Recommended
PDF
PDF
PDF
プログラミングコンテストでのデータ構造 2 ~動的木編~
PDF
PDF
PDF
TokyoNLP#7 きれいなジャイアンのカカカカ☆カーネル法入門-C++
PDF
文字列カーネルによる辞書なしツイート分類 〜文字列カーネル入門〜
PDF
PDF
PDF
パターン認識と機械学習 §6.2 カーネル関数の構成
PDF
PDF
PDF
機械学習による統計的実験計画(ベイズ最適化を中心に)
ZIP
PDF
PDF
クラシックな機械学習の入門 6. 最適化と学習アルゴリズム
PDF
WSDM2012読み会: Learning to Rank with Multi-Aspect Relevance for Vertical Search
PDF
[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介
PDF
Rパッケージ“KFAS”を使った時系列データの解析方法
PDF
PDF
PDF
PDF
(文献紹介) 画像復元:Plug-and-Play ADMM
PDF
PDF
クラシックな機械学習の入門 3. 線形回帰および識別
PDF
Clustering _ishii_2014__ch10
PDF
PPTX
DCC2014 - Fully Online Grammar Compression in Constant Space
PDF
Sketch sort sugiyamalab-20101026 - public
PDF
Gwt presen alsip-20111201
More Related Content
PDF
PDF
PDF
プログラミングコンテストでのデータ構造 2 ~動的木編~
PDF
PDF
PDF
TokyoNLP#7 きれいなジャイアンのカカカカ☆カーネル法入門-C++
PDF
文字列カーネルによる辞書なしツイート分類 〜文字列カーネル入門〜
PDF
What's hot
PDF
PDF
パターン認識と機械学習 §6.2 カーネル関数の構成
PDF
PDF
PDF
機械学習による統計的実験計画(ベイズ最適化を中心に)
ZIP
PDF
PDF
クラシックな機械学習の入門 6. 最適化と学習アルゴリズム
PDF
WSDM2012読み会: Learning to Rank with Multi-Aspect Relevance for Vertical Search
PDF
[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介
PDF
Rパッケージ“KFAS”を使った時系列データの解析方法
PDF
PDF
PDF
PDF
(文献紹介) 画像復元:Plug-and-Play ADMM
PDF
PDF
クラシックな機械学習の入門 3. 線形回帰および識別
PDF
Clustering _ishii_2014__ch10
PDF
Viewers also liked
PPTX
DCC2014 - Fully Online Grammar Compression in Constant Space
PDF
Sketch sort sugiyamalab-20101026 - public
PDF
Gwt presen alsip-20111201
PDF
Sketch sort ochadai20101015-public
PPTX
PDF
PDF
PDF
PPT
PPTX
PPTX
PDF
WABI2012-SuccinctMultibitTree
PDF
PPTX
PDF
NIPS2013読み会: Scalable kernels for graphs with continuous attributes
PPTX
Scalable Partial Least Squares Regression on Grammar-Compressed Data Matrices
PDF
PDF
異常検知 - 何を探すかよく分かっていないものを見つける方法
PDF
PDF
文法圧縮入門:超高速テキスト処理のためのデータ圧縮(NLP2014チュートリアル)
Similar to Ibisml2011 06-20
PDF
PDF
Ruby科学データ処理ツールの開発 NArrayとPwrake
PDF
PDF
プログラミングコンテストでのデータ構造 2 ~平衡二分探索木編~
PDF
PFI Christmas seminar 2009
PDF
NArray and scientific computing with Ruby - RubyKaigi2010
PDF
PDF
PFI Seminar 2012/03/15 カーネルとハッシュの機械学習
PDF
HistoPyramid Stream Compaction
PDF
最近傍探索と直積量子化(Nearest neighbor search and Product Quantization)
PPTX
PDF
PDF
ODP
区間をキーとして保持する分散KVSの効率的な実現法
PDF
PDF
PDF
CODE THANKS FESTIVAL 2014 A日程 解説
PPT
PDF
R language definition3.1_3.2
PDF
Recently uploaded
PDF
さくらインターネットの今 法林リージョン:さくらのAIとか GPUとかイベントとか 〜2026年もバク進します!〜
PDF
PDF
2025→2026宙畑ゆく年くる年レポート_100社を超える企業アンケート総まとめ!!_企業まとめ_1229_3版
