Downloaded 359 times
![Apache UIMA and
Metadata Generation
Gestione delle Informazioni su Web - 2009/2010
Tommaso Teofili
tommaso [at] apache [dot] org
mercoledì 14 aprile 2010](https://image.slidesharecdn.com/uima2-100414092756-phpapp01/75/Apache-UIMA-and-Metadata-Generation-1-2048.jpg)





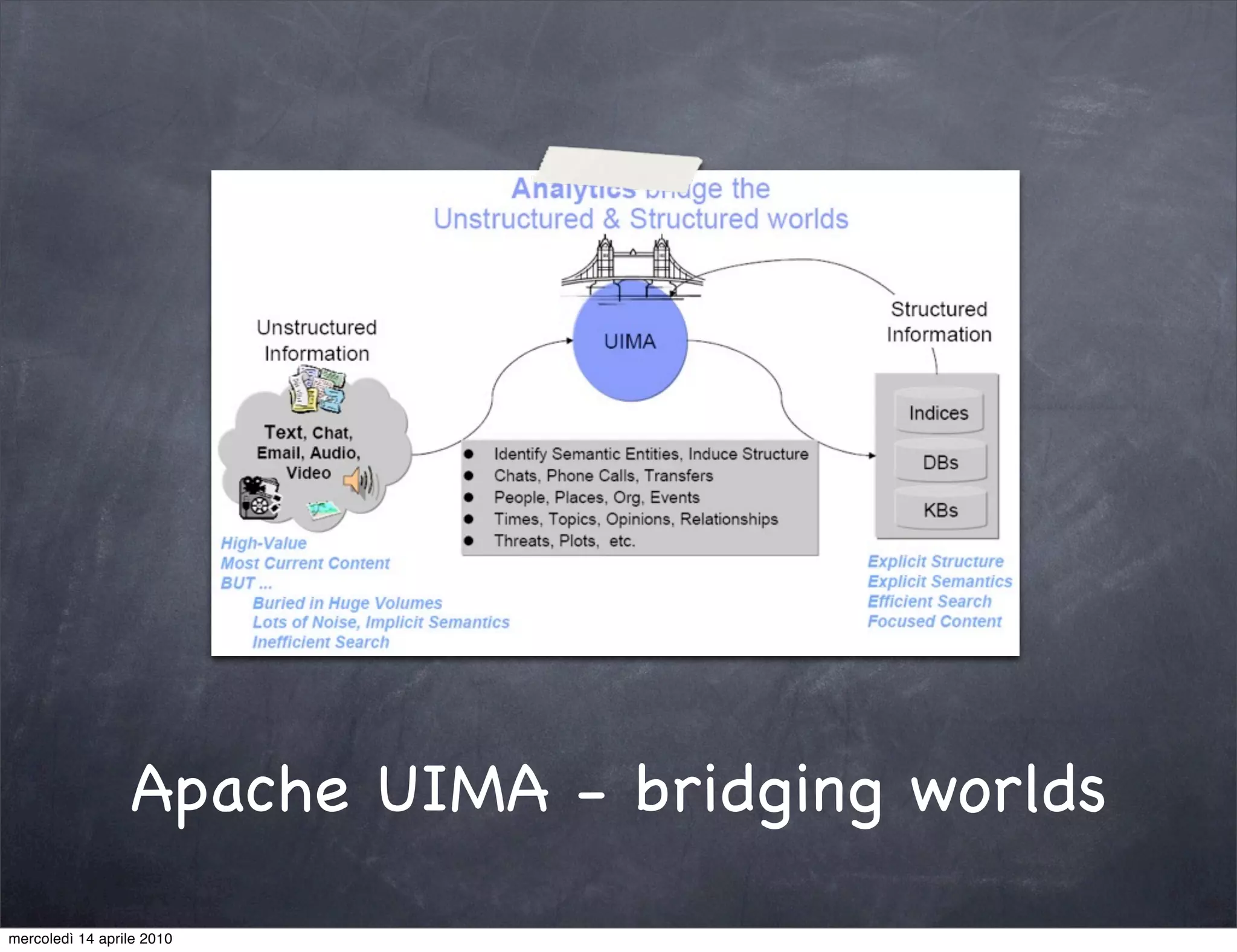





