Downloaded 16 times







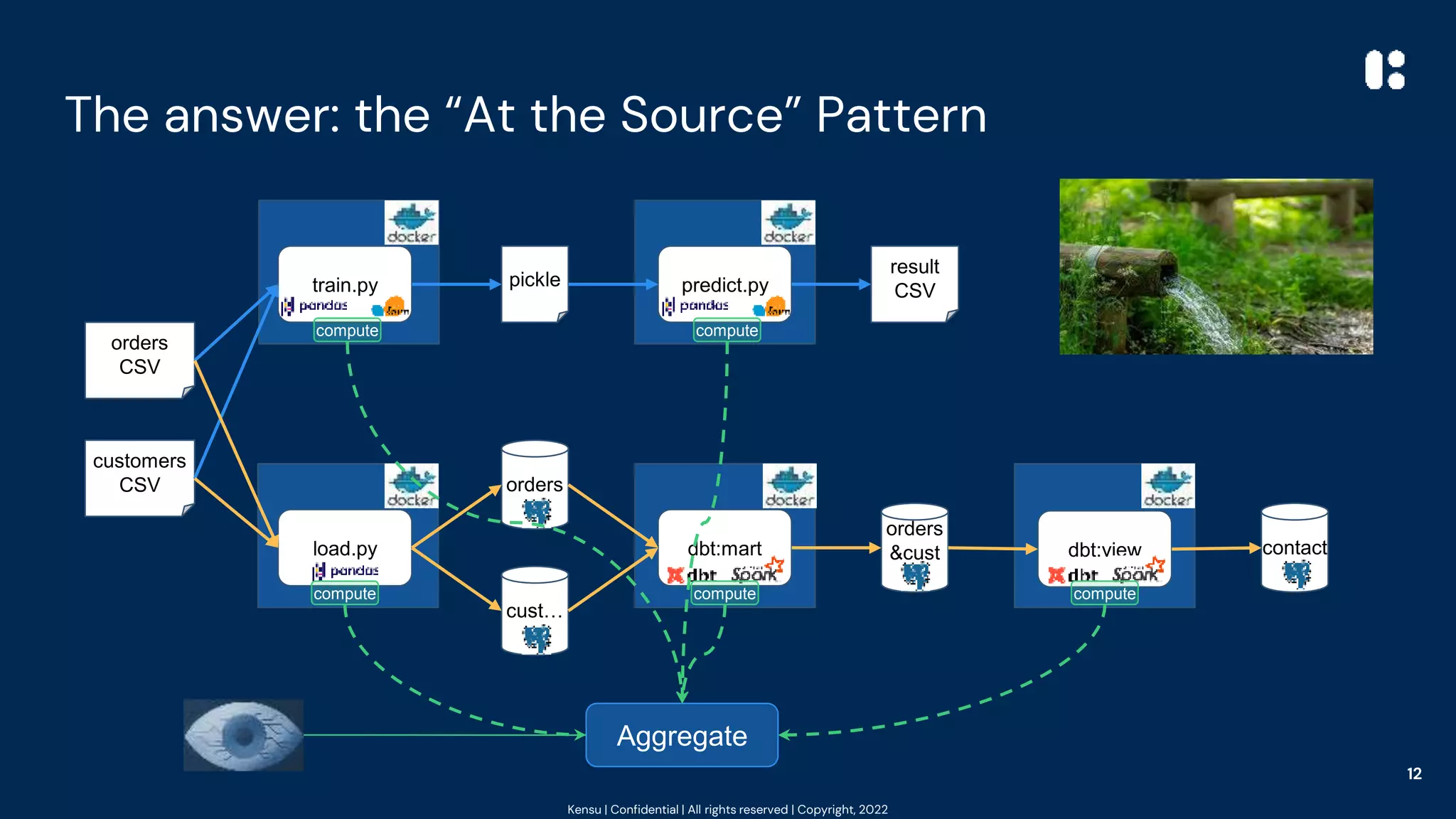
![Kensu | Confidential | All rights reserved | Copyright, 2022
PySpark (& dbt)
spark = SparkSession.builder.appName("MyApp").getOrCreate()
all_assets = spark.read.option("inferSchema","true")
.option("header","true")
.csv("monthly_assets.csv")
apptech = all_assets[all_assets['Symbol'] == 'APCX']
Buzzfeed = all_assets[all_assets['Symbol'] == 'ENFA']
buzz_report = Buzzfeed.withColumn('Intraday_Delta',
Buzzfeed['Adj Close'] - Buzzfeed['Open'])
apptech_report = apptech.withColumn('Intraday_Delta',
apptech['Adj Close'] - apptech['Open'])
kept_values = ['Open','Adj Close','Intraday_Delta']
final_report_buzzfeed = buzz_report[kept_values]
final_report_apptech = apptech_report[kept_values]
final_report_buzzfeed.write.mode('overwrite').csv("report_bf.csv")
final_report_apptech.write.mode('overwrite').csv("report_afcsv")
spark = SparkSession.builder.appName("MyApp")