PDF
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信
PDF
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」
PPTX
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis
PDF
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望
Ibisml2011 06-20 1. 2. 発表の流れ
• 背景
近傍検索法の必要性
• 本発表で用いるデータ構造
ウェーブレット木
• バイナリコードの検索(提案法)
幾何制約を取り入れたウェーブレット
木による検索
• 実験
既存手法との比較 (転置インデックス)
8000万画像
2
3. 4. 近傍検索の必要性
• あらゆる手法のもととなるタスク
例) semi-supervised learning, spectral
clustering, ROI detection in images, etc
• 2つの研究の方向性
1. 空間分割による索引に基づく検索法
cover tree(ICML,06), spill tree(NIPS05) etc
高次元データに対しては有効ではない(NIPS,09)
2. locality sensitive codeを用いた検索法
コンパクトにデータを保持することが可能
エラーと速度のトレードオフをコントロールす
ることが困難
4
5. 6. 発表の流れ
• 背景
近傍検索法の必要性
• 本発表で用いるデータ構造
ウェーブレット木
• バイナリコードの検索法(提案法)
幾何制約を取り入れたウェーブレッ
ト木による検索
• 実験
8000万画像
6
7. ウェーブレット木 (SODA,03)
• 整数配列のself-index
A 1 3 6 8 2 5 7 1 2 7 4 5
• 高速な配列上の操作
連続した区間内の値cの出現回数
値cのi番目の出現位置
連続した区間内の最大値,最小値,k番目に大きい値,
出現位置 etc
• 区間の長さに関して定数時間, 約nlogsビット
のメモリ(n:配列長,s:整数の最大値)
• 2次元Arange intersection:
ms の範囲内で, n個の区間で共通す
mi t
る要素を求める
7
8. 配列上のRange Intersection
• 長さNの配列 A, 1 Ai M
i j k "
A 1 3 6 8 2 5 7 1 2 7 4 5
• Range Intersection: rint(A,[i,j],[k,l])
A[i,j]とA[k,l]の共通要素を求める
ナイーブ法=2つの区間を連結してソート
• 配列のインデックス(ウェーブレット木)を使
い, 高速に解く
8
9. 部分配列上の木:
下半分:左の子 上半分:右の子
[1,8]
1 3 6 8 2 5 7 1 7 2 4 5
[1,4] [5,8]
1 3 2 1 2 4 6 8 5 7 7 5
[1,2] [3,4] [5,6] [7,8]
1 2 1 2 3 4 6 5 5 8 7 7
1 1 2 2 3 4 5 5 6 7 7 8
9
10. それぞれの要素が下半分(0)
または上半分(1)かを記憶
[1,8]
0 0 1 1 0 1 1 0 1 0 0 1
[1,4] [5,8]
0 1 0 0 0 1 0 1 0 1 1 0
[1,2] [3,4] [5,6] [7,8]
0 1 0 1 0 1 1 0 0 1 0 0
1 2 3 4 5 6 7 8
10
11. ランク辞書によりビット
配列をインデックス
• 定数時間でランク操作が可能
rankc (B, i) : B[1..i] のc {0, 1} の個数を返す
• 代表的な手法: rank9sel (Vigna,08)
✴ 例) B=0110011100
i 1 2 3 4 5 6 7 8 9 10
rank1 (B, 8) = 5 011001110 0
rank0 (B, 5) = 3 011001110 0
11
12. ランク辞書の実装
• 長さnのビット配列 B を
長さ
B
= log2 n
の大ブロックに
分割
RL
RL:大ブロックの1の個数
RS
• R のそれぞれのブロック
L
を長さ s = log2 n/2 の小ブ
ロックに分割
Rs:小ブロックの1の個数
rank1 (B, i) = RL [i/ ] + Rs [i/s] + (remaining rank)
• 時間:O(1) メモリ:n+o(n) bits
12
13. 区間の定数時間分割
• ランク操作により, 区間の分割は定数時
間で行うことができる
左の子: rank0, 右の子: rank1
• ナイーブ法: 全区間の要素の総和に線形時間
[1,8]
Aroot 1 3 6 8 2 5 7 1 7 2 4 5
rank0 rank1
[1,4] [5,8]
Aleft 1 3 2 1 2 4 Aright 6 8 5 7 7 5
13
14. 枝刈りによるrange intersection
の高速計算
Pruned [1,8]
1 3 6 8 2 5 7 1 7 2 4 5
[1,4] [5,8]
1 3 2 1 2 4 6 8 5 7 7 5
[1,2] [3,4] [5,6] [6,8]
1 2 1 2 3 4 6 5 5 8 7 7
1 1 2 2 3 4 5 5 6 7 7 8
solution!!