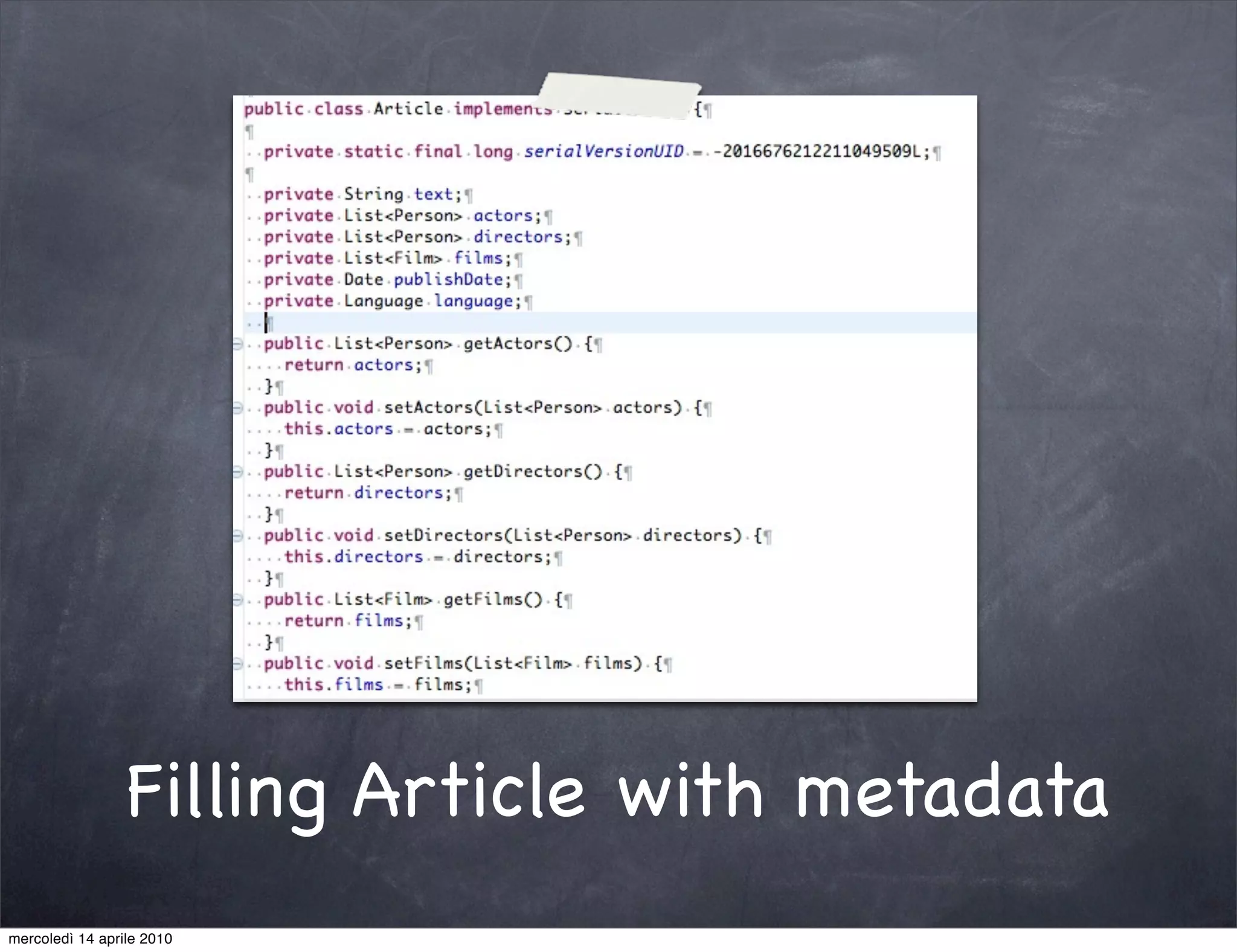

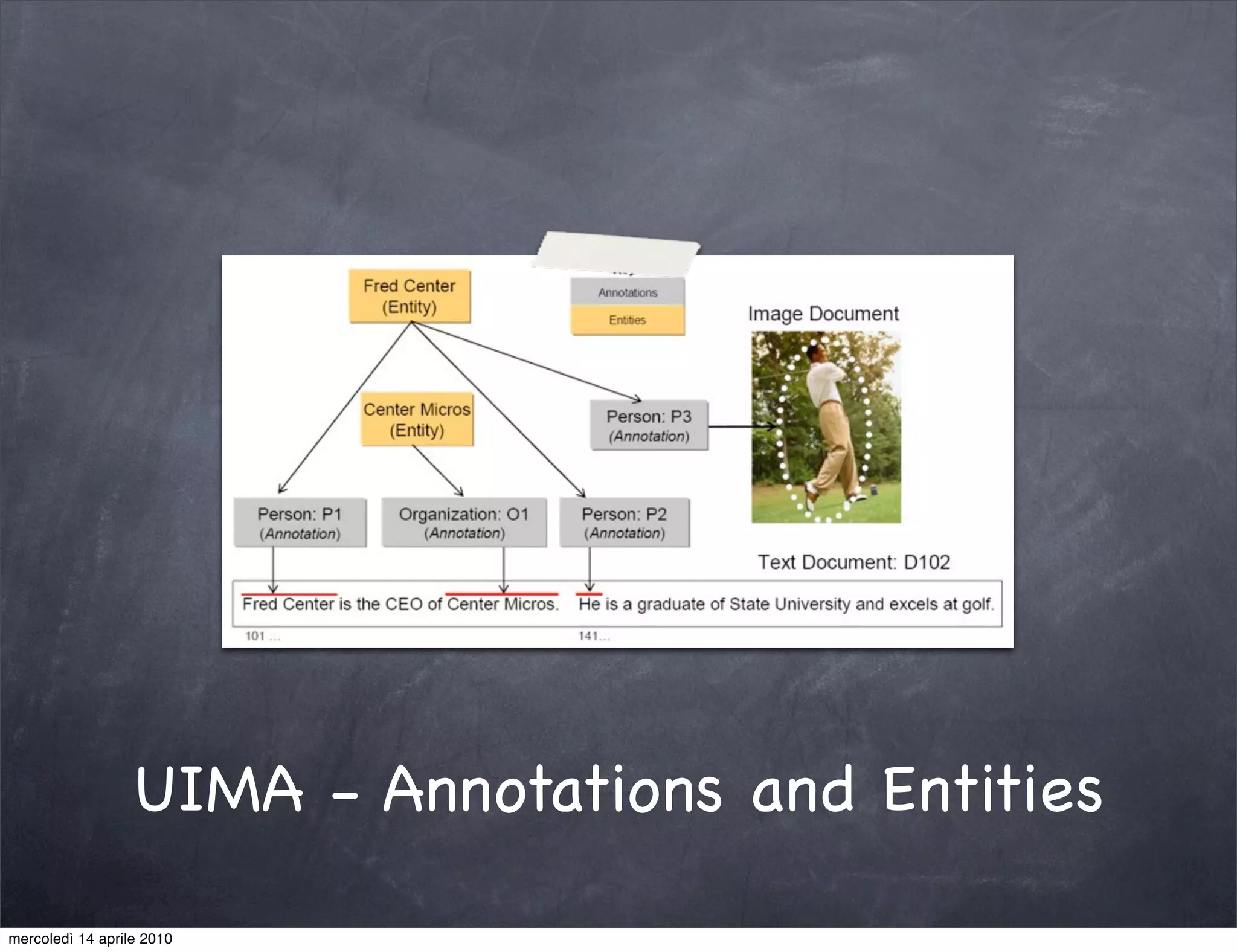











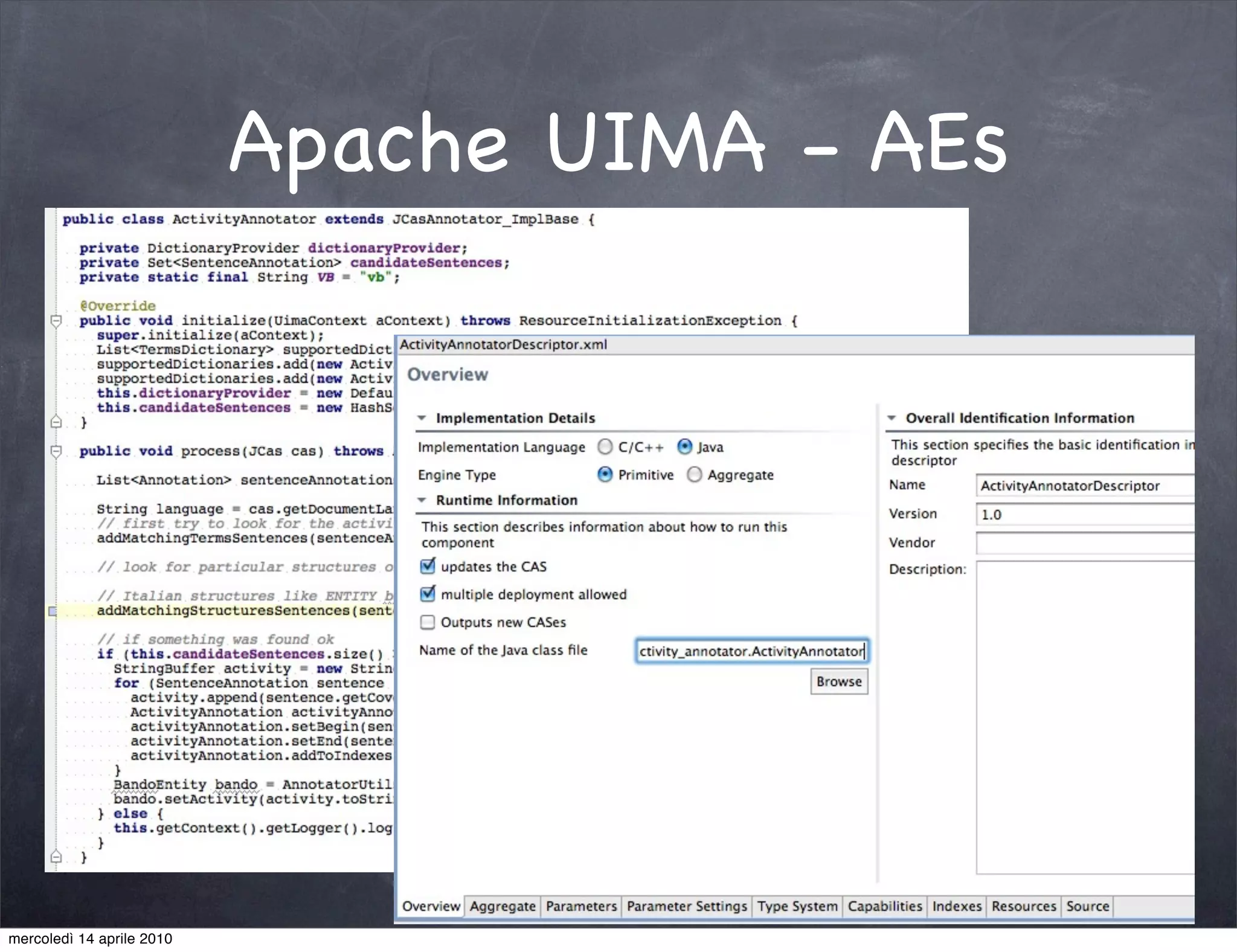
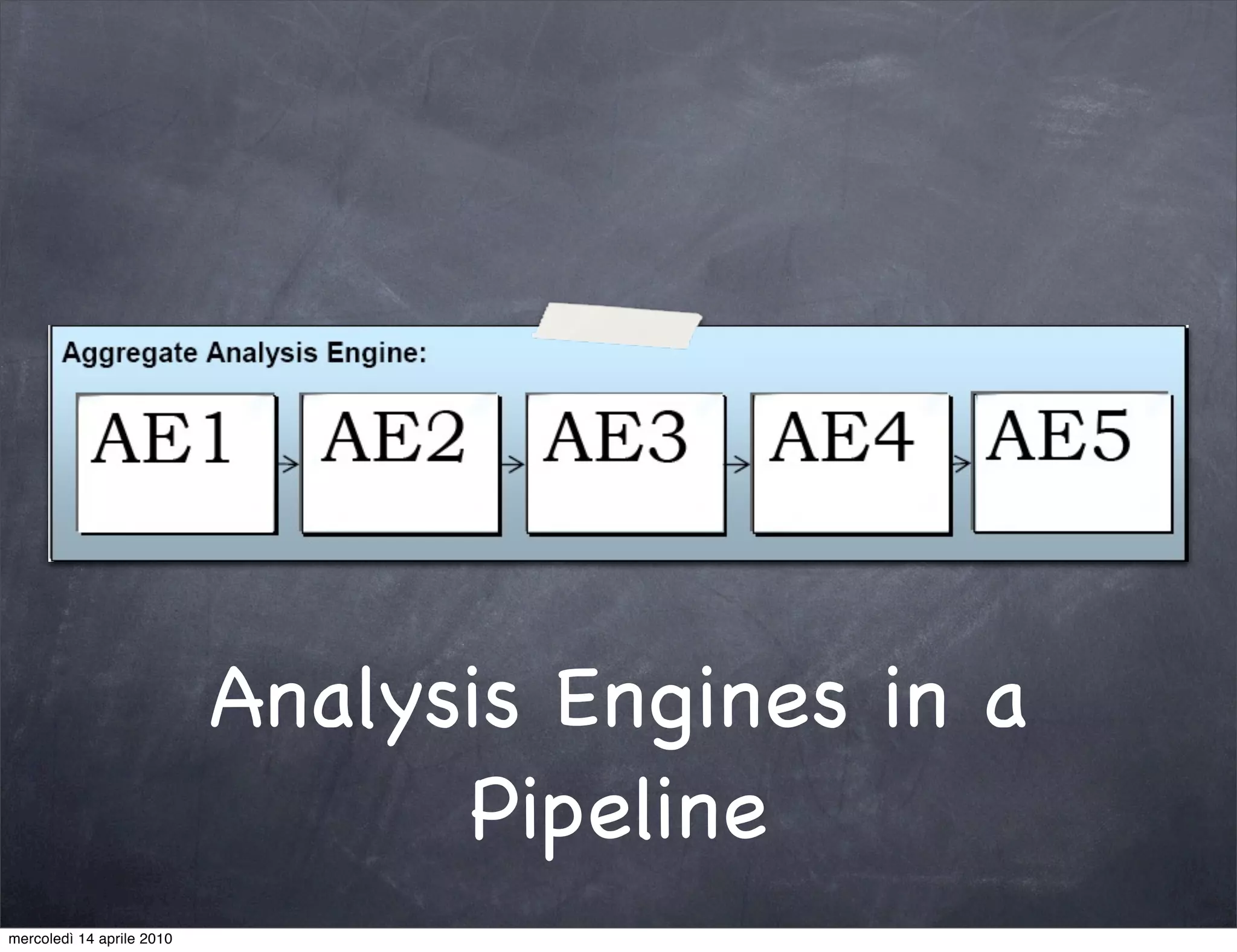

