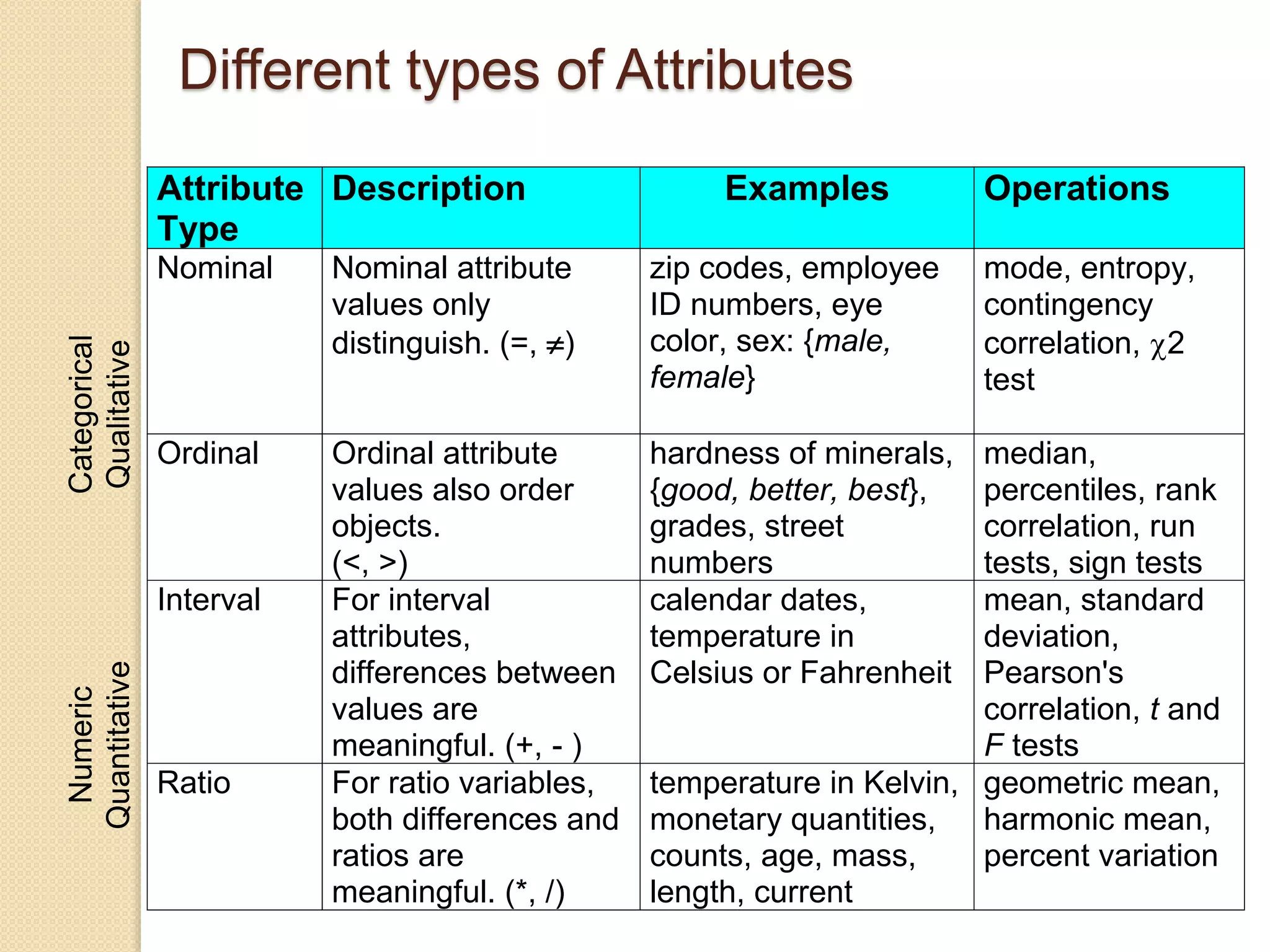
