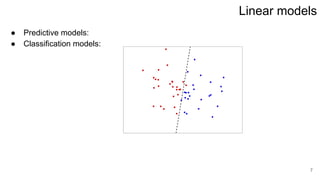
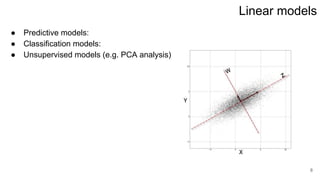
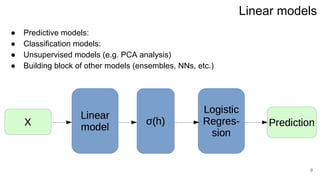
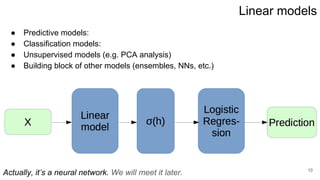
This lecture covers linear regression models. It discusses linear regression problem statements, analytical solutions using least squares, regularization to address ill-conditioned matrices, and probabilistic interpretations of regularization. The key topics are:
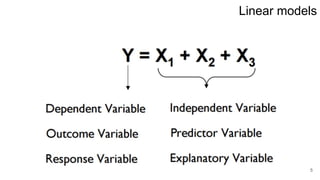
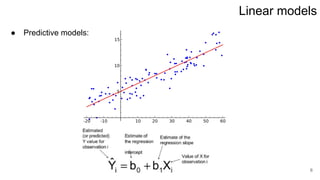
1. Linear regression finds a linear function to model the relationship between inputs and output in a dataset.
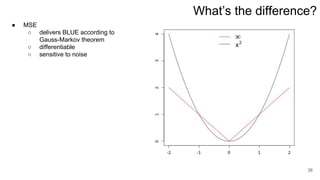
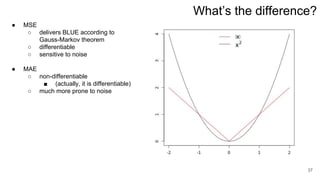
2. Least squares estimation provides an analytical solution for the optimal weights vector that minimizes error.
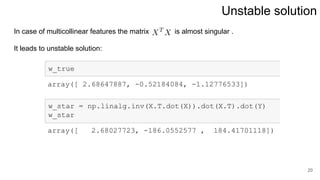
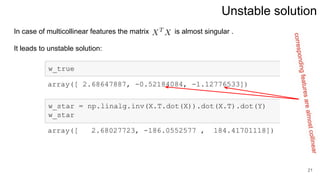
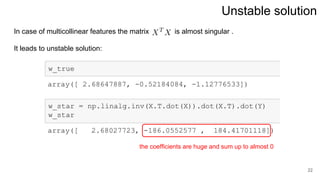
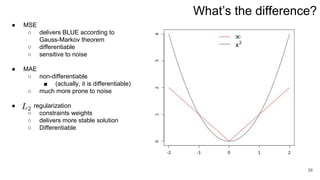
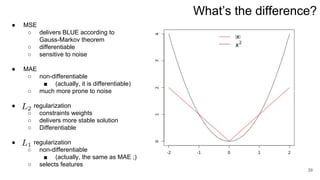
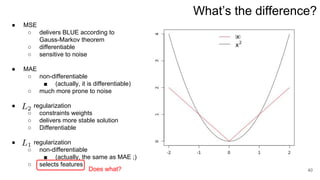
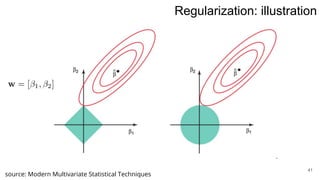
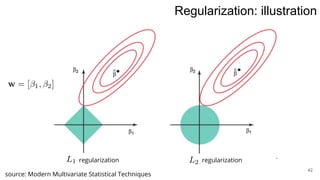
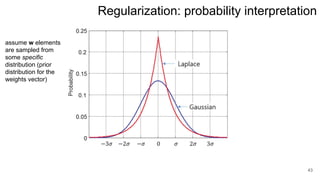
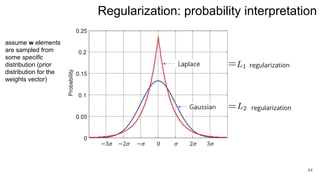
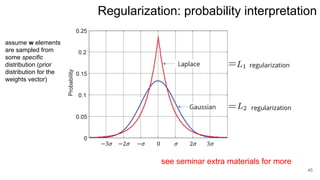
3. Regularization adds a diagonal matrix to make the matrix nonsingular when features are multicollinear, providing a more stable solution.