The document discusses physical database design, including:
- Designing fields by choosing data types, coding techniques, and controlling data integrity.
- Denormalizing relations through joining tables or data replication to improve processing speed at the cost of storage space and integrity.
- Organizing physical files through sequential, indexed, or hashed arrangements and using indexes to efficiently locate records.
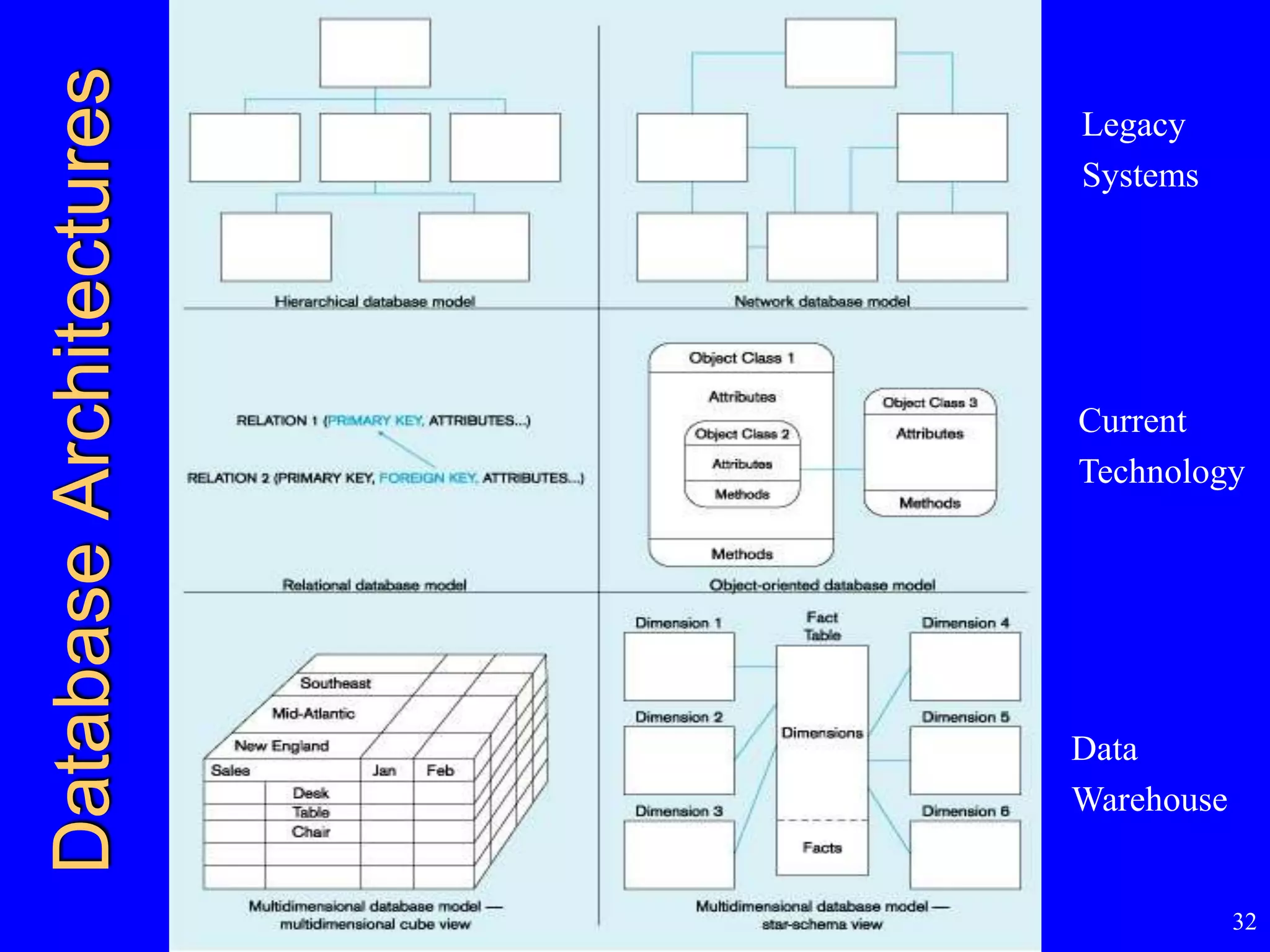
- Database architectures including legacy systems, current technologies, and data warehouses.
2
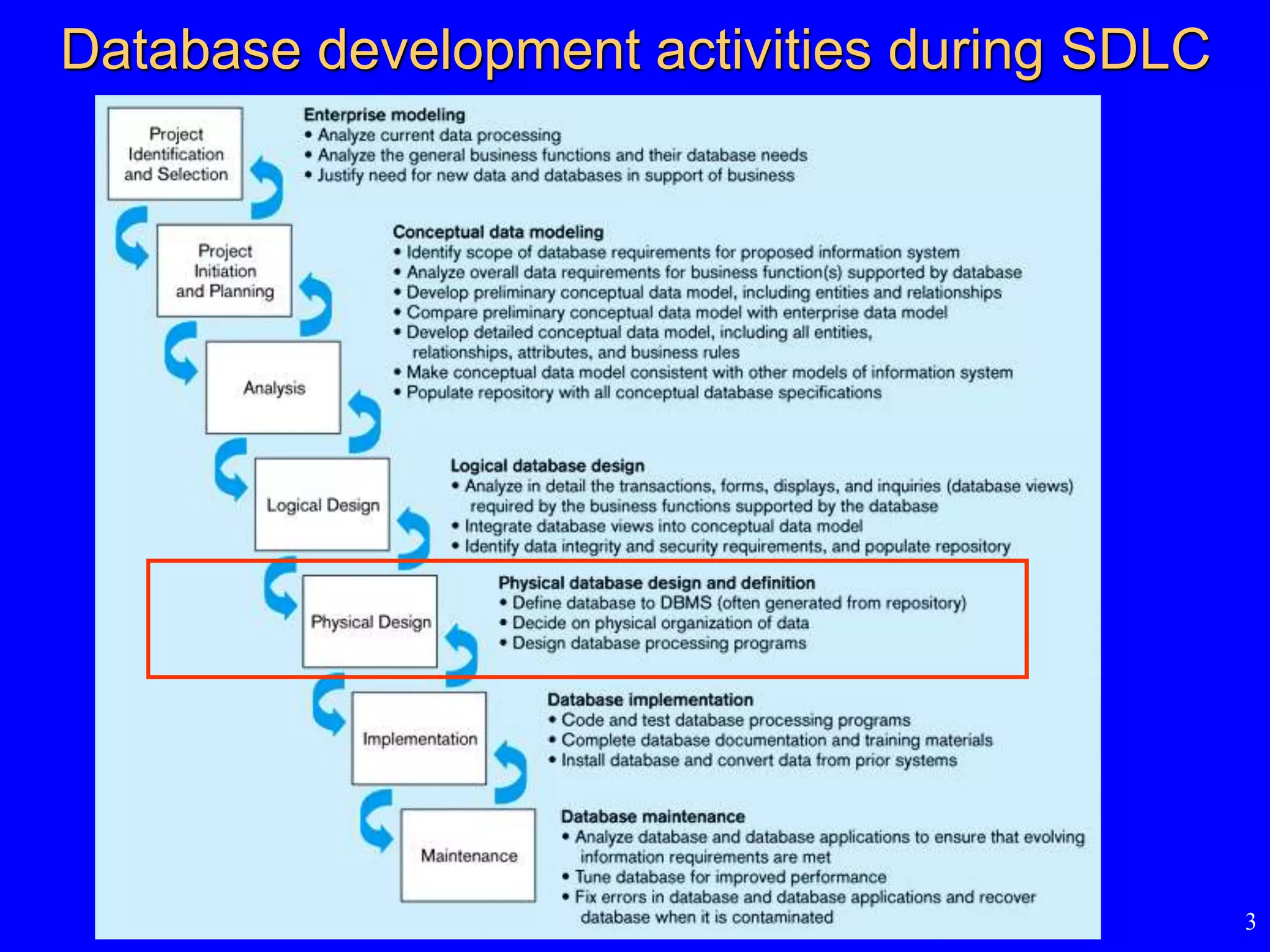
Where we arenow
• Database environment
– Introduction to database
• Database development process
– steps to develop a database
• Conceptual data modeling
– entity-relationship (ER) diagram; enhanced ER
• Logical database design
– transforming ER diagram into relations; normalization
• Physical database design
– technical specifications of the database
• Database implementation
– Structured Query Language (SQL), Advanced SQL
• Advanced topics
– data and database administration
4
Physical Database Design
•Physical Database Design Process
• Designing Fields
• Designing Physical Records and Denormalization
• Designing Physical Files
• Choosing Database Architectures
5.
