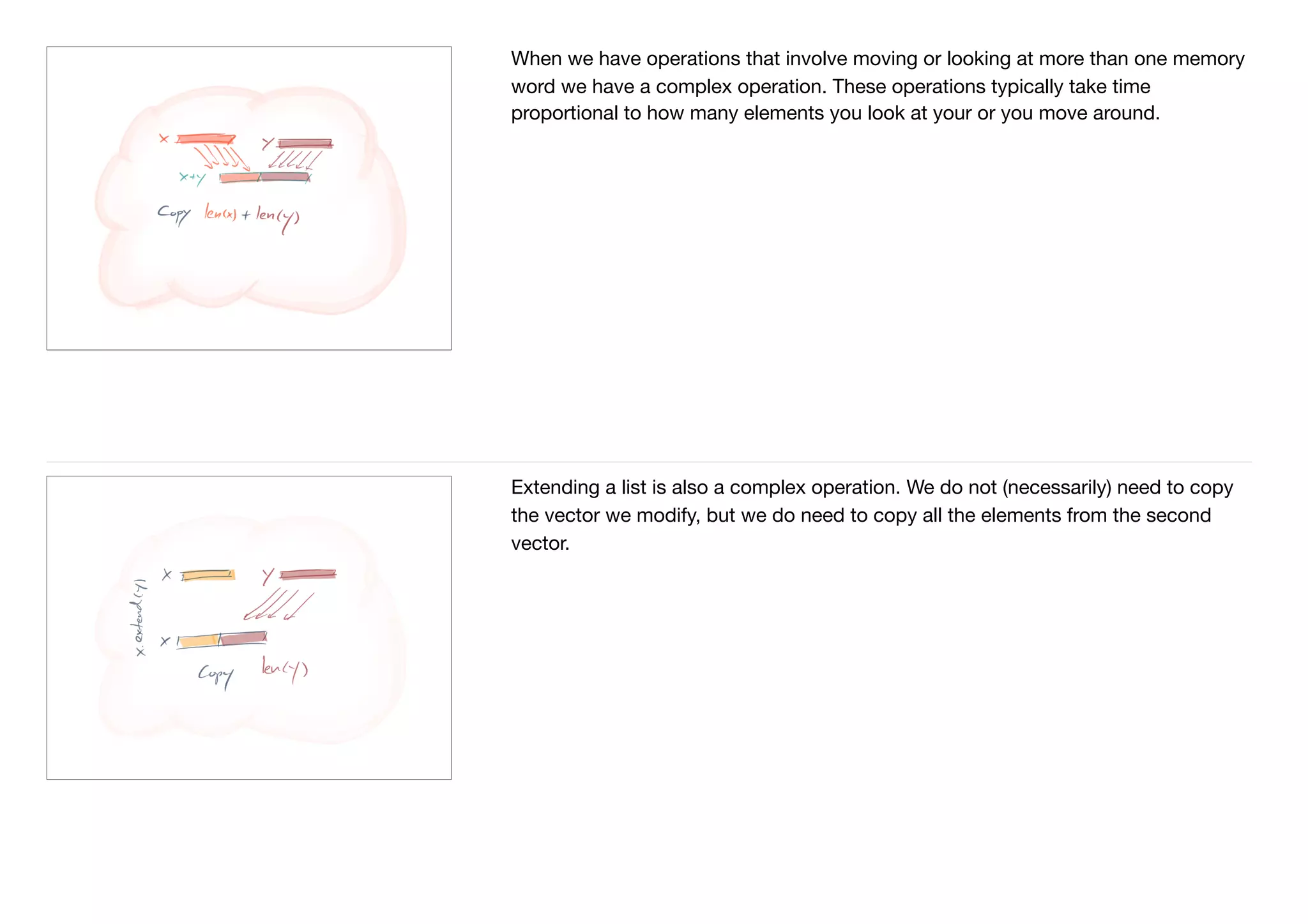
The document discusses algorithmic complexity and the RAM model for analyzing computational efficiency. It explains that the RAM model treats memory as contiguous words that can be accessed and stored values in primitive operations. Common data structures like lists can be modeled in this way. The complexity of operations like concatenating lists, deleting elements, or extending lists is analyzed based on the number of primitive operations required. The document also covers analyzing best, average, and worst-case complexity and discusses common complexity classes like constant, logarithmic, linear, and quadratic time.




![If you delete an element inside the list, you need to copy all the preceding items,
so that is also an operation that requires a number of primitive operations that is
proportional to the number of items copied. (You can delete the last element with a
few operations because you do not need to copy any items in that case).
Assumptions:
• All primitive operations take the
same time
• The cost of complex operations
is the sum of their primitive
operations
When we figure out how much time it takes to solve a particular problem, we
simply count the number of primitive operations the task takes. We do not
distinguish between the types of operations—that would be too hard, trust me, and
wouldn’t necessarily map well to actual hardware.
In all honesty, I am lying when I tell you that there even are such things as complex
operations. There are operations in Python that looks like they are operations at the
same level as getting the value at index i in list x, x[i], but are actually more
complicated. I call such things "complex operations", but the only reason that I
have to distinguish between primitive and complex operations is that a lot is
hidden from you when you ask Python to do such things as concatenate two lists
(or two strings) or when you slice out parts of a list. At the most primitive level, the
computer doesn’t have complex operations. If you had to implement Python based
only one the primitive operations you have there, then you would appreciate that](https://image.slidesharecdn.com/chapter4-algorithmicefficiencyhandoutswithnotes-181112062536/75/Chapter-4-algorithmic-efficiency-handouts-with-notes-5-2048.jpg)
![For some operations it isn’t necessarily clear exactly how many primitive
operations we need.
Can we assign to and read from variables in constant time? If we equate variable
names with memory locations, then yes, but otherwise it might be more complex.
When we do an operation such as "x = x + 5" do we count that as "read the value
of x" then "add 5 to it" and finally "put the result in the memory location referred to
as x"? That would be three operations. But hardware might support adding a
constant to a location as a single operation—quite frequently—so "x += 5" might
be faster; only one primitive operation.
Similarly, the number of operations it takes to access or update items at a given
index into a list can vary depending on how we imagine they are done. If the
variable x indicates the start address of the elements in the list (ignoring where we
store the length of the list), then we can get index i by adding i to x: x[0] is memory
address x, x[1] is memory address x + 1, …, x[i] is memory address x + i. Getting
that value could be
1.get x
2.add i
3.read has is at the address x+i
that would be three operations. Most hardware can combine some of them,
though. There are instructions that can take a location and an offset and get the
value in that word as a single instruction. That would be](https://image.slidesharecdn.com/chapter4-algorithmicefficiencyhandoutswithnotes-181112062536/75/Chapter-4-algorithmic-efficiency-handouts-with-notes-6-2048.jpg)