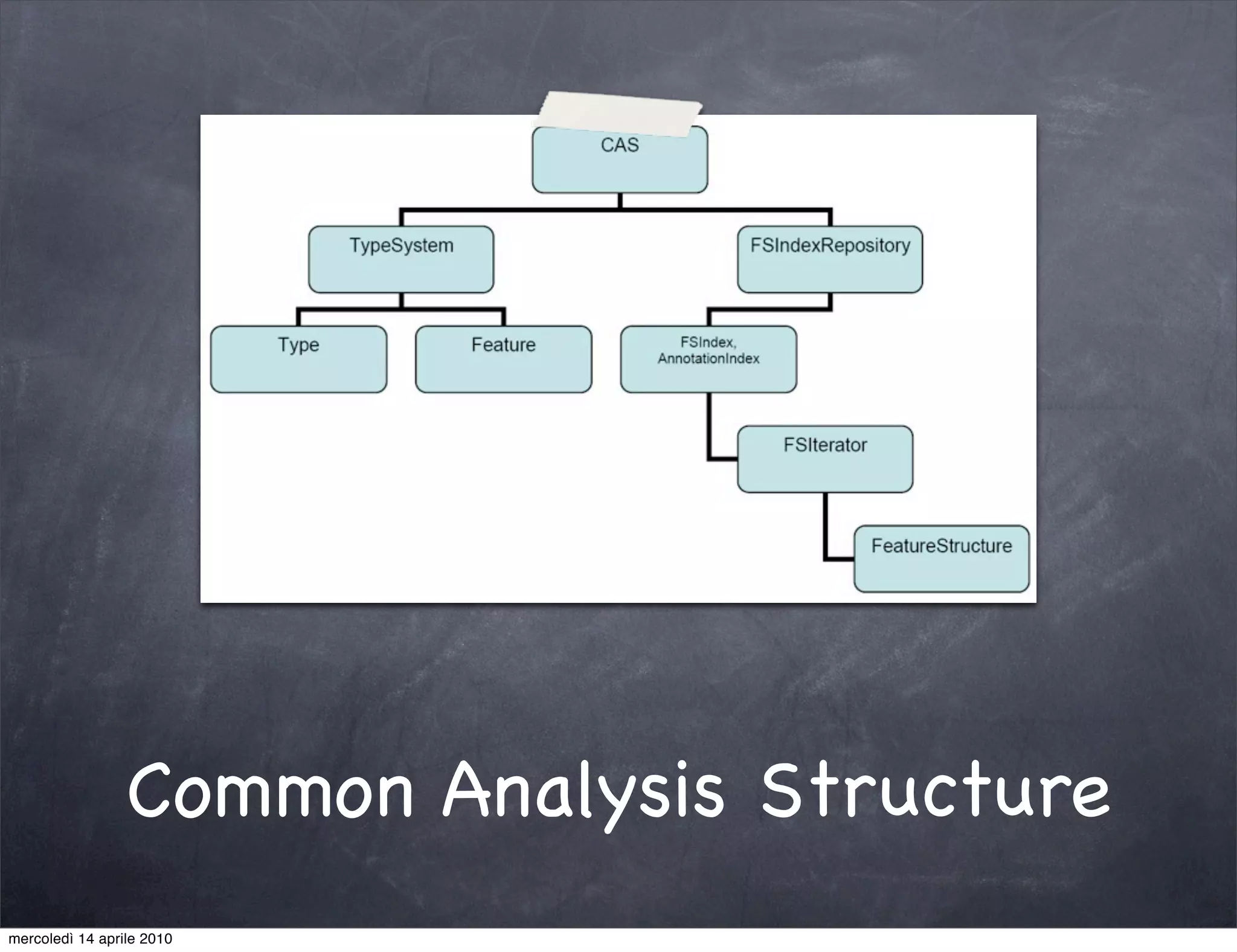





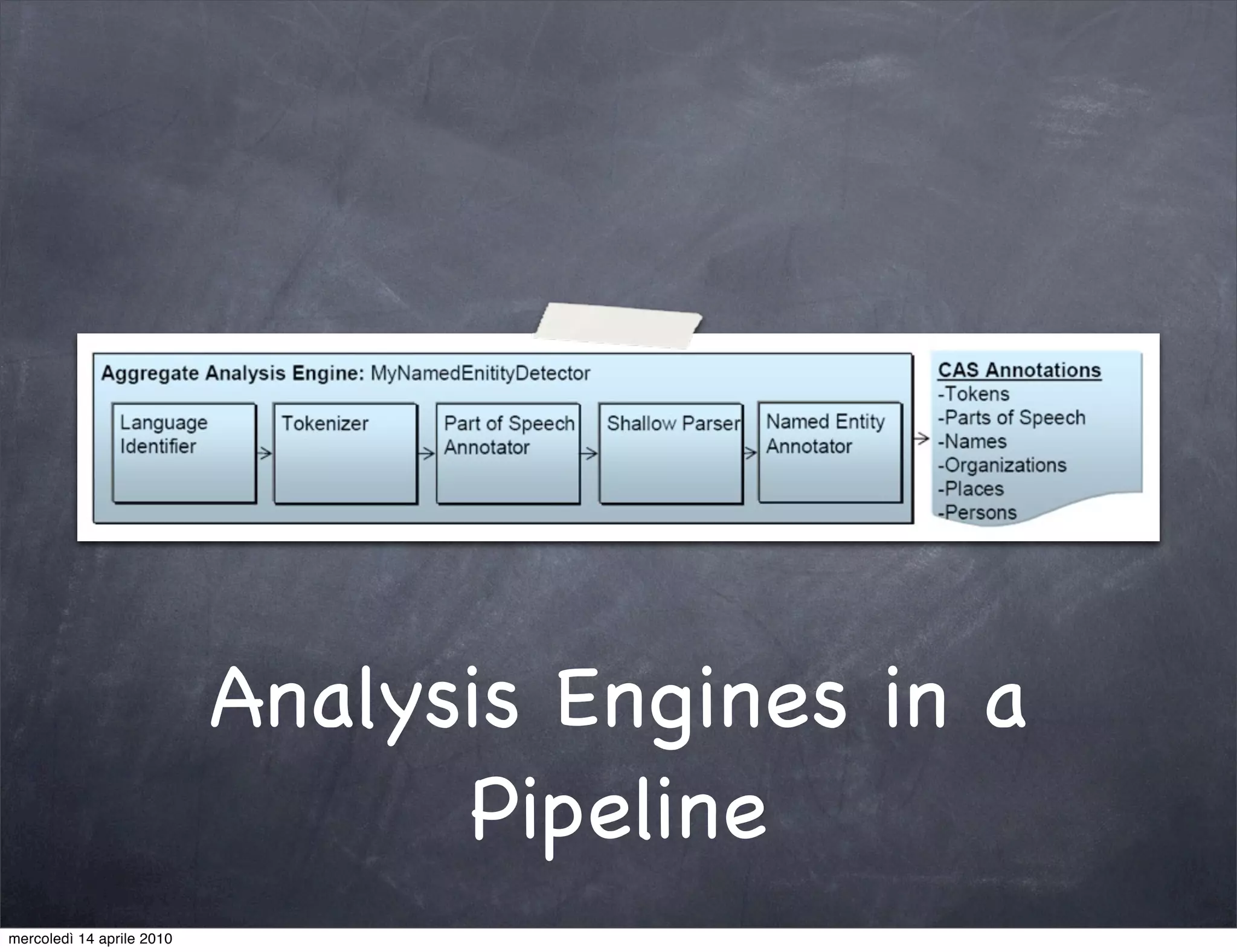


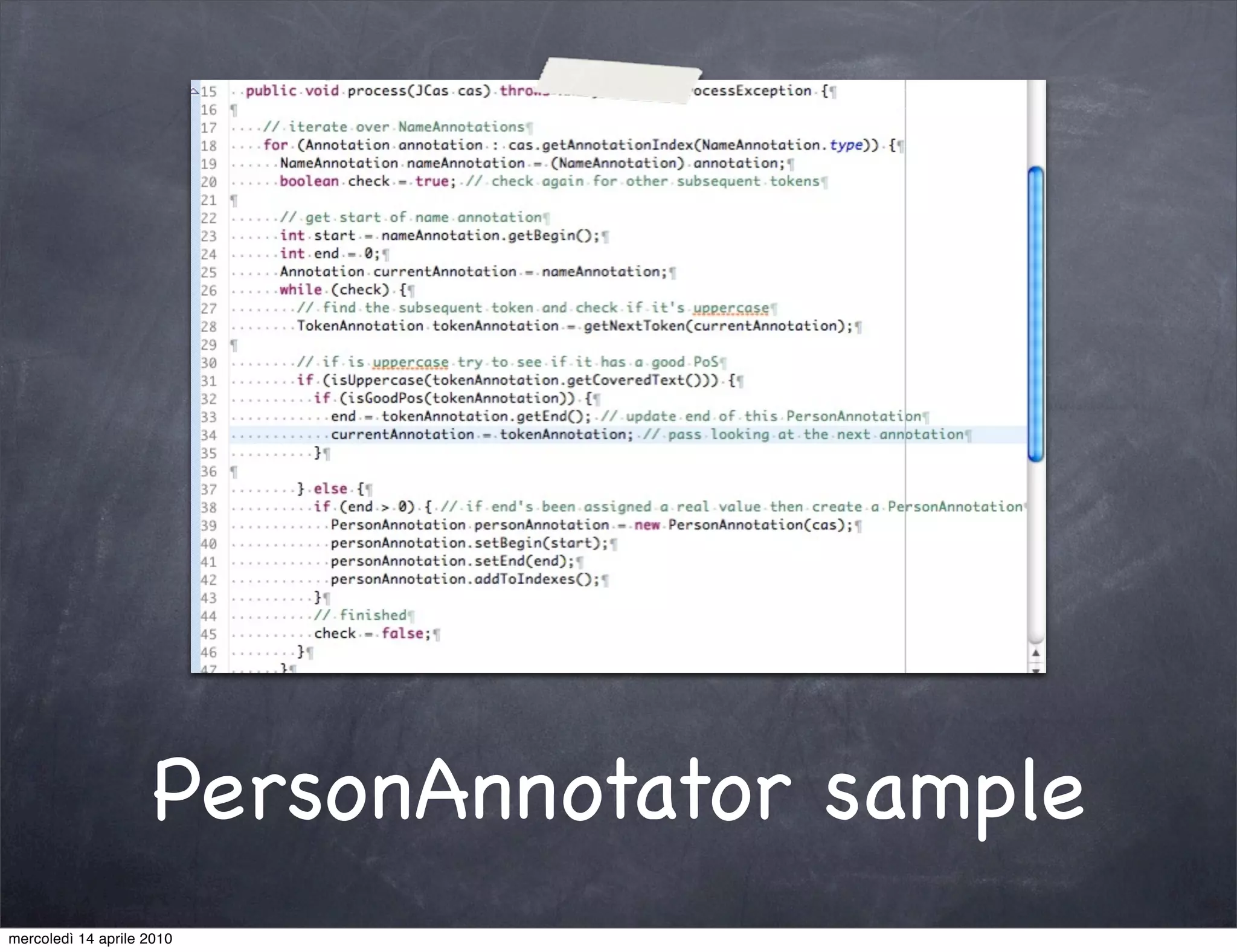