5
Physical Database Design
•Purpose
– translate the logical description of data into the technical
specifications for storing and retrieving data
• Goal
– create a design for storing data that will provide adequate
performance and insure database integrity, security and
recoverability
– balance between efficient storage space and processing
speed
– efficient processing tend to dominate as storage is getting
cheaper
6.
6
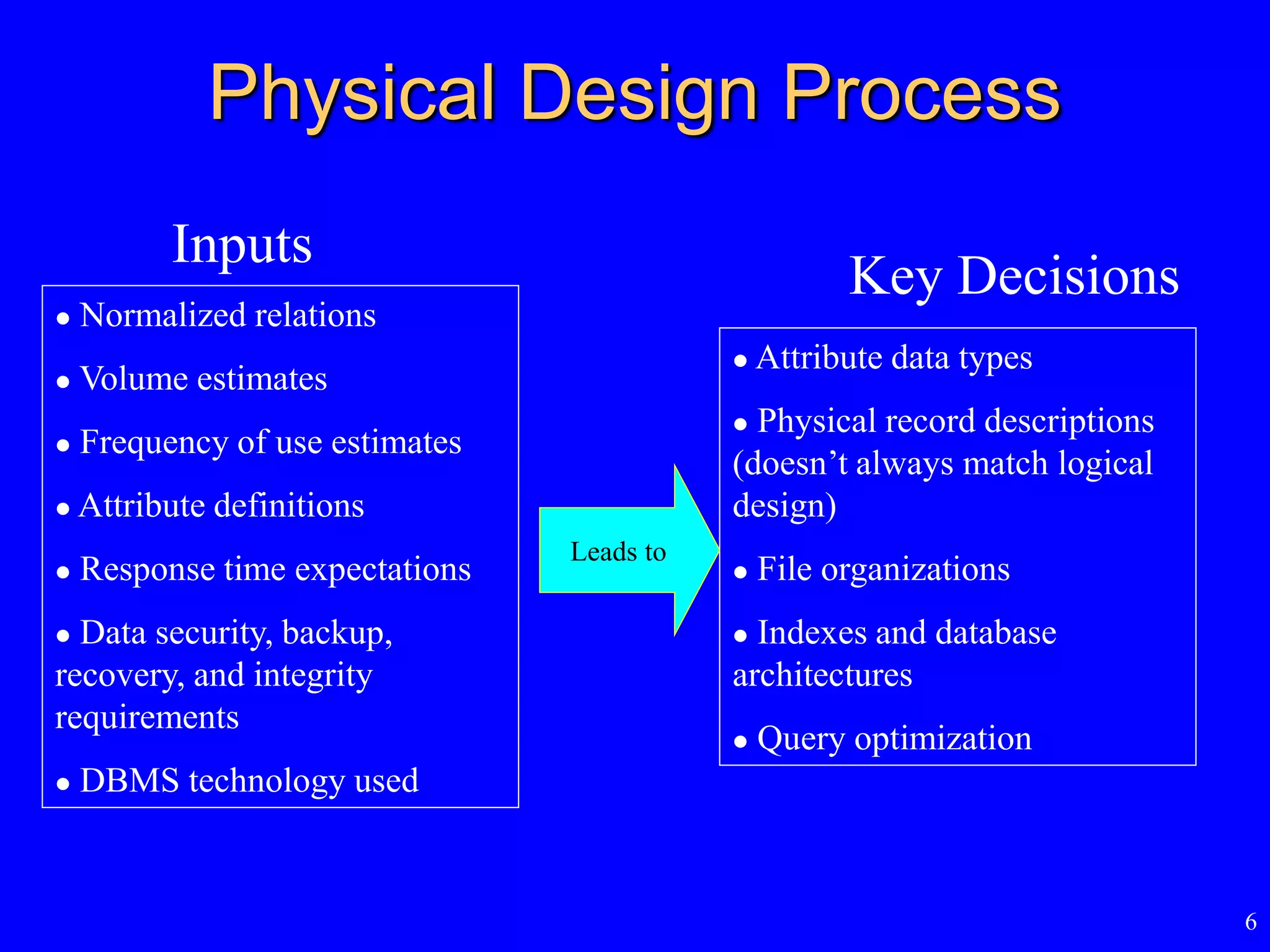
Physical Design Process
Normalized relations
Volume estimates
Frequency of use estimates
Attribute definitions
Response time expectations
Data security, backup,
recovery, and integrity
requirements
DBMS technology used
