Download as PDF, PPTX
![Apache UIMA
Introduction
Gestione delle Informazioni su Web - 2010/2011
Tommaso Teofili
tommaso [at] apache [dot] org](https://image.slidesharecdn.com/uima-110331160950-phpapp01/75/Apache-UIMA-Introduction-1-2048.jpg)




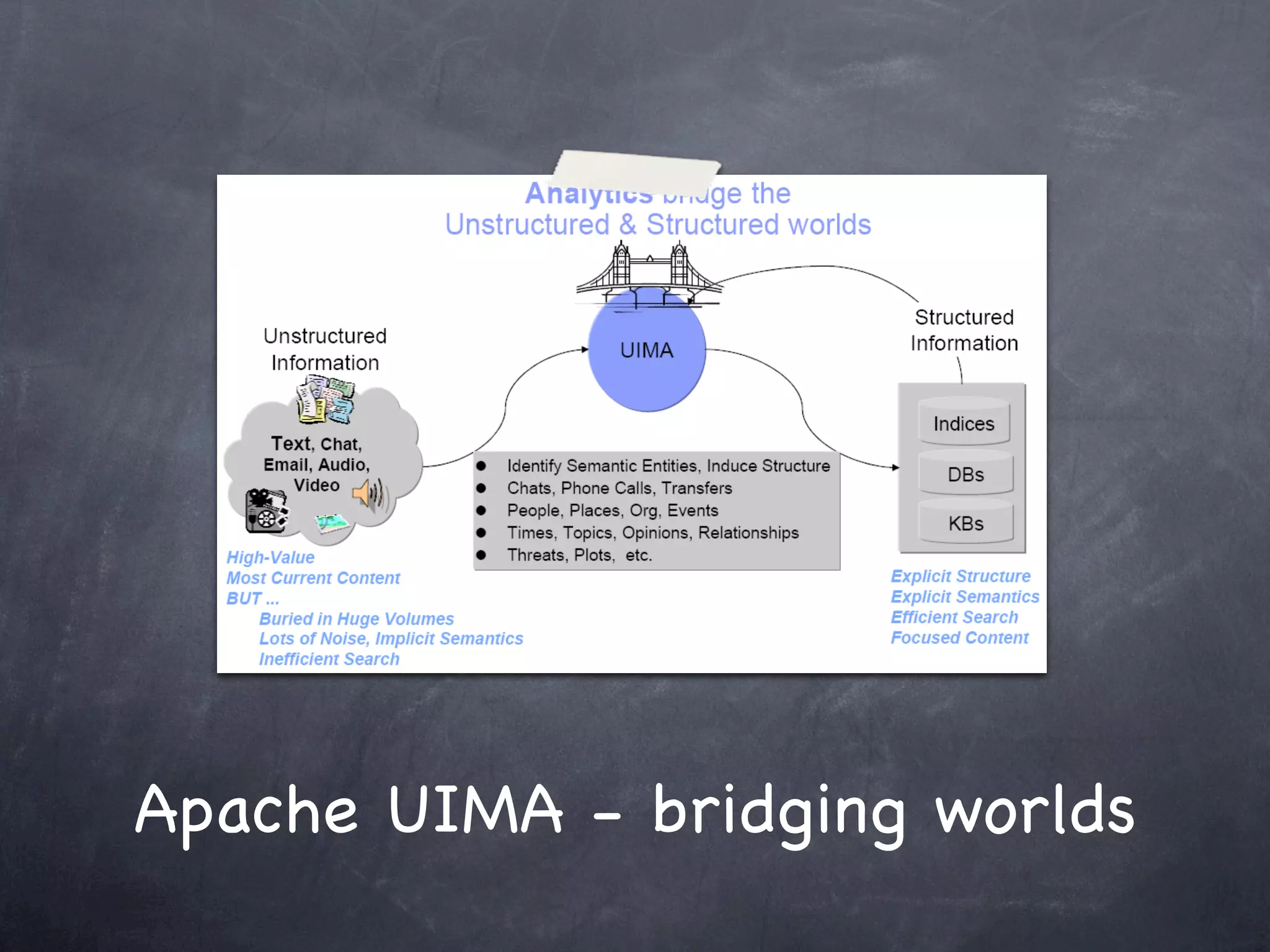





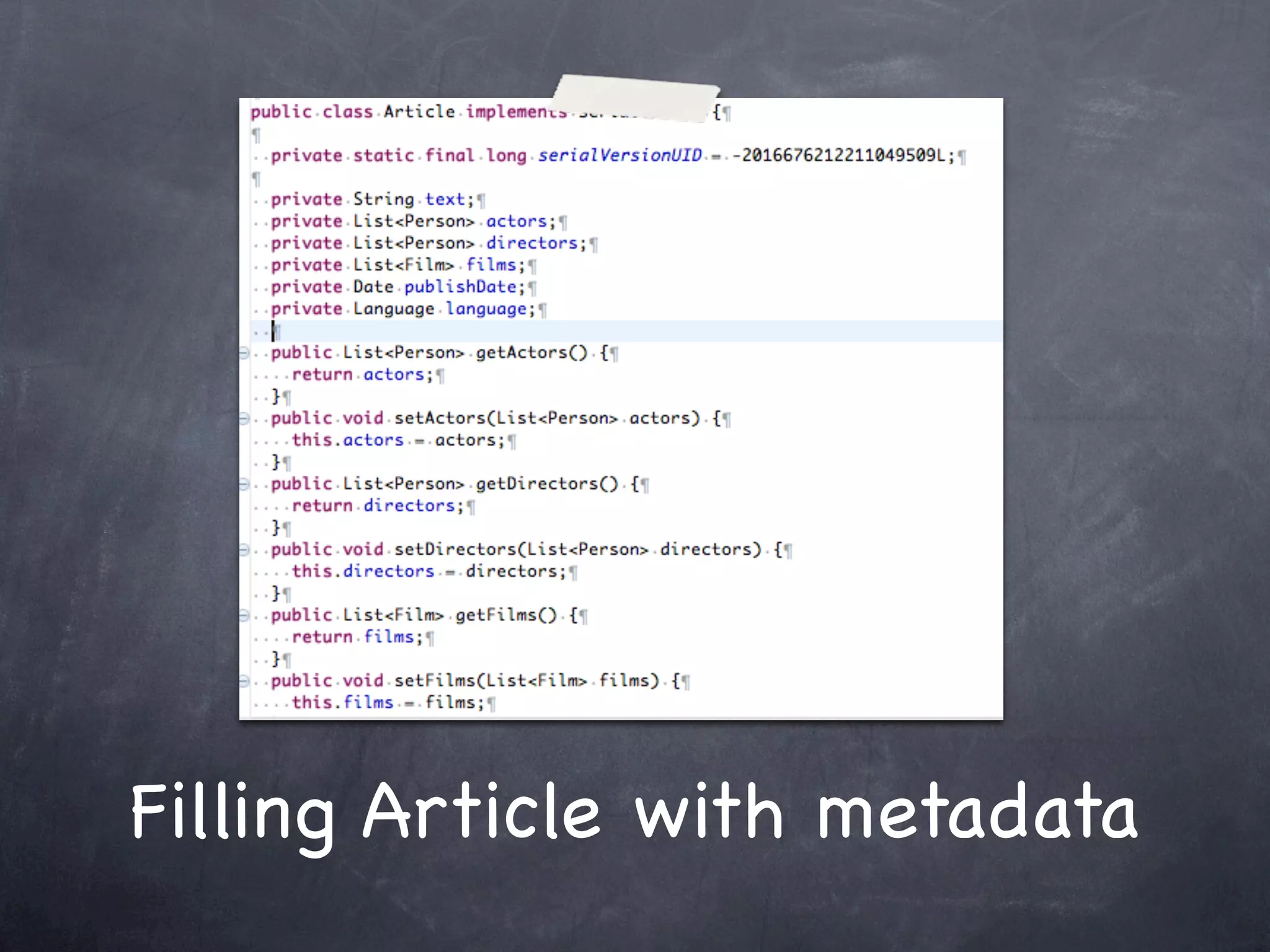

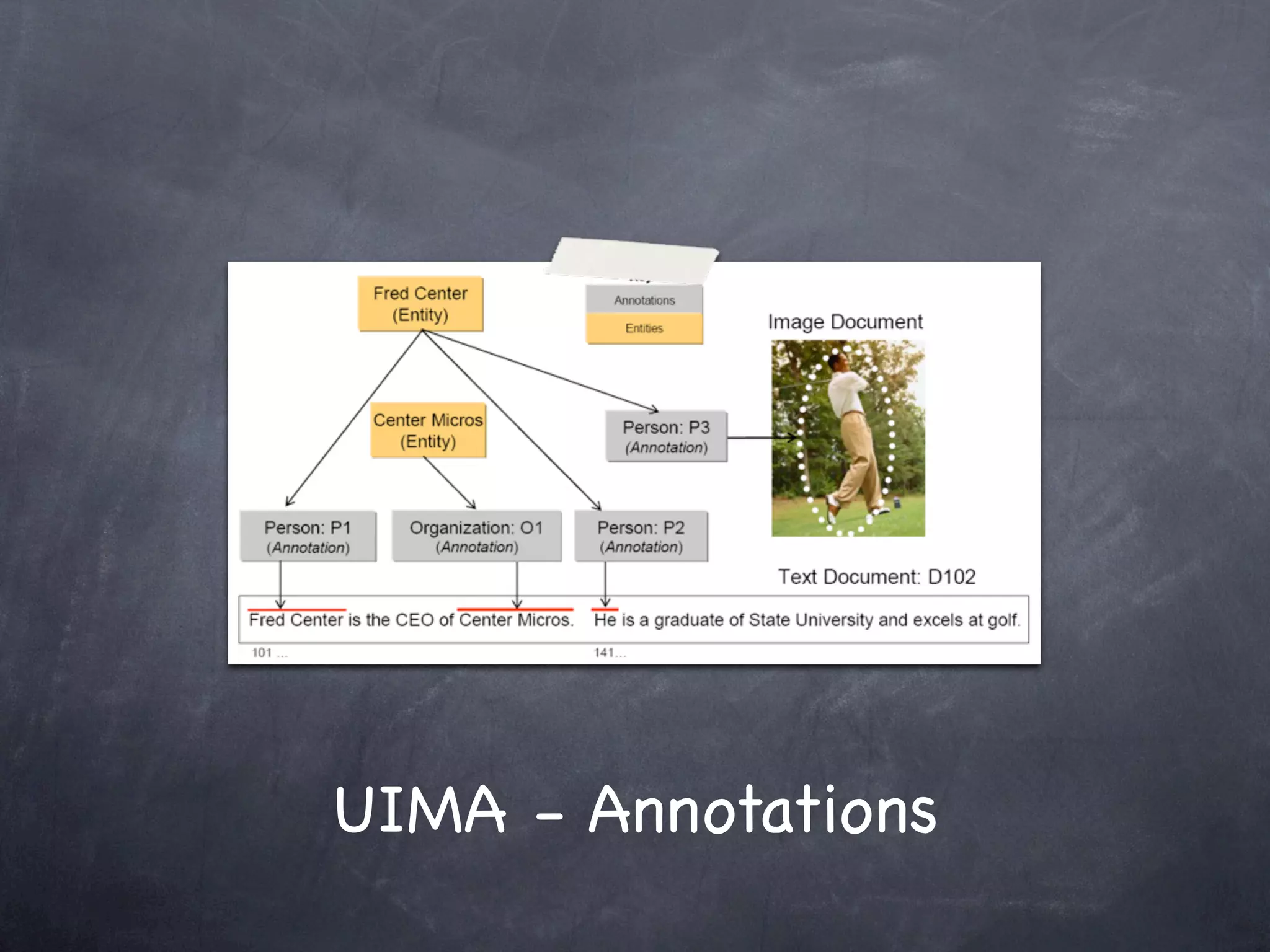









