今回紹介する論文 Soft Marginsfor AdaBoost,Ratsch et al,JMLR Sparse Regression Ensembles in Infinite and Finite Hypothesis Spaces, Ratsch et al,JMLR Linear Programming Boosting via Column Generation, Demiriz et al, JMLR Mining complex genotypic features for predicting HIV-1 drug resistance,Saigo et al, Bioinformatics
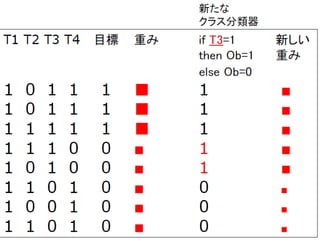
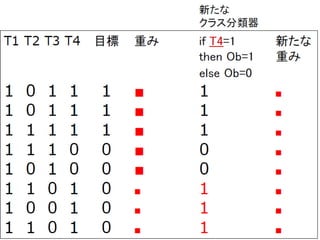
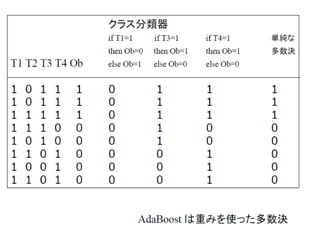
Adaboost 1.Input: S={(x1 ,y 1 ),…,(x N ,y N )},Number of Iterations T 2.Initialize: d n (1) =1/N for all n=1,..,N 3. Do for t=1,..,T. (a) :obtain hypothesis (b) Calculate the weighted training error ε t of h t : (c)Set (d) Update Weights where z t is a normalized constant 4. Break if 5. Output: 今までの採用した 仮説では最も正解を 得にくいデータを、 当てられるように 仮説を選択 重みの更新 重み付多数決 で最終的な予測を 得る
12.
Adaboost の目的関数 Adaboostは以下のエラー関数を最小化 y n f a (x n ): マージン - 予測が当たると正でエラーは減少する - 間違えると負となってエラーは増加する AdaBoost は以下の最小マージン Q を最大化する ( と信じられている。 )
13.
Adaboost の目的関数 Hypothesisset H 上の線形計画問題としてとくことができる AdaBoost は Hard Margin を最大がしているのでノイズに弱い。 線形計画法として形式化が行われるようになる (Soft Margin) 。 線形計画法として定式化した Boosting を LPBoost という
Column Generation Algorithm1.制約なし双対問題からスタート 2.すべての仮説に対して、最も合わない制約を加える。 3. 双対問題を解く 4.収束するまで、繰り返す。 Constraint Matrix Used Part
16.
Column Generation AlgorithmAlgorithm (LPBoost) (1) Given as input training set S=<(x 1 ,y 1 ),…(x n ,y n )> (2) t← 0 (Weak Learner の数 ) (3) a ← 0 ( 仮説に対する係数 0), β←0, u ←(1/n, …, 1/n): 双対変数 (6) REPEAT (7) t←t+1 (8) h t ←H(S,u) (9) i f (10) H ji ←h t (x i ) (11) 右の双対問題を解く (12)END (13) a ← Lagrangian multipliers from last LP (14) return 最も制約に反する仮説を 選択 ( すべての仮説に 反する制約を選択 ) 加えた制約のみで 双対問題を解く
LPBoost ε-insensitive loss関数など、 SVM で使われている損失関数が取り入れられている。 最近は、 LPBoost の収束は遅いことが理解され始めたので、高速化の方向へ - Boosting Algorithms for Maximizing the Soft Margin, K.Warmuth et al.nips2007
19.
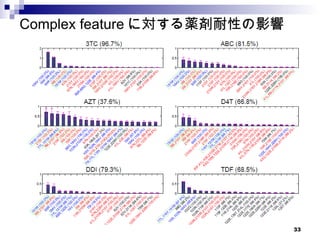
LPBoost の応用 Miningcomplex genotypic features for predicting HIV-1 drug resistance, Hiroto Saigo, Takeaki Uno, Koji Tsuda, Bioinformatics, 2007 比較的新しい 他の回帰手法との比較も行われている
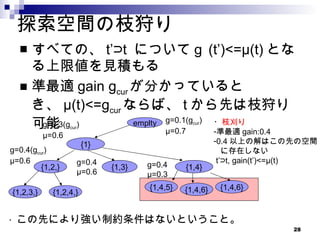
問題設定 ・ データの定義 - (x i ,y i ) x i ∈{0,1} d , y i ∈R, - x i :i 番目の配列に対する置換パターン , - y i : 薬剤耐性 ・学習データ Wild type ADANNNDDD 薬剤耐性 y∈ R 患者 1 AGDNNNDQQ 0.8 x 1 =(0,1,1,0,0,0,0,1,1) 0.8 患者 2 AGGNNADQQ 0.7 x 2 =(0,1,1,0,0,1,0,1,1) 0,7 ・テストデータ 新しい患者 3 x 3 =(0,1,1,0,0,0,0,0,0) から y を予測 ? ・置換パターン対する変異の入り方の影響も見たい
22.
データの表現 ・学習データ :L・ 配列の置換パターン x と薬剤耐性 y∈R L={<x 1 ,y 1 >,<x 2 ,y 2 >,…,<x k ,y k >} ・例 L={ (0,1,1,0,0,0,0,1,1) 0.8,(0,1,1,0,0,1,0,1,1) 0,7 (1,0,0,1,0,0,0,1,0) -0.7} ・ X i :x i において j 番目の配列上の位置 x ij =1 となるすべての添え字 j を含む集合とする ・例 T={{2,3,8,9},{2,3,6,8,9},{1,4,8}}
23.
weak learner 弱仮説( 部分配列の置換パターン t の有無に基づく分類器 ) 例 X={2,3,8,9} - t={2,3} z t (X) = 1, - t={1} z t (X) = -1 部分配列の置換パターン t を complex feature という
24.
回帰関数 T をX 1 ,…,X n の少なくとも一つの配列の中に現れるすべての complex feature の集合とする。 回帰のために以下の回帰関数を用いる。 - a t , b は学習パラメータ 学習問題を以下で定式化 - L1-norm なのでスパースな解をうることができる α は超高次元なので、このままでは解くことは困難 二次計画問題で形式化して、 Column Generation Algorithm で解く















![SVMとの比較 AdaBoost SVM ・1つめの制約は同じ - マージン最大化という意味では同じ ・違いは、 a のノルム (1-norm, 2-norm) ・ 1-norm の場合、最適解が訓練データ数個の弱学習器の 線形和で表すことができる。 [G.Ratsch 01] ・ 2-norm では、 a* は訓練データの線形和で表される。 (Representer Theorem)](https://image.slidesharecdn.com/lpboost-091110085345-phpapp01/85/Lp-Boost-17-320.jpg)





























![[DL輪読会]End-to-End Object Detection with Transformers](https://cdn.slidesharecdn.com/ss_thumbnails/200529dlseminardetr-200529061512-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)




![SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=640&height=640&fit=bounds)







