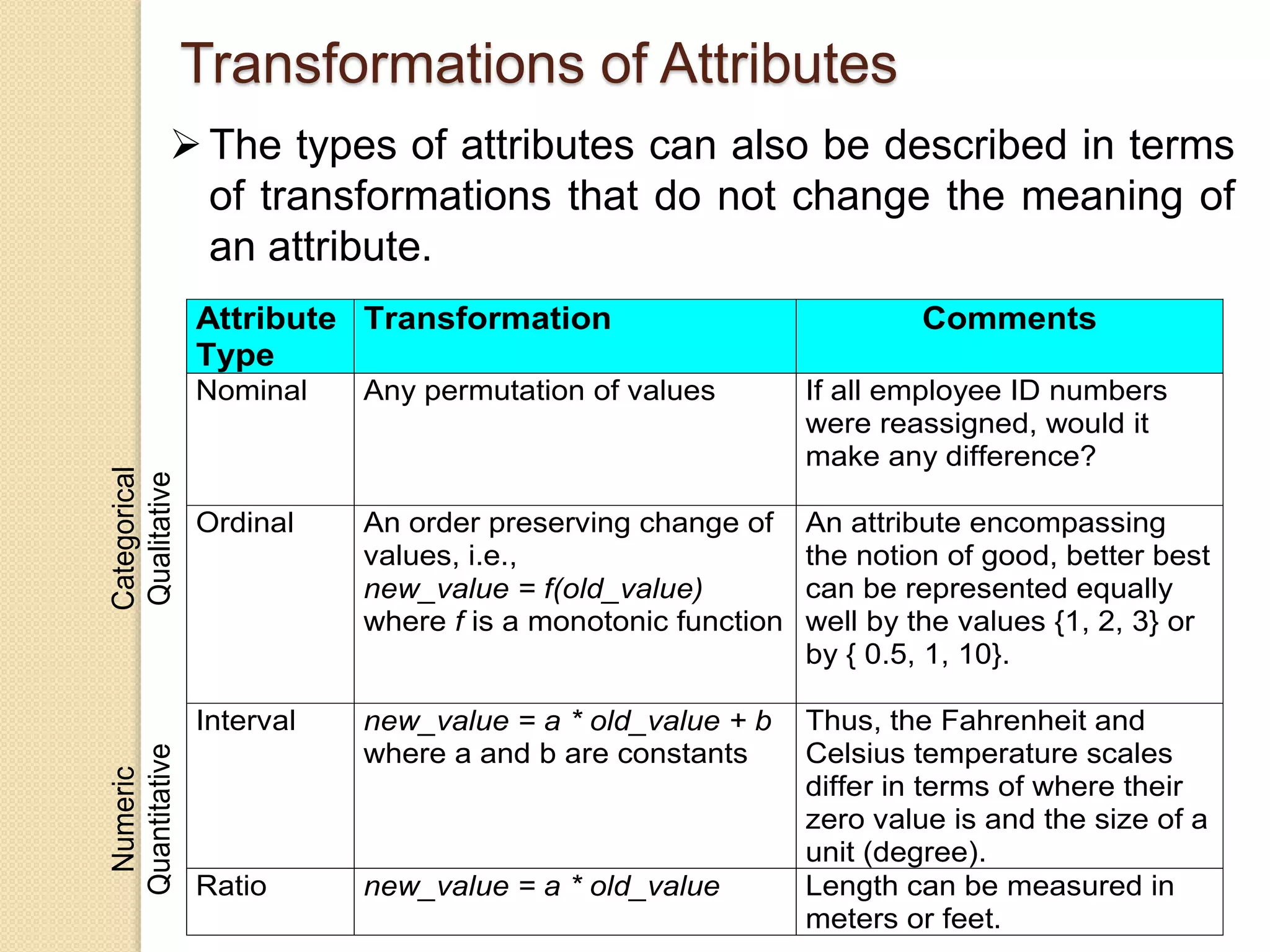