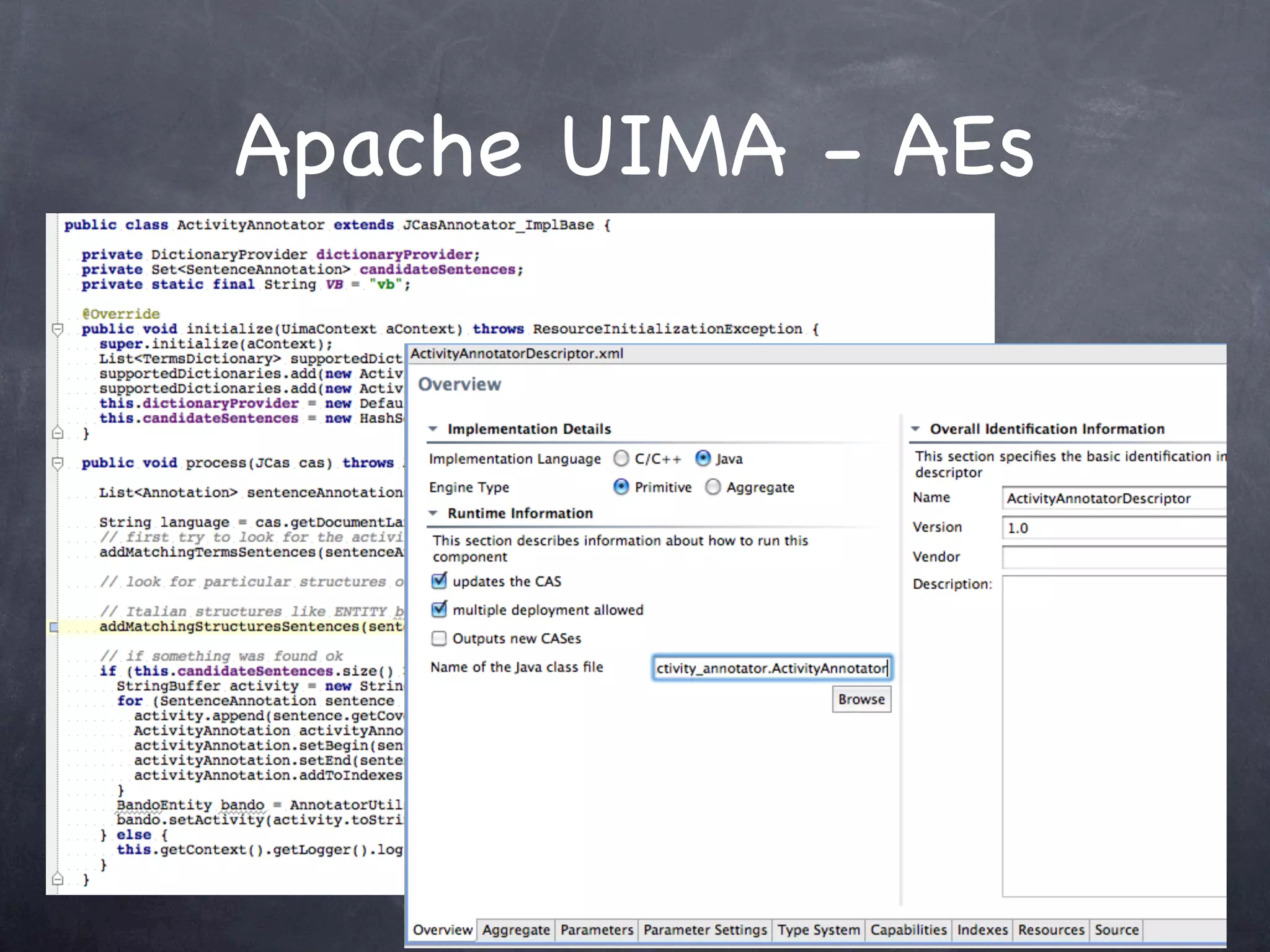
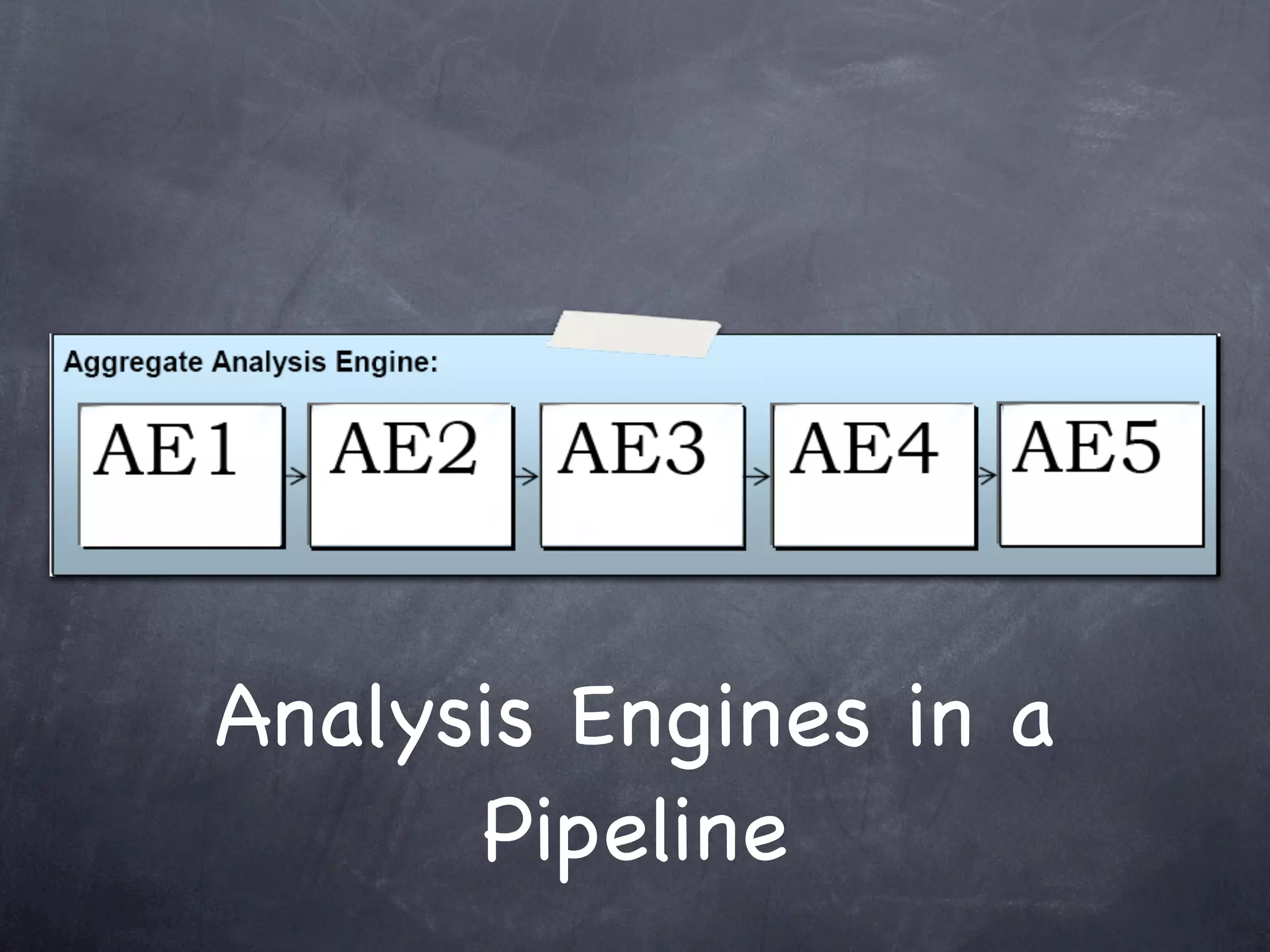

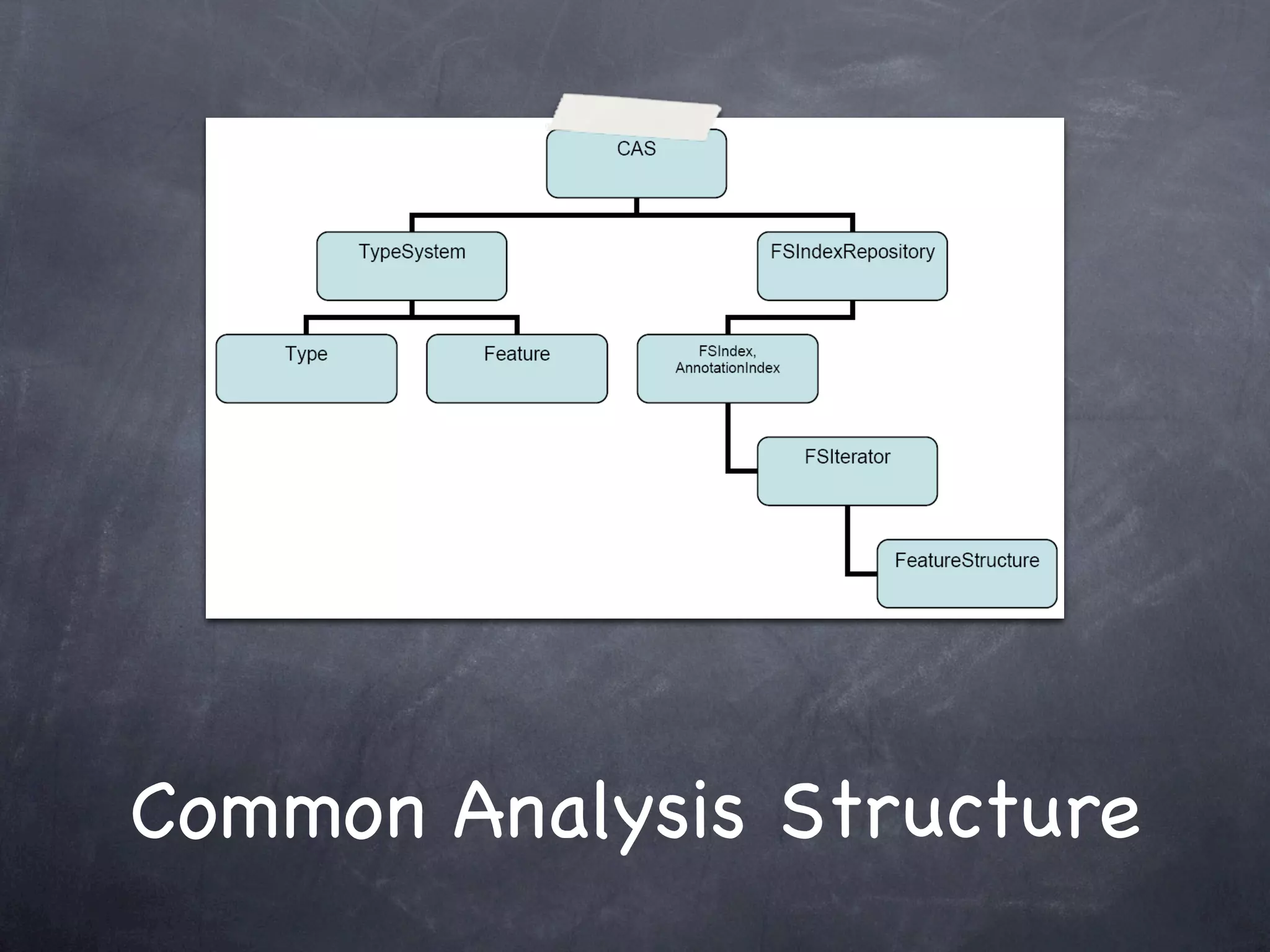





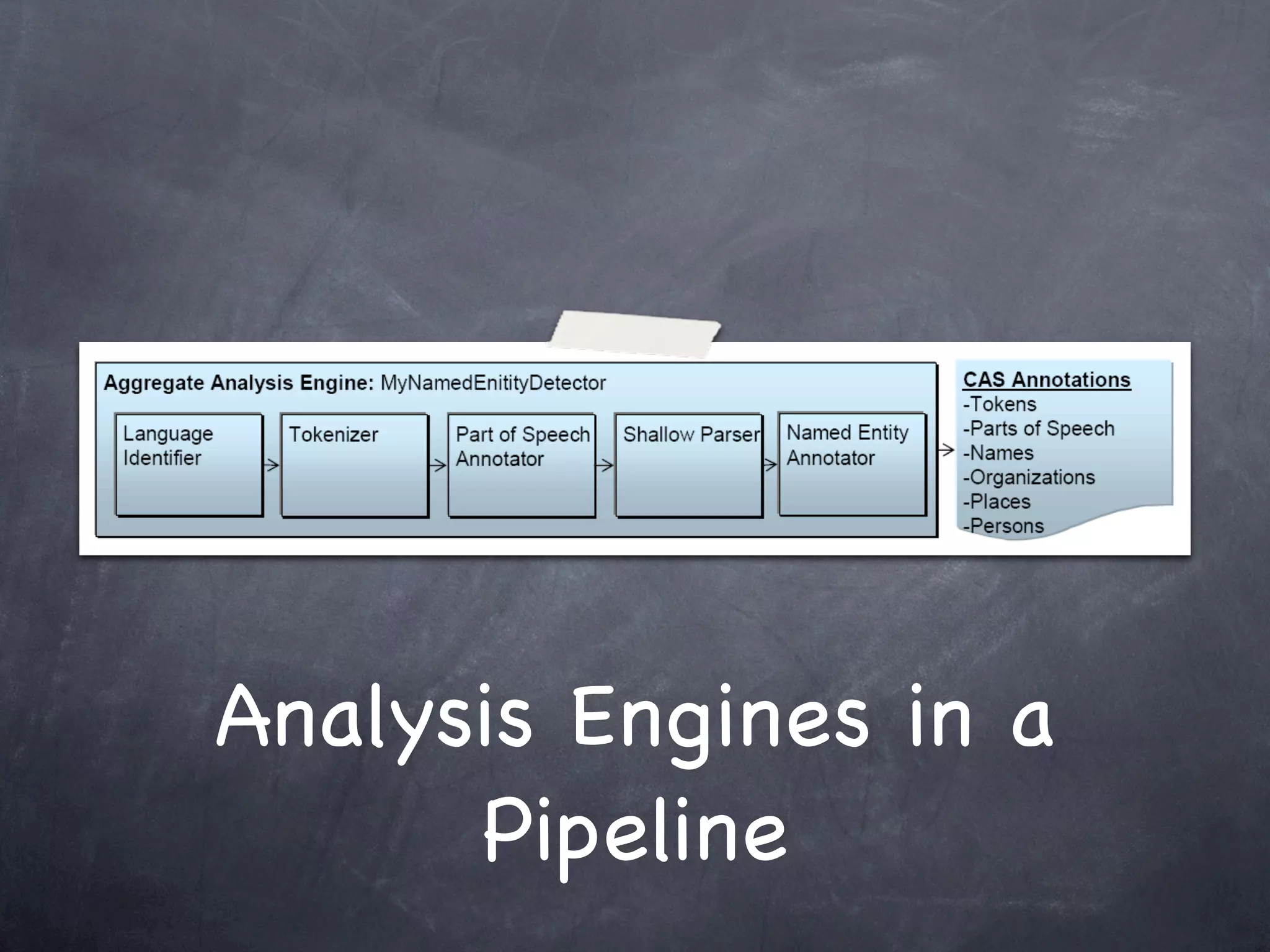