Inputs
Attribute data types
Physical record descriptions
(doesn’t always match logical
design)
File organizations
Indexes and database
architectures
Query optimization
Leads to
Key Decisions
7.
7
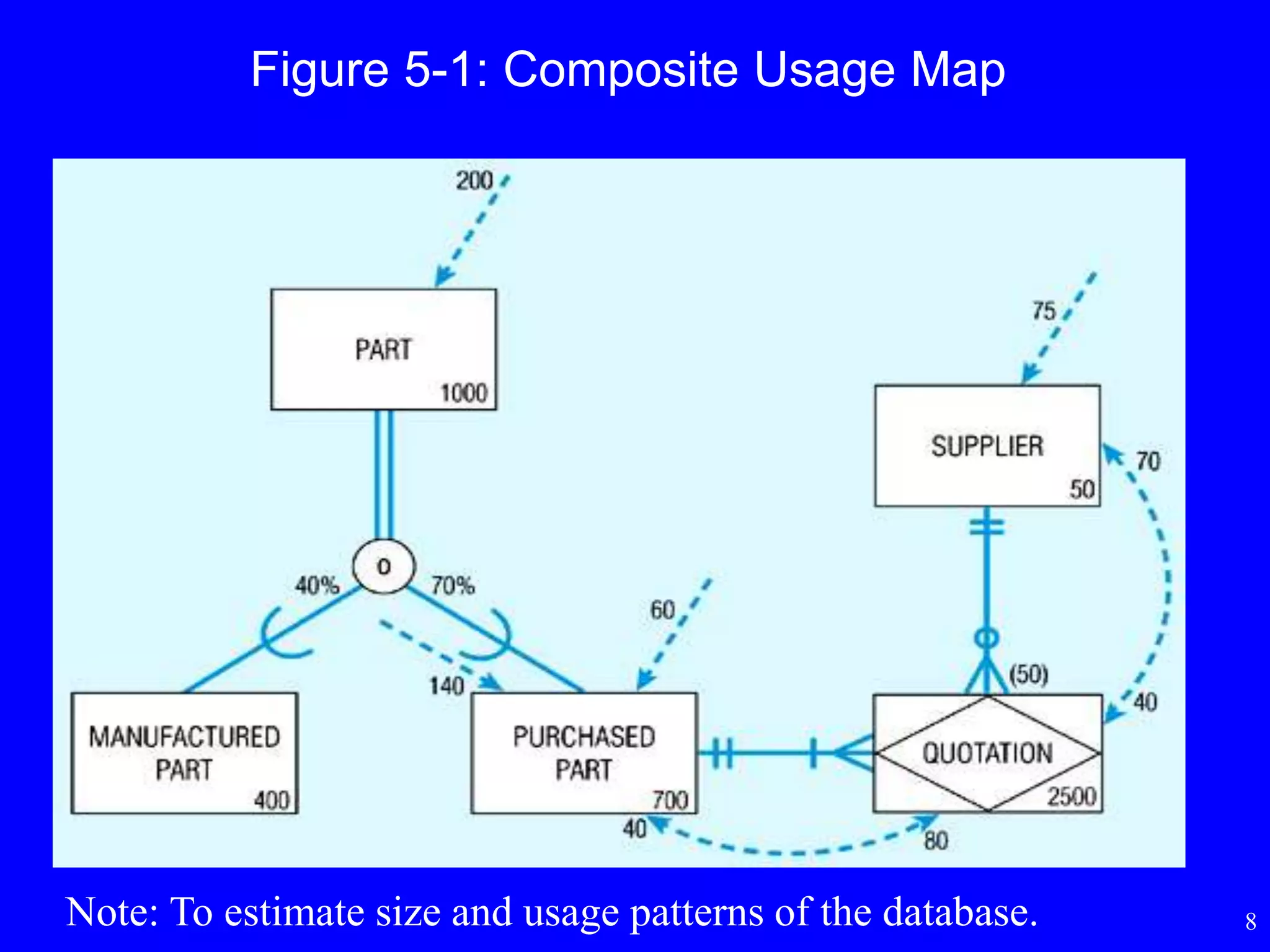
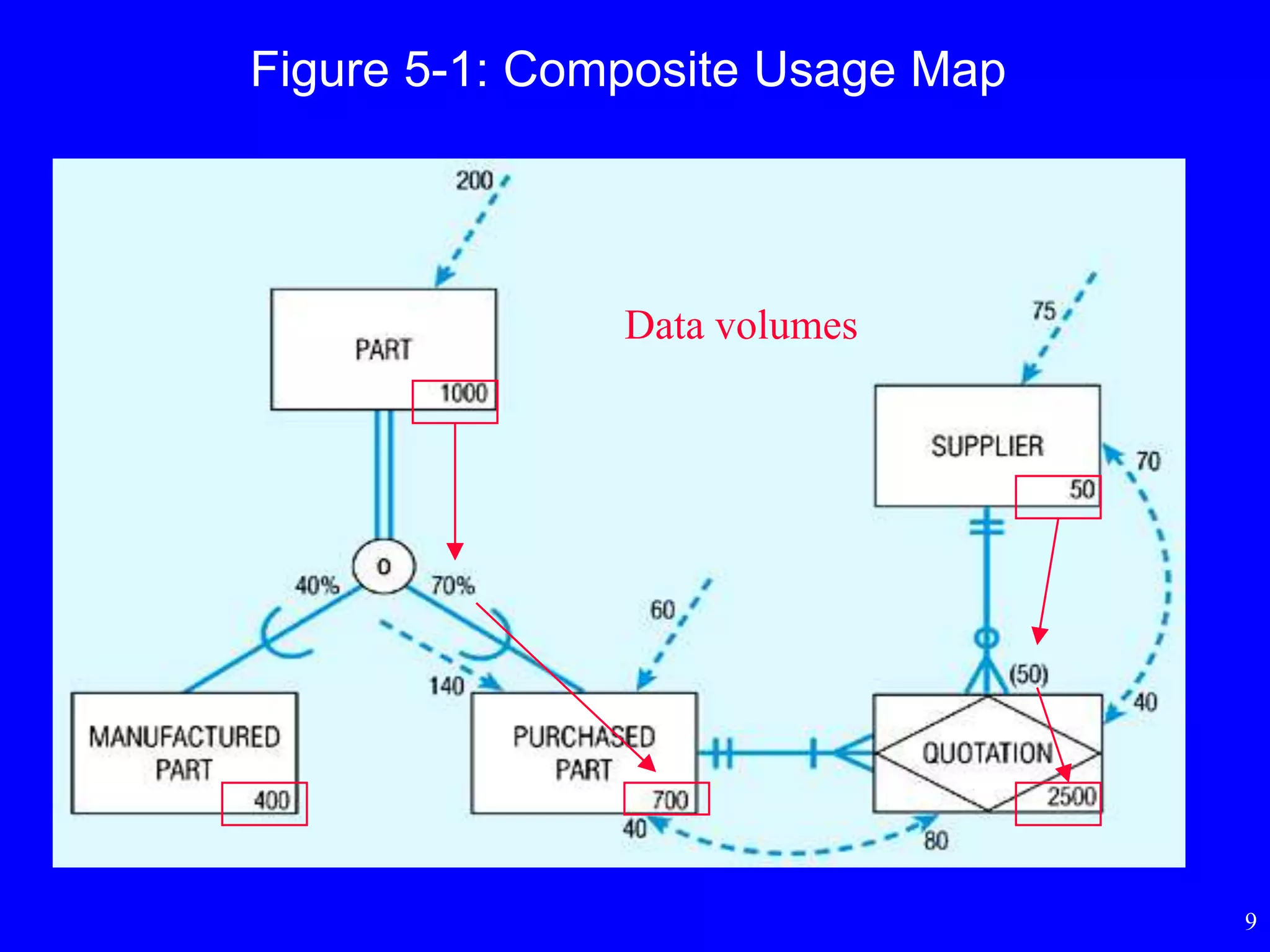
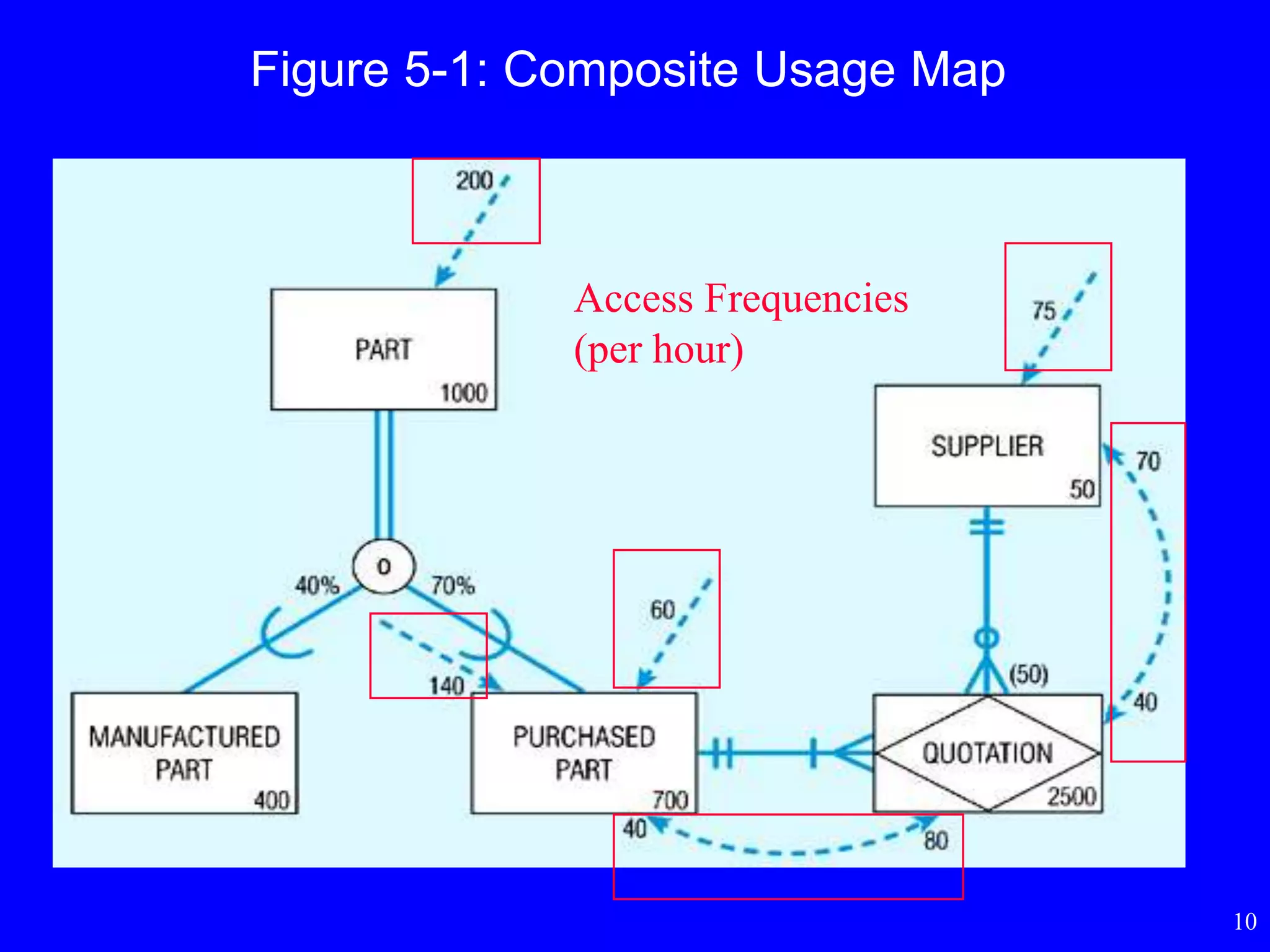
Composite Usage Map
•To estimate data volume and frequency of use
statistics
• First step in physical database design or last step
in logical database design
• Add notations to the EER diagram
11
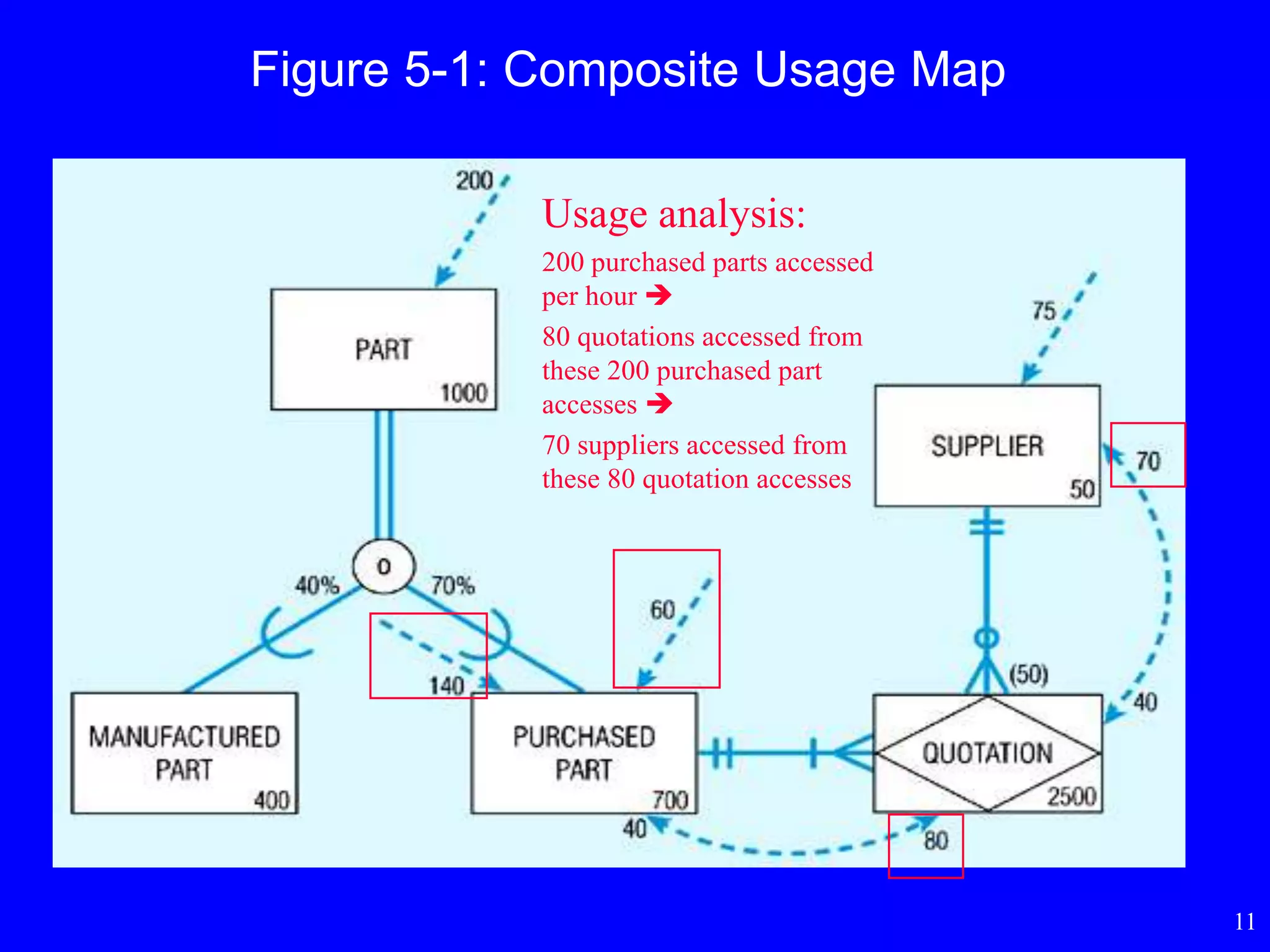
Figure 5-1: CompositeUsage Map
Usage analysis:
200 purchased parts accessed
per hour
80 quotations accessed from