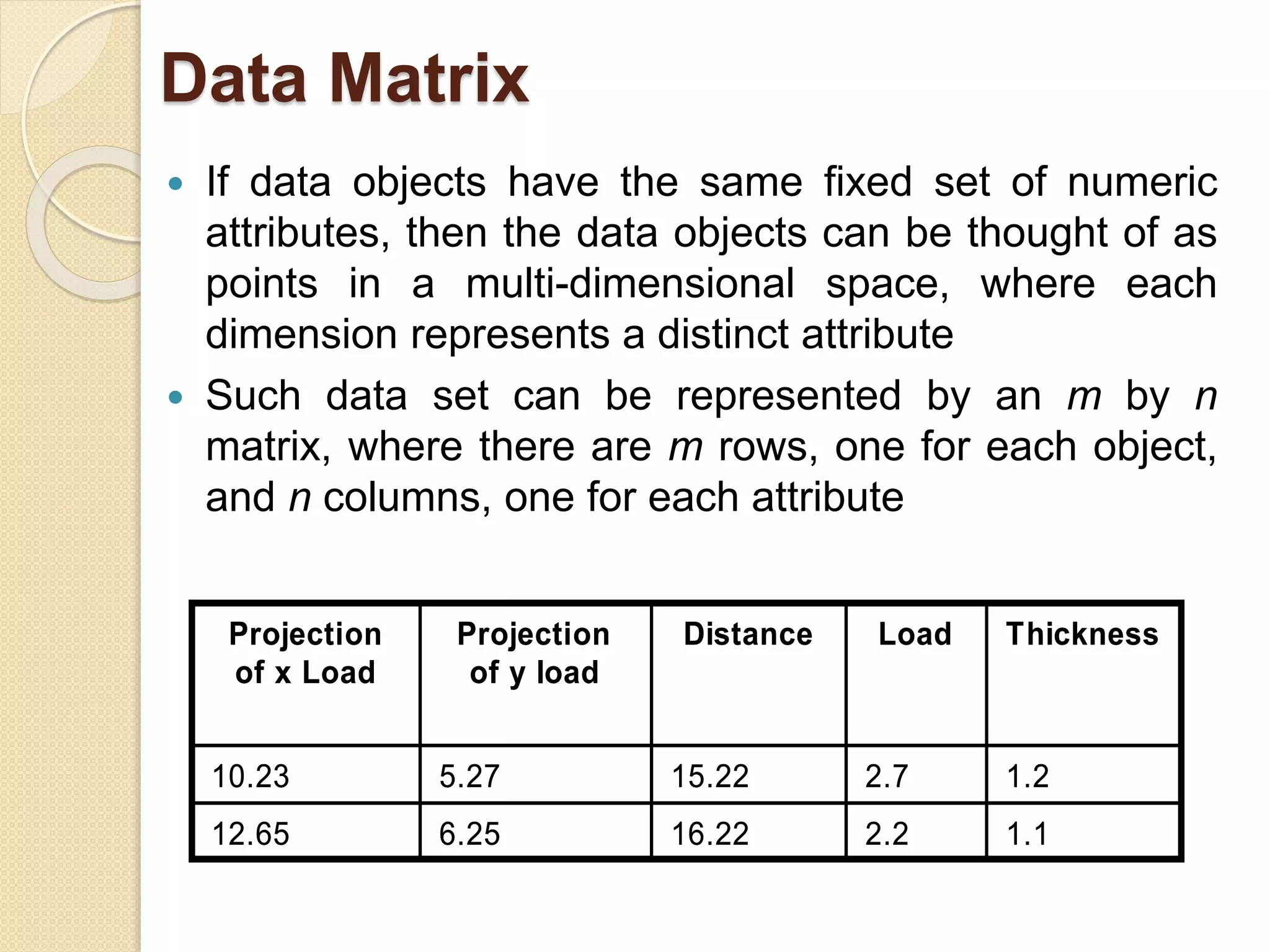