.config("spark.driver.extraClassPath",
"kensu-spark-
agent.jar").getOrCreate()
init_kensu_spark(spark, input_stats=True)
all_assets = spark.read.option("inferSchema","true")
.option("header","true")
.csv("monthly_assets.csv")
apptech = all_assets[all_assets['Symbol'] == 'APCX']
Buzzfeed = all_assets[all_assets['Symbol'] == 'ENFA']
buzz_report = Buzzfeed.withColumn('Intraday_Delta',
Buzzfeed['Adj Close'] - Buzzfeed['Open'])
apptech_report = apptech.withColumn('Intraday_Delta',
apptech['Adj Close'] - apptech['Open'])
kept_values = ['Open','Adj Close','Intraday_Delta']
final_report_buzzfeed = buzz_report[kept_values]
final_report_apptech = apptech_report[kept_values]
final_report_buzzfeed.write.mode('overwrite').csv("report_bf.csv")
final_report_apptech.write.mode('overwrite').csv("report_afcsv")
14
Input
Filters
Computations
Select
2 Outputs
Interceptor
Logger
Extract from DAG:
- DataFrames
(I/O)
- Location
- Schema
- Metrics
- Lineage](https://image.slidesharecdn.com/dataobservabilitybestpracices-220828103431-70ae7028/75/Data-Observability-Best-Pracices-14-2048.jpg)
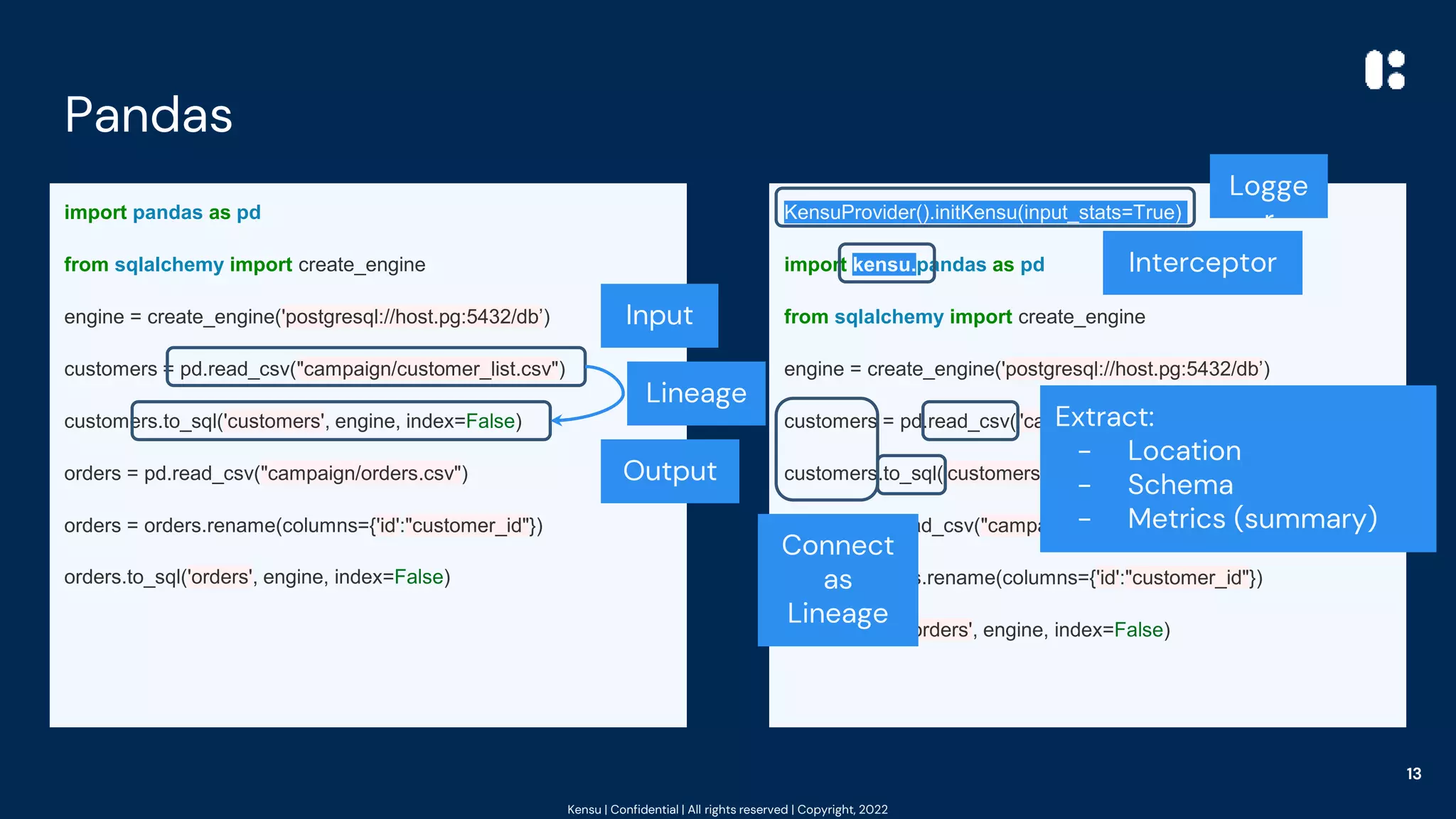
![Kensu | Confidential | All rights reserved | Copyright, 2022
k = KensuProvider().initKensu(input_stats=True)
Import kensu.pickle as pickle
from kensu.sklearn.model_selection import train_test_split
import kensu.pandas as pd
data = pd.read_csv("orders.csv")
df=data[['total_qty', 'total_basket']]
X = df.drop('total_basket',axis=1)
y = df['total_basket']
X_train, X_test, y_train, y_test = train_test_split(X, y)
from kensu.sklearn.linear_model import LinearRegression
model=LinearRegression().fit(X_train,y_train)
with open('model.pickle', 'wb') as f:
pickle.dump(model,f)
Scikit-Learn: 🚂
import pickle as pickle
from sklearn.model_selection import train_test_split
import pandas as pd
data = pd.read_csv("orders.csv")
df=data[['total_qty', 'total_basket']]
