Download as PDF, PPTX
![Information Extraction
with UIMA - Use Cases
Gestione delle Informazioni su Web - 2009/2010
Tommaso Teofili
tommaso [at] apache [dot] org
venerdì 16 aprile 2010](https://image.slidesharecdn.com/uimausecases2-100418081630-phpapp02/75/Information-Extraction-with-UIMA-Usecases-1-2048.jpg)



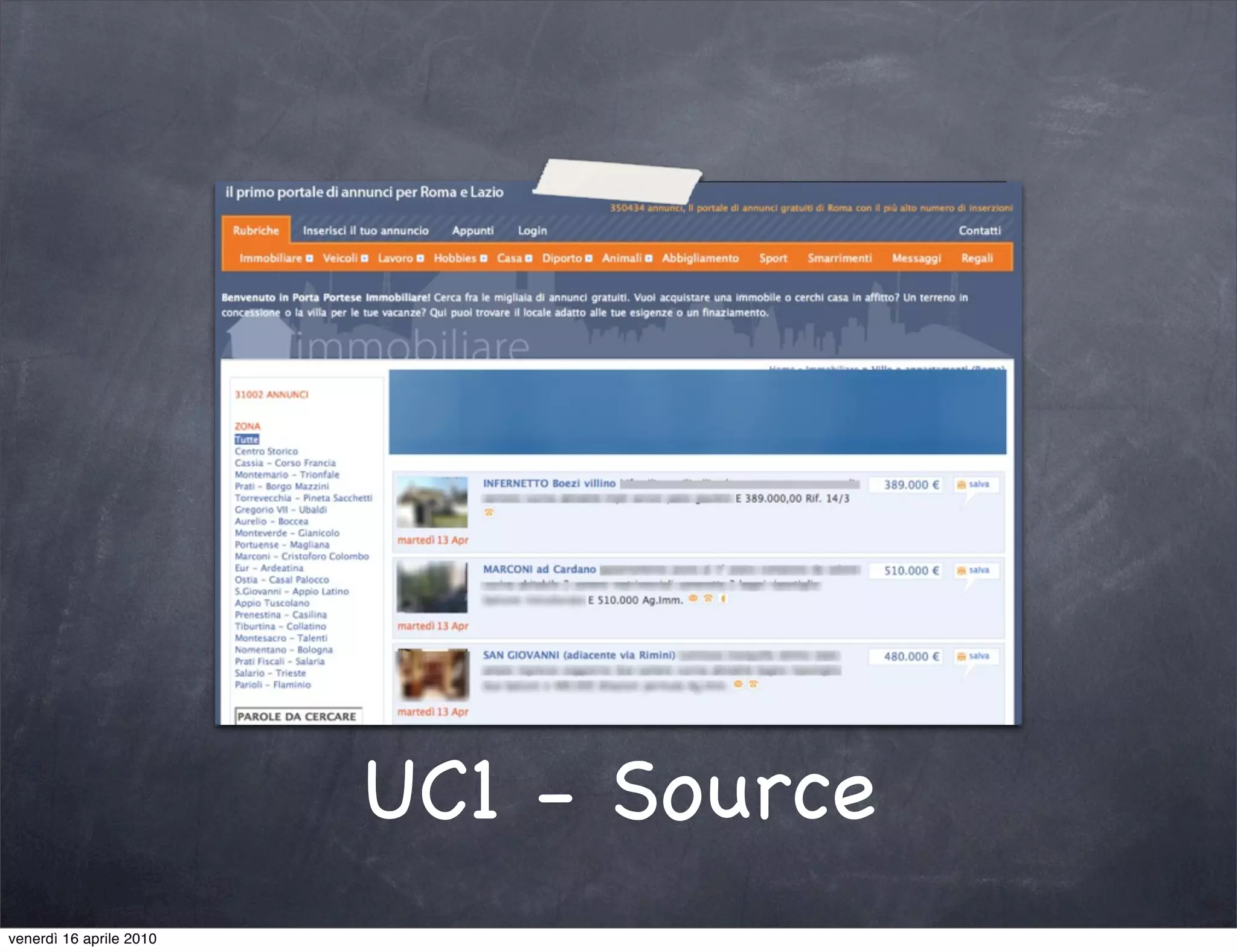


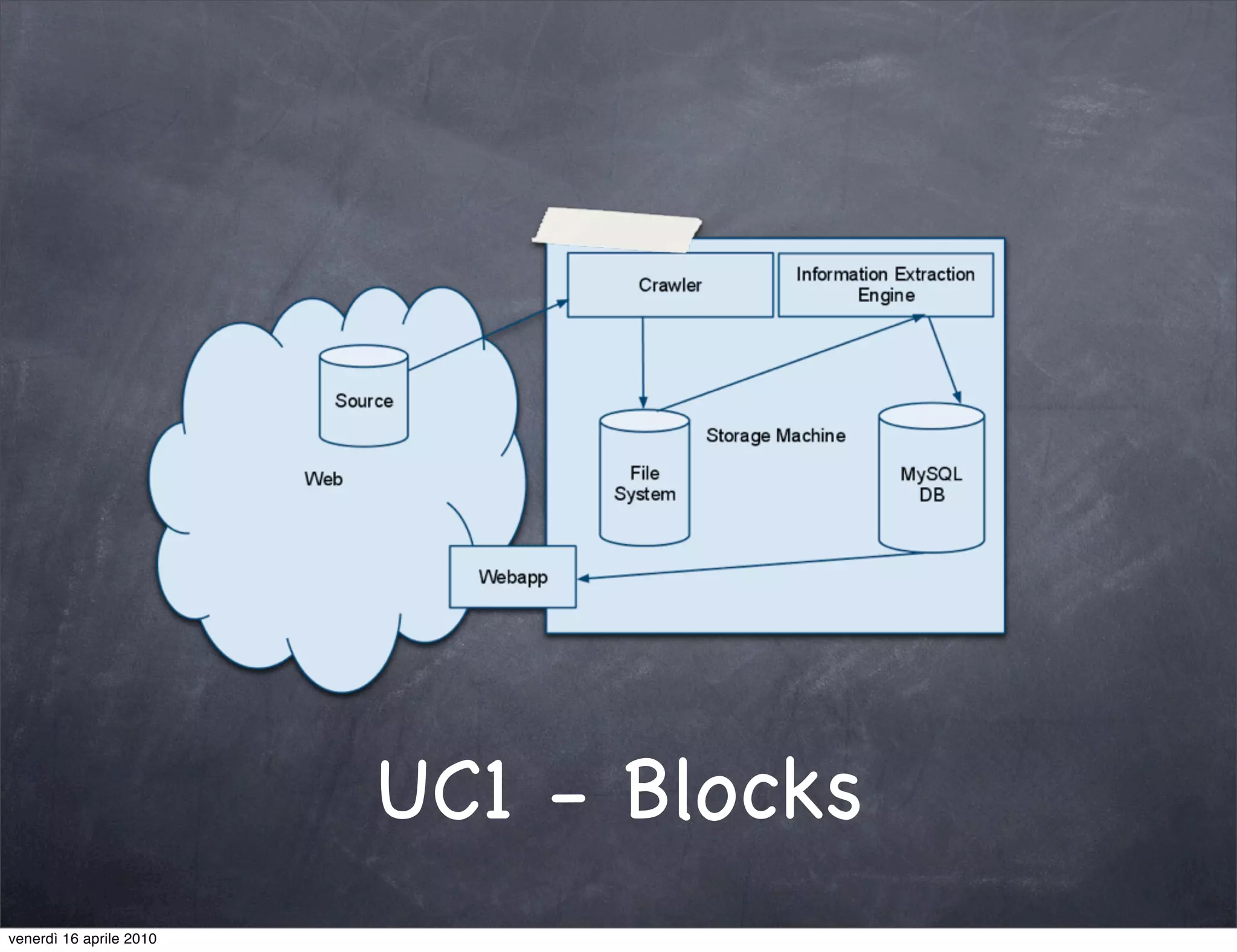


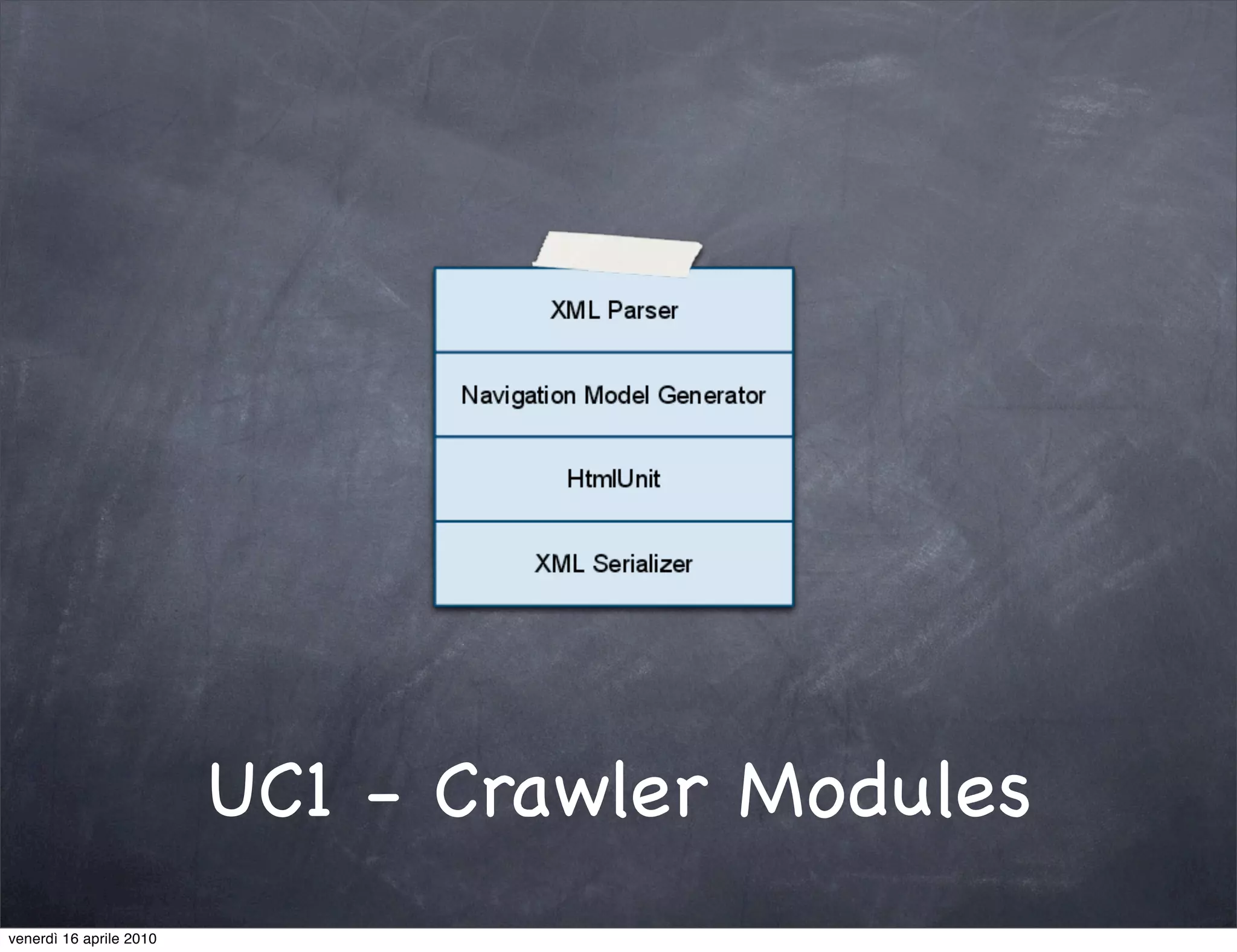






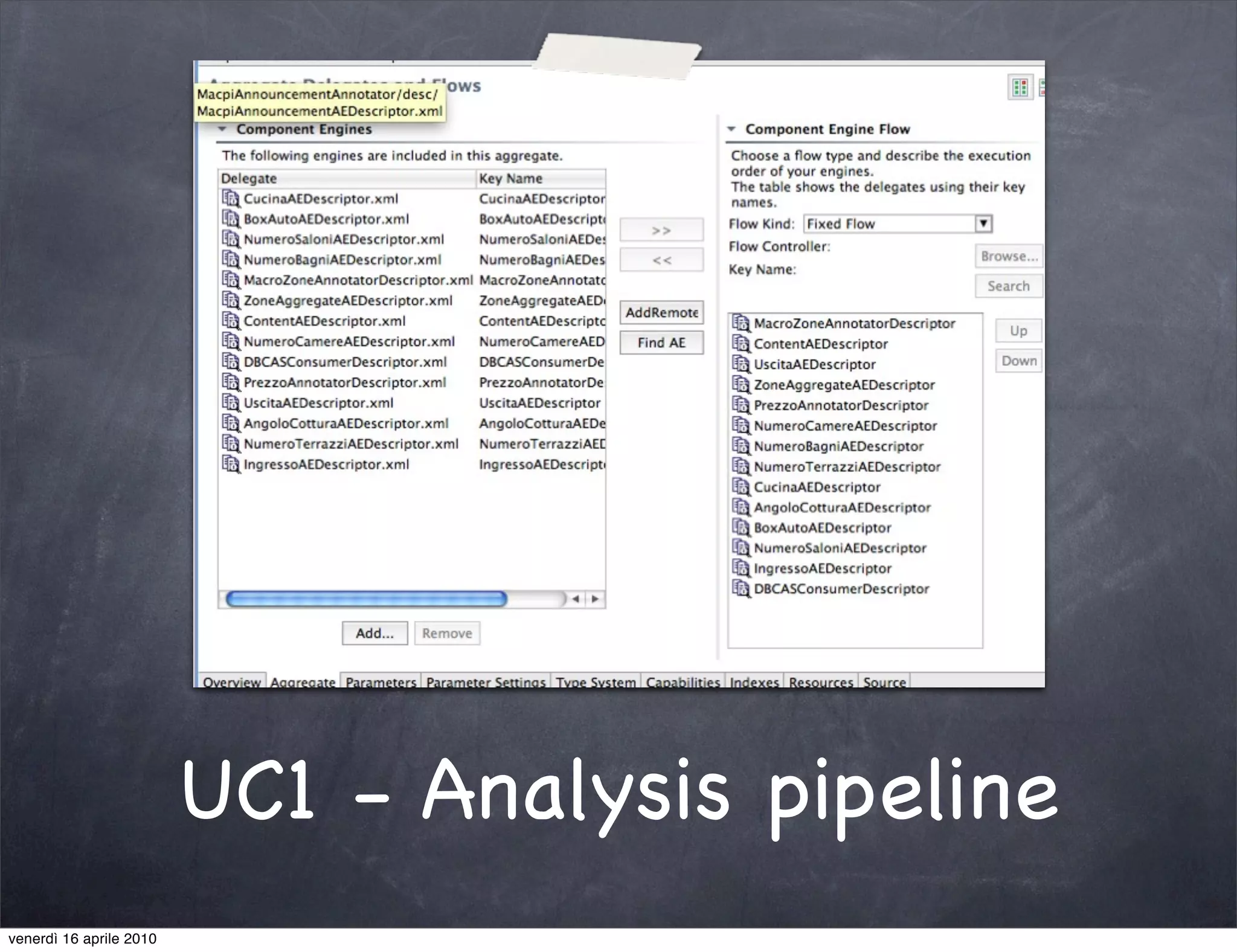