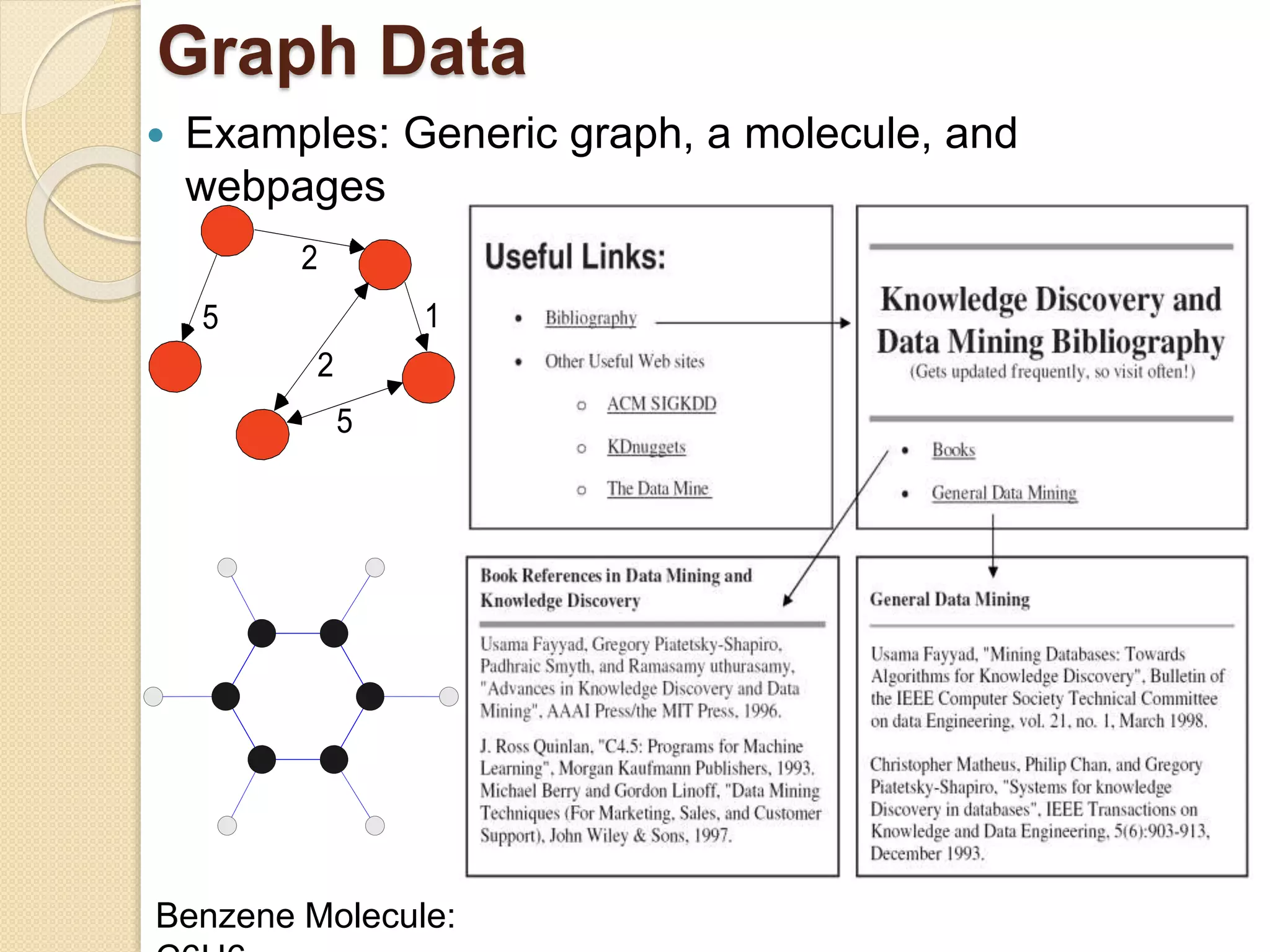