X = df.drop('total_basket',axis=1)
y = df['total_basket']
X_train, X_test, y_train, y_test = train_test_split(X, y)
from sklearn.linear_model import LinearRegression
model=LinearRegression().fit(X_train,y_train)
with open('model.pickle', 'wb') as f:
pickle.dump(model,f)
15
Filter
Transformation
Output
Input
Select
Logge
r
Interceptors
Extract:
- Location
- Schema
- Data Metrics
- Model Metrics
Accumulate
connections as
Lineage](https://image.slidesharecdn.com/dataobservabilitybestpracices-220828103431-70ae7028/75/Data-Observability-Best-Pracices-15-2048.jpg)
![Kensu | Confidential | All rights reserved | Copyright, 2022
k = KensuProvider().initKensu(input_stats=True)
import kensu.pandas as pd
import kensu.pickle as pickle
data = pd.read_csv("second_campaign/orders.csv")
with open('model.pickle', 'rb') as f:
model=pickle.load(f)
df=data[['total_qty']]
pred = model.predict(df)
df = data.copy()
df['model_pred']=pred
df.to_csv('model_results.csv', index=False)
Scikit-Learn: 🔮
import pandas as pd
import pickle as pickle
data = pd.read_csv("second_campaign/orders.csv")
with open('model.pickle', 'rb') as f:
model=pickle.load(f)
df=data[['total_qty']]
pred = model.predict(df)
df = data.copy()
df['model_pred']=pred
df.to_csv('model_results.csv', index=False)
2 Inputs
Output
Transformation
Select
Computation
Logge
r
Interceptors
Accumulate
connections as
Lineage
Extract:
- Location
- Schema
- Data Metrics
- Model Metrics?](https://image.slidesharecdn.com/dataobservabilitybestpracices-220828103431-70ae7028/75/Data-Observability-Best-Pracices-16-2048.jpg)




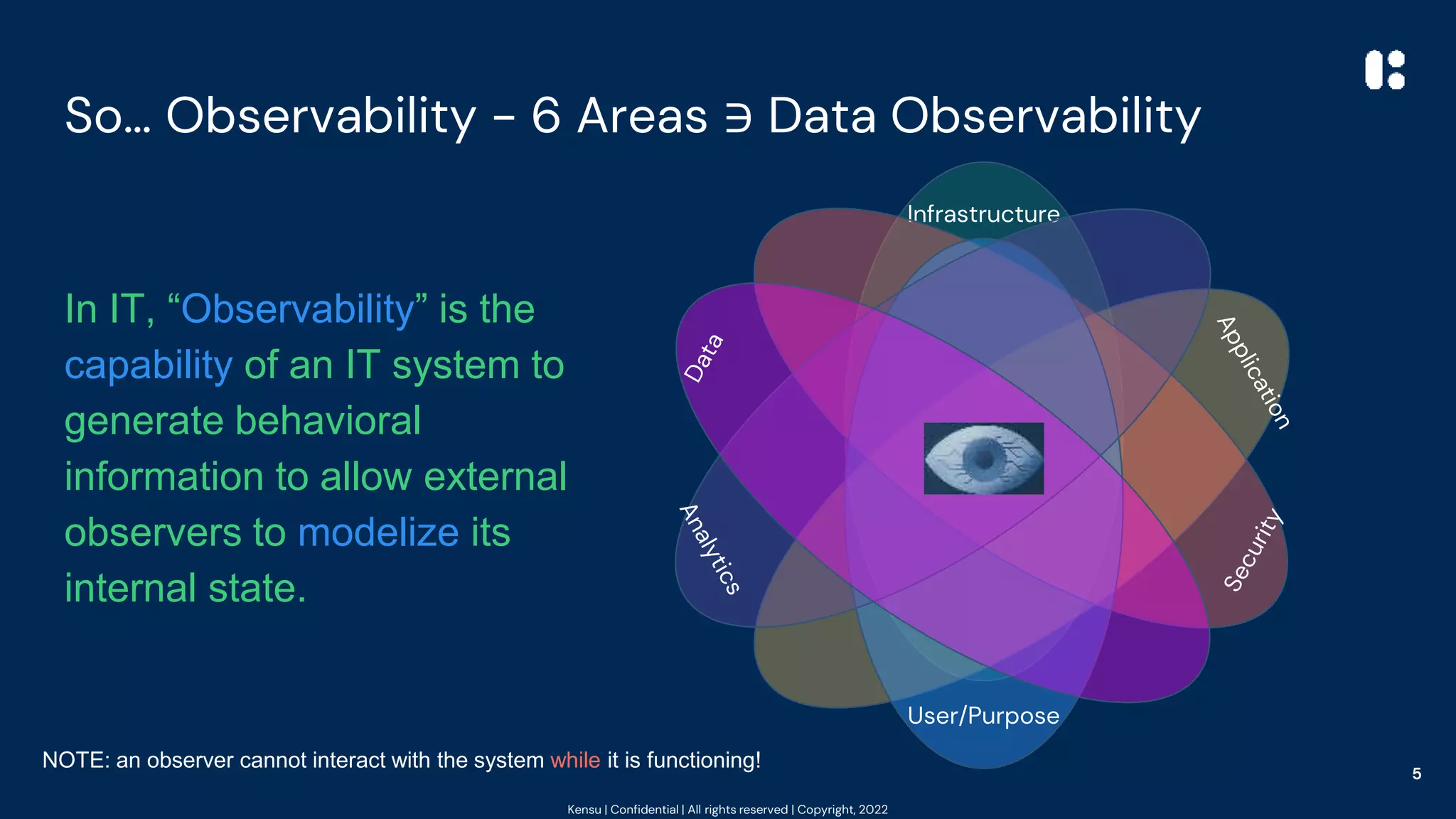
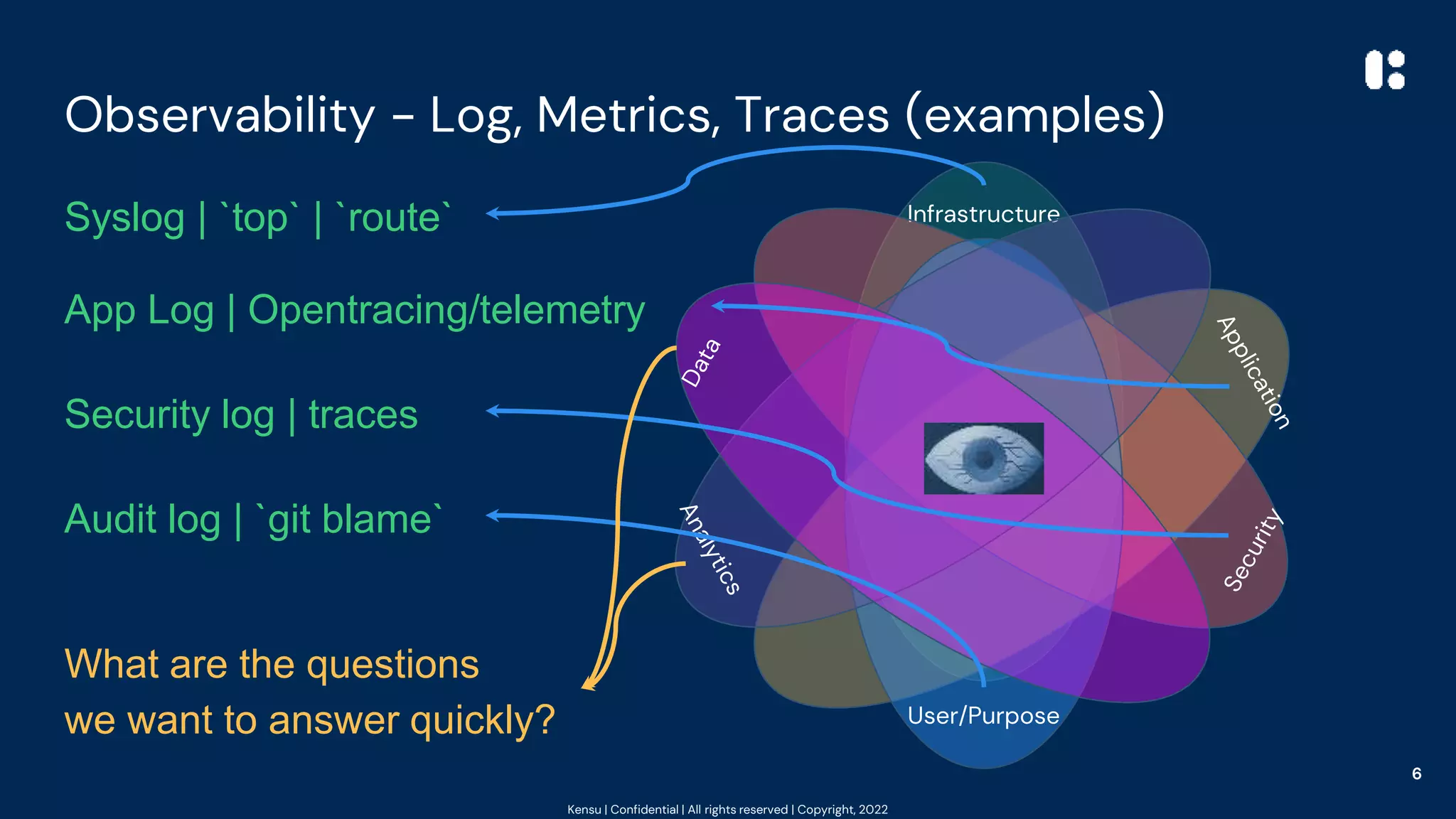
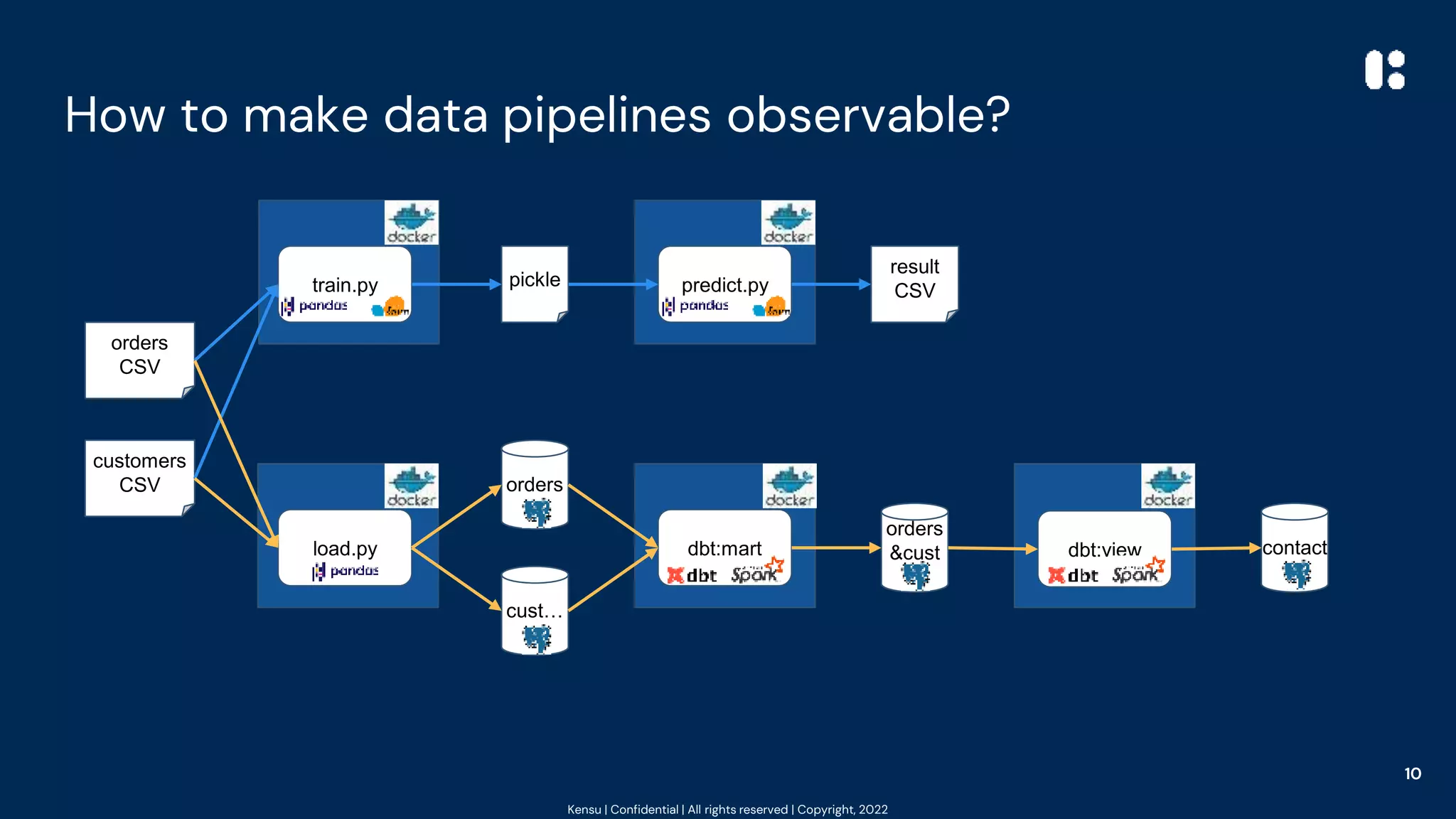
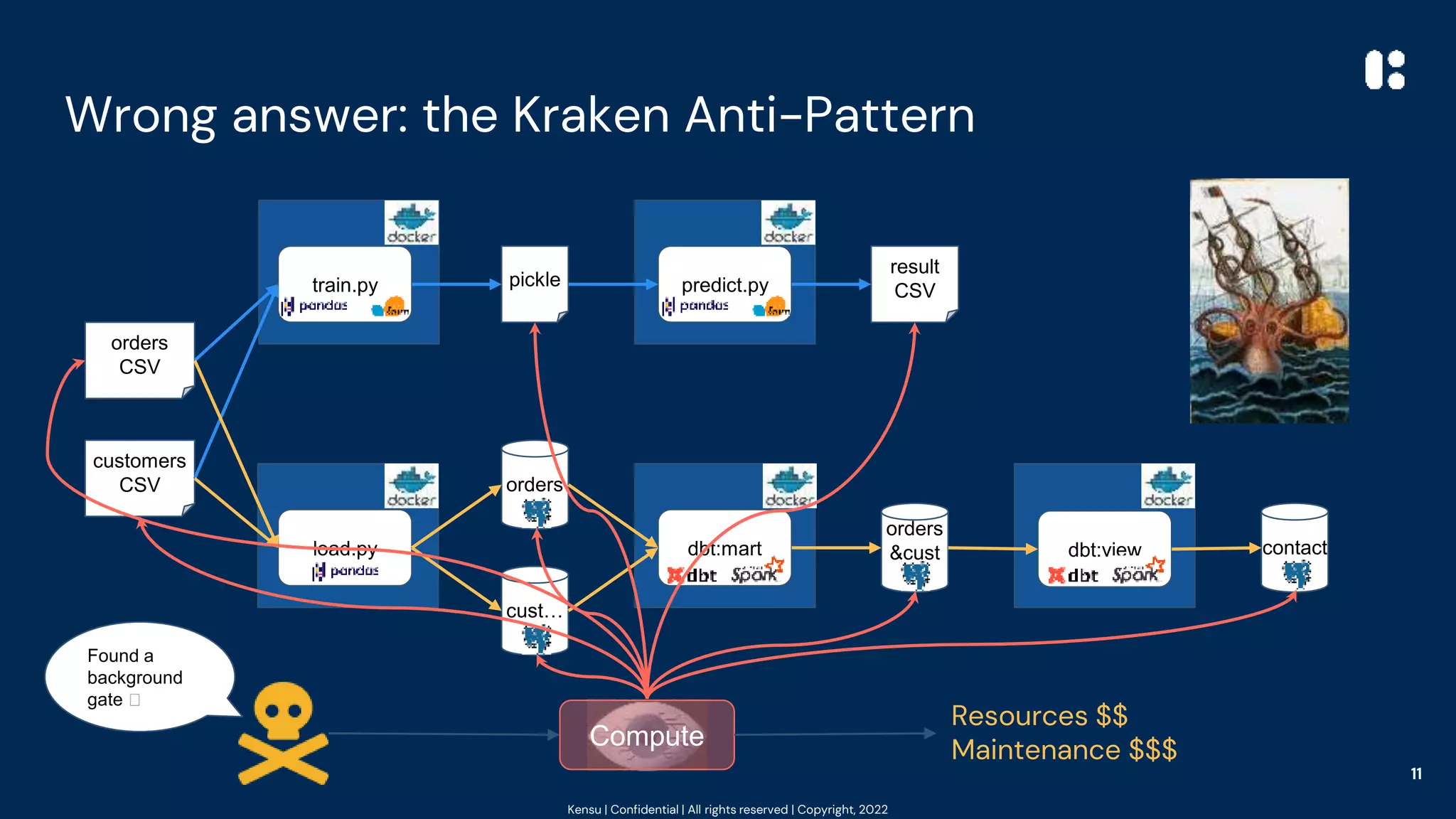
The document outlines best practices for data observability using tools such as Pandas, Scikit-learn, and PySpark, highlighting the author's 