


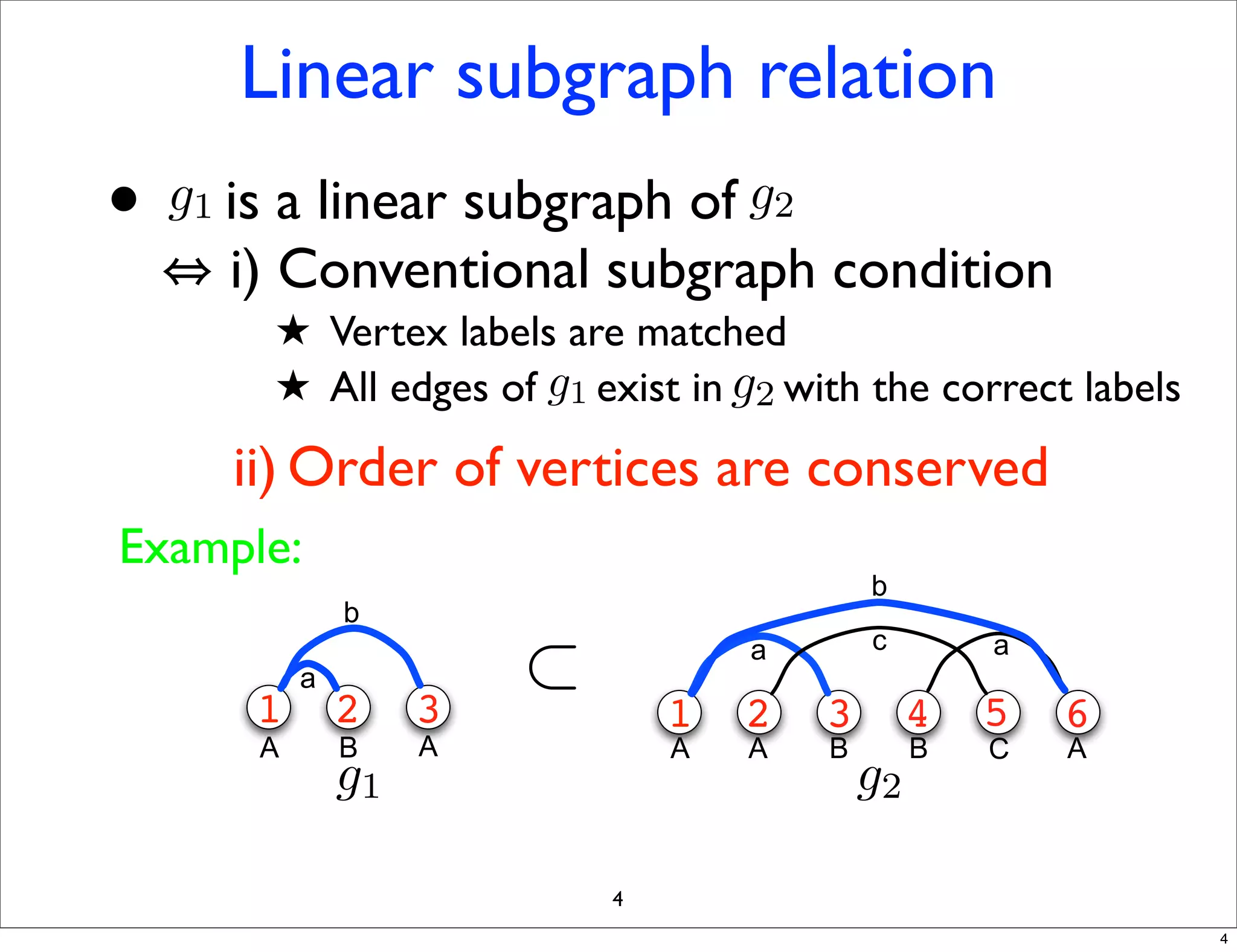

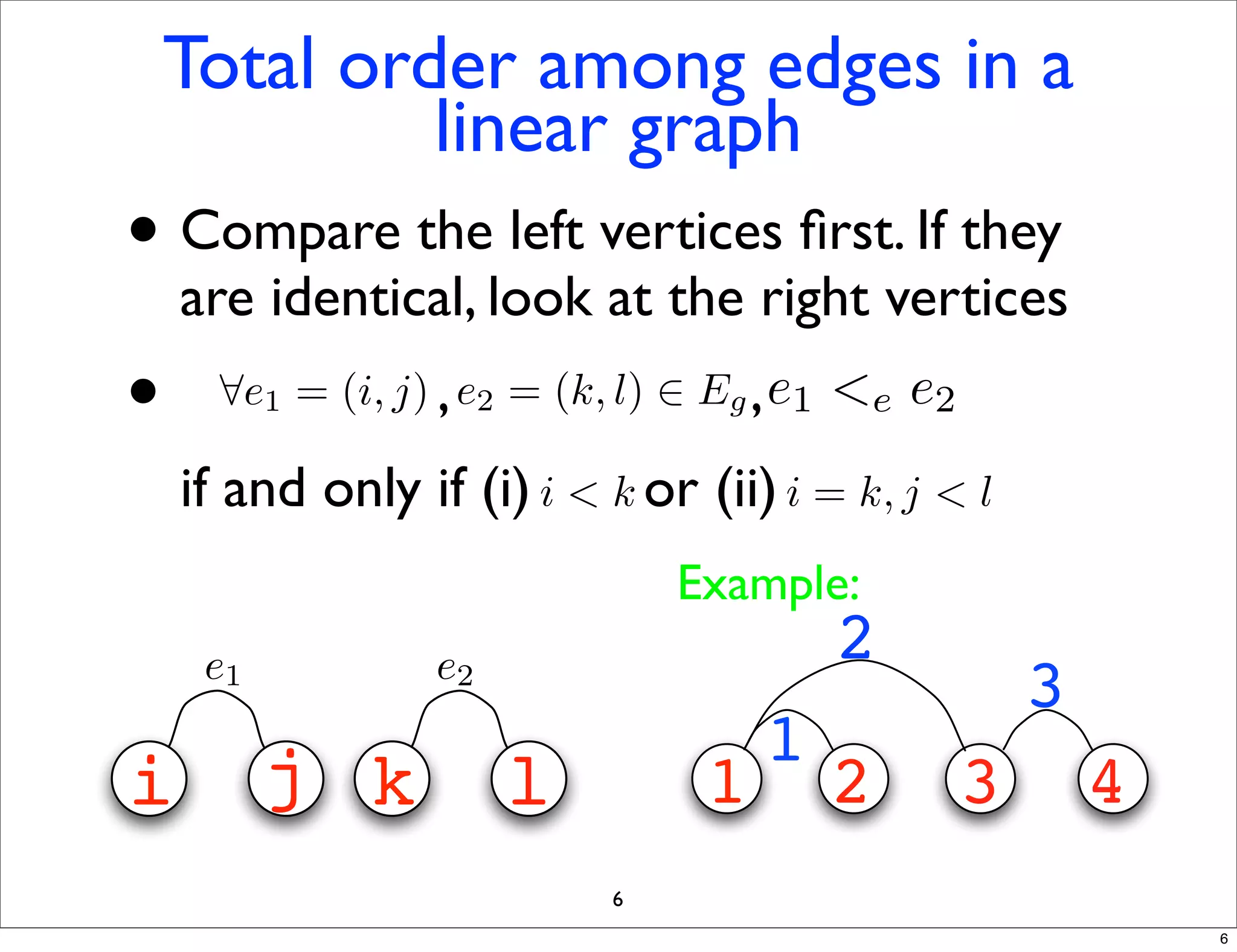



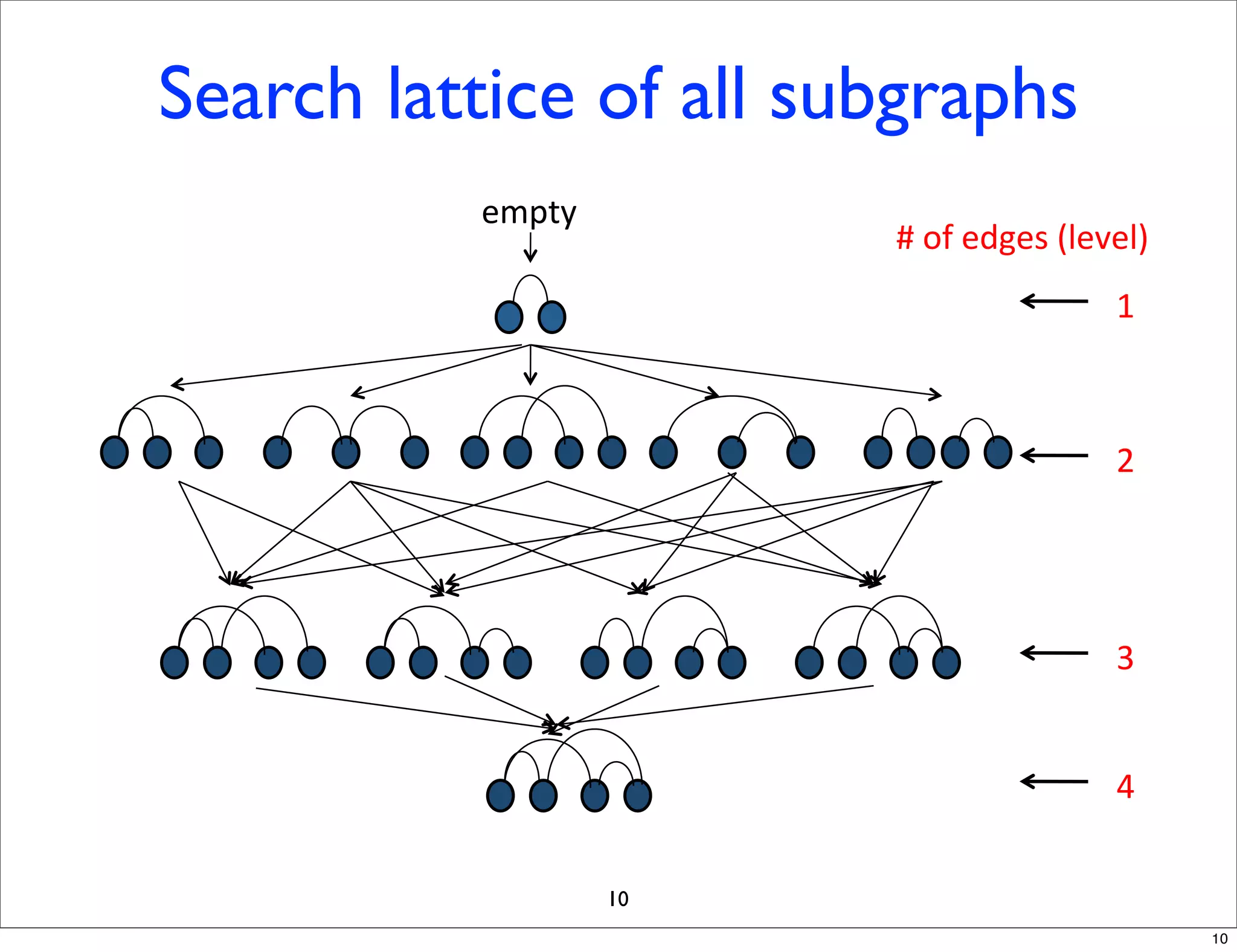

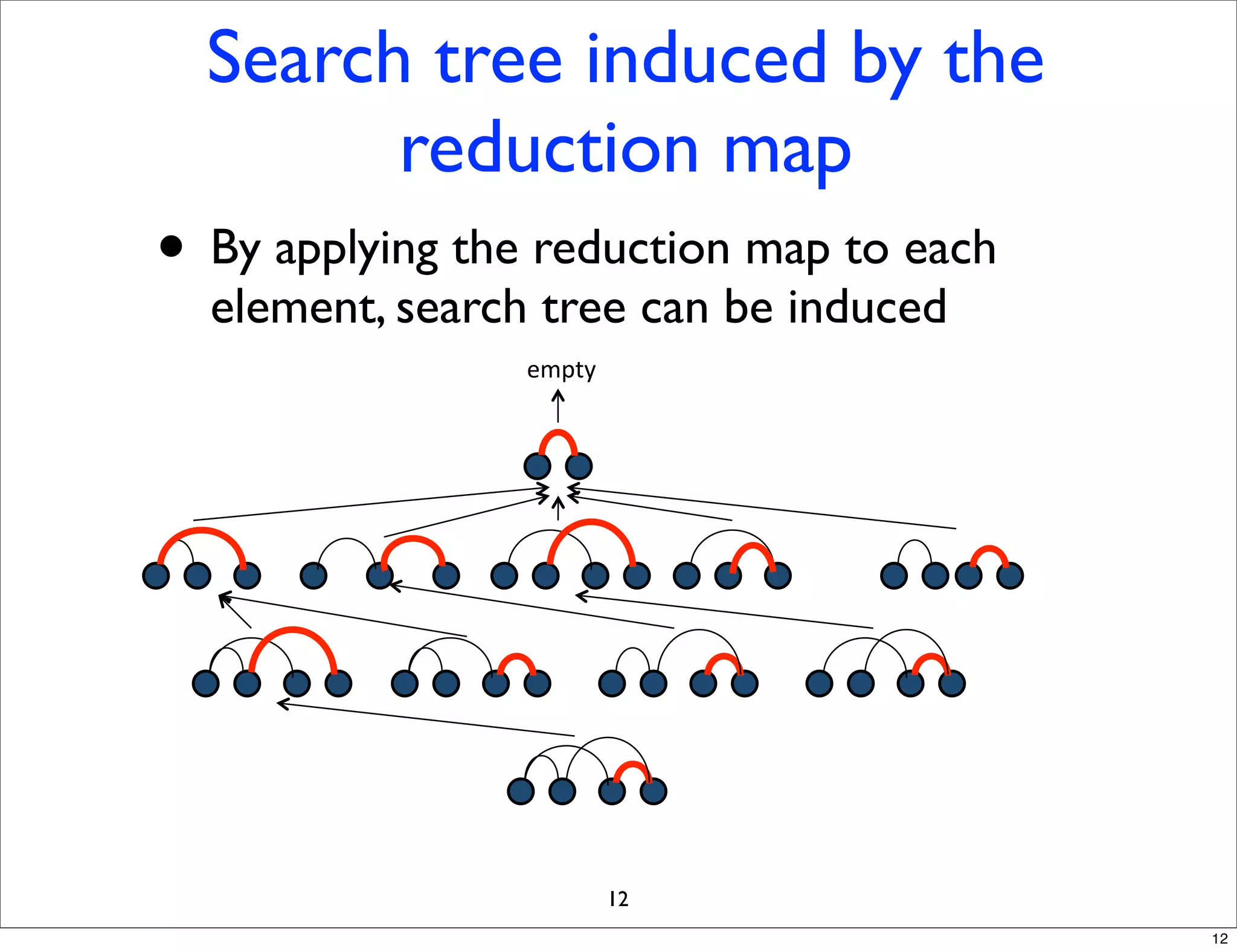
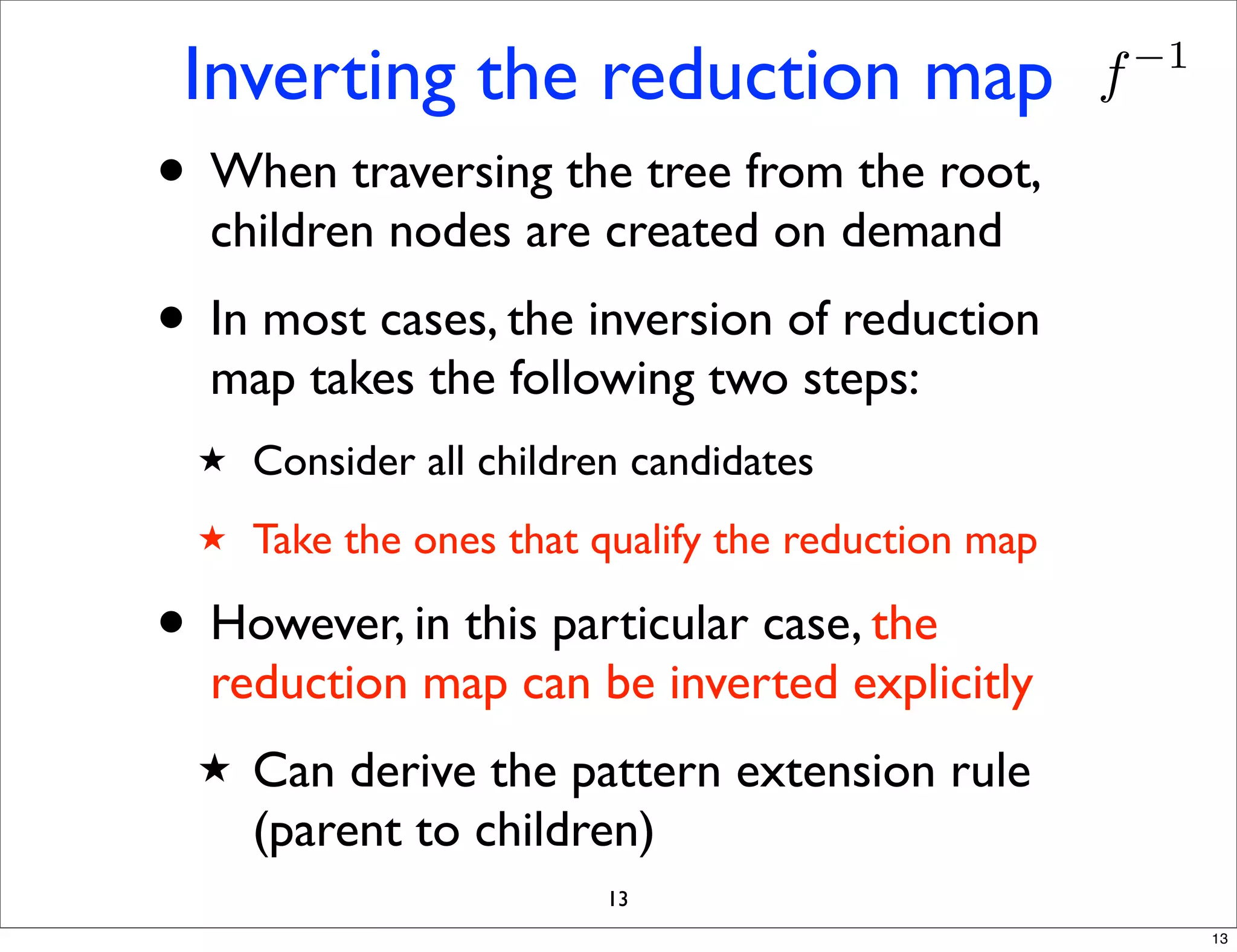

