Downloaded 30 times





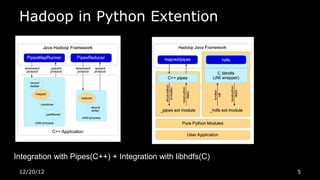
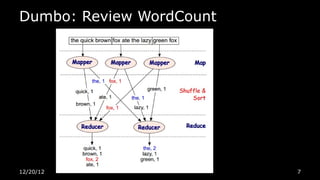


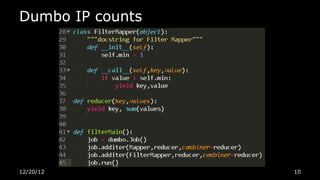





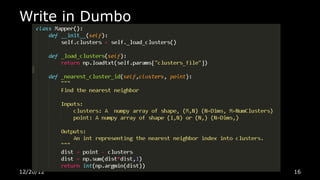
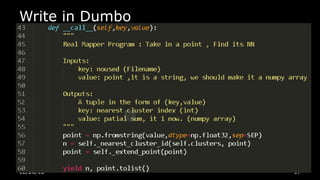
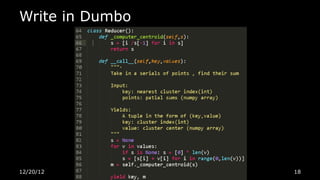



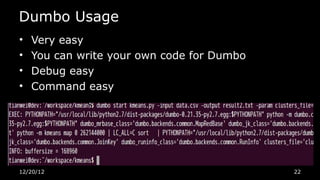




This document discusses using Python for Hadoop and data mining. It introduces Dumbo, which allows writing Hadoop programs in Python. K-means clustering in MapReduce is also covered. Dumbo provides a Pythonic API for MapReduce and allows extending Hadoop functionality. Examples demonstrate implementing K-means in Dumbo and optimizing it by computing partial centroids locally in mappers. The document also lists Python books and tools for data mining and scientific computing.













































![[Harvard CS264] 08b - MapReduce and Hadoop (Zak Stone, Harvard)](https://cdn.slidesharecdn.com/ss_thumbnails/cs264hadooplecture2011-110322172329-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



