these 200 purchased part
accesses
70 suppliers accessed from
these 80 quotation accesses
12.
12
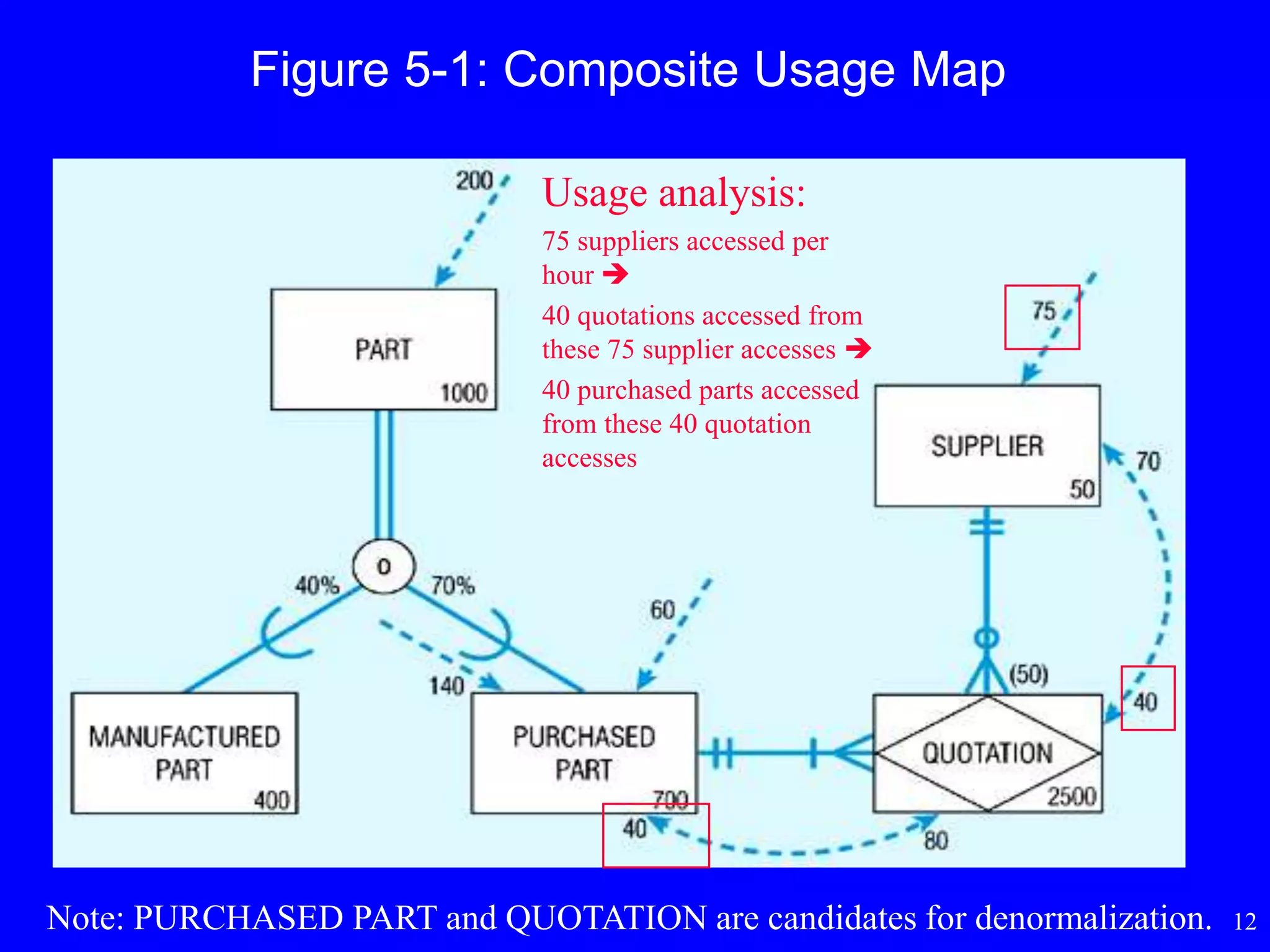
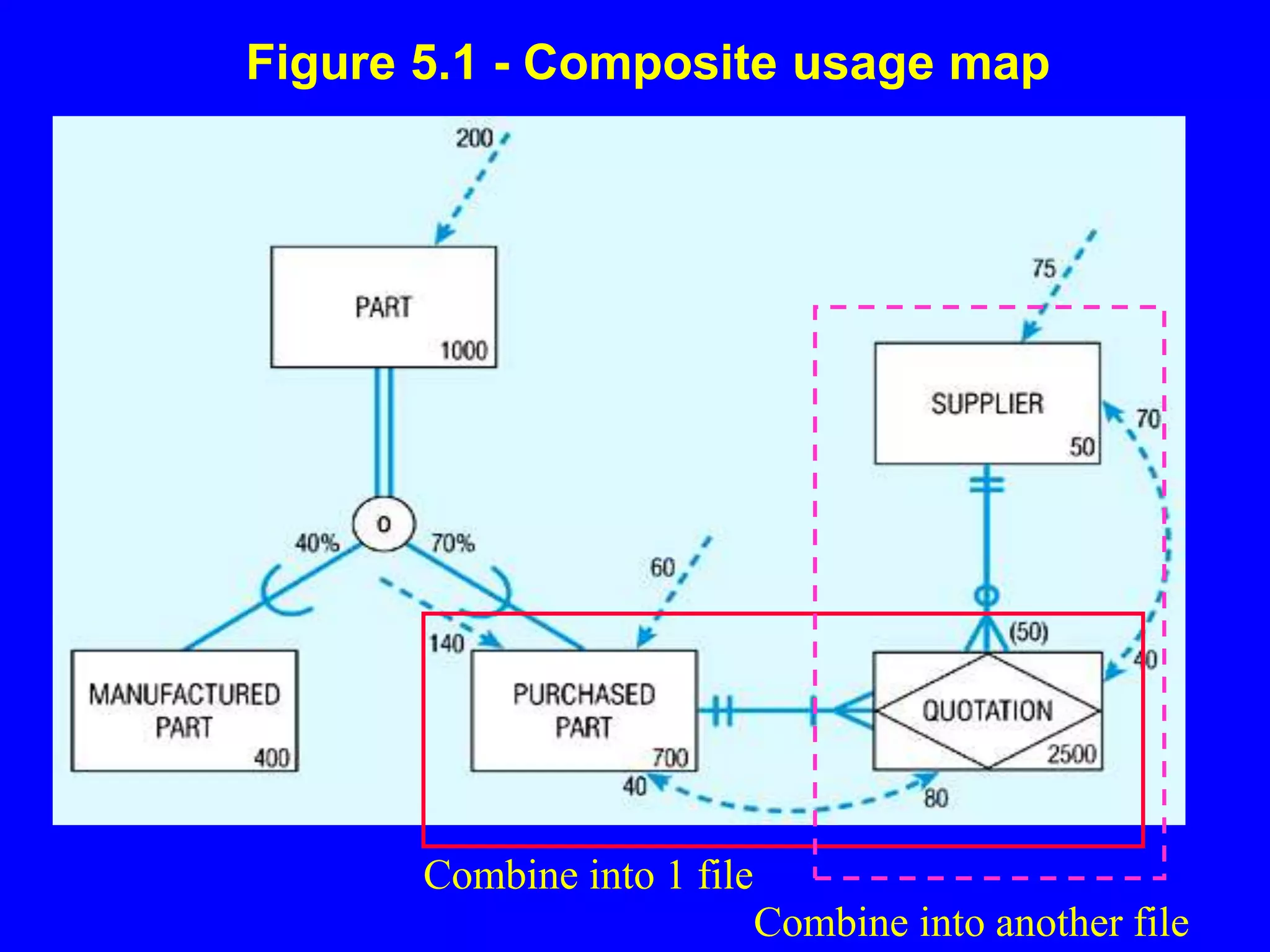
Figure 5-1: CompositeUsage Map
Usage analysis:
75 suppliers accessed per
hour
40 quotations accessed from
these 75 supplier accesses
40 purchased parts accessed
from these 40 quotation
accesses
Note: PURCHASED PART and QUOTATION are candidates for denormalization.
13.
13
Designing Fields
• Field
–smallest unit of data in database
– correspond to a simple attribute from the E-R diagram
• Field design
– choosing data types
– coding techniques
– controlling data integrity
– handling missing values
14.
14