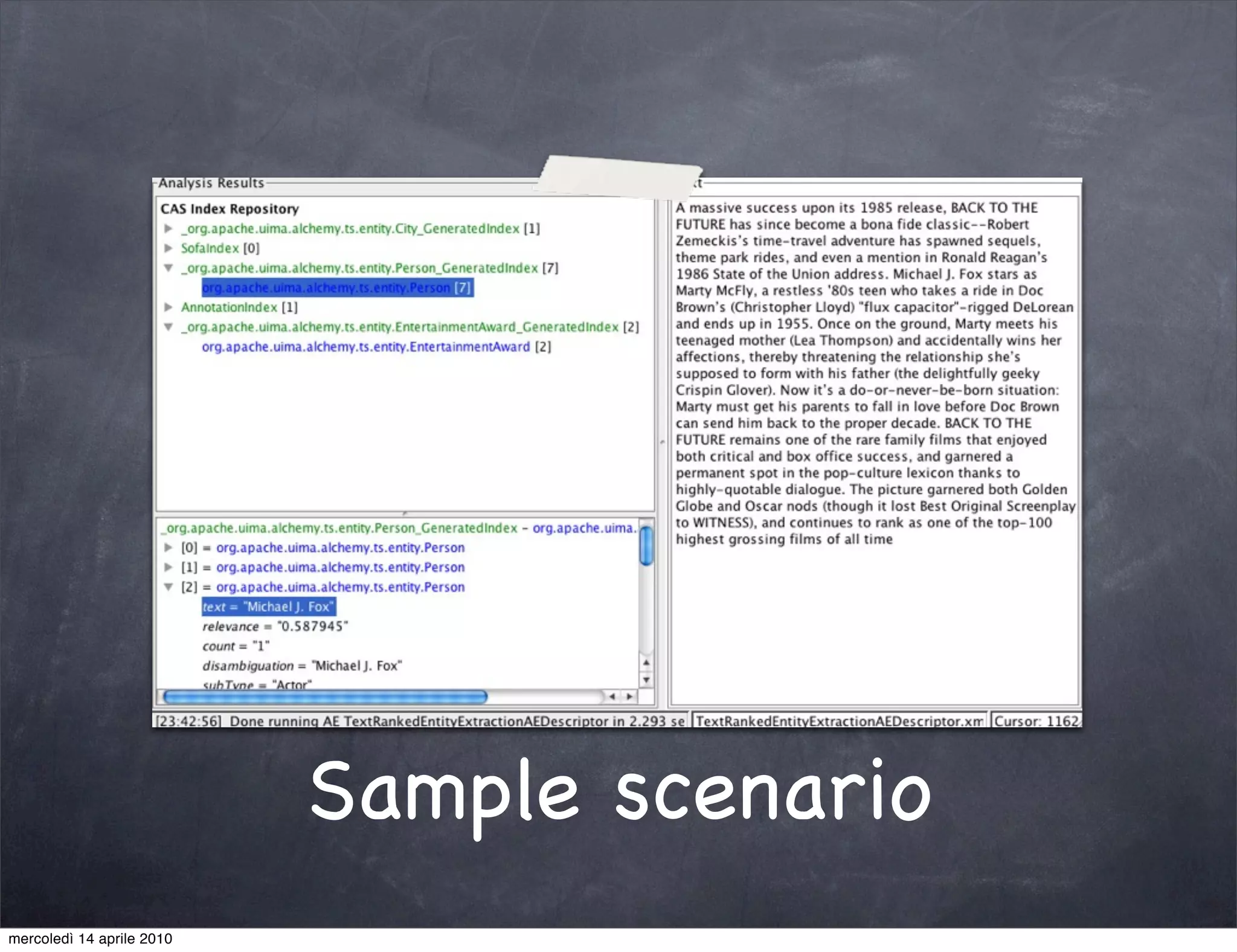




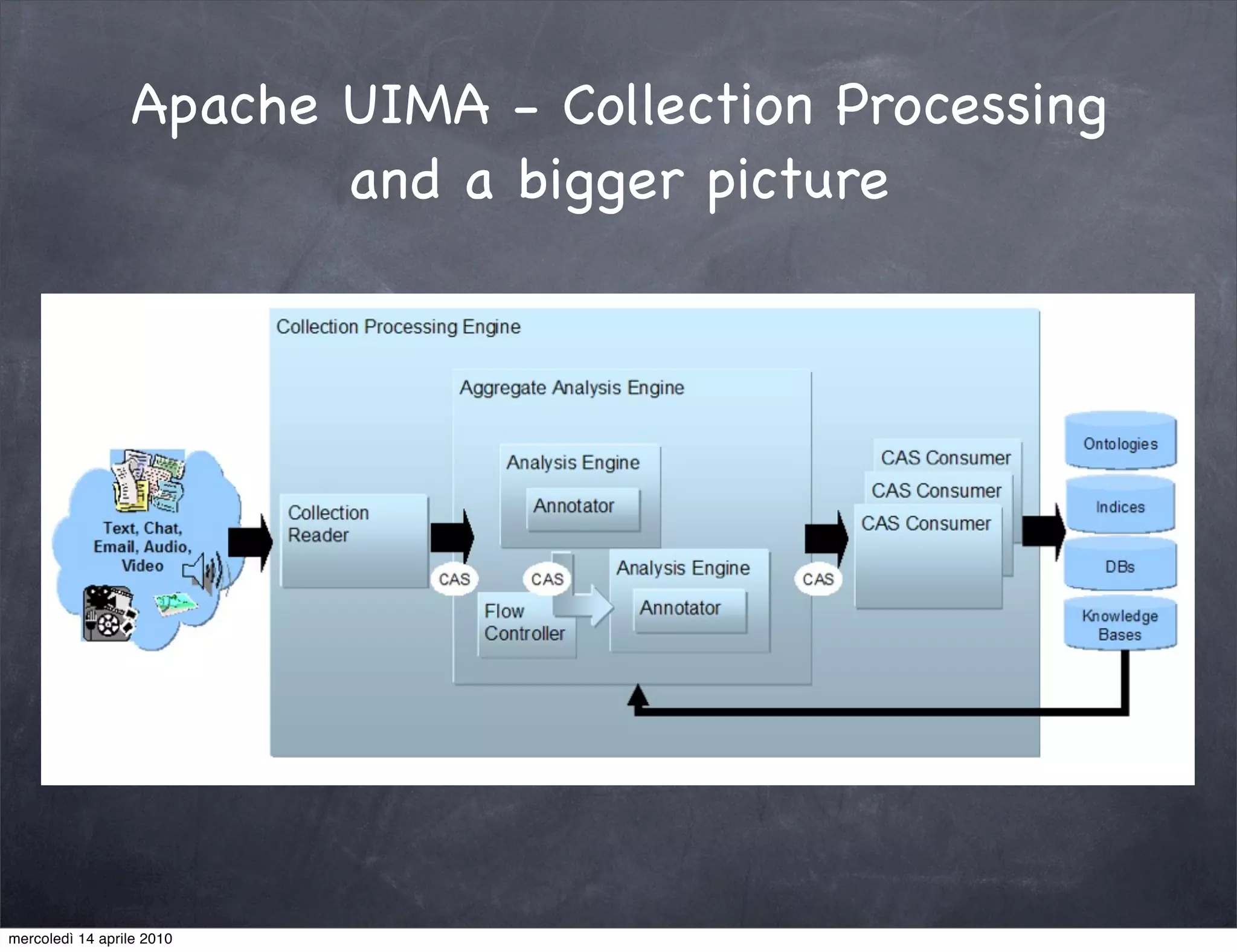









The document provides an overview of Apache UIMA, an open-source framework designed for processing unstructured data such as text, audio, and video. It discusses UIMA's architecture, goals, components, and its capabilities in metadata generation and multimodal analysis, along with key concepts like analysis engines, annotators, and type systems. Furthermore, it presents sample scenarios demonstrating UIMA's application in enriching content with metadata and enhancing information retrieval through natural language processing techniques.









































