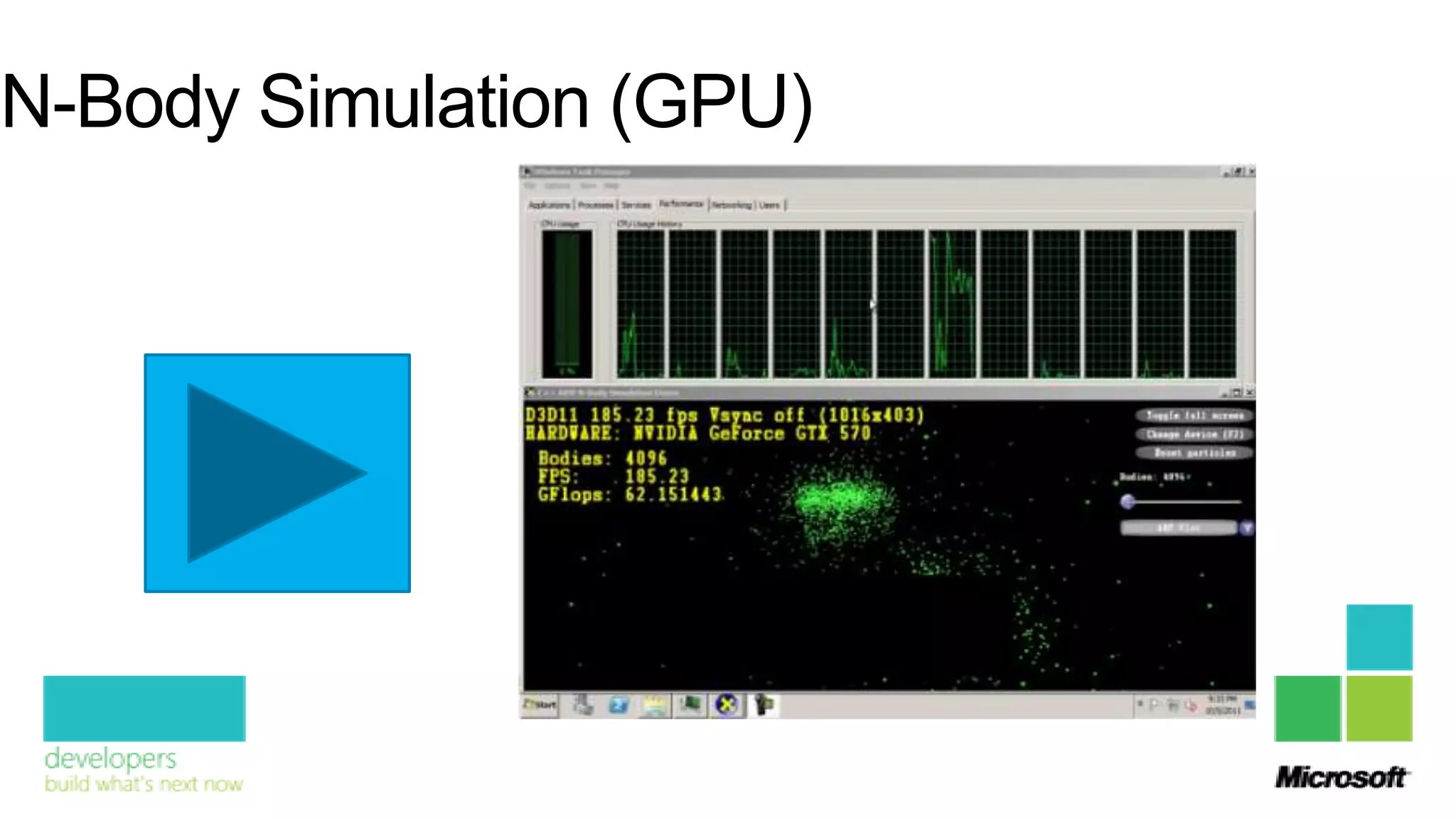
![Vector Processors – How they work
RAX 1.10
SCALAR ADD RAX, RBX RBX 1.20
RAX 2.30
for (int i = 0; i < 1000; ++i) a[i] += b[i ]
XMM1 1.10 2.10 3.10 4.10
VECTOR ADDPS XMM1, XMM2 1.20 2.20 3.20 4.20
XMM2
XMM1 2.30 4.30 6.30 8.30
for (int i = 0; i < 1000; i += 4) a[i : i+3] += b[i : i+3]](https://image.slidesharecdn.com/whatsnewinvisualc11-130411031029-phpapp02/75/What-rsquo-s-new-in-Visual-C-8-2048.jpg)
![Compiler Enhancements
• Auto-vectorizer • Auto-parallelization
• Automatically vectorize loops. – Reorganizes the loop to run
• SIMD instructions. on multiple threads
• ON by default – /Qpar
– Optional #pragma loop
for (i = 0; i < 1024; i++)
a[i] = b[i] * c[i]; #pragma loop(hint_parallel(N))
for (i = 0; i < 1024; i++)
a[i] = b[i] * c[i];
for (i = 0; i < 1024; i += 4)
a[i:i+3] = b[i:i+3] * c[i:i+3];](https://image.slidesharecdn.com/whatsnewinvisualc11-130411031029-phpapp02/75/What-rsquo-s-new-in-Visual-C-10-2048.jpg)

![Source Code Assembly of Body
int A[20000]; $LL3@foo:
mov ecx, DWORD PTR ?C@@3PAHA[eax*4]
int B[20000]; mov edx, DWORD PTR ?B@@3PAHA[eax*4]