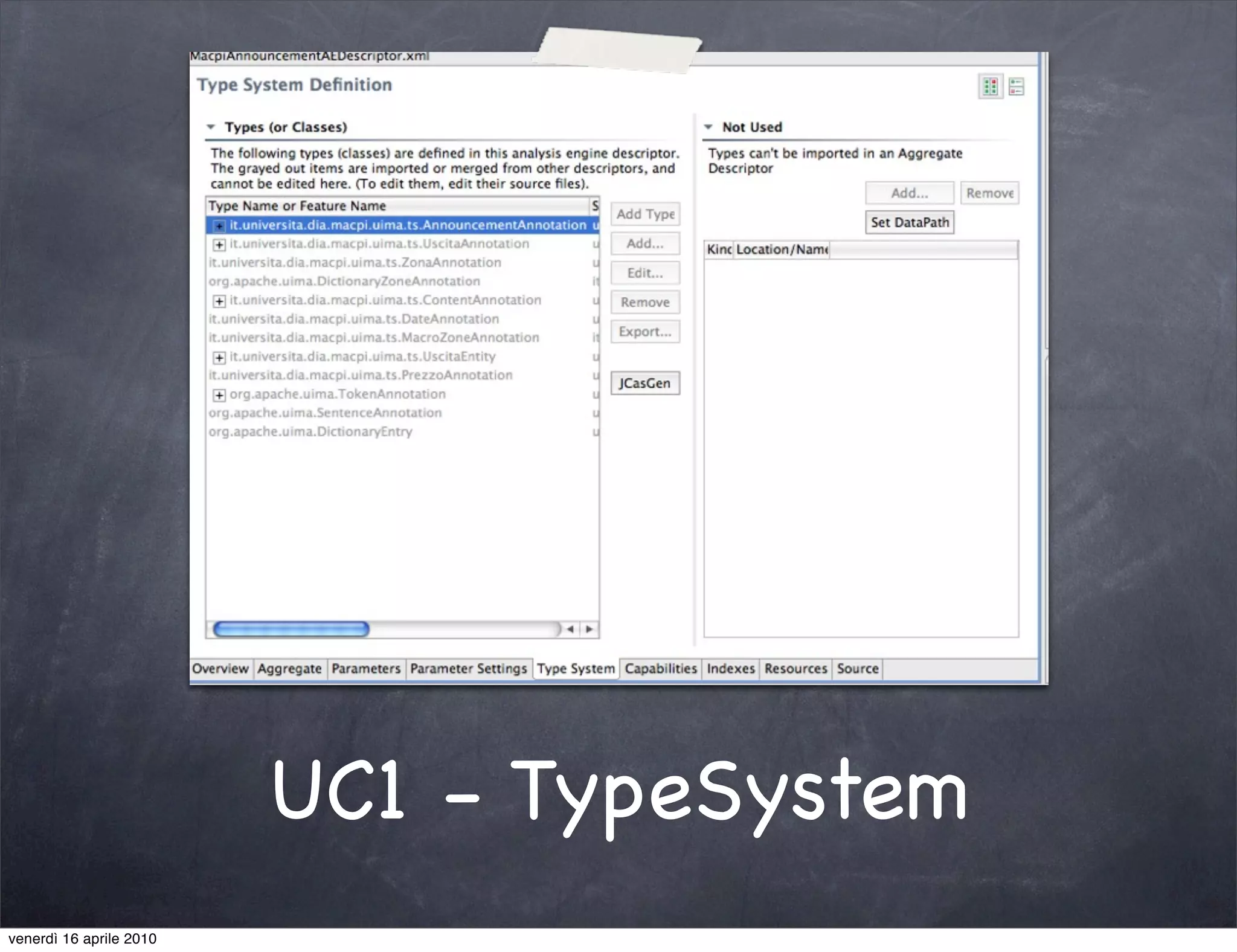
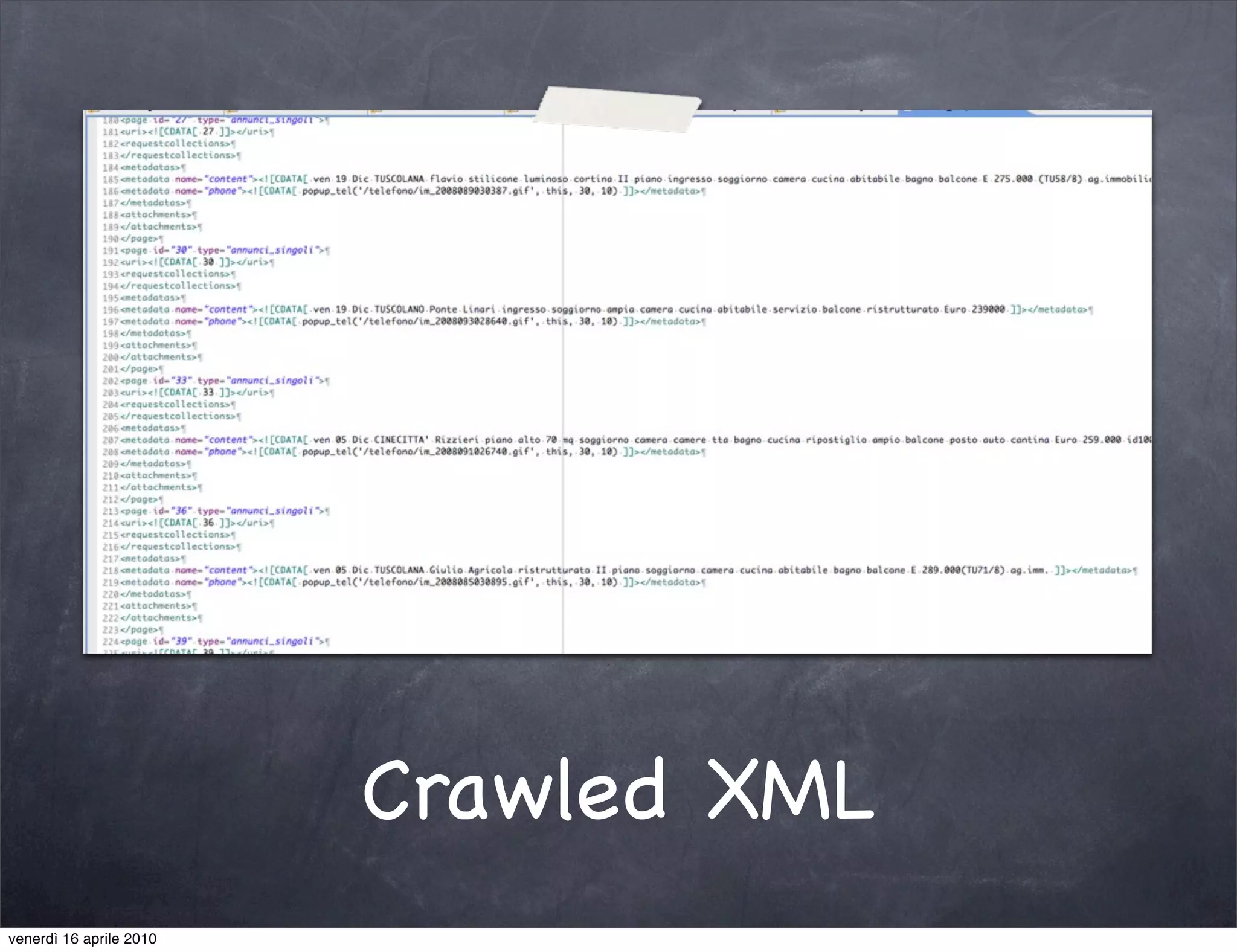



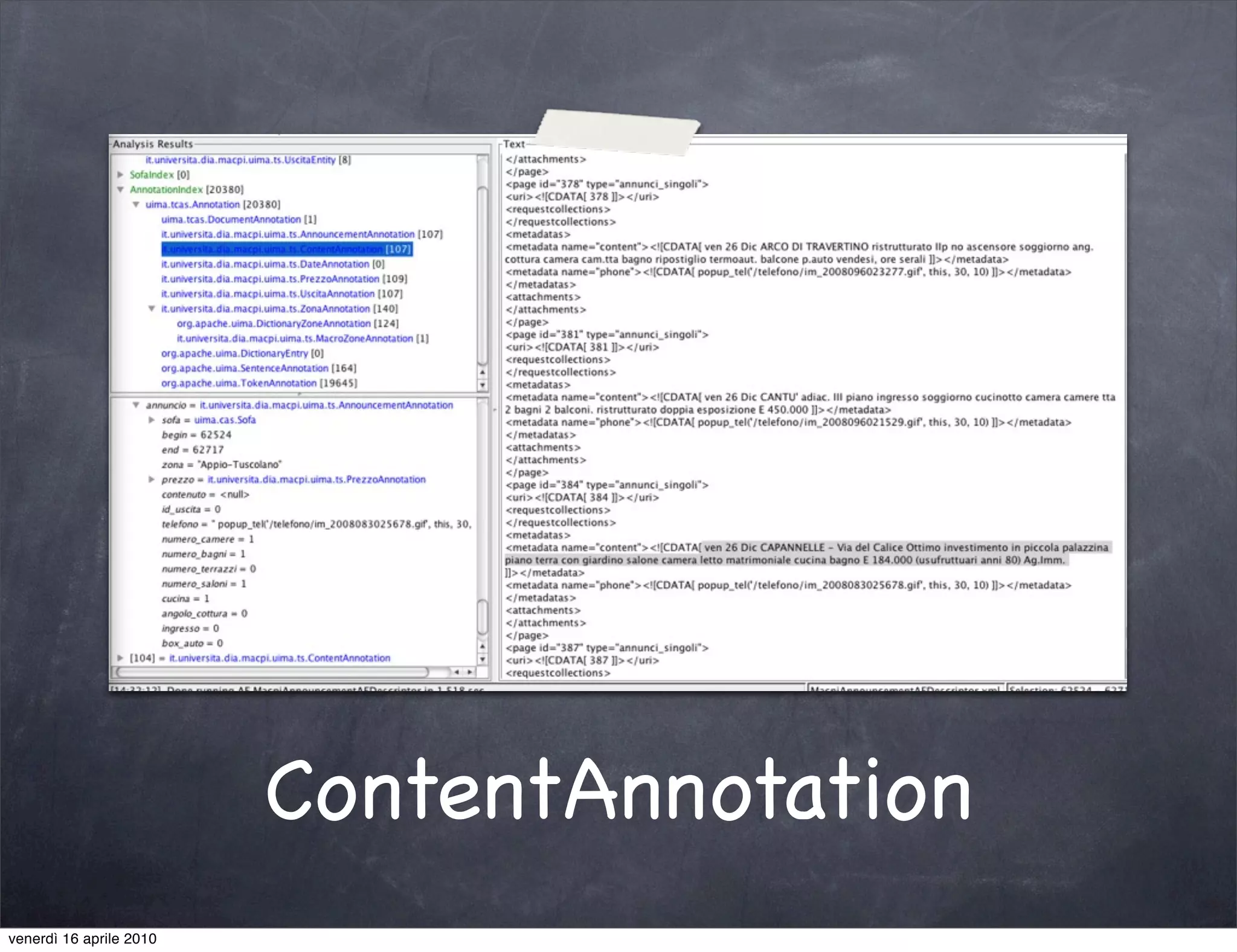
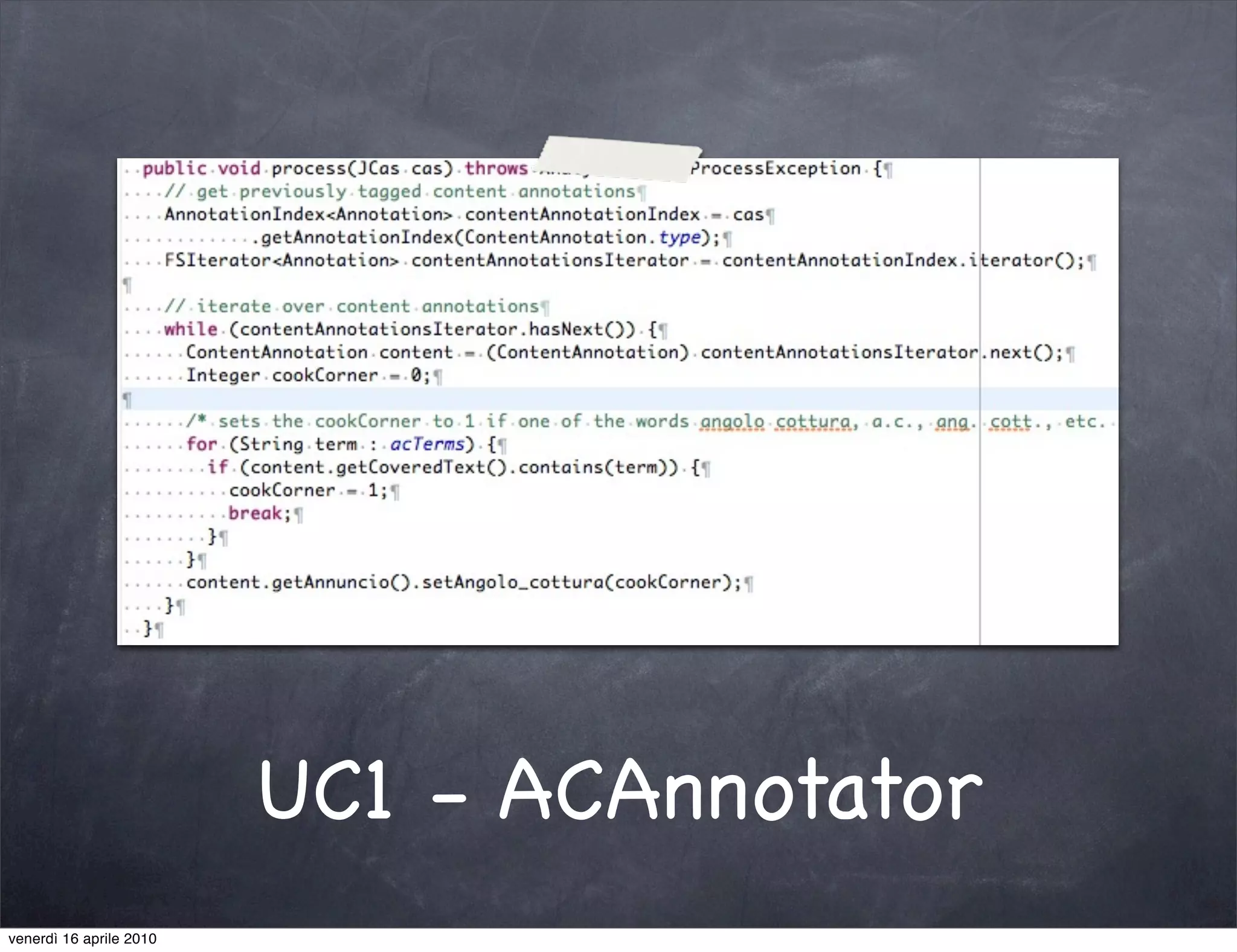
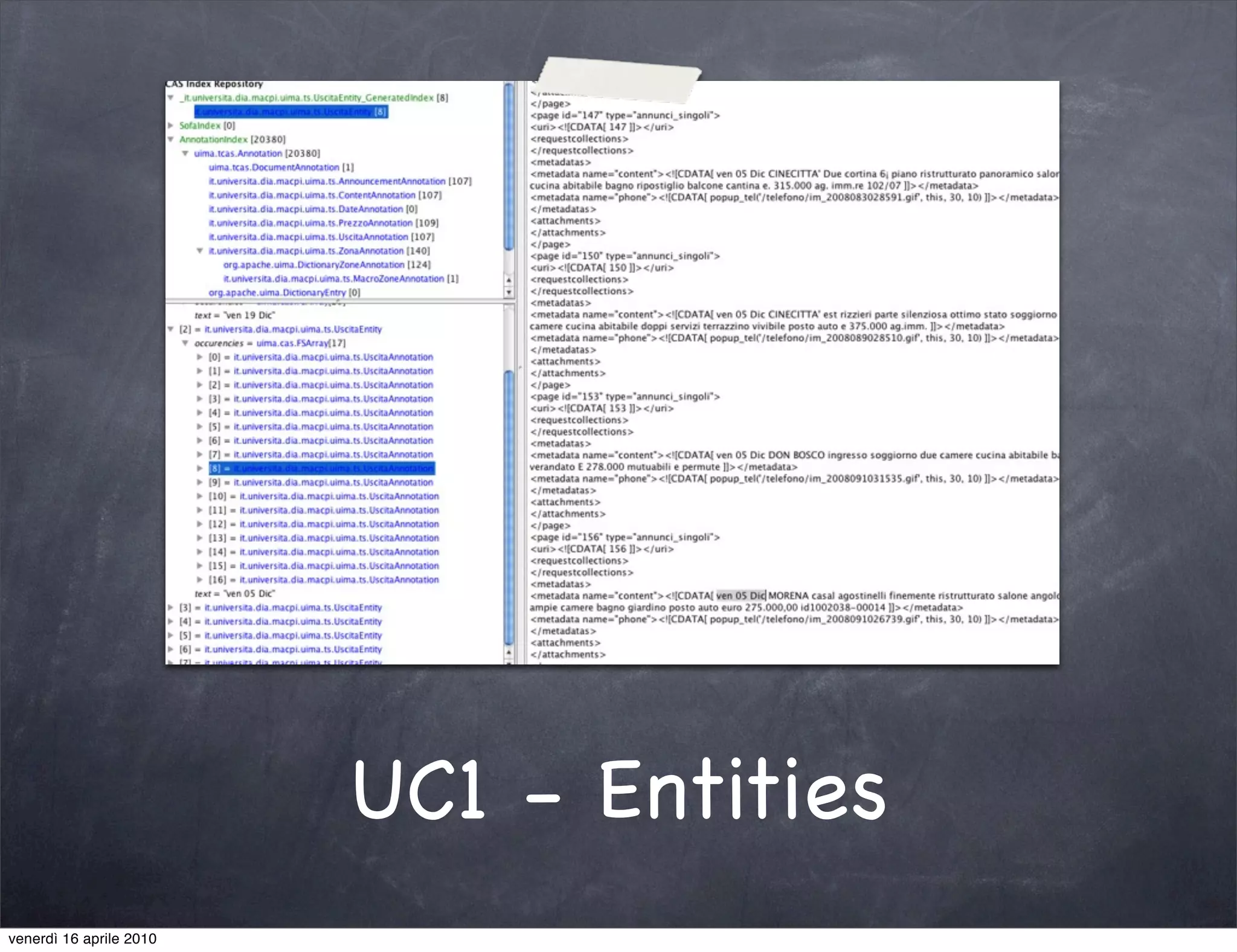


