1. STRING MATCHING
Partha P. Chakrabarti & Aritra Hazra
Department of Computer Science and Engineering
Indian Institute of Technology Kharagpur
P
P
P
P
P
P
P
P
T
P
P
2. String Matching: The Problem
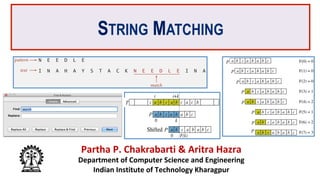
• Goal: Find pattern P[ ] of length M in a text T[ ] of length N.
– Typically, N >> M and N is very very large (M can also be large)!
• Example: Finding a keyword from a whole PDF document
3. Naïve (Brute-Force) Approach
• Check for pattern starting at each text position
– Recursive Formulation (naiveMatch_rec)
– Iterative Approach (naiveMatch_itr)
Algorithm naiveMatch_rec (T[ ], N, P[ ], M)
if (N < M) then return 0;
else if (M == -1) then return 1;
else if (T[N] == P[M]) then
return (naiveMatchRec (T, N-1, P, M-1));
else
return (naiveMatchRec (T, N-1, P, M));
Algorithm naiveMatch_itr (T[ ], N, P[ ], M)
for i = 0 to N-M do {
for j = 0 to M-1 do {
if (P[i+j] == T[j]) then j++;
else break;
}
if (j == M) then
match found starting at T[i]; break;
}
Overall Time
Complexity: Θ(MN)
4. Can Naïve String Search be made Better?
• Illustrating Example:
– Suppose we are searching in text for pattern BAAAAAAAAA
– Suppose we match 5 characters in pattern, with mismatch on 6th character
– We know previous 6 characters in text are BAAAAB (assuming, alphabet Σ = {A, B})
• How can we make string search
algorithm more efficient?
– DO NOT check every
overlapping occurrence of
pattern string in text string
– DO make greater jumps
and DO reduce number of
comparisons
– DO NOT need to back up
the pointer in text string
5. Reducing Overlapped Checking: by Memorization
• Additional storage remembering what has been SEEN in Text String previously
• State Machine as
the data structure
Finite number of
states (including
start state and
halt state)
Exactly one state
transition for each
char in alphabet
Accept if sequence
of state transitions
leads to halt state DFA (Deterministic Finite Automaton)
Text String
Pattern String
6. Knuth-Morris-Pratt (KMP) Algorithm: Definitions
• Some Necessary Definitions
– String of length N is given as, S[0..N-1] = s0 s1 … sN-1 (where each si is from Σ)
– Substring of S[0..N-1] of length (j-i+1) is, S[i..j] = si si+1 ... sj-1 sj (0 ≤ i ≤ j ≤ N-1)
– Prefix of S[0..N-1] of length k is given as, S[0..k-1] = s0 s1 … sk-1 (1 ≤ k ≤ N-1)
– Suffix of S[0..N-1] of length l is given as, S[N-l..N-1] = sN-l sN-l+1 ... sN-1 (1 ≤ k ≤ N-1)
– Border: A substring if it is a prefix as well as suffix
• Border of S[0..N-1] having length k if S[0..k-1] = S[N-k..N-1]
• Proper Border if it is not the whole string itself
• Intuition: To find longest length proper border!!
ß string of length N à
s0 … sk-1 sk ... sN-k-1 sN-k ... sN-1
prefix suffix
7. KMP Algorithm: Notions and Intuition
• Longest Proper Border à Failure Function
– Given pattern string P[0..M-1], we define failure function for each i (0 ≤ i ≤ M) as,
F(i) = MAXIMUM { k | 0 ≤ k ≤ i-1 and P[1..k] = P[i-k+1..i] }
– Example:
i 0 1 2 3 4 5 6 7
P[i] a b c a b a b c
Longest Proper Border of P[0..i] ϕ ϕ ϕ a ab a ab abc
F[i] 0 0 0 1 2 1 2 3
T
P
P
§ Intuition: Use failure function to jump/shift P[ ]
by (k-F[k]+1) positions ahead
§ Proof: If shifting P by smaller amount
produced a match, then proper border of
P[0..k] longer than F[k] à Contradiction!!