int C[20000]; add ecx, edx
mov DWORD PTR ?A@@3PAHA[eax*4], ecx
for (i=0; i<20000; i++) { inc eax
A[i] = B[i] + C[i]; cmp eax, esi
jl SHORT $LL3@foo
}
Dev11 /O2 400% Speedup!!!
Transformation Assembly of Body
int A[20000]; $LL3@foo:
movdqu xmm1, XMMWORD PTR ?C@@3PAHA[eax*4]
int B[20000]; movdqu xmm0, XMMWORD PTR ?B@@3PAHA[eax*4]
int C[20000]; paddd xmm1, xmm0
movdqu XMMWORD PTR ?A@@3PAHA[eax*4], xmm1
for (i=0; i<20000; i+=4) { add eax, 4
A[i:i+3] = B[i:i+3] + C[i:i+3]; cmp eax, ecx
jl SHORT $LL3@foo
}](https://image.slidesharecdn.com/whatsnewinvisualc11-130411031029-phpapp02/75/What-rsquo-s-new-in-Visual-C-13-2048.jpg)
![for (k = 1; k <= M; k++) {
if
if
if xmb
if
for dc[k] 1; dc[k-1] +k++) {
(k = = k <= M; tpdd[k-1];
if ((sc = = dc[k-1] + tpdd[k-1]; dc[k]) dc[k] = sc;
dc[k] mc[k-1] + tpmd[k-1]) >
if (dc[k] <= -INFTY) dc[k] = -INFTY; dc[k]) dc[k] = sc;
if ((sc mc[k-1] + tpmd[k-1]) >
if (dc[k] < -INFTY) dc[k] = -INFTY;
for if (k < M) { M; k++) { {
for (k = 1; k < M; k++)
(k = 1; k <=
if (k < M) =mpp[k] ++tpmi[k];
ic[k] = { mpp[k]
ic[k] tpmi[k];
ic[k] = mpp[k] + tpii[k])
