Downloaded 150 times
![Apache UIMA - hands
on code
Gestione delle Informazioni su Web - 2010/2011
Tommaso Teofili
tommaso [at] apache [dot] org](https://image.slidesharecdn.com/uimahoc-110406003305-phpapp02/75/Apache-UIMA-Hands-on-code-1-2048.jpg)



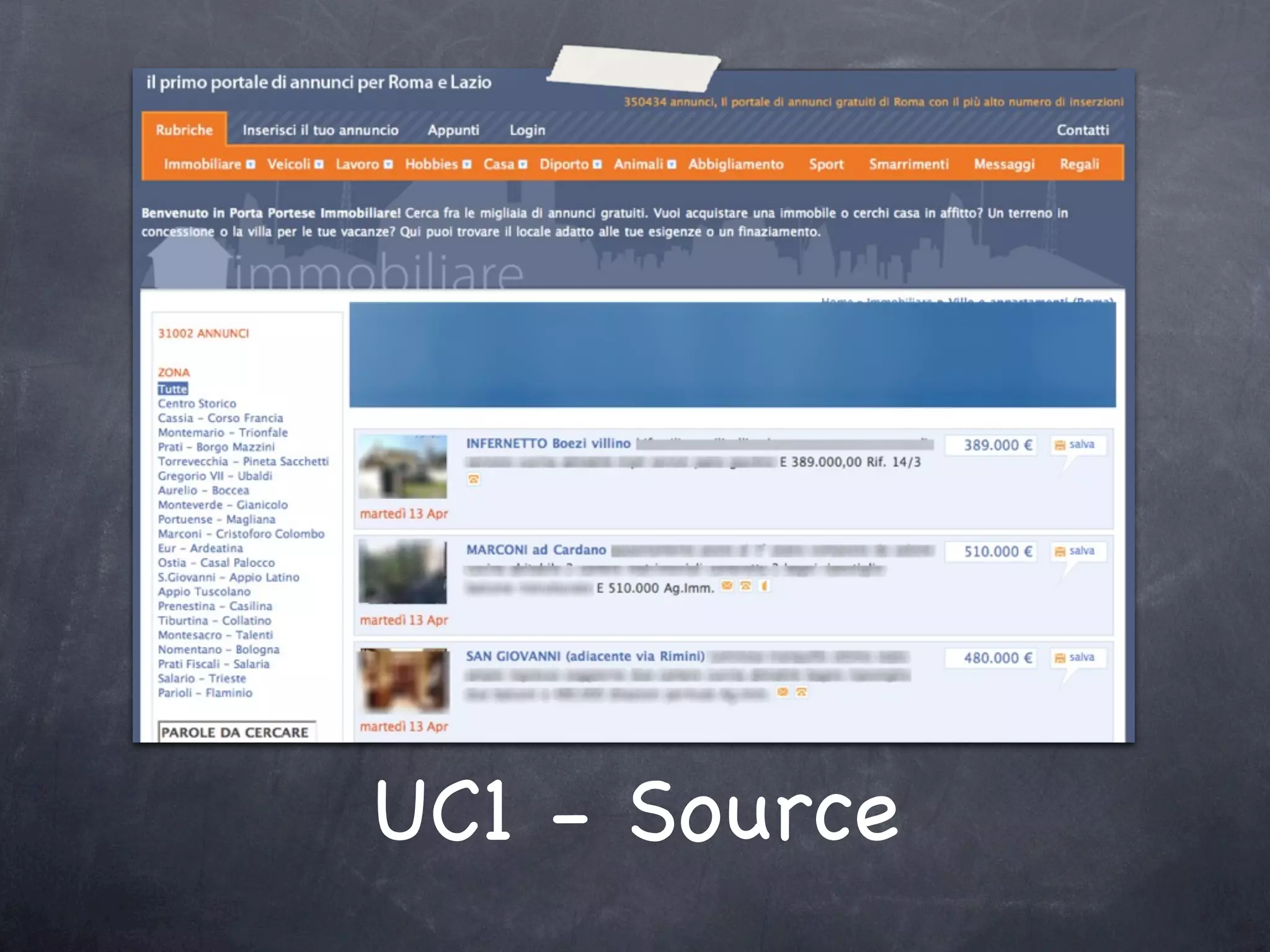
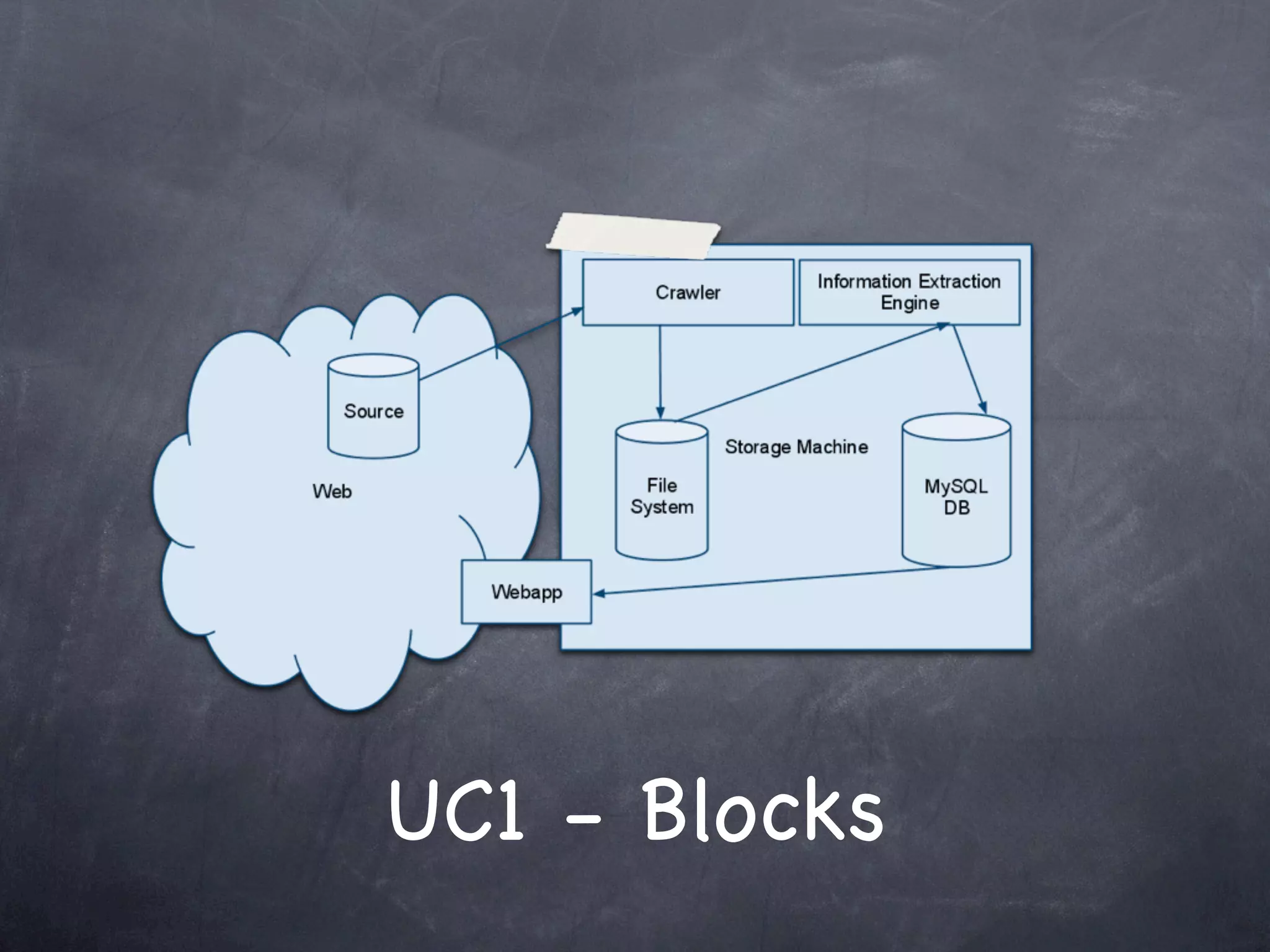







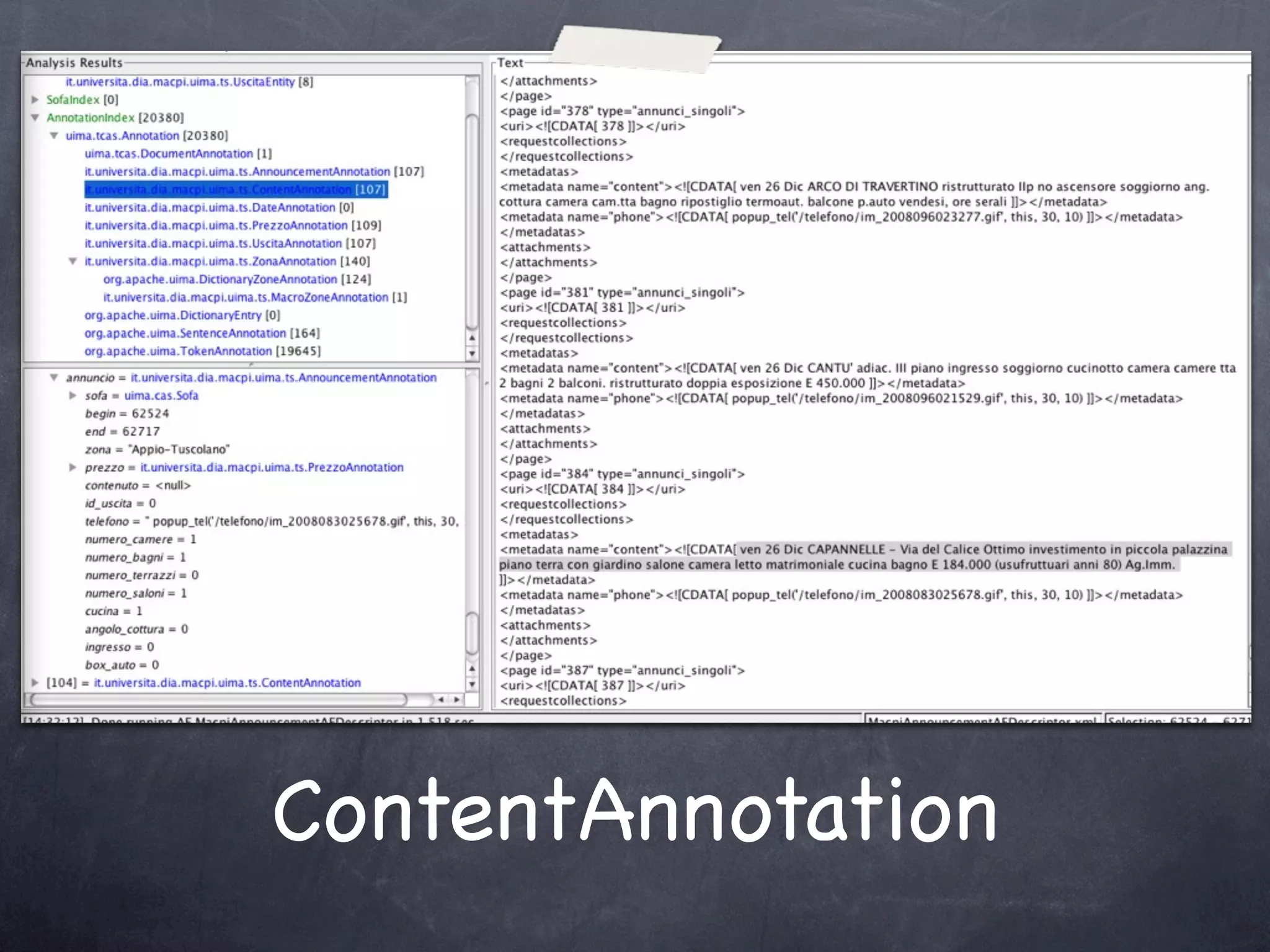