8. KMP Algorithm: An Example
b a b
c a b a b a b a c a a b
a b a b a c a
b a b
c a b a b a b a c a a b
a b a b a c a
b a b
c a b a b a b a c a a b
a b a b a c a
0 0 1 2 3 0 1
b a b
c a b a b a b a c a a b
a b a b a c a
b a b
c a b a b a b a c a a b
a b a b a c a
b a b
c a b a b a b a c a a b
a b a b a c a
b a b
c a b a b a b a c a a b
a b a b a c a
Pattern String
Longest Proper Border Length
Text String
MATCH
9. KMP Algorithm and Time Complexity
Time Complexity:
• Outer loop runs ≤ (N-M+1) time
• Each iteration of outer loop increments (i-j)
– (i-j) initializes to 0 and inner loop does
not impact (i-j), as it increases i & j both
– when j continues to be 0, i increases by
1 => (i-j) increases by 1
– when j>1, i unchanged & j gets F[j-1]
• F[j-1] ≤ j-1 => i - F[j-1] ≥ (i-j)+1
• so j getting F[j-1] increases (i-j) by 1
• O(N) time in total
+ KMP_Match algorithm = O(N-M+1) time
+ Computing failure function = O(M) time
Algorithm KMP_Match (T[ ], N, P[ ], M)
F[ ] ß ComputeFailureFunct (P[ ], M);
i = 0; j = 0;
while (i-j ≤ N-M) do { // M-j ≤ N-i
while ( (j < M) and (T[i+j] == P[j]) ) do {
i++; j++;
}
if (j == M) then
match found starting at T[i-M]
if (j == 0) then i++;
else j = F[j-1];
}
find longest
matching prefix
report for match
jump/shift using
failure function
10. KMP Algorithm: Computing Failure Function
Algorithm ComputeFailureFunct (P[ ], M);
F[0] = 0; i = 1; j = 0;
while (i < M) do {
while ( (i < M) and (P[i] == P[j]) ) do {
j++; F[i] = j; i++;
}
if (j == 0) then do {
F[i] = 0; i++;
}
else j = F[j-1];
}
P
P
P
P
P
P
P
P
Example
Failure Function computed by sliding the Pattern String over itself !
Time Complexity: O(M)
11. Food-for-Thought: Exercise?
• String matching using KMP Algorithm searches only for first match
• Modify KMP Algorithm to perform the following:
① What changes will you make in the algorithm so that it can search for all
matches of pattern present in the text string?
• Example: Text = ABACAABAACAABABABAACAABBCA & Pattern = ACAAB
② When the matches may be overlapped, then how can you find all overlapping
matches as well?
• Example: Text = BABABABACABABABABACBABABAC & Pattern = ABABA
Hint: Try to bring modifications to the DFA and re-position your jumps/shifts!
12. Rabin-Karp Algorithm: Mathematical Overview
• Use mathematical computations
– Assume that, string is formed from Σ = {0, 1, 2, …, R-1} (radix-R notation, R = |Σ|)
– P ß decimal value of pattern string P[0..M-1] = p0 p1 … pM-1 (each pi is from Σ)
• P = pM-1 + R (pM-2 + R (pM-3 + … + R (p1 + R p0) ... )) ß Horner’s Rule [ Θ(M)-time ]
– Ti ß decimal value of M-window text-string starting at T[i], i.e. ti ti+1 … ti+M-1
• T0 ß Compute similarly for t0 t1 … tM-1 using Horner’s Rule in Θ(M)-time
– Example (…32145… in decimal): Ti = 5 + 10 x (4 + 10 x (1 + 10 x (2 + 10 x 3)))
• Ti+1 = R (Ti – RM-1 ti) + ti+M ß Compute from Ti (shift M-length window) in Θ(1)-time
– Example (...321456... à ...321456...): Ti+1 = 10 x (Ti – 10(5-1) x 3) + 6
• Computation of T1, T2, …, TN-M in Θ(N-M)-time
• When P = Ti, MATCH FOUND from index-i at T[ ], i.e. p0 p1 … pM-1 = ti ti+1 … ti+M-1
Overall Time
Complexity:
Θ(N)
13. Rabin-Karp Algorithm: Efficient Computation
• Challenge: efficiently compute Ti+1 given that we know Ti
– Ti = ti RM-1 + ti+1 RM-2 + ... + ti+M-1 R0 and Ti+1 = ti+1 RM-1 + ti+2 RM-2 + ... + ti+M R0
• Key property:
Can update function in
constant time!
– Ti+1 = (Ti – ti RM-1) R + ti+M
current
value
subtract
leading digit
multiply
by radix
add new
trailing digit
15. Rabin-Karp Algorithm: Hash-map based Approach
• Solution: use Modular Hashing
– Compute a hash of
P[0..M-1], say HP
– For each i, compute a hash
of T[i..i+M-1], say HT
– If pattern hash (HP) ≠ text
substring hash (HT),
definitely NOT a match
– If pattern hash (HP) = text
substring hash (HT), check
for a VALID match
• Demerit of computing P and Ti values:
– may be very large if M is long! (non-constant arithmetic operations)
Modular Hash with R=10
and H(k) = k (mod 997)
17. Rabin-Karp Algorithm: Rolling Modular Hash-map
• First R entries: Use Horner's rule
• Remaining entries: Use rolling hash (and % or modulus to avoid overflow)
18. Rabin-Karp Algorithm (Psudo-code)
Algorithm Rabin-Karp_StrMatch (TXT[], N, PAT[], M, R, Q)
C = RM-1 mod Q; P = 0; T0 = 0;
for j = 1 to m do { // Preprocessing
P = (RP + PAT[j]) mod Q; T0 = (RT0 + TXT[j]) mod Q;
}
for i = 0 to N-M do { // Matching
if (P == Ti) then
if (PAT[1..M] = TXT[i+1..i+M]) then
match found starting at TXT[i];
if (i < N-M) then
Ti+1 = (R (Ti – TXT[i+1] C) + TXT[i+M+1]) mod Q
}
![String Matching: The Problem
• Goal: Find pattern P[ ] of length M in a text T[ ] of length N.
– Typically, N >> M and N is very very large (M can also be large)!
• Example: Finding a keyword from a whole PDF document](data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7)