((sc ip[k] tpmi[k];
ifif((sc ==ip[k] ++tpii[k]) >>ic[k]) ic[k] ==sc;
ic[k]) ic[k] sc;
ic[k] += = is[k]; + tpii[k]) > ic[k]) ic[k] = sc;
ic[k] +=is[k];
if ((sc ip[k]
ic[k] += is[k];
ifif(ic[k] <<-INFTY) ic[k] ==-INFTY;
(ic[k] -INFTY) ic[k] -INFTY;
} if (ic[k] < -INFTY) ic[k] = -INFTY;
}} }
}](https://image.slidesharecdn.com/whatsnewinvisualc11-130411031029-phpapp02/75/What-rsquo-s-new-in-Visual-C-14-2048.jpg)



 restrict(direct3d)
{
{ { va[i] = vb[i] + vc[i];
a[i] = b[i] + c[i]; } pC[i] = pA[i] + pB[i];
} ); }
}
} }](https://image.slidesharecdn.com/whatsnewinvisualc11-130411031029-phpapp02/75/What-rsquo-s-new-in-Visual-C-19-2048.jpg)
 restrict(direct3d)
execute the lambda {
va[i] = vb[i] + vc[i];
} array_view variables captured
); and associated data copied to
index: the thread ID that is running the
} accelerator (on demand)
lambda, used to index into data](https://image.slidesharecdn.com/whatsnewinvisualc11-130411031029-phpapp02/75/What-rsquo-s-new-in-Visual-C-20-2048.jpg)
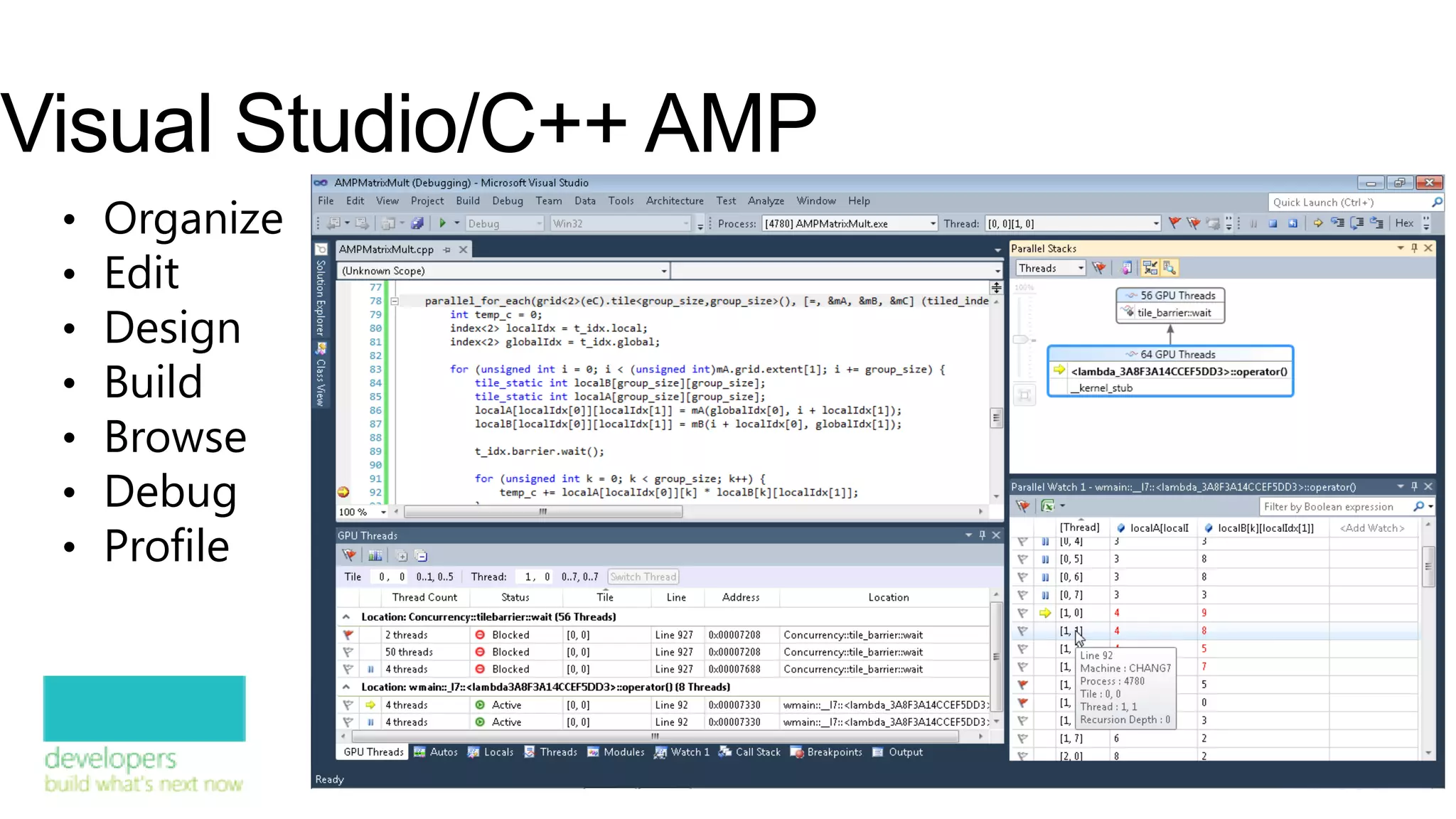
![Achieving maximum performance gains
• Schedule threads in tiles 0 1 2 3 4 5 0 1 2 3 4 5