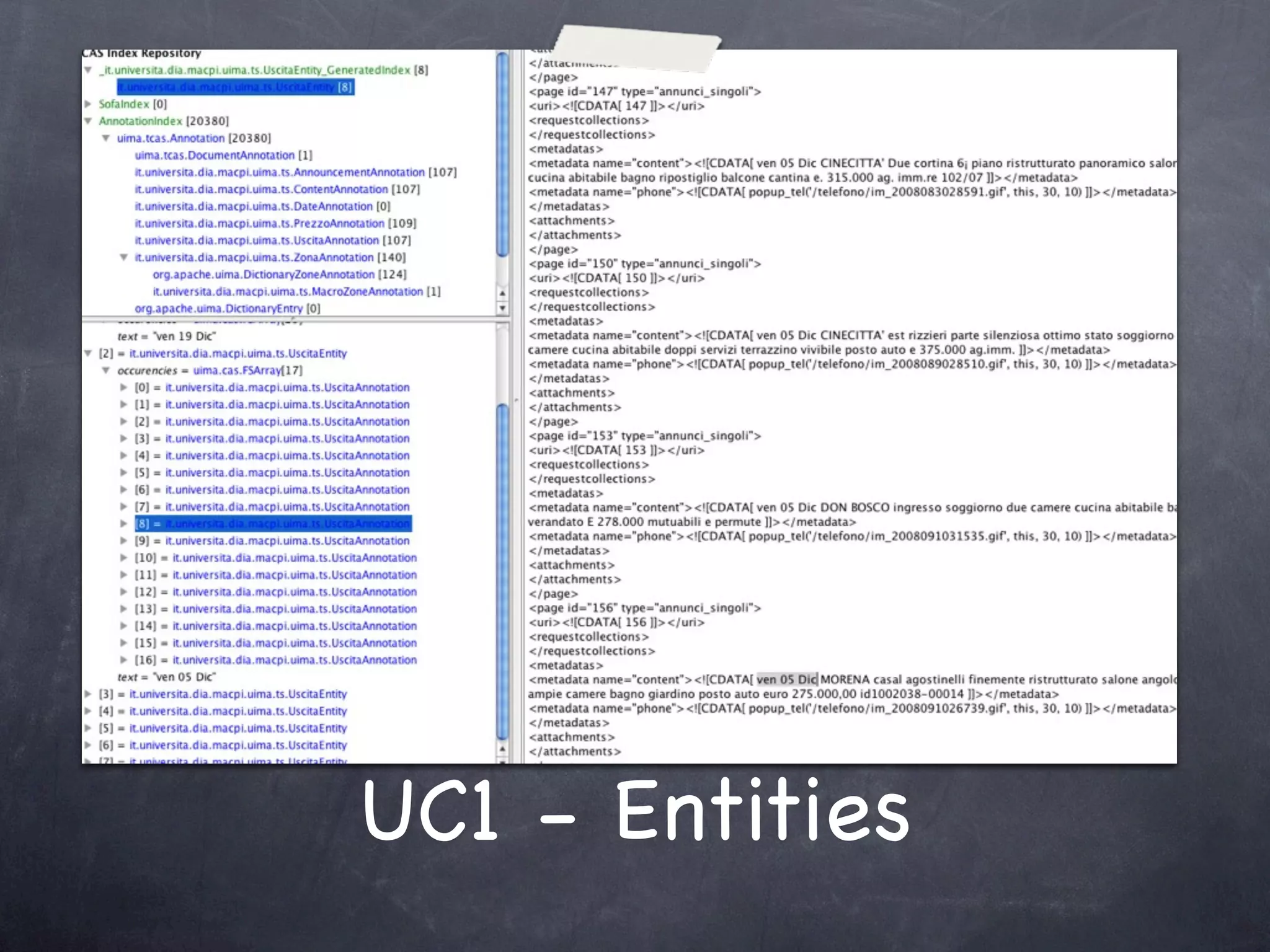



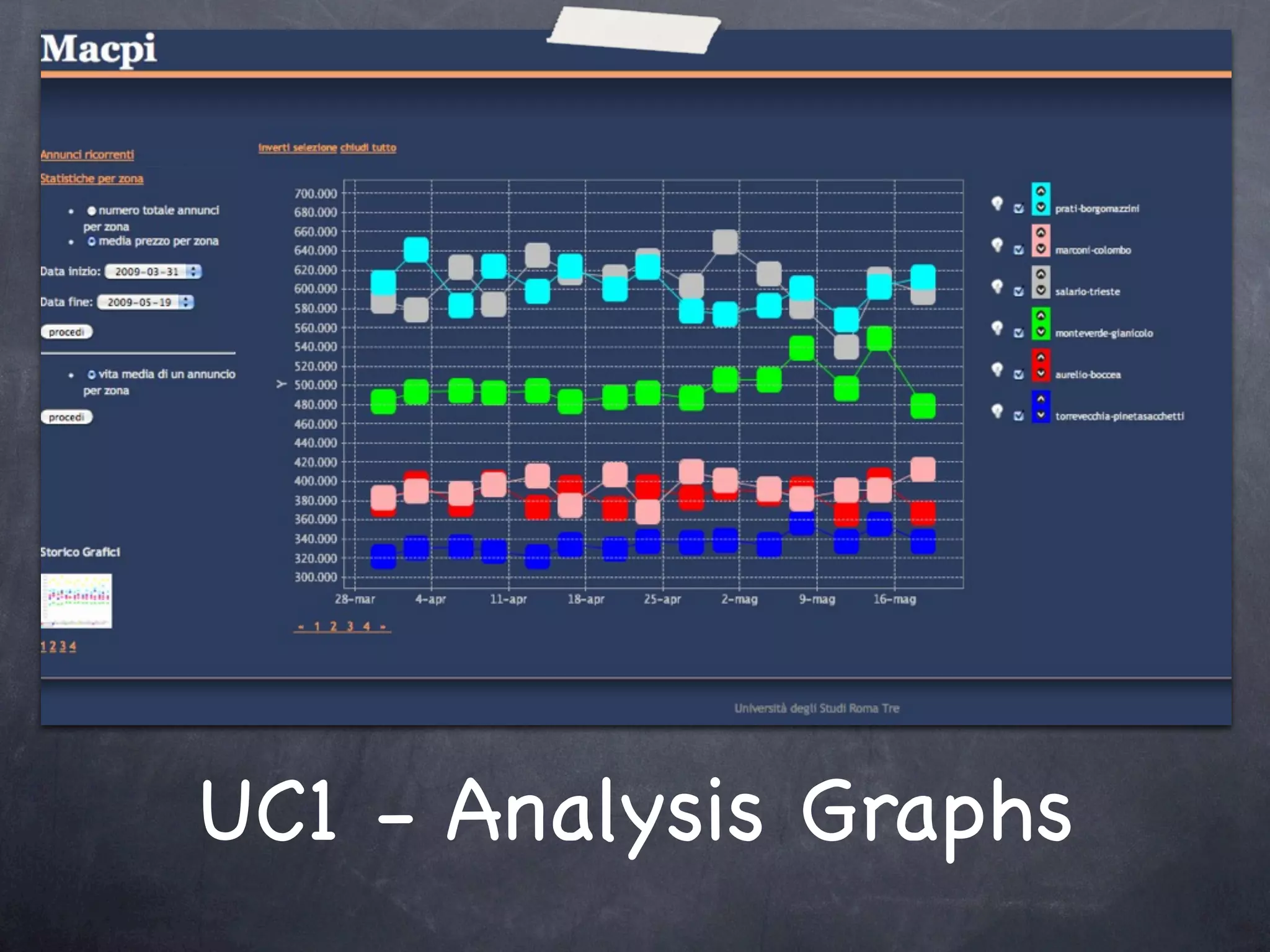
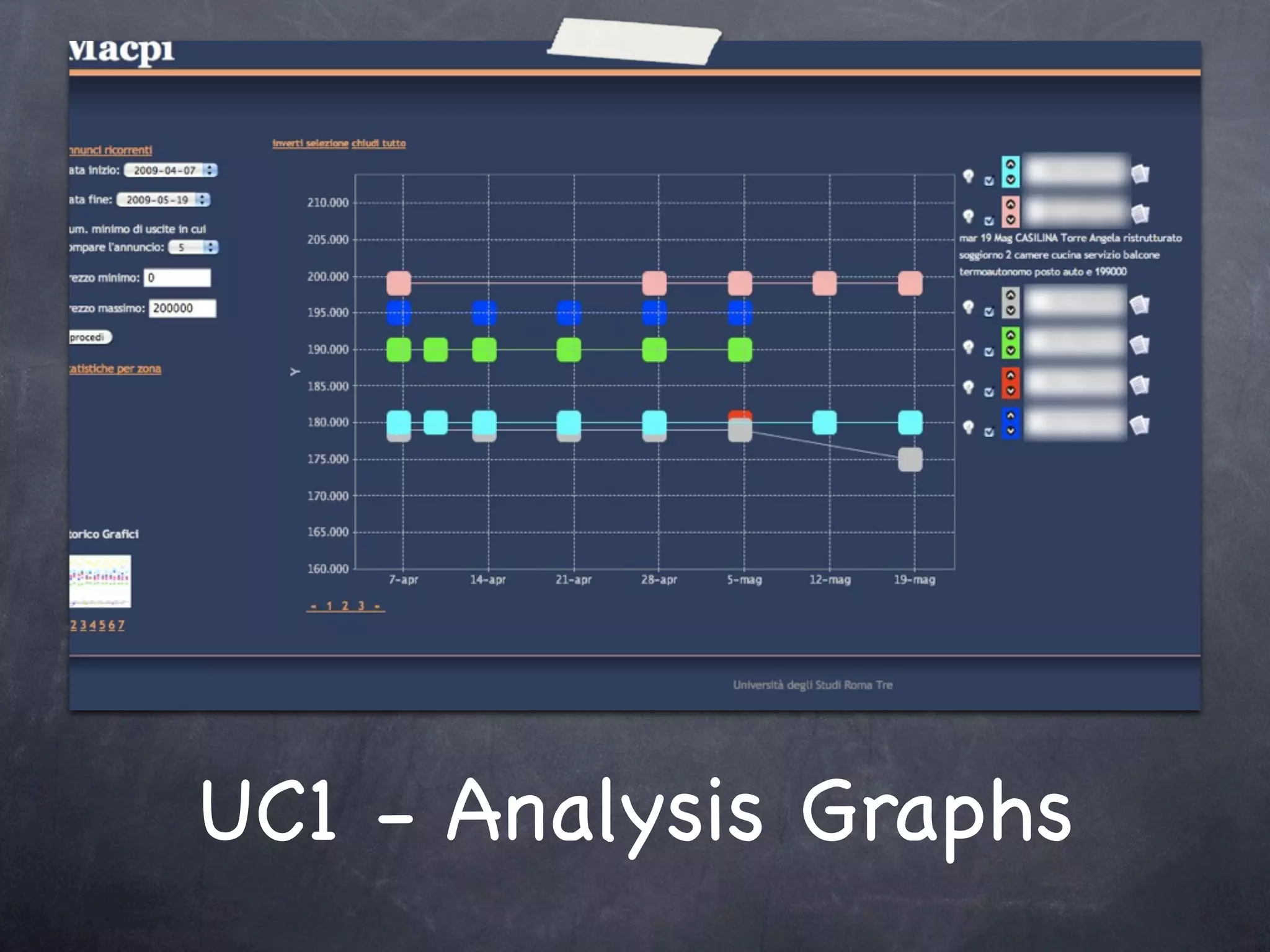

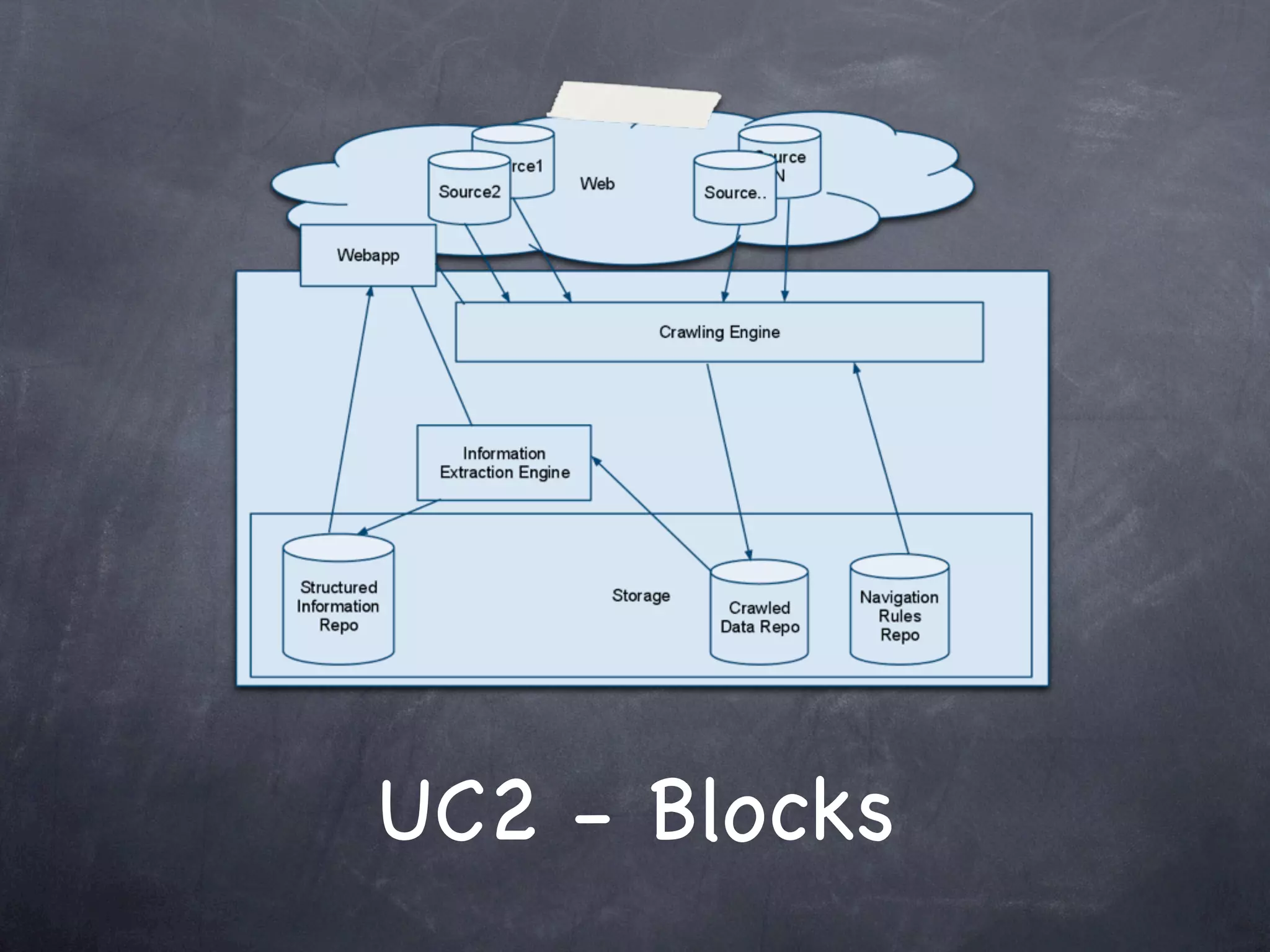