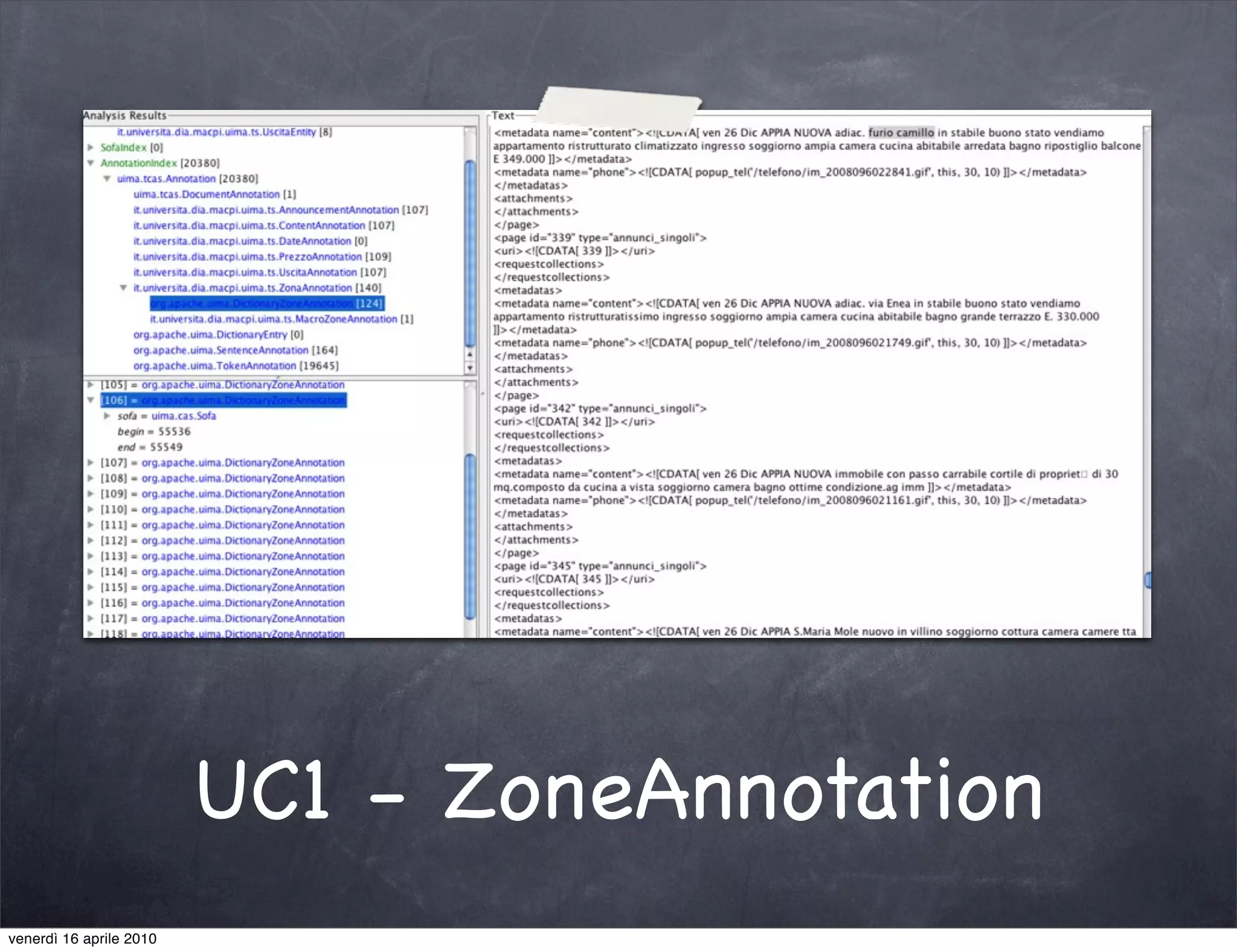


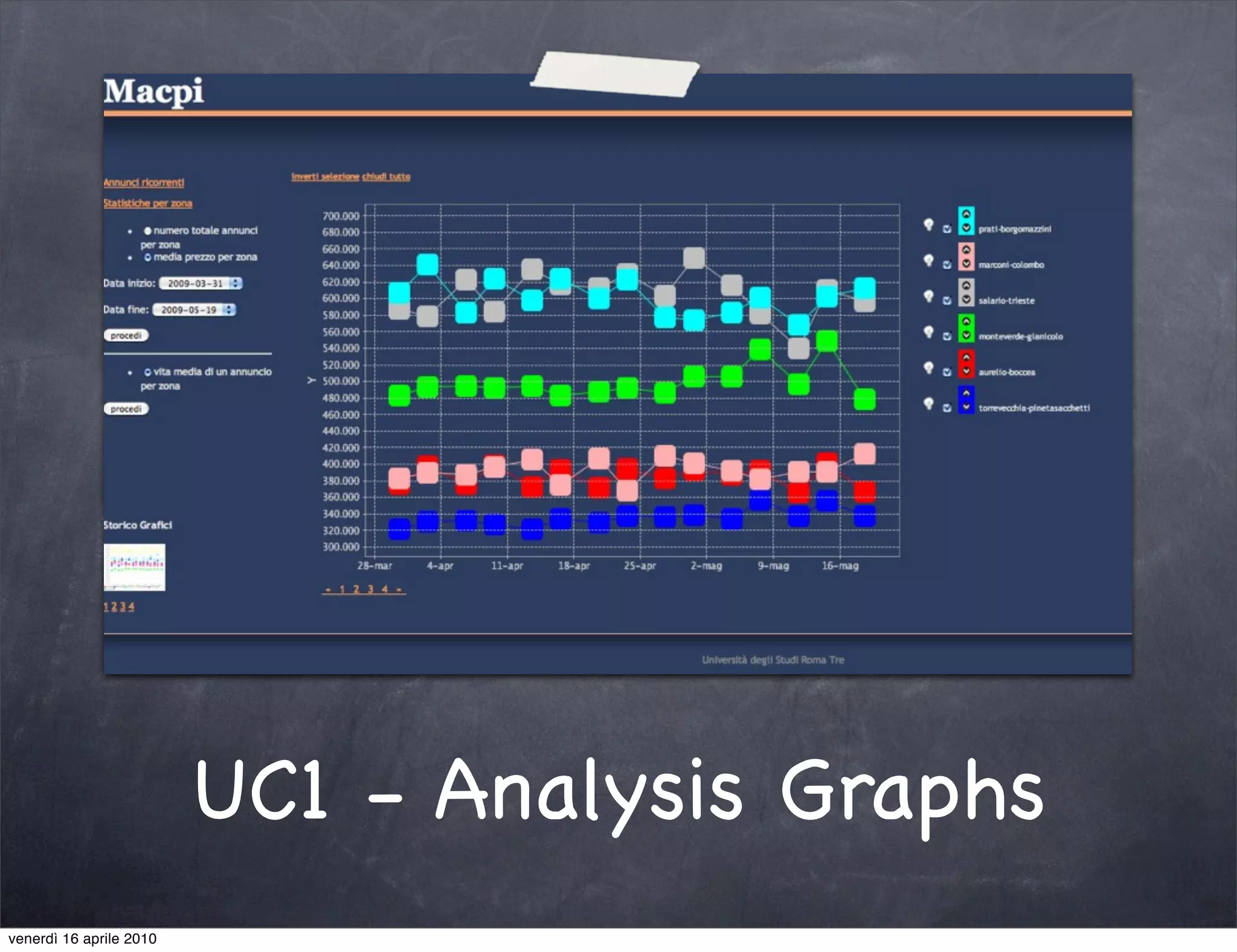
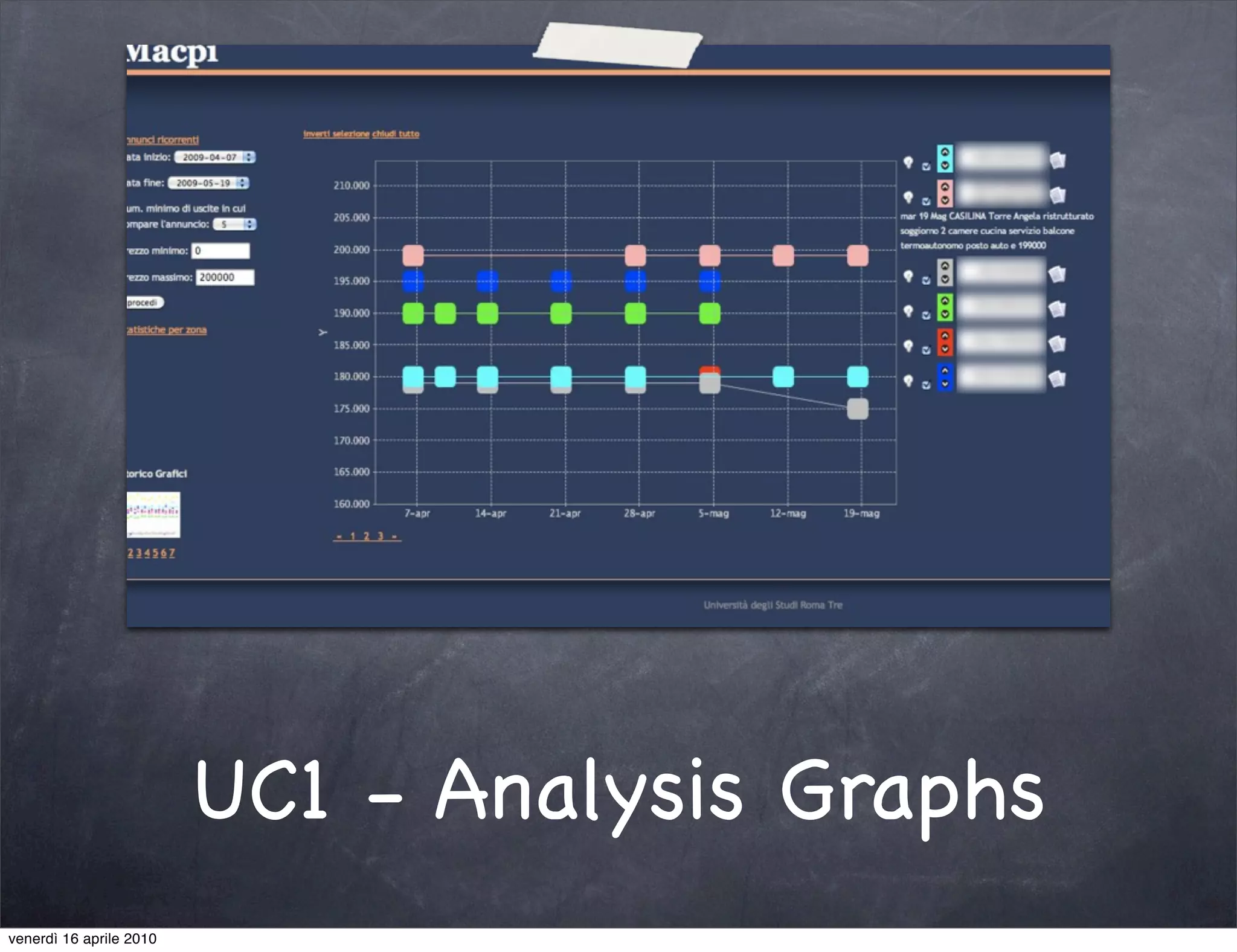

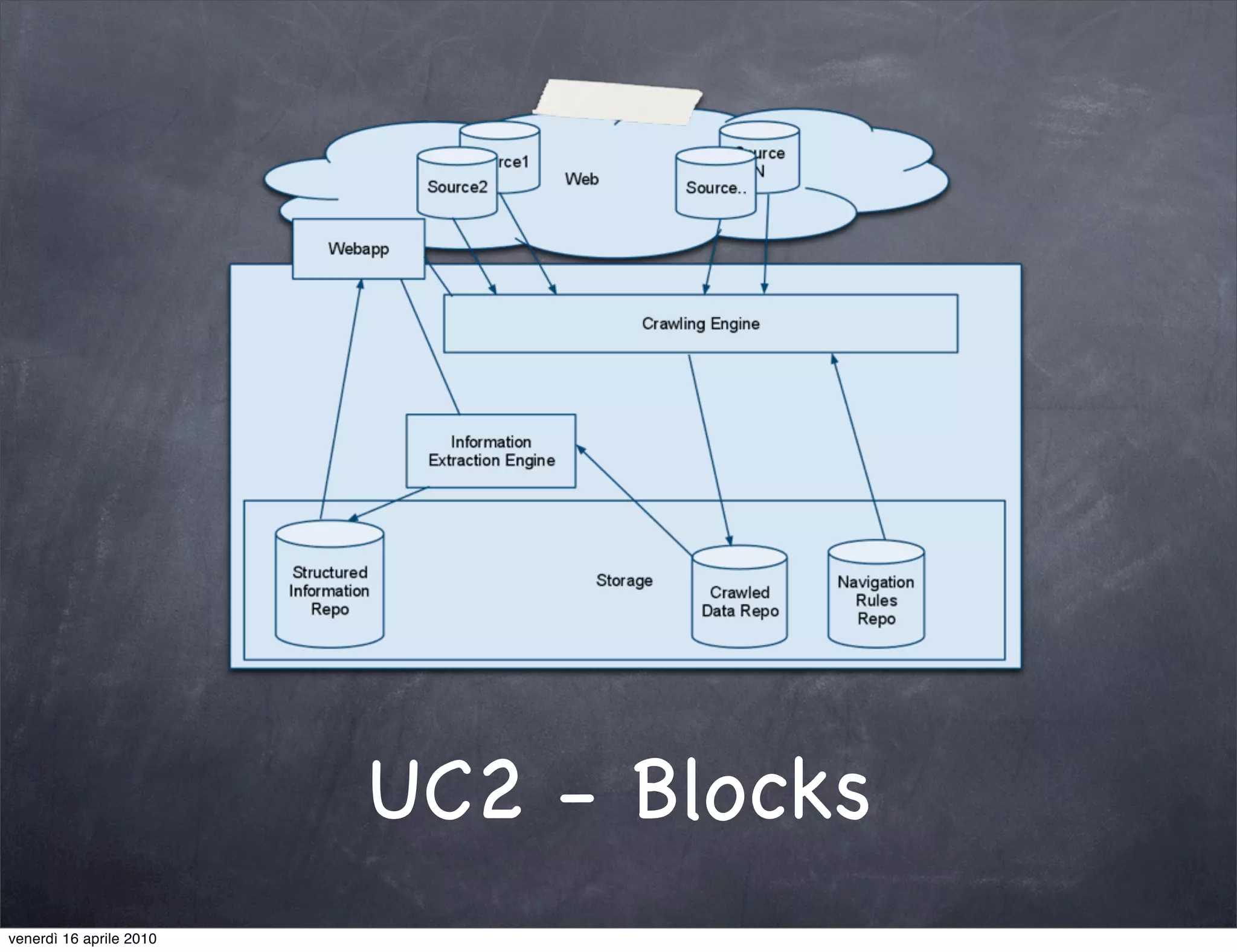
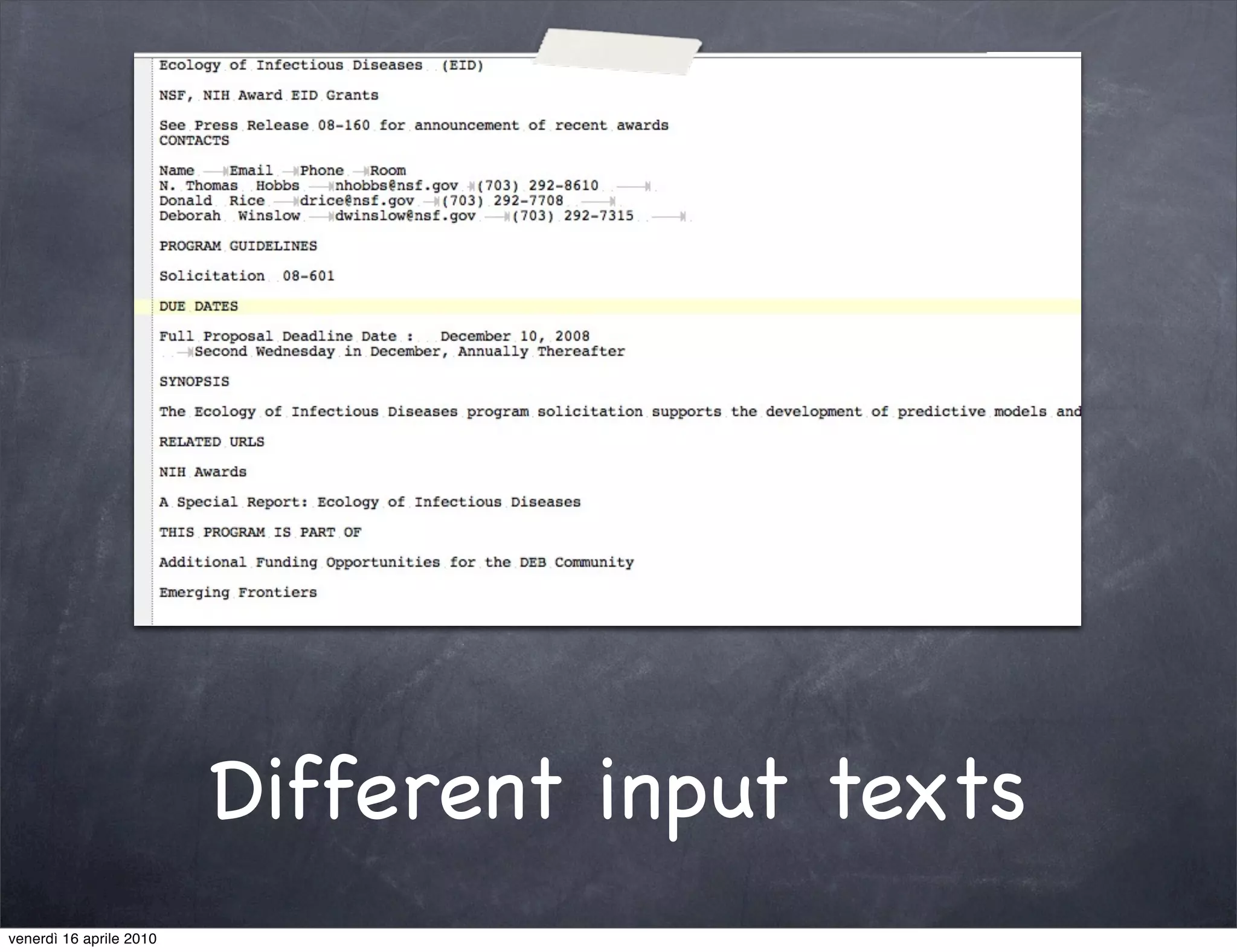




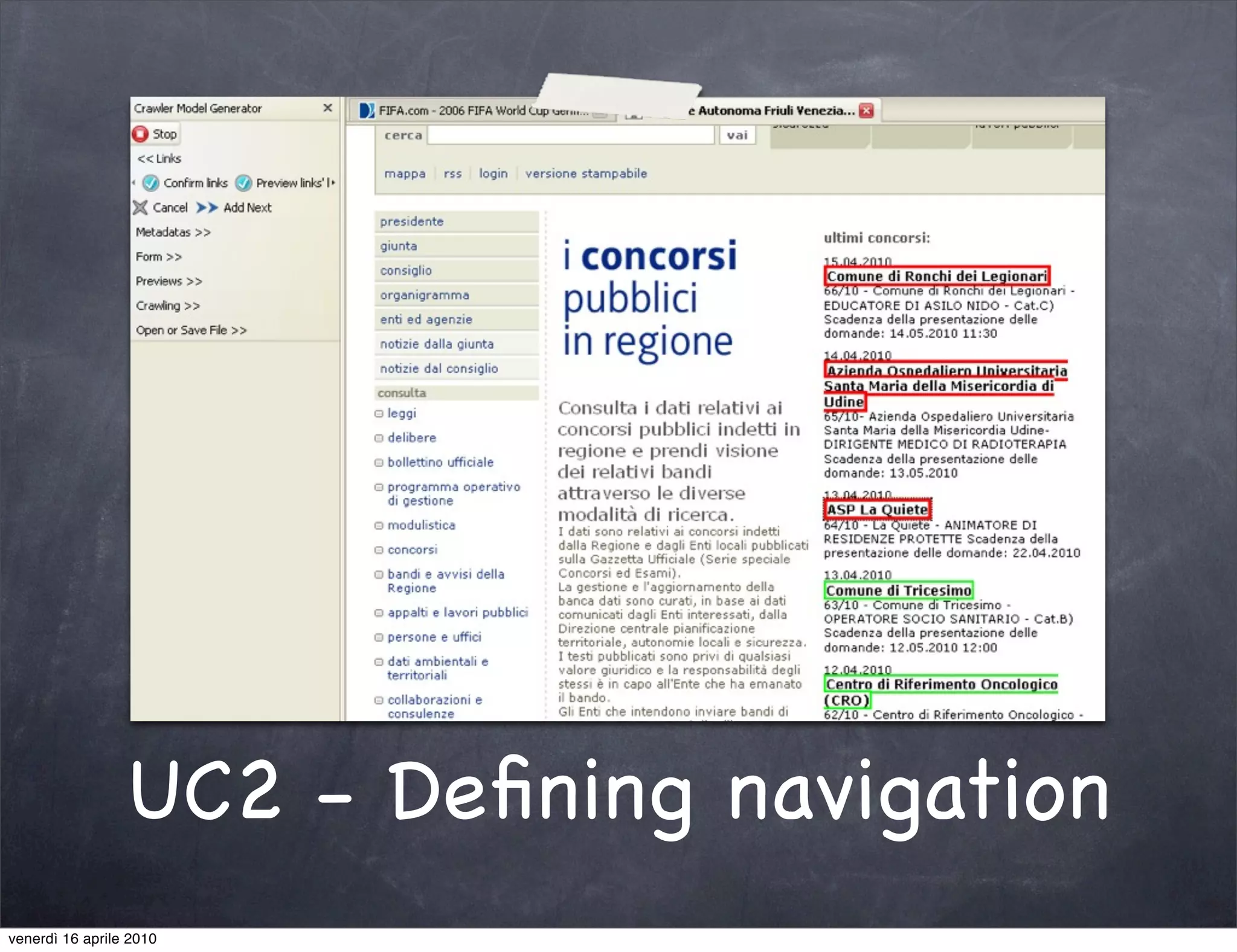


