Downloaded 192 times
![Machine Learning with
Apache Hama
Tommaso Teofili
tommaso [at] apache [dot] org
1](https://image.slidesharecdn.com/mlwhama2-121107065829-phpapp01/85/Machine-learning-with-Apache-Hama-1-320.jpg)
![Machine Learning with
Apache Hama
Tommaso Teofili
tommaso [at] apache [dot] org
1](https://image.slidesharecdn.com/mlwhama2-121107065829-phpapp01/75/Machine-learning-with-Apache-Hama-1-2048.jpg)



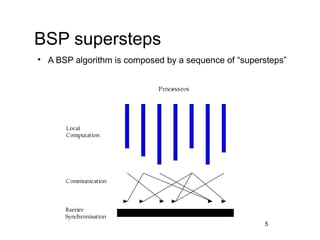


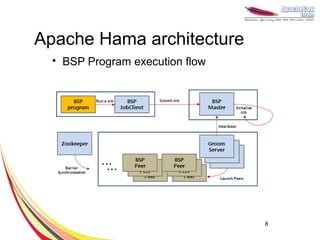
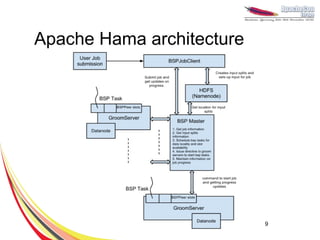




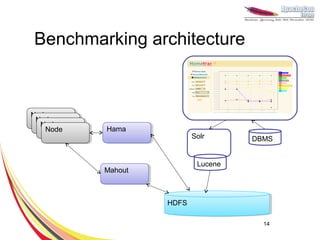





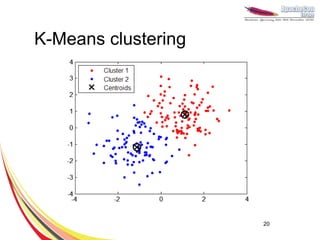

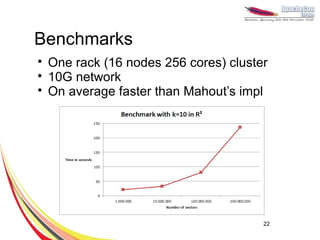

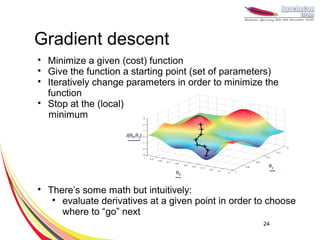



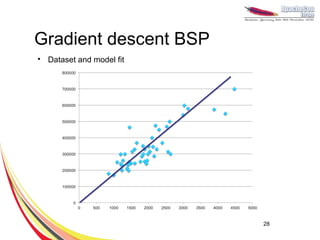
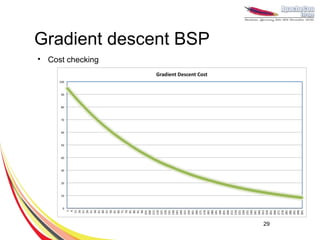

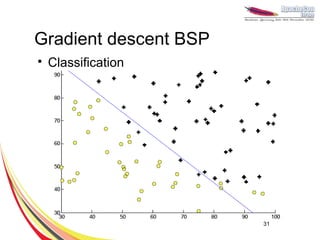




This document discusses machine learning with Apache Hama, a Bulk Synchronous Parallel computing framework. It provides an overview of Apache Hama and BSP, explains why machine learning algorithms are well-suited for BSP, and gives examples of collaborative filtering, k-means clustering, and gradient descent implemented on Hama. Benchmark results show Hama performs comparably to Apache Mahout for these algorithms.





























































