Choosing Data Types
•Correct data type to choose for a field should
– minimize storage space
– represent all possible values
– improve data integrity (eliminate illegal values)
– support all data manipulations
• Examples of data types
– CHAR: fixed-length character
– VARCHAR2: variable-length character
– CLOB: capable of storing up to 4GB (e.g. customer’s comment)
– NUMBER: positive/negative number
– DATE: actual date and time
– BLOB: binary large object (e.g. photograph or sound clip)
15.
15
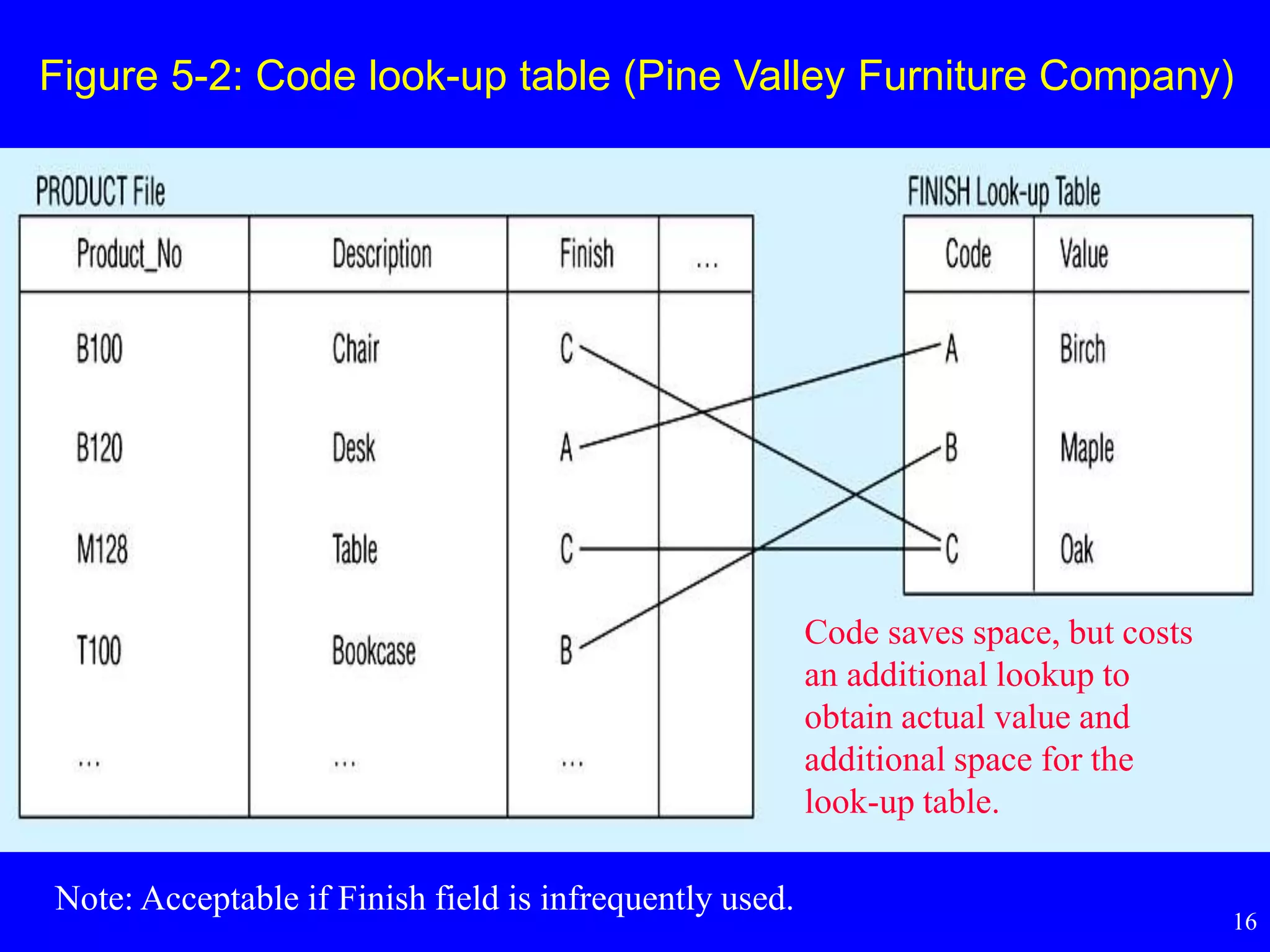
Coding Techniques
• Someattributes may be very large
• These data are further apart; results in slower
data processing
• Create a code look-up table
16.