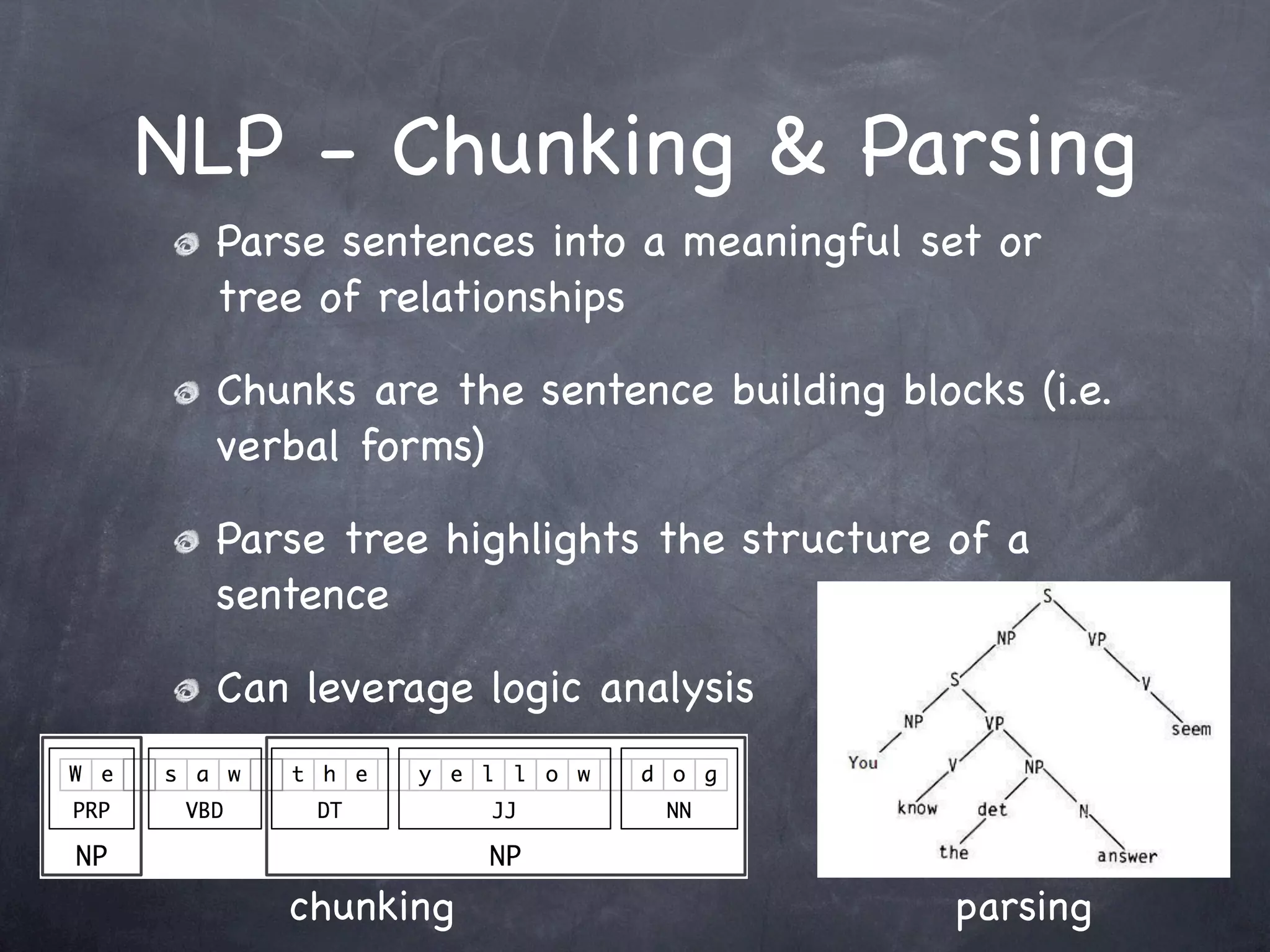

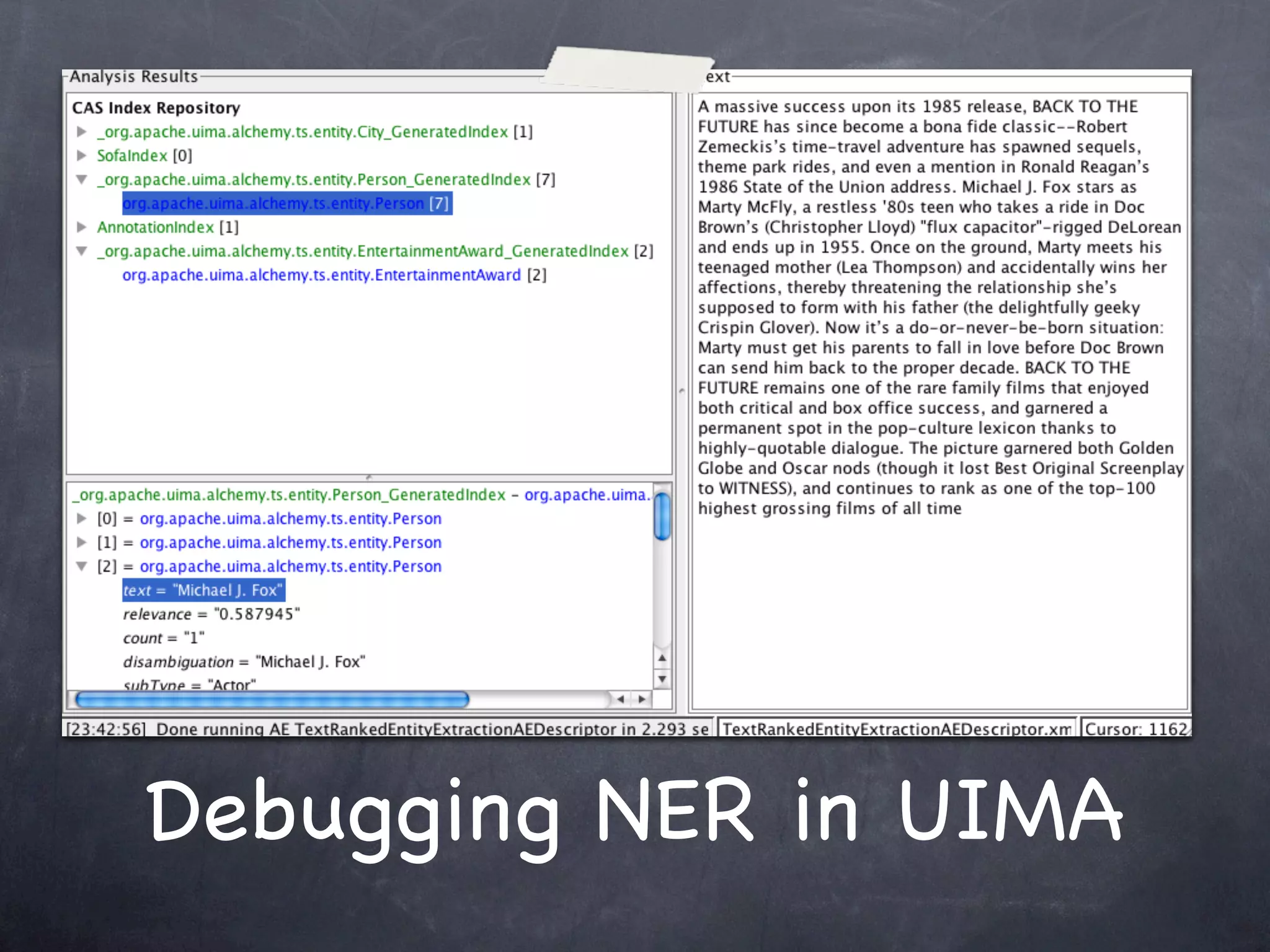







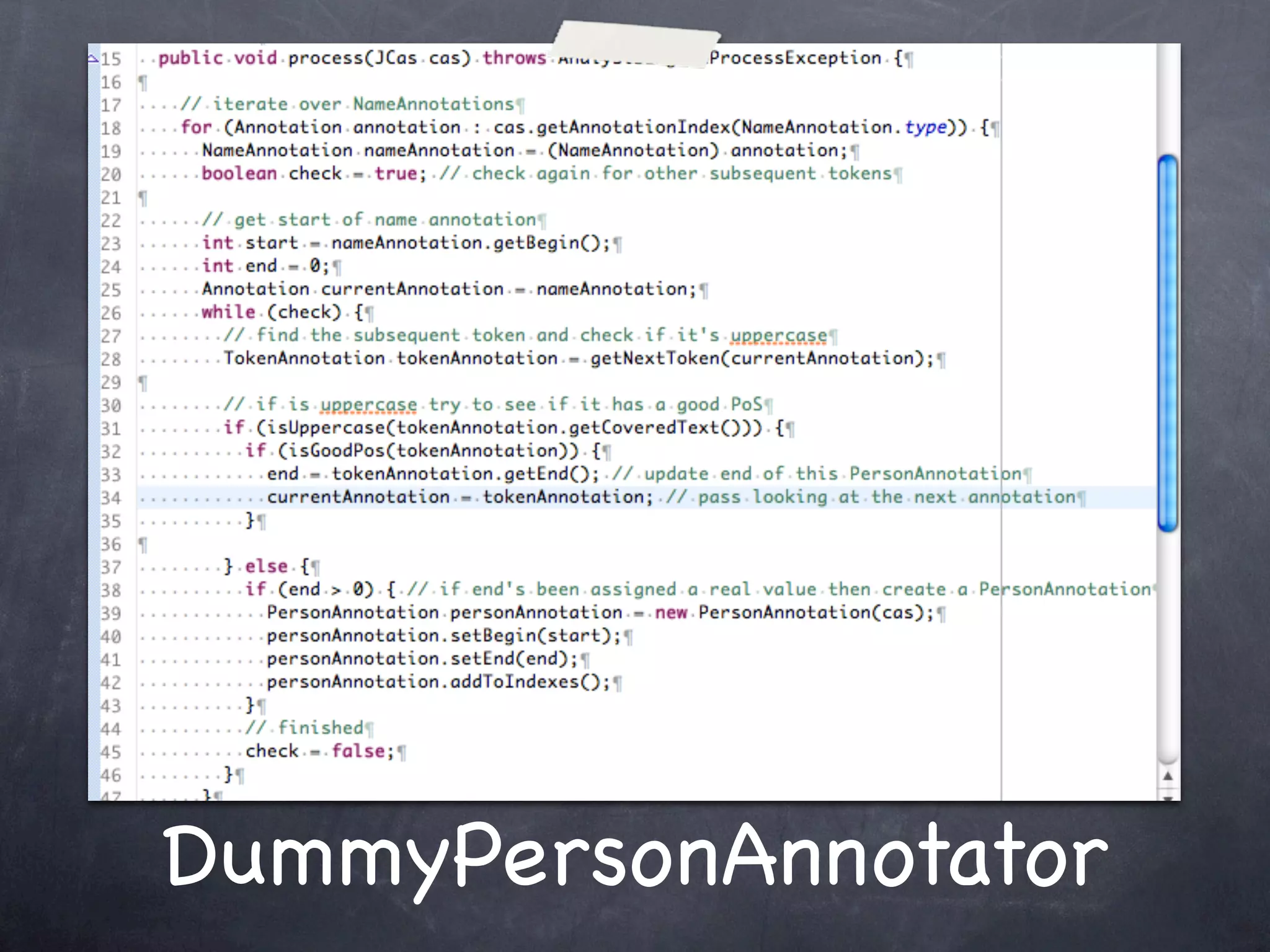

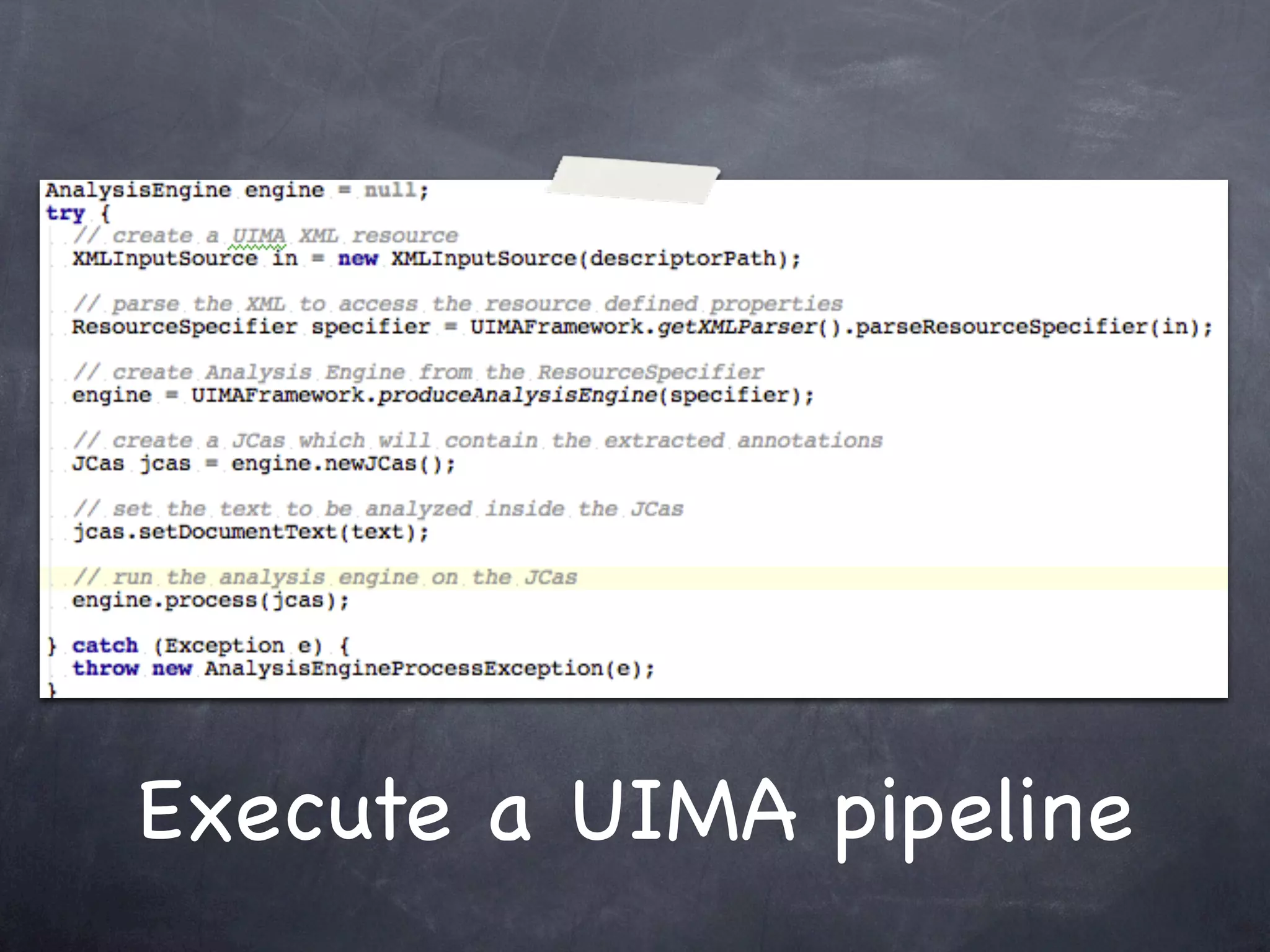



This document provides an introduction and overview of Apache UIMA (Unstructured Information Management Architecture). Apache UIMA is an open source framework for analyzing unstructured information like text, audio, and video. It allows defining type systems and building analysis pipelines using components called annotators that can extract metadata from unstructured data. The document outlines some key aspects of Apache UIMA including its goals of supporting a community around analyzing unstructured content, how it can bridge different domains, and provides an example scenario of using it to extract metadata from articles about movies.

















































