14
15. Two dimensional range
intersection
• 長さNの配列 A, 1 Ai M
i j k "
A 1 3 6 8 2 5 7 1 2 7 4 5
• Two dimensional range intersection:
trint(A,[i,j],[k,l],[ms,mt])
A[i,j]とA[k,l]の共通要素をms Ai mtの範囲内
で求める
探索空間の枝刈りが可能
15
16. Two dimensional range
intersection
2 A[i] 3
Pruned// [1,8]
1 3 6 8 2 5 7 1 7 2 4 5
[1,4] [5,8]
1 3 2 1 2 4 6 8 5 7 7 5
[1,2] [3,4] [5,6] [6,8]
1 2 1 2 3 4 6 5 5 8 7 7
1 1 2 2 3 4 5 5 6 7 7 8
solu3on!!/
16
17. 発表の流れ
• 背景
近傍検索法の必要性
• 本発表で用いるデータ構造
ウェーブレット木
• バイナリコードの検索(提案法)
幾何制約を取り入れたウェーブレッ
ト木による検索
• 実験
8000万画像
17
18. バイナリコードの類似度検索
xi=(1.2,-0.9,2,3,4,...) • ベクトルデータ
Xi=100011... • バイナリコード(SIHK)
10 00 11... • ブロック分割
1-10, 2-00, 3-11,... • Bag-of-words表現
• Semi-conjunctive query
クエリQに対して, 少なくともkワードを共有す
るデータXiをデータベースからすべて求める
|Xi Q| k
18
19. Shift-invariant kernel based hashing (NIPS,09)
• ベクトルデータ x d
をバイナリs {0, 1}へ射影
s = sign(cos(r x + ) + )
T
r d
N (0, )
:正規分布 からのランダムベクトル
, : 一様分布U[-1,1], U[0,2π]からの乱数
• 2つのベルトルx,yの (x) = 2 cos(rT x + ) の内積の期
待値 Er, [ (x) (y)] がtransition invariant kernel
k(x,y)=k(x-y)の近似(Rahimi and Recht,07)
• L回繰り返してバイナリコード(文字列)へ射影
• 元の空間のユーグリッド距離を文字列のハミン
グ距離で保つ
• データのコンパクトな表現
19
20. 転置インデックス,配列,ウェーブレット木
ワード 識別子 • データベースを転置インデック
1-00 1,3,6,8 に格納
1-01 2,5,7 • すべての行を連結し, 配列に格納
1-10 2,7 • ウェーブレット木により
1-11 4,5 配列を索引付ける
2-00 2,6,8
• Semi-conjunctive query
= Extension of range
intersection
A 1 3 6 8 2 5 7 2 7 4 5 26 8
6
配列中少なくともk回現れる
識別子を発見する
ウェーブレット木
20
21. 幾何制約
• クエリーqに対して, 距離ε
以内の点は, 第一主成分の座
h6 標hiもε以内
q h4 h5
ε is = min{i|hq hi }
ie = min{i|hi hq + }
h3
hq
h2
h1 • is i ieかつ |Xi Q| k
を満たすiをすべて求める
hq hi hq + (Extension of two
dimensional range
intersecion)
21
22. 2種類のエラー
• I*:クエリqに対して, 距離ε以内の
データベース中の点xiの集合
I = {i| (xi , q) , is i ie }
• I: クエリQに対して, k個のワードを共有
するデータベース中の点Xiの集合
I = {i||Xi Q| k, is i ie }
• False positive rate: Fp = |I I |/|I|
• False negative rate: Fn = |I I|/|I |
22
23. False negative rateの上限
• False negative rateは以下のように抑え
ることができる
b
Fn 1 p0 (1
k
p0 )
b k
p0 = (1 p)
k=0
• pは近傍に対する非衝突確率の上限
8 1 exp( 2
/2)
p= 2
m=0
4m2 1
• False negative rateをできるだけ小さく
するようにパラメータを決定できる
23
24. 時間とメモリ
• クエリあたりの検索時間: O(τb)
τ:たどったノード数