16
Figure 5-2: Codelook-up table (Pine Valley Furniture Company)
Code saves space, but costs
an additional lookup to
obtain actual value and
additional space for the
look-up table.
Note: Acceptable if Finish field is infrequently used.
17.
17
Controlling Data Integrity
•Control on the possible values a field can assume
– Default value
value a field will assume unless a user enters an explicit
value for that field
– Range control
limits the set of permissible values a field can assume
– Null value control
allowing or prohibiting empty fields
e.g. primary keys
– Referential integrity
range control for foreign-key to primary-key match-ups
18.
18
Handling Missing Data
•Substitute an estimate of the missing value
– e.g. using some formula
• Trigger a report listing missing values
• Perform sensitivity analysis
– missing data are ignored unless knowing a value
might be significant
19.
19
Designing Physical Records
•Physical record
– a group of fields stored in adjacent memory locations and
retrieved or written together as a unit by a DBMS
• Sometimes, the normalized relation may not be
converted directly into a physical record
– often all the attributes in a relation are not used together,
and data from different relations are needed together to
produce a report
– efficient processing of data depends on how close together
related data are
20.
20
Denormalization
• Process oftransforming normalized relations into unnormalized
physical record specifications
– either by joining files, partitioning files or data replication
• Benefit
– improve processing speed
• Costs
– more storage space needed
– data integrity and inconsistency threats
• Common denormalization opportunities
– e.g. of combining tables to avoid doing joins
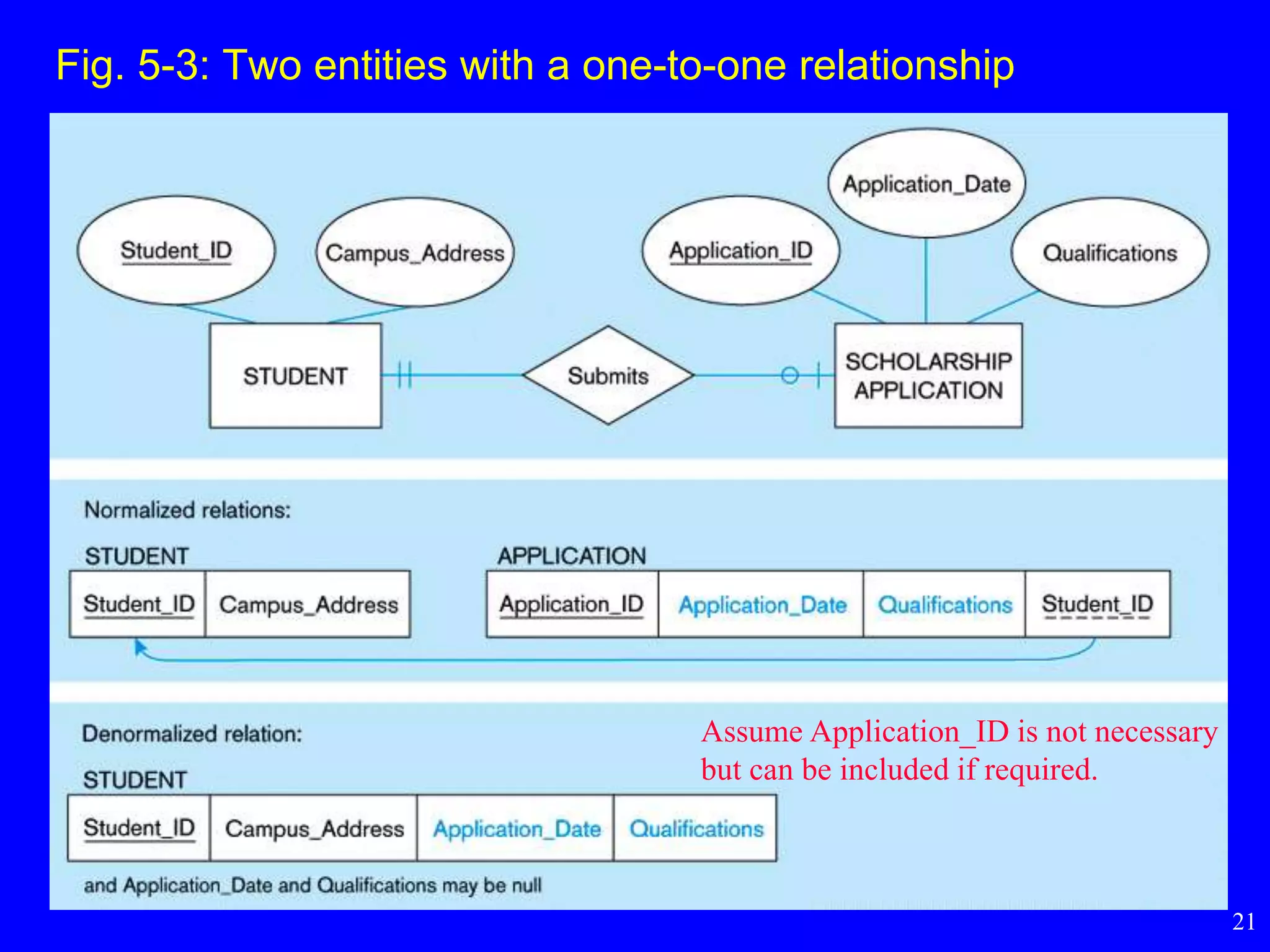
– one-to-one relationship
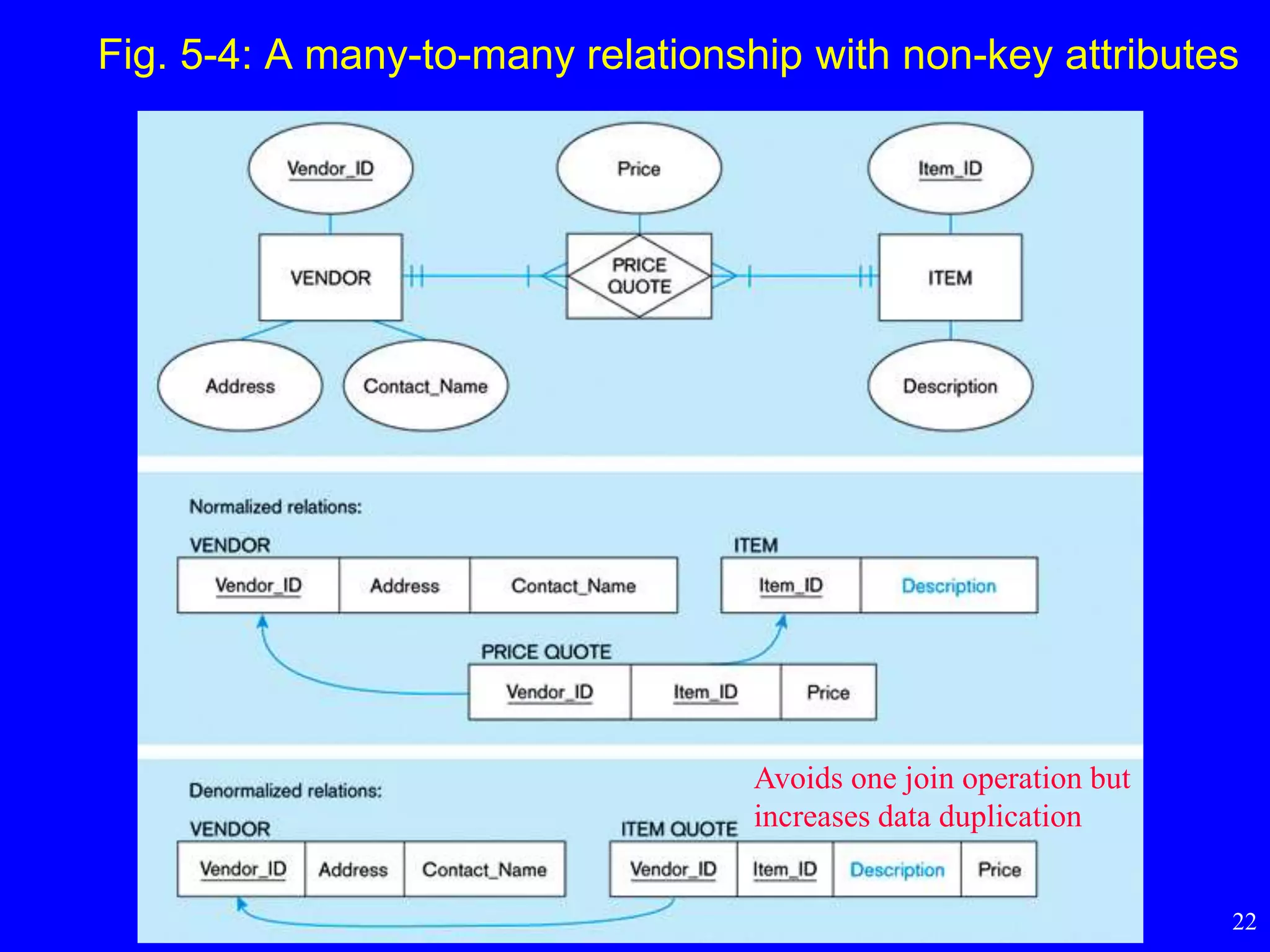
– many-to-many relationship with non-key attributes
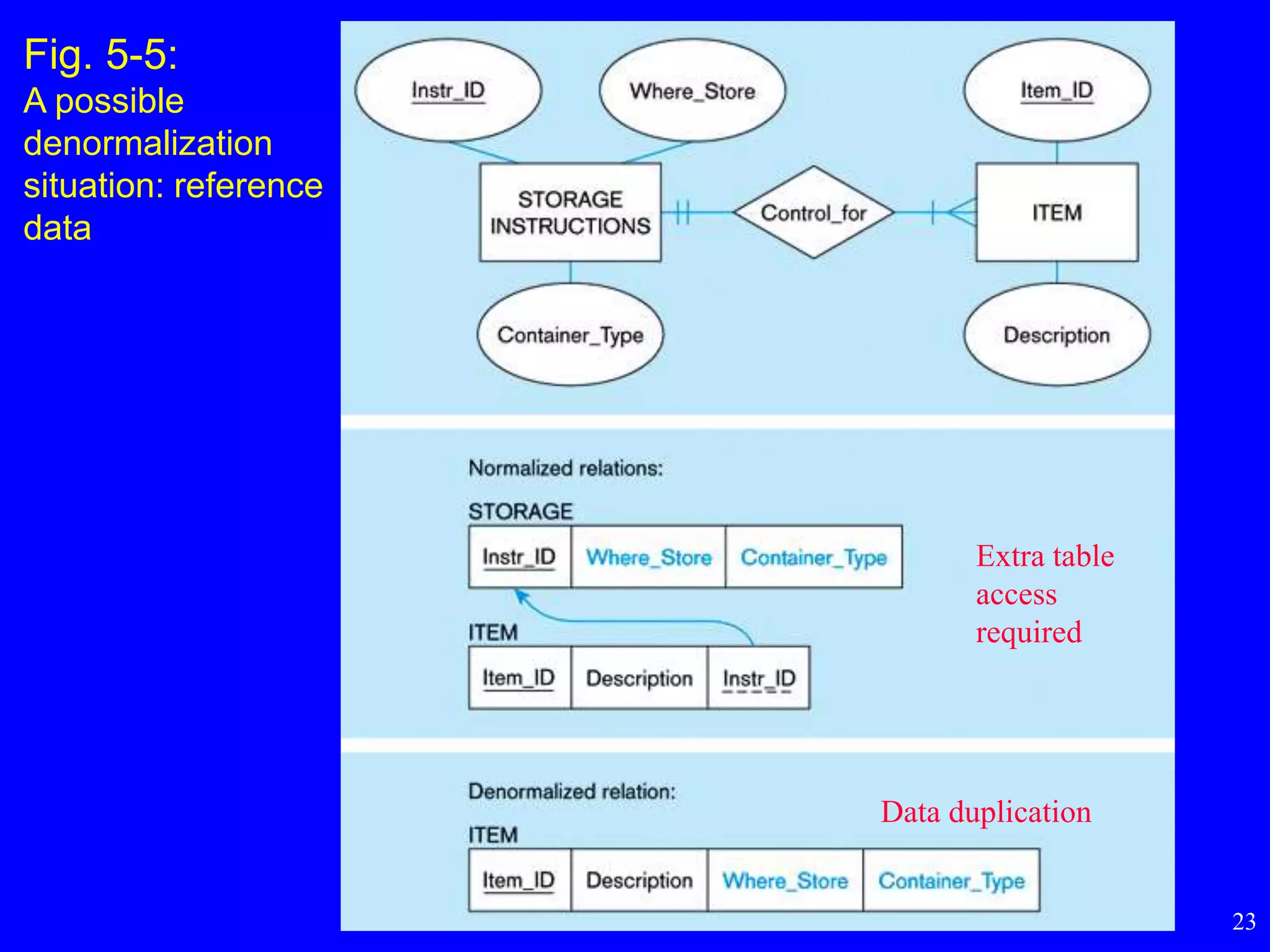
– reference data (1:N relationship where 1-side has data not used in any