20 years of experience in software engineering and data governance. It emphasizes the importance of understanding data's impact on system behavior and introduces the 'at the source' pattern for improving data pipeline observability. Additionally, it provides code examples and resources for implementing these practices effectively.









































































![[DSC Europe 25] Miodrag Pesovic & Vladislav Radonjic - Federated Data Archite...](https://cdn.slidesharecdn.com/ss_thumbnails/gsbe3y5it5uhndi4e08e-1-251212103249-f1008e0c-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Jon Dajci - Bridging TradFi and DeFi: Building the Future of ...](https://cdn.slidesharecdn.com/ss_thumbnails/fqmhfvlbqhkihjvqvhmu-7-251211083849-6af7e325-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Vladimir Jelic - The AI-Driven Security Shift From Reactive D...](https://cdn.slidesharecdn.com/ss_thumbnails/6g5gj25mtjwayniqem1t-6-251209104645-7a5a5fc6-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Milan Sekuloski - Data, Defence, and Development: Cybersecuri...](https://cdn.slidesharecdn.com/ss_thumbnails/dfrkwwx4qly6atqpbl4z-4-251209104645-c3d4b0ca-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Marko Krstic - Understanding the AI Threat Landscape - Risks,...](https://cdn.slidesharecdn.com/ss_thumbnails/tiyim1ins5jvbrvzpzla-2-251209104645-c69d3553-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dusan Nesic - Securing Tomorrow’s Infrastructure: Why Cyber-P...](https://cdn.slidesharecdn.com/ss_thumbnails/qikbszfftyowjm2q6duw-1-251211083848-8f2ead6b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Nikolay Burlutskiy - Best Practices for Building Enterprise M...](https://cdn.slidesharecdn.com/ss_thumbnails/uirvaiuvq8y1w8hzd9tx-7-251212103249-2619edb4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)