b:ブロックの個数(L/l)
• メモリ:(1+α)Nlogn+MlogN ビット
N: すべてのワードの個数
M:配列中の最大整数
n:データ点の数
• 転置インデックスのメモリ:Nlognビット
• 転置インデックスと比較して約60%のオー
バーヘッド
24
25. 発表の流れ
• 背景
近傍検索法の必要性
• 本発表で用いるデータ構造
ウェーブレット木
• バイナリコードの検索(提案法)
幾何制約を取り入れたウェーブレット
木による検索
• 実験
既存手法との比較 (転置インデックス)
8000万画像
25
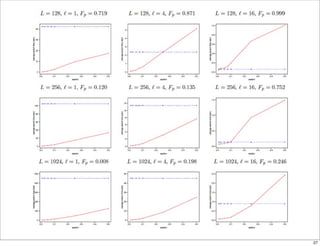
26. 実験
• Tiny image dataset (Torralba et al., 08)
約8000万データ, 386次元
• 500万データを用いて, 従来法 (転置インデックス)
と比較
コード長 L=128,256,1024ビット
ブロック長 =1,4,16
距離の閾値ε 0.01,から0.5の値
ブロックマッチの個数の閾値kは, false
negative rateの上限が0.001にできるだけ近く
なるように決める
• false negative rate一定のもとで, false positive
rateと速度の変化をみる
26
27. 28. 29. 30. 31. まとめ
• 高速かつメモリー効率の良いバイナリ
コードの検索法
• 第一主成分による制約を入れてsemi-
conjunctive queryを効率的に解く
• ウェーブレット木による索引
• バイナリコードへの変換は
shift-invariant kernel based hashing
を用いる
• 8000万画像にも適応可能
31








![配列上のRange Intersection
• 長さNの配列 A, 1 Ai M
i j k "
A 1 3 6 8 2 5 7 1 2 7 4 5
• Range Intersection: rint(A,[i,j],[k,l])
A[i,j]とA[k,l]の共通要素を求める
ナイーブ法=2つの区間を連結してソート
• 配列のインデックス(ウェーブレット木)を使
い, 高速に解く
8](https://image.slidesharecdn.com/ibisml2011-06-20-111206203146-phpapp01/85/Ibisml2011-06-20-8-320.jpg)
![部分配列上の木:
下半分:左の子 上半分:右の子
[1,8]
1 3 6 8 2 5 7 1 7 2 4 5
[1,4] [5,8]
1 3 2 1 2 4 6 8 5 7 7 5
[1,2] [3,4] [5,6] [7,8]
1 2 1 2 3 4 6 5 5 8 7 7
1 1 2 2 3 4 5 5 6 7 7 8
9](https://image.slidesharecdn.com/ibisml2011-06-20-111206203146-phpapp01/85/Ibisml2011-06-20-9-320.jpg)
![それぞれの要素が下半分(0)
または上半分(1)かを記憶
[1,8]
0 0 1 1 0 1 1 0 1 0 0 1
[1,4] [5,8]
0 1 0 0 0 1 0 1 0 1 1 0
[1,2] [3,4] [5,6] [7,8]
0 1 0 1 0 1 1 0 0 1 0 0
1 2 3 4 5 6 7 8
10](https://image.slidesharecdn.com/ibisml2011-06-20-111206203146-phpapp01/85/Ibisml2011-06-20-10-320.jpg)
![ランク辞書によりビット
配列をインデックス
• 定数時間でランク操作が可能
rankc (B, i) : B[1..i] のc {0, 1} の個数を返す
• 代表的な手法: rank9sel (Vigna,08)
✴ 例) B=0110011100
i 1 2 3 4 5 6 7 8 9 10
rank1 (B, 8) = 5 011001110 0
rank0 (B, 5) = 3 011001110 0
11](https://image.slidesharecdn.com/ibisml2011-06-20-111206203146-phpapp01/85/Ibisml2011-06-20-11-320.jpg)
![ランク辞書の実装
• 長さnのビット配列 B を
長さ
B
= log2 n
の大ブロックに
分割
RL
RL:大ブロックの1の個数
RS
• R のそれぞれのブロック
L
を長さ s = log2 n/2 の小ブ
ロックに分割
Rs:小ブロックの1の個数