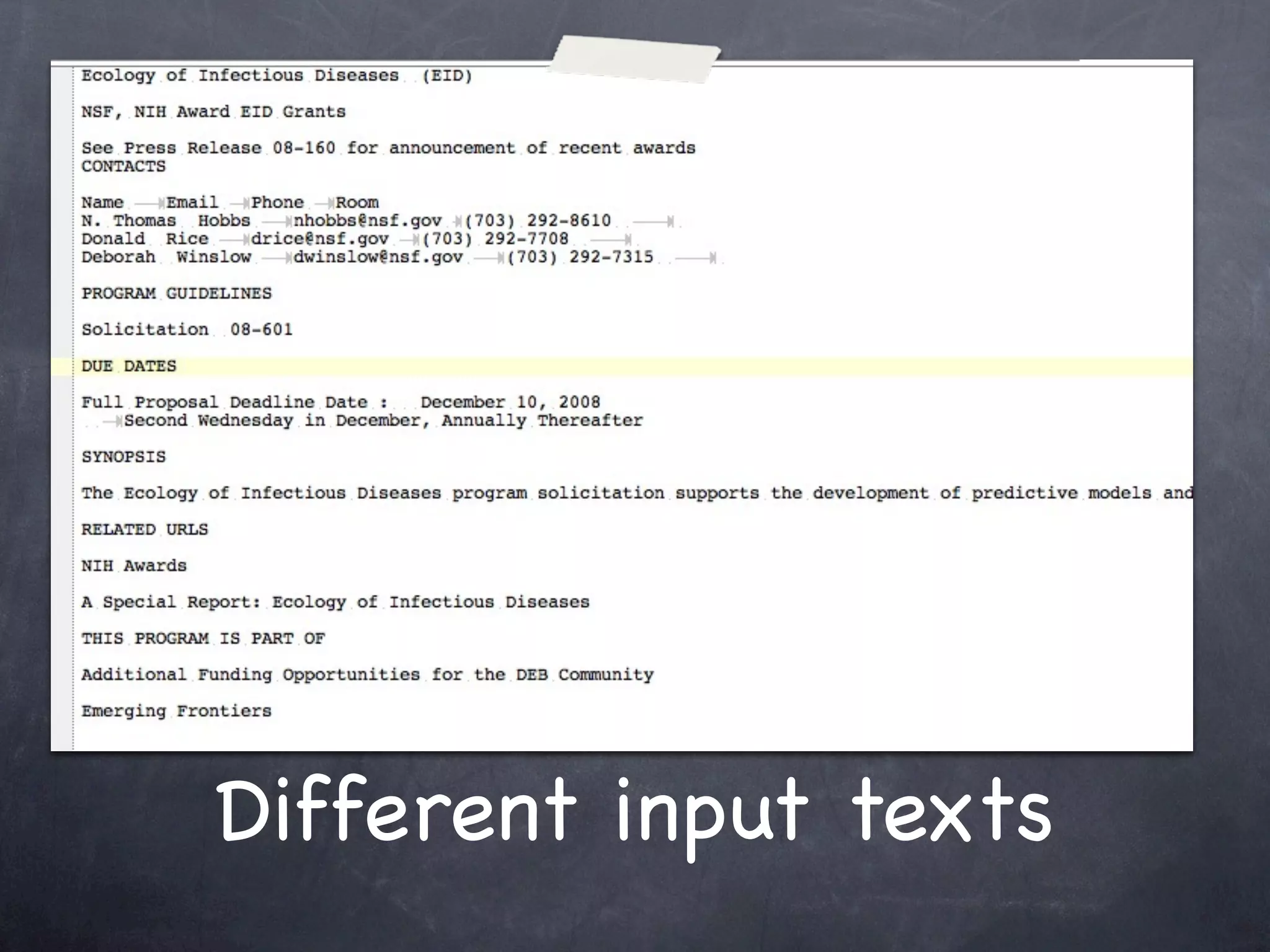
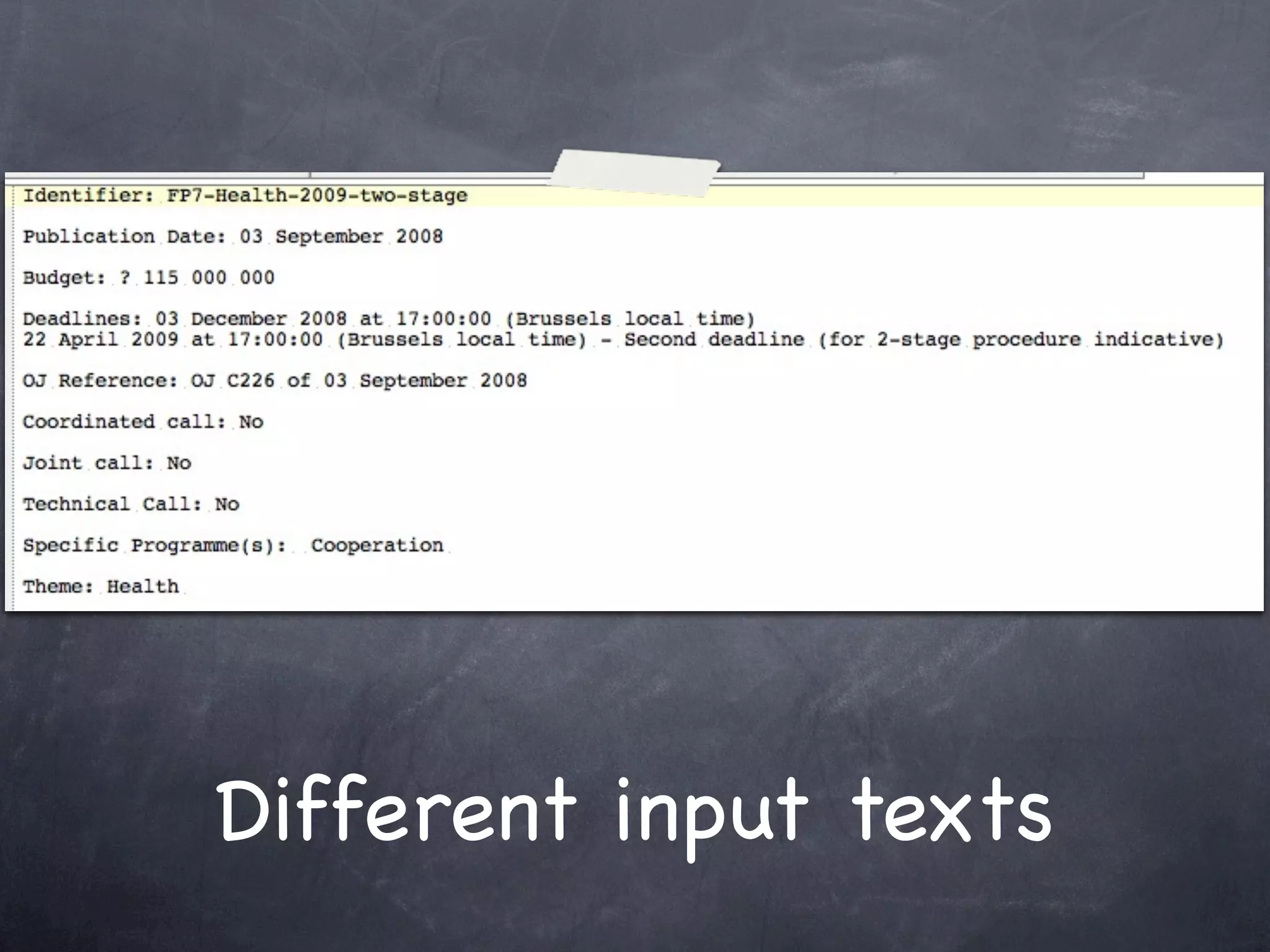






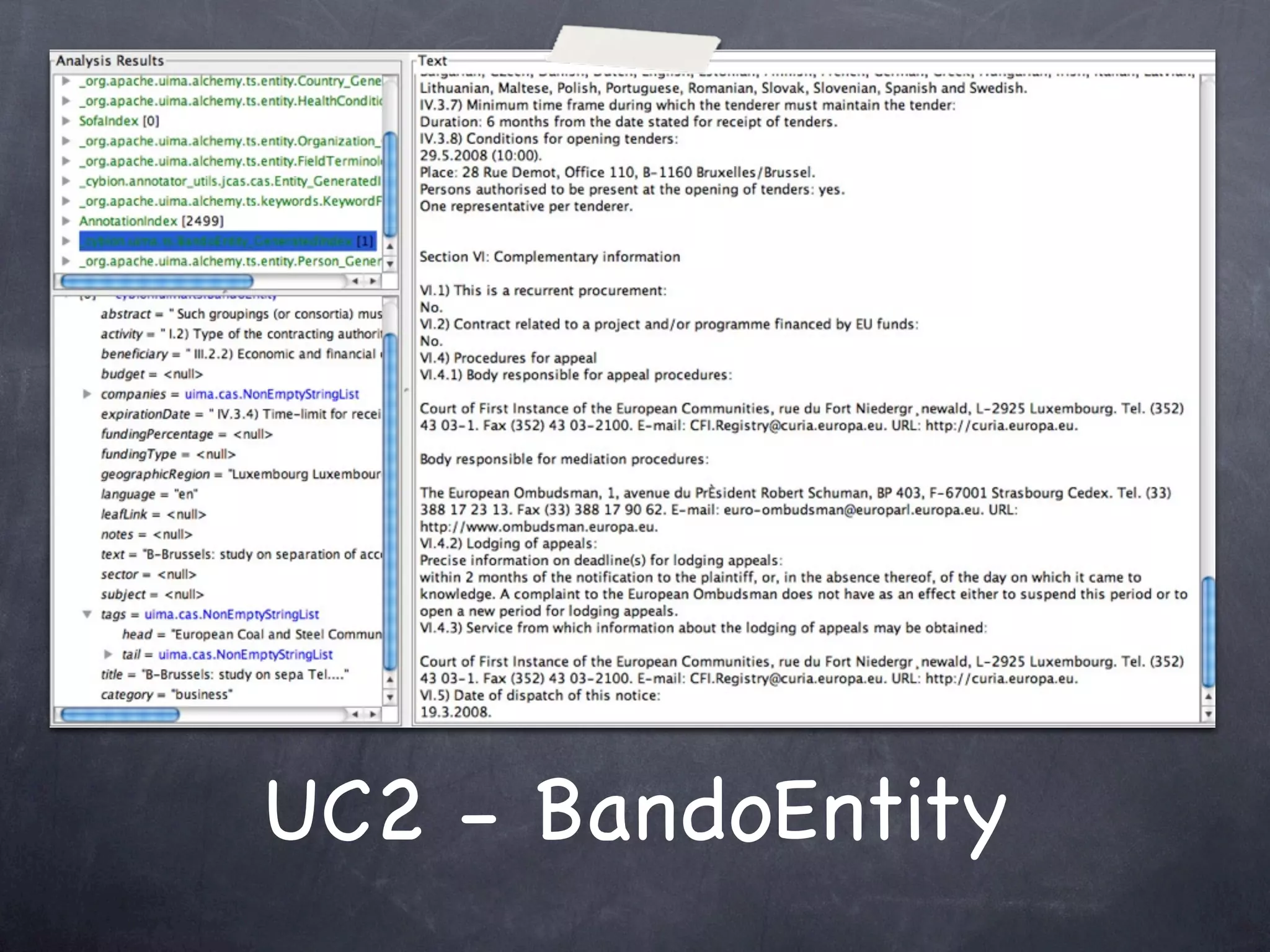






The document discusses two use cases (UC1 and UC2) for applying Apache UIMA to automatically extract structured information from unstructured text. UC1 involves using UIMA to analyze real estate listings to extract fields like price, zone, and phone number to track trends in the real estate market. UC2 aims to automatically extract common information like language, funding type, and expiration date from announcements of EU tenders and contracts. The document outlines the different components involved in each use case, including crawlers to extract text, annotators to identify relevant entities, and CAS consumers to store extracted fields in databases or indexes.


















































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)