• Avoid thread index remapping 0 0
• Gain ability to use tile static memory
1 1
2 2
3 3
4 4
array_view<int,2> data(8, 6, p_my_data); 5 5
parallel_for_each( 6 6
data.grid.tile<2,2>(), 7 7
[=] (tiled_index<2,2> t_idx)… { … }); g.tile<4,3>() g.tile<2,2>()](https://image.slidesharecdn.com/whatsnewinvisualc11-130411031029-phpapp02/75/What-rsquo-s-new-in-Visual-C-21-2048.jpg)




 ){
cout << **i << “ is a matchn”; if( s && *s == *p )
} cout << *s << “ is a matchn”;
for( vector<circle*>::iterator i = v.begin(); i != v.end(); ++i ) } ); for/while/do
{ std:: algorithms
delete *i; [&] lambda functions
no need for “delete”
} not exception-safe
automatic lifetime
delete p; missing try/catch, management
__try/__finally
exception-safe](https://image.slidesharecdn.com/whatsnewinvisualc11-130411031029-phpapp02/75/What-rsquo-s-new-in-Visual-C-27-2048.jpg)





![lambdas – functions with no name
[ ] ( ) -> int { return 42; } ; // no arguments
[ ] (int n) -> int { return n * n; } ; // one argument
[ ] (int a, int b) -> int { return a + b; } ; // two arguments