other relationship)
21.
21
Fig. 5-3: Twoentities with a one-to-one relationship
Assume Application_ID is not necessary
but can be included if required.
22.
22
Fig. 5-4: Amany-to-many relationship with non-key attributes
Avoids one join operation but
increases data duplication
24
Partitioning
• Create moretables
• Horizontal partitioning
– distributing the rows of a table into several separate files
– useful for situations where different users need access to different rows
• Vertical partitioning
– distributing the columns of a table into several separate files
– the primary key must be repeated in each file
– useful for situations where different users need access to different
columns
• Combinations of horizontal and vertical partitioning
– useful for database distributed across multiple computers (distributed
database)
25.
25
Data Replication
• purposelystoring the same data in multiple locations of
the database
• improves performance by allowing multiple users to
access the same data at the same time with minimum
contention
• sacrifices data integrity due to data duplication
• best for data that is not updated often
26.
Figure 5.1 -Composite usage map
Combine into 1 file
Combine into another file
27.
27
Designing Physical Files
•Physical file
– a named portion of secondary memory (e.g. hard disk)
allocated for the purpose of storing physical records
• Basic constructs to link two pieces of data
– sequential storage
one field or record is stored right after another field or record
– pointers
a field of data that can be used to locate a related field or record
• File organization
– technique for physically arranging a file on the disk
– three types
Sequential file organization
Indexed file organization
Hashed file organization
28.
28
Fig. 5-7 (a)
Sequentialfile
organization
1
2
n
Records of the file
are stored in
sequence by the
primary key field
values.
every insert or
delete requires file
to be resorted
Note: Inflexible; not used in database but may be used to backup data from a database.
29.
