Download to read offline



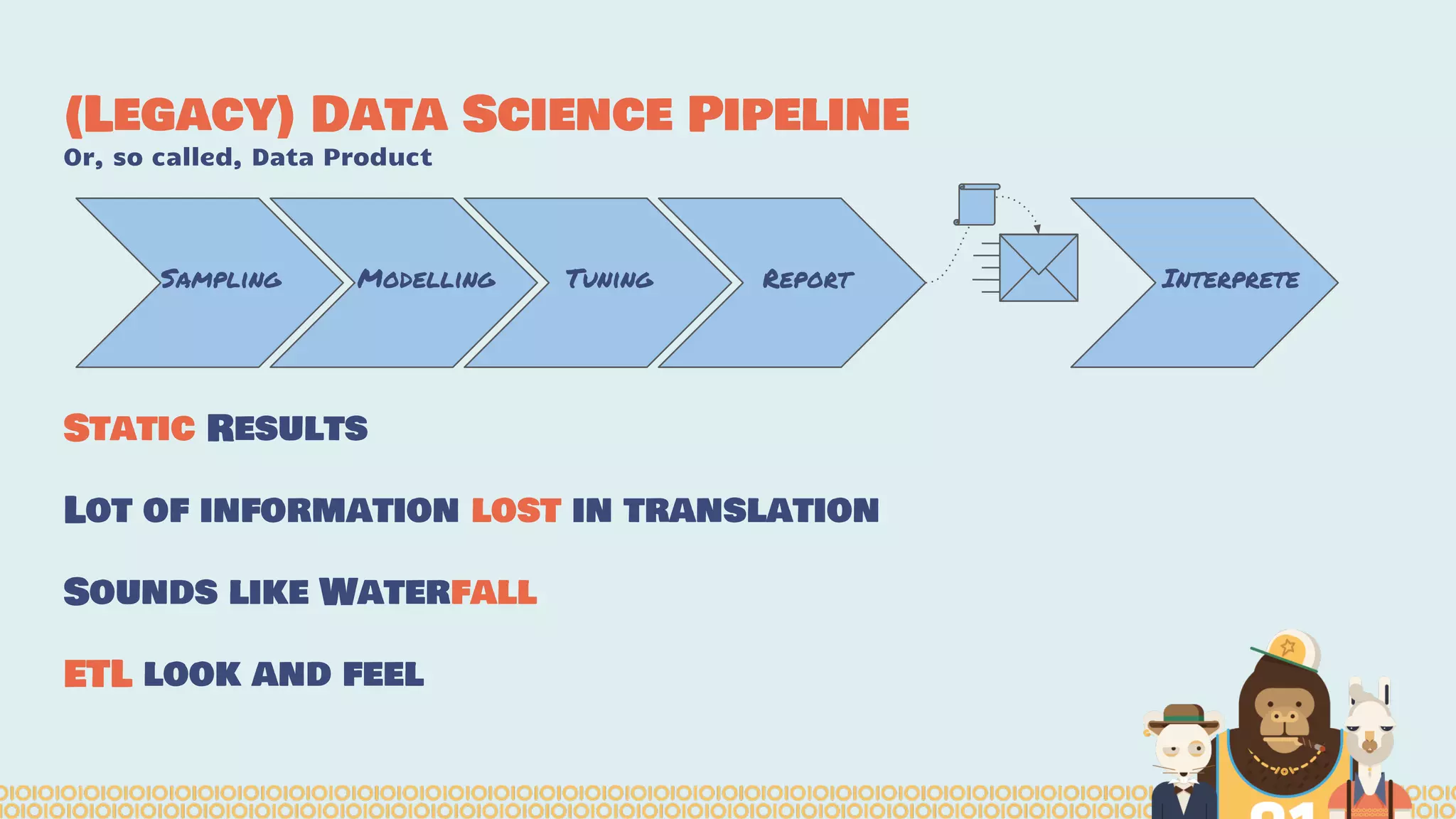
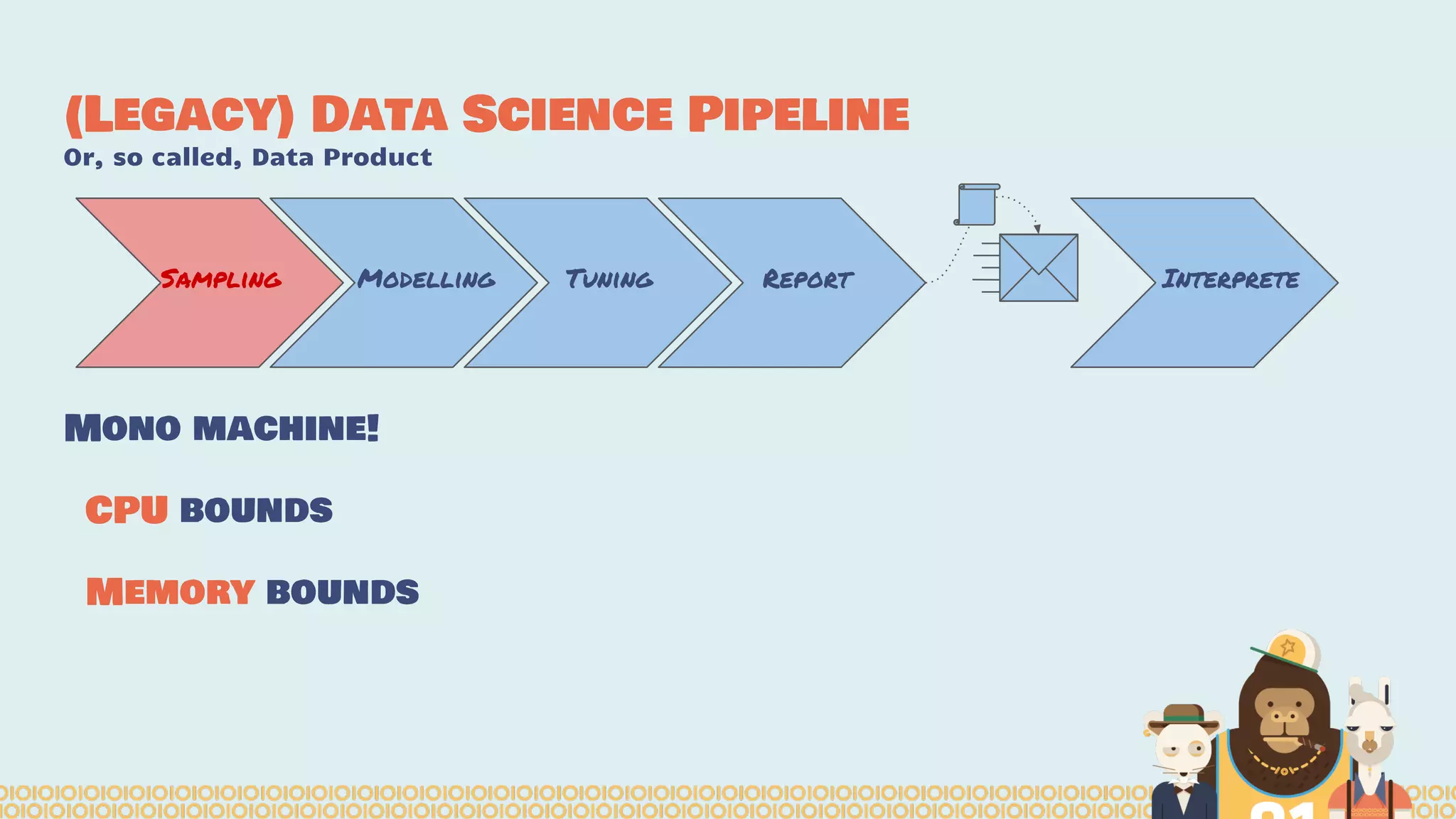

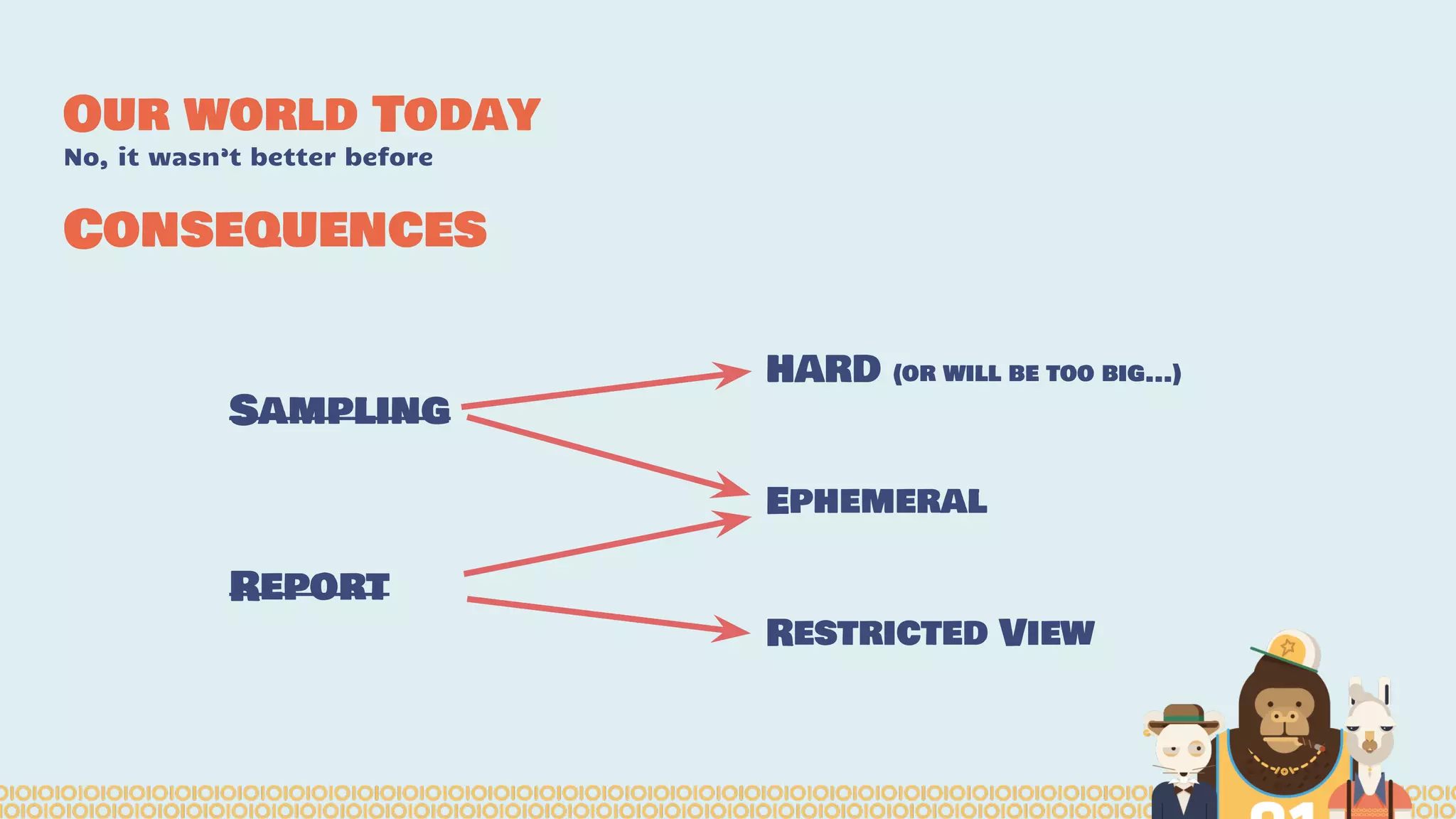












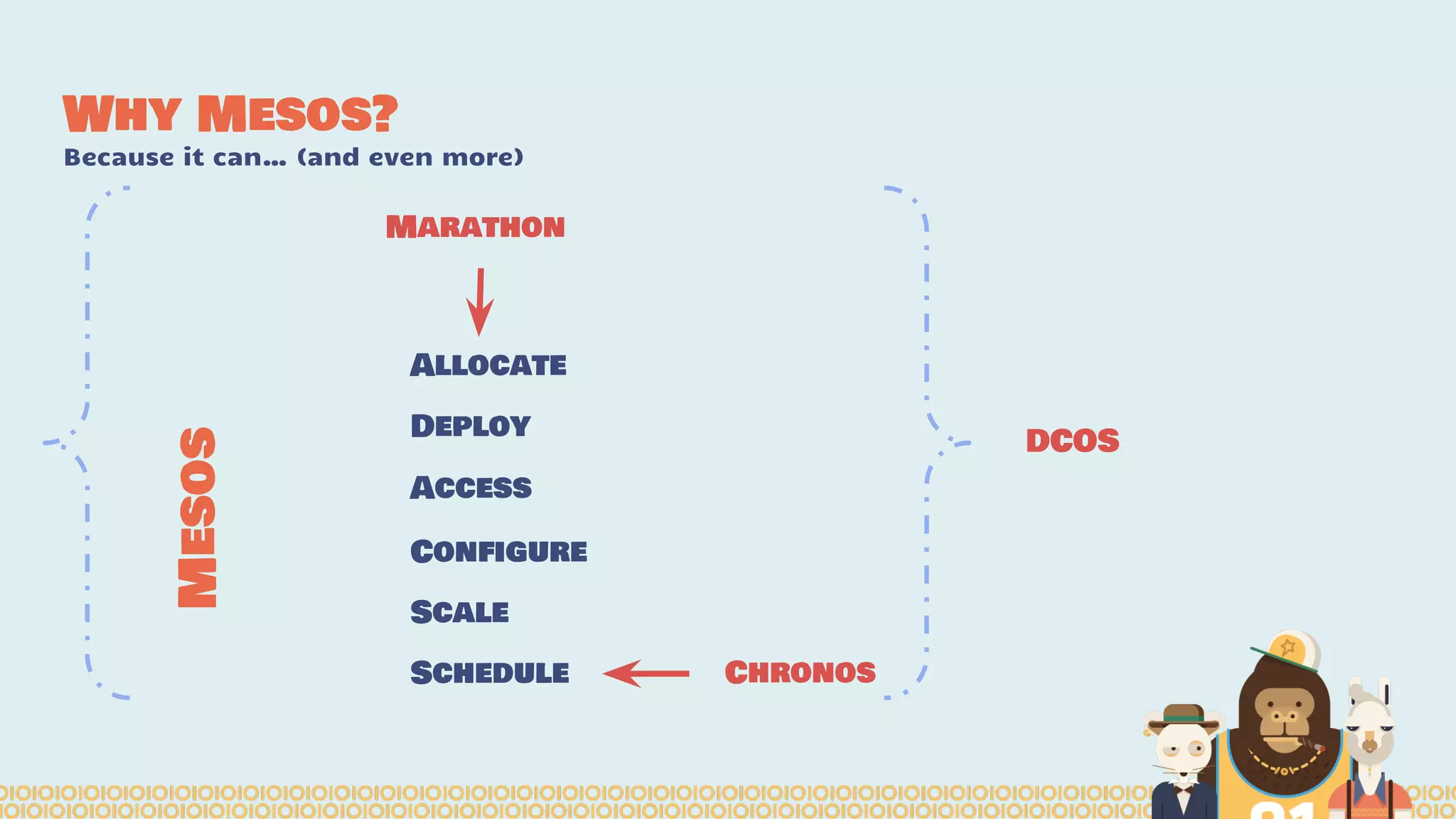




The document discusses the evolution and importance of distributed data science platforms like Mesos in handling big data effectively. It highlights the challenges in legacy data science pipelines and the need for modern, scalable solutions to manage vast amounts of data efficiently. The authors advocate for interactivity, reactivity, and improved productivity within data science teams through the use of advanced tools and technologies.


















































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)