for_each(v.begin(), v.end(), [ ] (int n) { cout << n << “ “; }); // one-liner
float f1 = integrate ( golden, 0.0, 1.0 );
float f2 = integrate ( [ ] (float x ) { return x * x + x – 1; }, 0.0, 1.0 );
[ ] { cout << “hi” } // can omit ( ) if no parameters
// can omit -> return-type if inferable
[ capture-clause] ( parameter-list ) -> return-type { body }// grammar](https://image.slidesharecdn.com/whatsnewinvisualc11-130411031029-phpapp02/75/What-rsquo-s-new-in-Visual-C-34-2048.jpg)




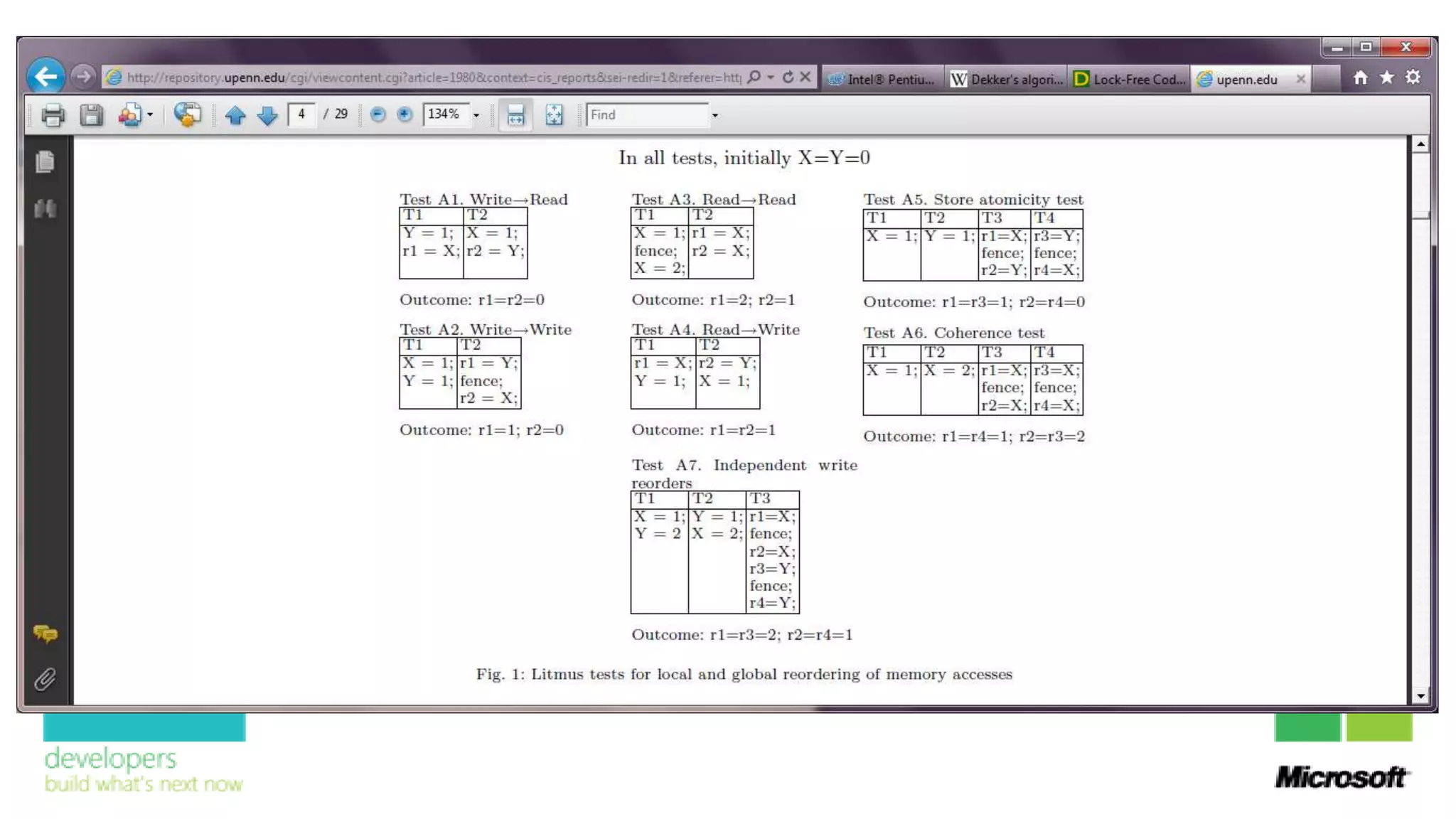
![Dekker’s Algorithm
flag[0] := true flag[1] := true
while flag[1] = true { while flag[0] = true {
if turn ≠ 0 { if turn ≠ 1 {
flag[0] := false flag[1] := false
while turn ≠ 0 { } while turn ≠ 1 { }
flag[0] := true flag[1] := true
} }
} }
// critical section // critical section
turn := 1 turn := 0
flag[0] := false flag[1] := false](https://image.slidesharecdn.com/whatsnewinvisualc11-130411031029-phpapp02/75/What-rsquo-s-new-in-Visual-C-39-2048.jpg)
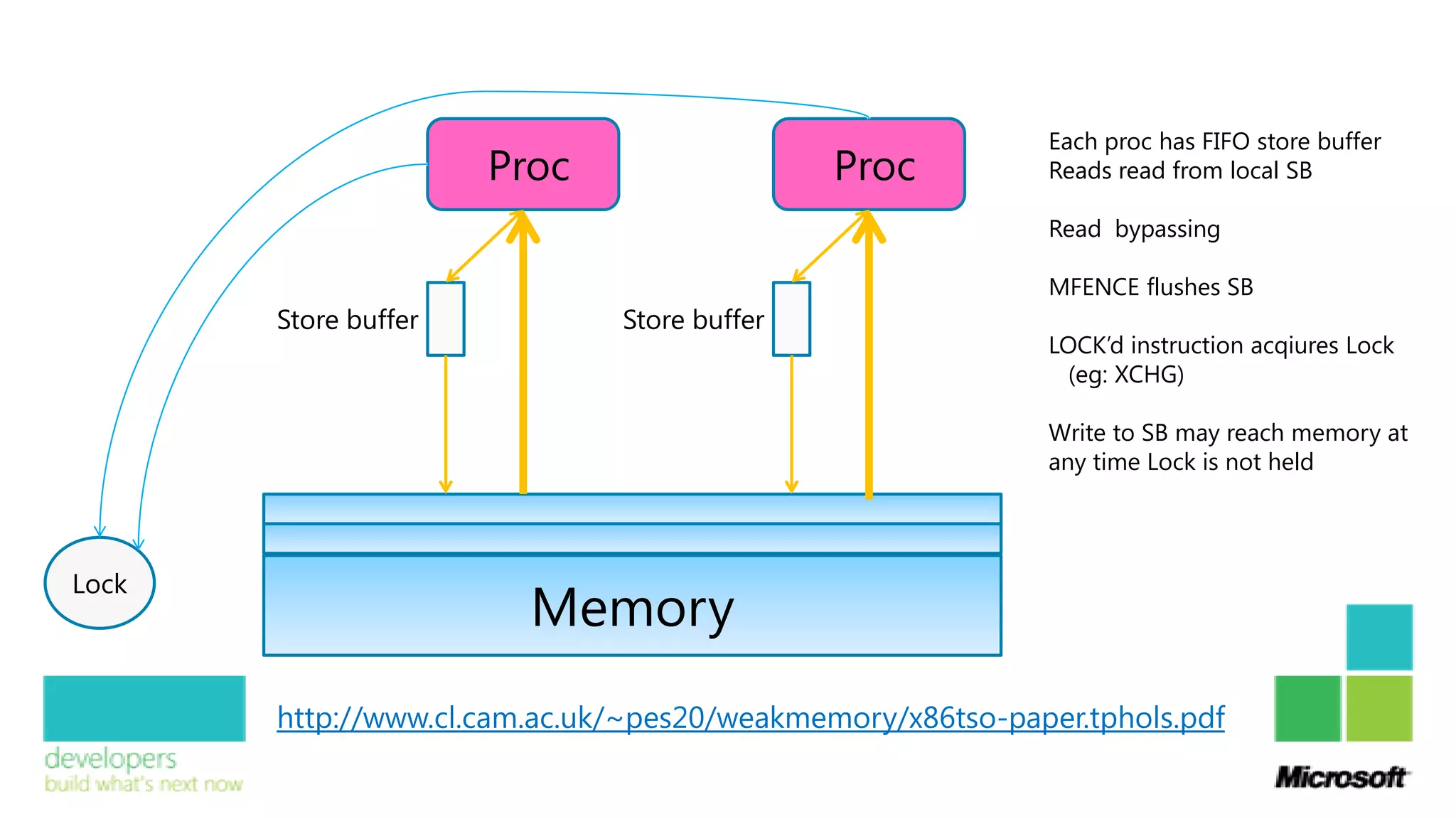








The document presents an overview of the advancements in Visual C++ 11, emphasizing the power and performance of C++ for modern computing, including both CPU and GPU optimizations. It covers key features, such as ISO C++ 11 enhancements, C++ AMP for heterogeneous computing, and improvements in auto-vectorization and parallelization. Additionally, it illustrates the potential performance benefits and high-level abstractions that C++ now offers developers through its integration with Visual Studio.







![[JavaOne 2011] Models for Concurrent Programming](https://cdn.slidesharecdn.com/ss_thumbnails/24881-modelsforconcurrentprogramming-111019034625-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)












































![[01][gpu 컴퓨팅을 위한 언어, 도구 및 api] miller languages tools](https://cdn.slidesharecdn.com/ss_thumbnails/01gpuapimillerlanguagestools-110106231409-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)










![[05][cuda 및 fermi 최적화 기술] hryu optimization](https://cdn.slidesharecdn.com/ss_thumbnails/05cudafermihryuoptimization-110106231451-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)










