rank1 (B, i) = RL [i/ ] + Rs [i/s] + (remaining rank)
• 時間:O(1) メモリ:n+o(n) bits
12](https://image.slidesharecdn.com/ibisml2011-06-20-111206203146-phpapp01/85/Ibisml2011-06-20-12-320.jpg)
![区間の定数時間分割
• ランク操作により, 区間の分割は定数時
間で行うことができる
左の子: rank0, 右の子: rank1
• ナイーブ法: 全区間の要素の総和に線形時間
[1,8]
Aroot 1 3 6 8 2 5 7 1 7 2 4 5
rank0 rank1
[1,4] [5,8]
Aleft 1 3 2 1 2 4 Aright 6 8 5 7 7 5
13](https://image.slidesharecdn.com/ibisml2011-06-20-111206203146-phpapp01/85/Ibisml2011-06-20-13-320.jpg)
![枝刈りによるrange intersection
の高速計算
Pruned [1,8]
1 3 6 8 2 5 7 1 7 2 4 5
[1,4] [5,8]
1 3 2 1 2 4 6 8 5 7 7 5
[1,2] [3,4] [5,6] [6,8]
1 2 1 2 3 4 6 5 5 8 7 7
1 1 2 2 3 4 5 5 6 7 7 8
solution!!
14](https://image.slidesharecdn.com/ibisml2011-06-20-111206203146-phpapp01/85/Ibisml2011-06-20-14-320.jpg)
![Two dimensional range
intersection
• 長さNの配列 A, 1 Ai M
i j k "
A 1 3 6 8 2 5 7 1 2 7 4 5
• Two dimensional range intersection:
trint(A,[i,j],[k,l],[ms,mt])
A[i,j]とA[k,l]の共通要素をms Ai mtの範囲内
で求める
探索空間の枝刈りが可能
15](https://image.slidesharecdn.com/ibisml2011-06-20-111206203146-phpapp01/85/Ibisml2011-06-20-15-320.jpg)
![Two dimensional range
intersection
2 A[i] 3
Pruned// [1,8]
1 3 6 8 2 5 7 1 7 2 4 5
[1,4] [5,8]
1 3 2 1 2 4 6 8 5 7 7 5
[1,2] [3,4] [5,6] [6,8]
1 2 1 2 3 4 6 5 5 8 7 7
1 1 2 2 3 4 5 5 6 7 7 8
solu3on!!/
16](https://image.slidesharecdn.com/ibisml2011-06-20-111206203146-phpapp01/85/Ibisml2011-06-20-16-320.jpg)


![Shift-invariant kernel based hashing (NIPS,09)
• ベクトルデータ x d
をバイナリs {0, 1}へ射影
s = sign(cos(r x + ) + )
T
r d
N (0, )
:正規分布 からのランダムベクトル
, : 一様分布U[-1,1], U[0,2π]からの乱数
• 2つのベルトルx,yの (x) = 2 cos(rT x + ) の内積の期
待値 Er, [ (x) (y)] がtransition invariant kernel
k(x,y)=k(x-y)の近似(Rahimi and Recht,07)
• L回繰り返してバイナリコード(文字列)へ射影
• 元の空間のユーグリッド距離を文字列のハミン
グ距離で保つ
• データのコンパクトな表現
19](https://image.slidesharecdn.com/ibisml2011-06-20-111206203146-phpapp01/85/Ibisml2011-06-20-19-320.jpg)




























![[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20191220readingpaperconvcnp-191220034420-thumbnail.jpg?width=640&height=640&fit=bounds)

























