29
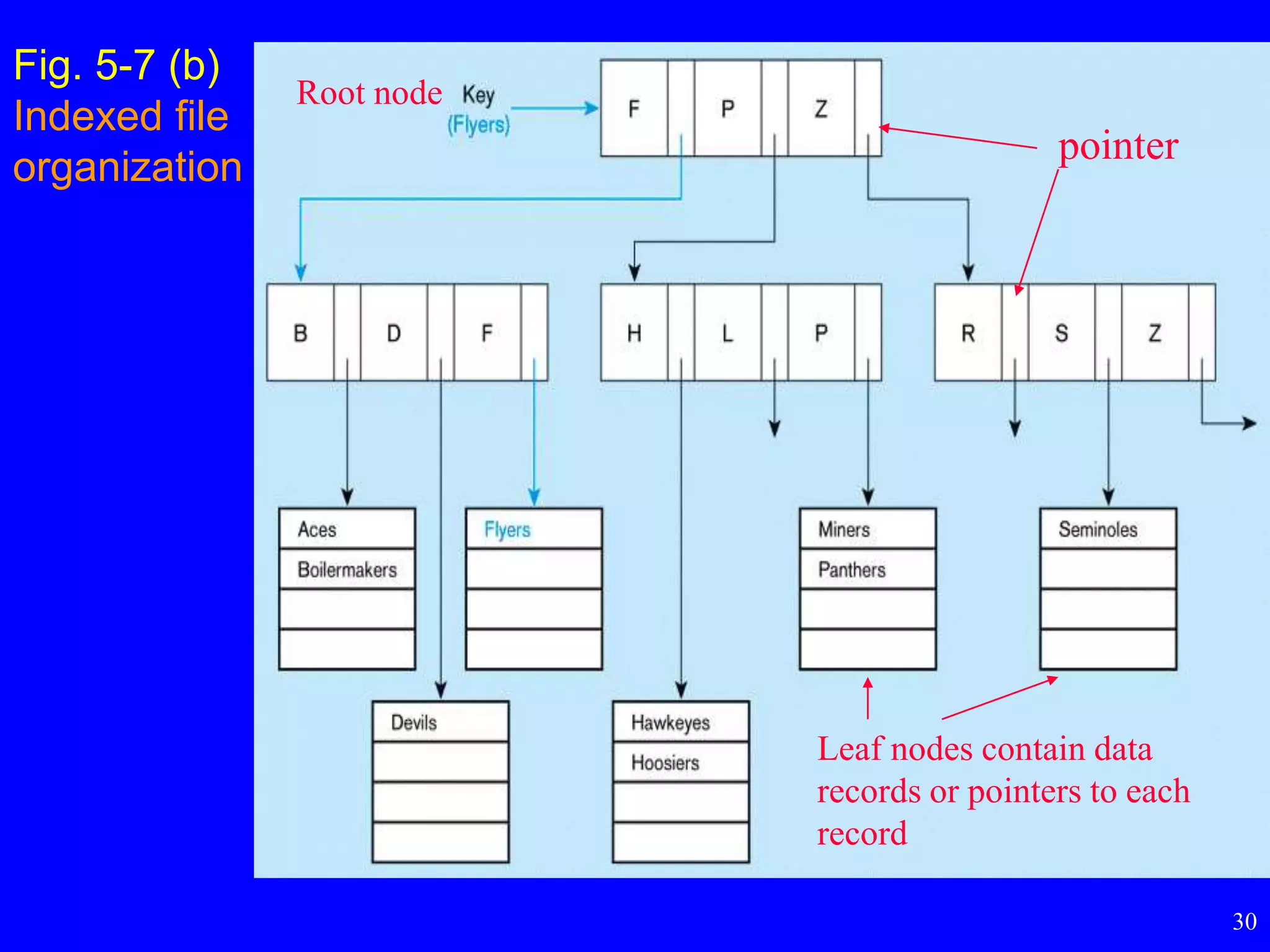
Indexed File Organizations
•More popular is indexed sequential file organization
– the storage of records sequentially with an index that allows
software to locate individual records
• Primary key index
– each index entry points a key value to a unique record
– primary keys are automatically indexed
• Secondary key index
– each index entry points to more than one record
– indexing on a non-primary key field
• Index handled by DBMS
30.
30
Fig. 5-7 (b)
Indexedfile
organization
Leaf nodes contain data
records or pointers to each
record
pointer
Root node
31.
31
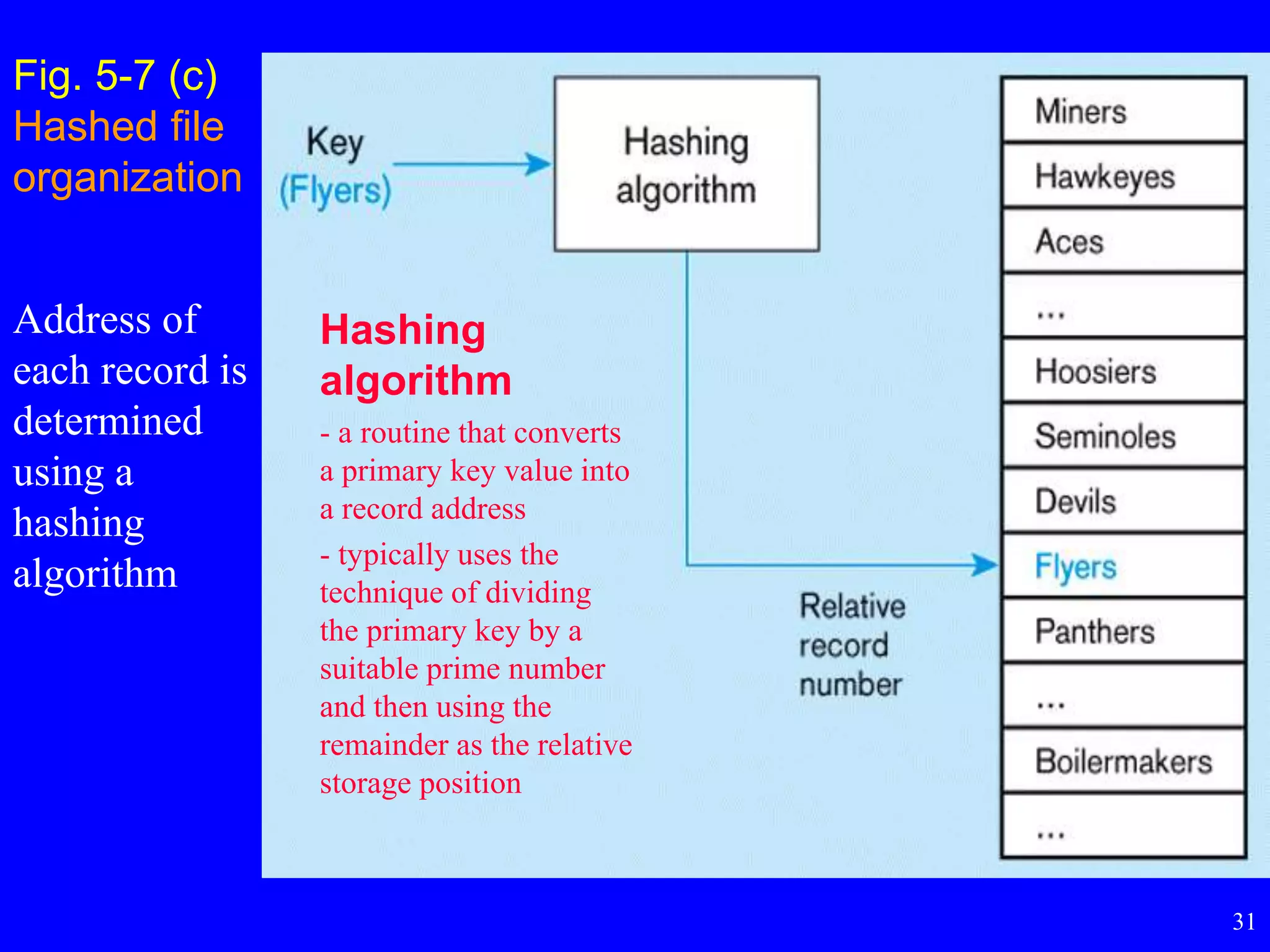
Fig. 5-7 (c)
Hashedfile
organization
Hashing
algorithm
- a routine that converts
a primary key value into
a record address
- typically uses the
technique of dividing
the primary key by a
suitable prime number
and then using the
remainder as the relative
storage position
Address of
each record is
determined
using a
hashing
algorithm
33
Review Questions
• Whatis a composite usage map?
• What are the 4 issues in designing fields?
• What are denormalization, partitioning, and data
replication?
• What are the 3 types of file organization?
• What are the types of database architectures?



















![Data Models [DATABASE SYSTEMS: Design, Implementation, and Management]](https://cdn.slidesharecdn.com/ss_thumbnails/coronelpptch02-datamodels-190903105908-thumbnail.jpg?width=640&height=640&fit=bounds)