Download as PDF, PPTX


























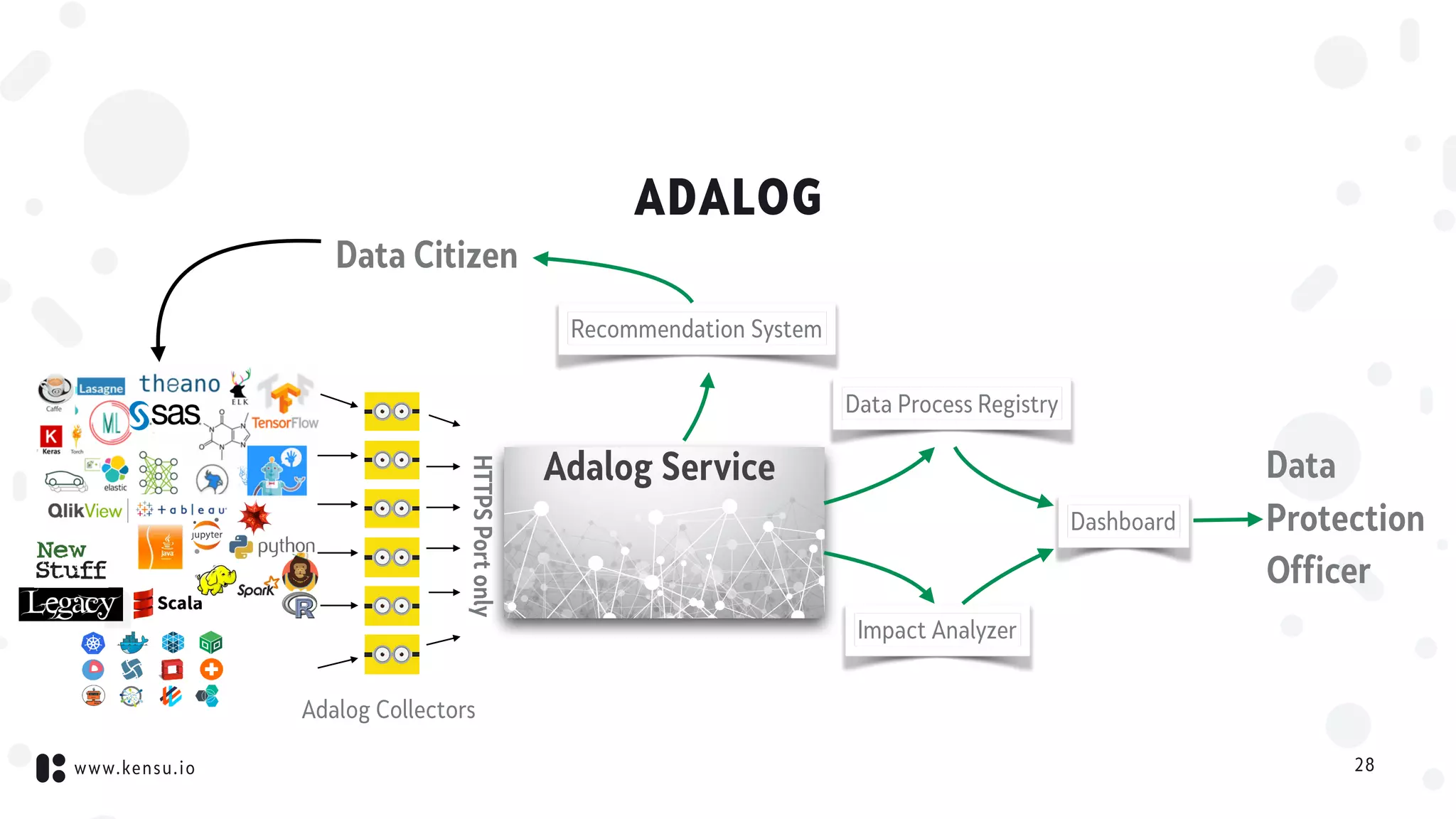


This document discusses data science governance and Kensu's product, Adalog, which aims to address it. It defines data science governance as controlling data activities to meet standards and monitoring production data activity. This involves understanding who does what with which data. Kensu collects metadata on all data tools and processes, connects this information to create a map of all activities, and uses this for impact analysis, dependency analysis, and optimization. Adalog does this to provide accountability and transparency as required by GDPR. It collects data on activities and connects them to automatically generate a process registry and provide transparent reports across the processing chain.























































