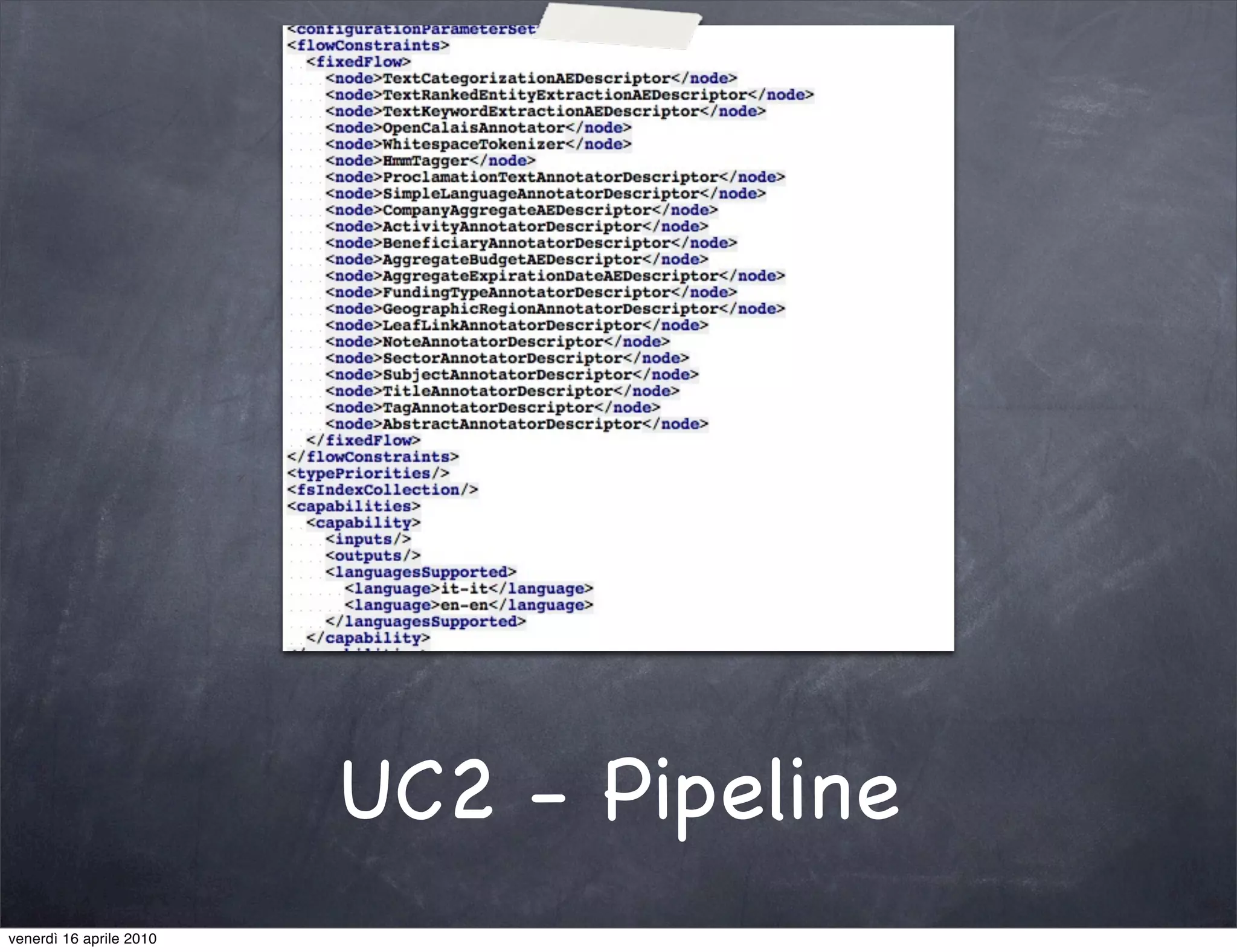





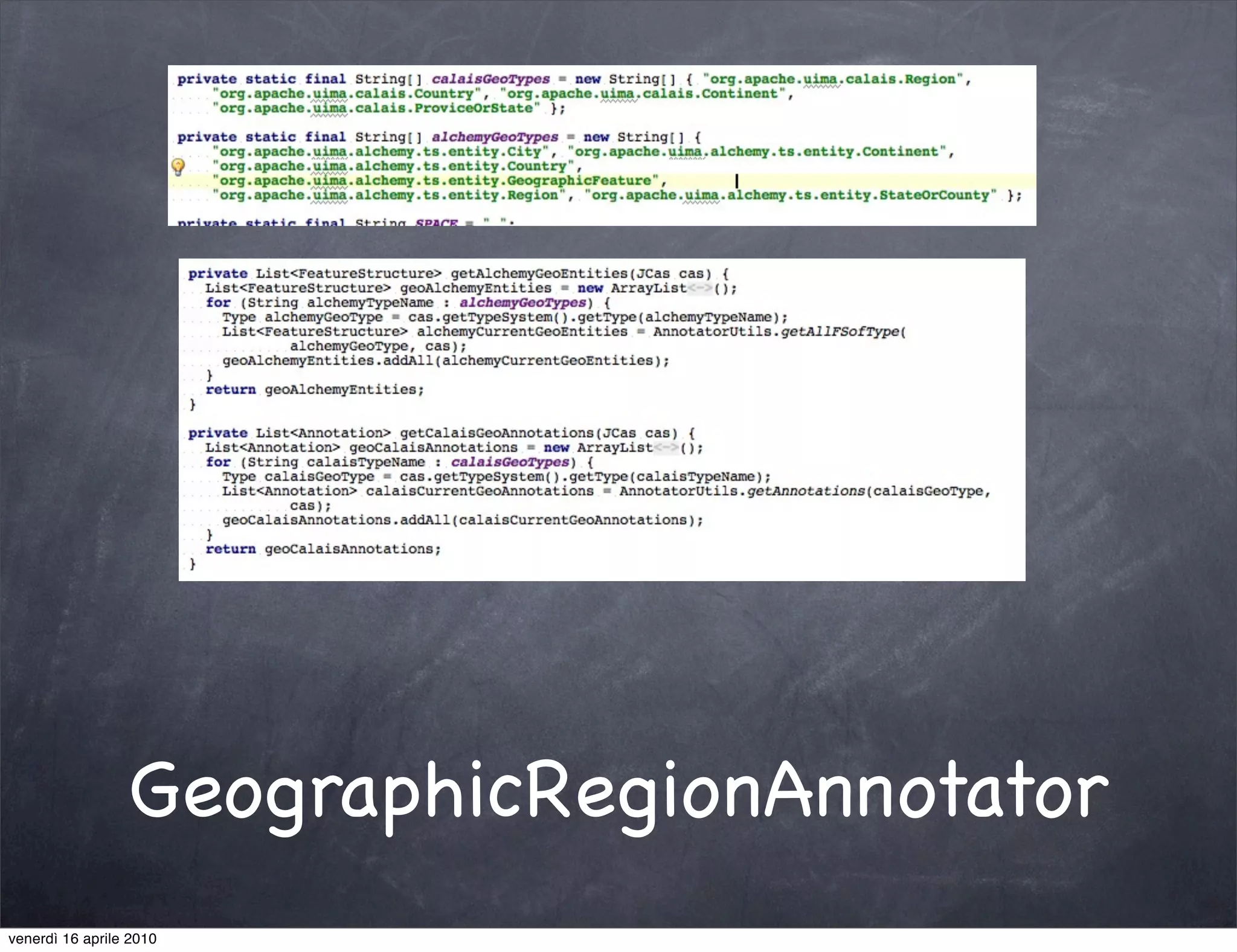




The document discusses the use cases of information extraction with UIMA, focusing on real estate market analysis and automated monitoring of tenders. It outlines the goals of building an information extraction engine to process unstructured estate listings and automate the monitoring of relevant announcements. The approach involves using specialized crawlers, annotators, and a structured analysis pipeline to extract and manage data efficiently.
















![[EN] Capture Indexing & Auto-Classification | DLM Forum Industry Whitepaper 0...](https://cdn.slidesharecdn.com/ss_thumbnails/dlmforumindustrywhitepaper01captureindexingauto-classificationser20020618-150824091618-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)







































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)