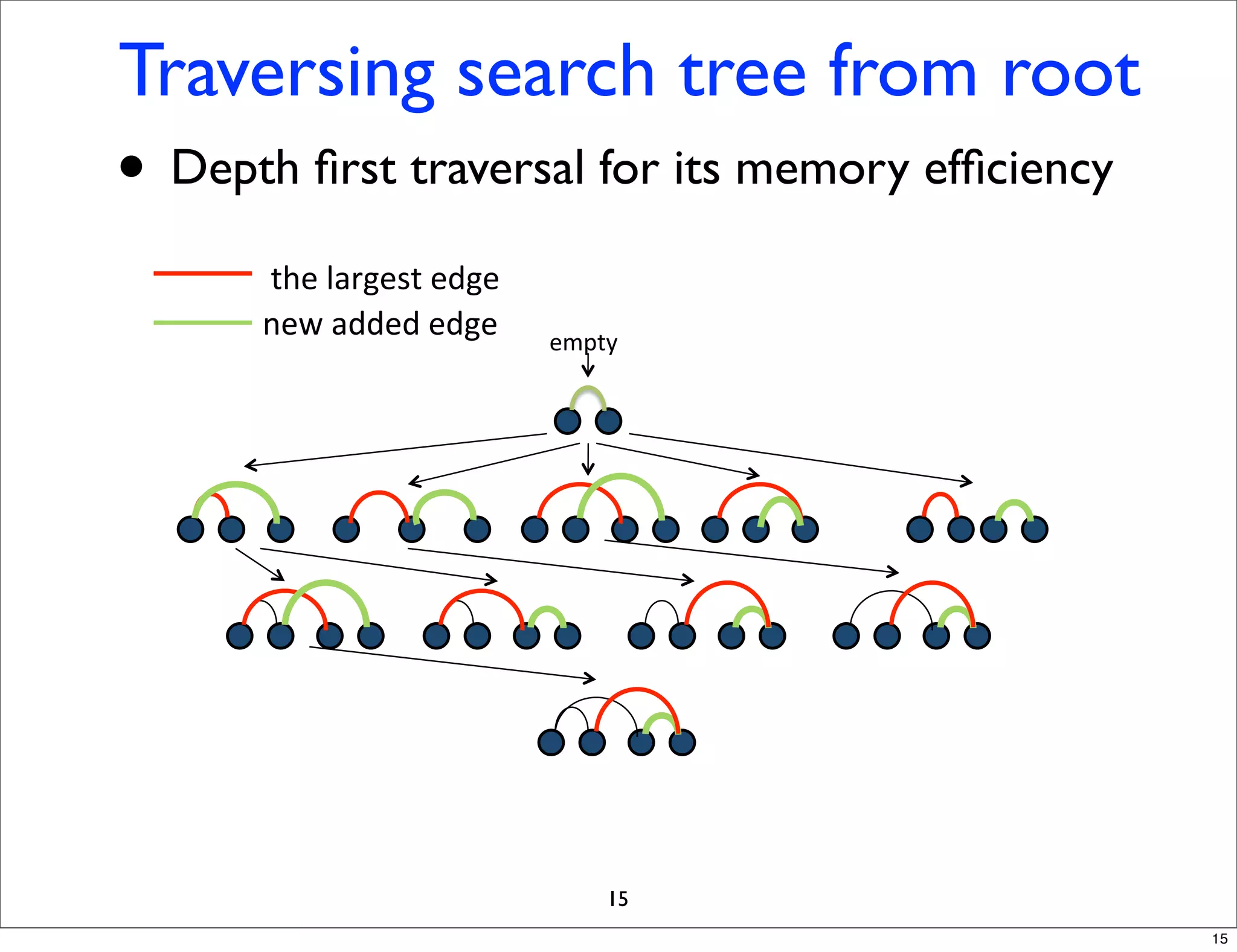



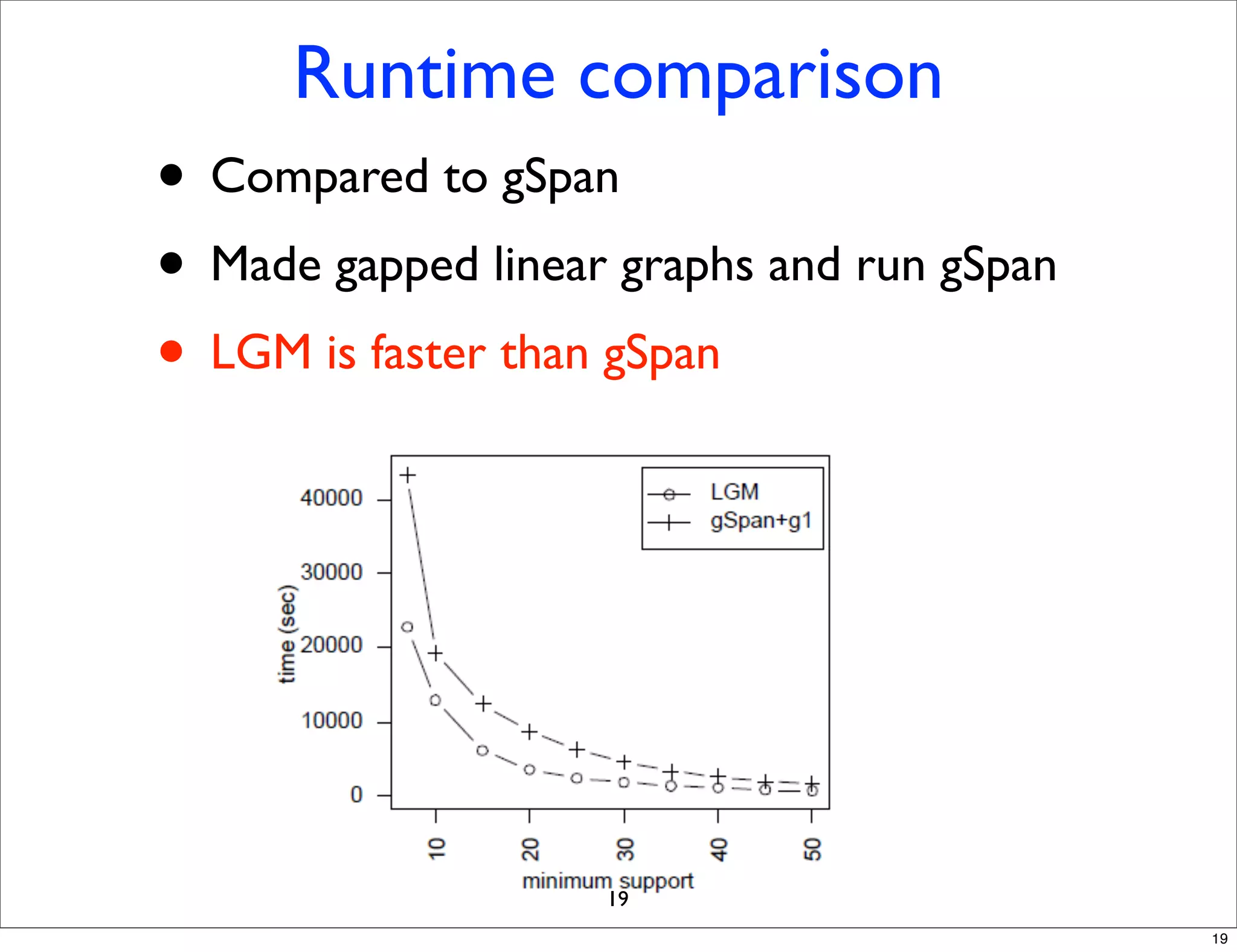




LGM is an algorithm that efficiently mines frequent subgraphs from a set of linear graphs. It uses a reverse search approach to enumerate all subgraphs without duplication, defining a search tree with a reduction map. By inverting the reduction map, it can extend patterns from parent to children nodes. Experiments apply LGM to mine motifs from protein structures, finding statistically significant patterns associated with thermophilic or mesophilic functions.










![Digital Signals and System (April – 2015) [Revised Syllabus | Question Paper]](https://cdn.slidesharecdn.com/ss_thumbnails/dss-rs-qp-april-2015-180428083802-thumbnail.jpg?width=640&height=640&fit=bounds)





![B.Sc.IT: Semester - VI (October - 2016) [IDOL - Revised Course | Question Paper]](https://cdn.slidesharecdn.com/ss_thumbnails/bscit-sem-vi-idol-oct-2016-qp-180803214341-thumbnail.jpg?width=640&height=640&fit=bounds)







![[Question Paper] Data Communication and Network Standards (Revised Course) [J...](https://cdn.slidesharecdn.com/ss_thumbnails/dcns-qprevisedcoursejun-2014-170714195207-thumbnail.jpg?width=640&height=640&fit=bounds)





























































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)
