Downloaded 62 times







![Hadoop as The Linux of Data
Hadoop has won the Cycle “Hadoop is the
kernel of a
Gartner: Hadoop will be in
distributed operating
2/3s of advanced analytics
products by 2015 [1] system, and all the
other components
around the kernel
are now arriving on
this stage”
---Doug Cutting](https://image.slidesharecdn.com/hadoopsummiteu201327022013final-130324085852-phpapp01/85/Hadoop-Summit-EU-2013-Parallel-Linear-Regression-IterativeReduce-and-YARN-7-320.jpg)




![Distributed Systems Are Hard
Lots of moving parts
Especially as these applications become more complicated
Machine learning can be a non-trivial operation
We need great building blocks that work well together
I agree with Jimmy Lin [3]: “keep it simple”
“make sure costs don’t outweigh benefits”
Minimize “Yet Another Tool To Learn” (YATTL) as much as
we can!](https://image.slidesharecdn.com/hadoopsummiteu201327022013final-130324085852-phpapp01/85/Hadoop-Summit-EU-2013-Parallel-Linear-Regression-IterativeReduce-and-YARN-12-320.jpg)
















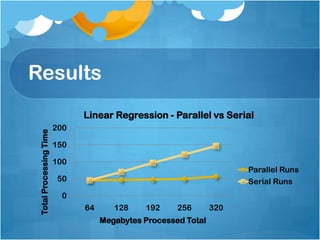






The document discusses the evolution of data analytics, emphasizing the significance of Hadoop as a central platform for managing big data and machine learning applications. It introduces Patterson’s Law, which states that as data storage approaches 100%, processing and analytics also increase, and outlines challenges and solutions related to parallel computing and distributed learning strategies. Additionally, it presents an overview of the parallel iterative algorithms implemented through a project called Metronome, highlighting its performance and future directions for improvement.





































![[Xin yan, xiao_gang_su]_linear_regression_analysis(book_fi.org)](https://cdn.slidesharecdn.com/ss_thumbnails/xinyanxiaogangsulinearregressionanalysisbookfi-140714092751-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



































