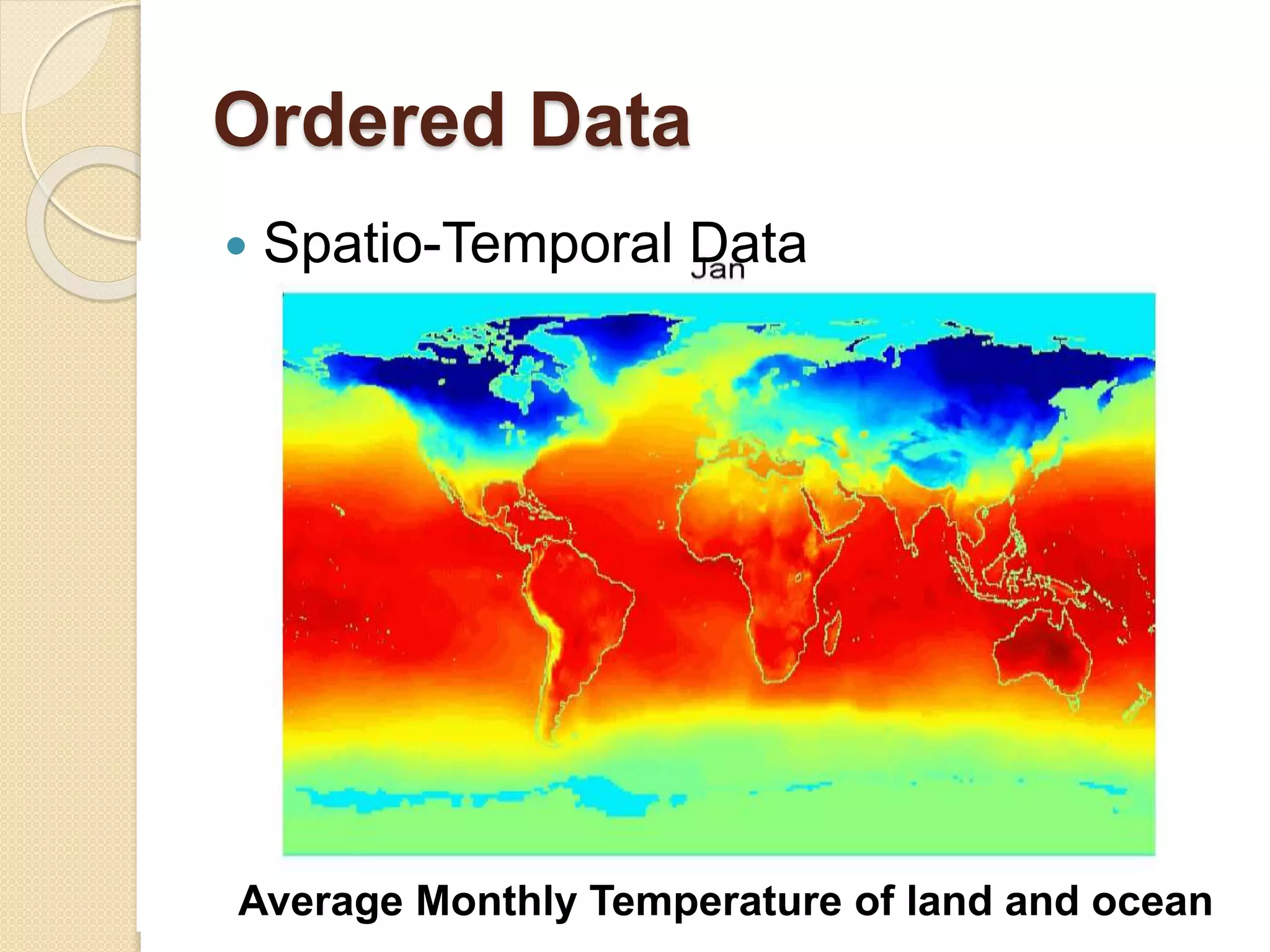
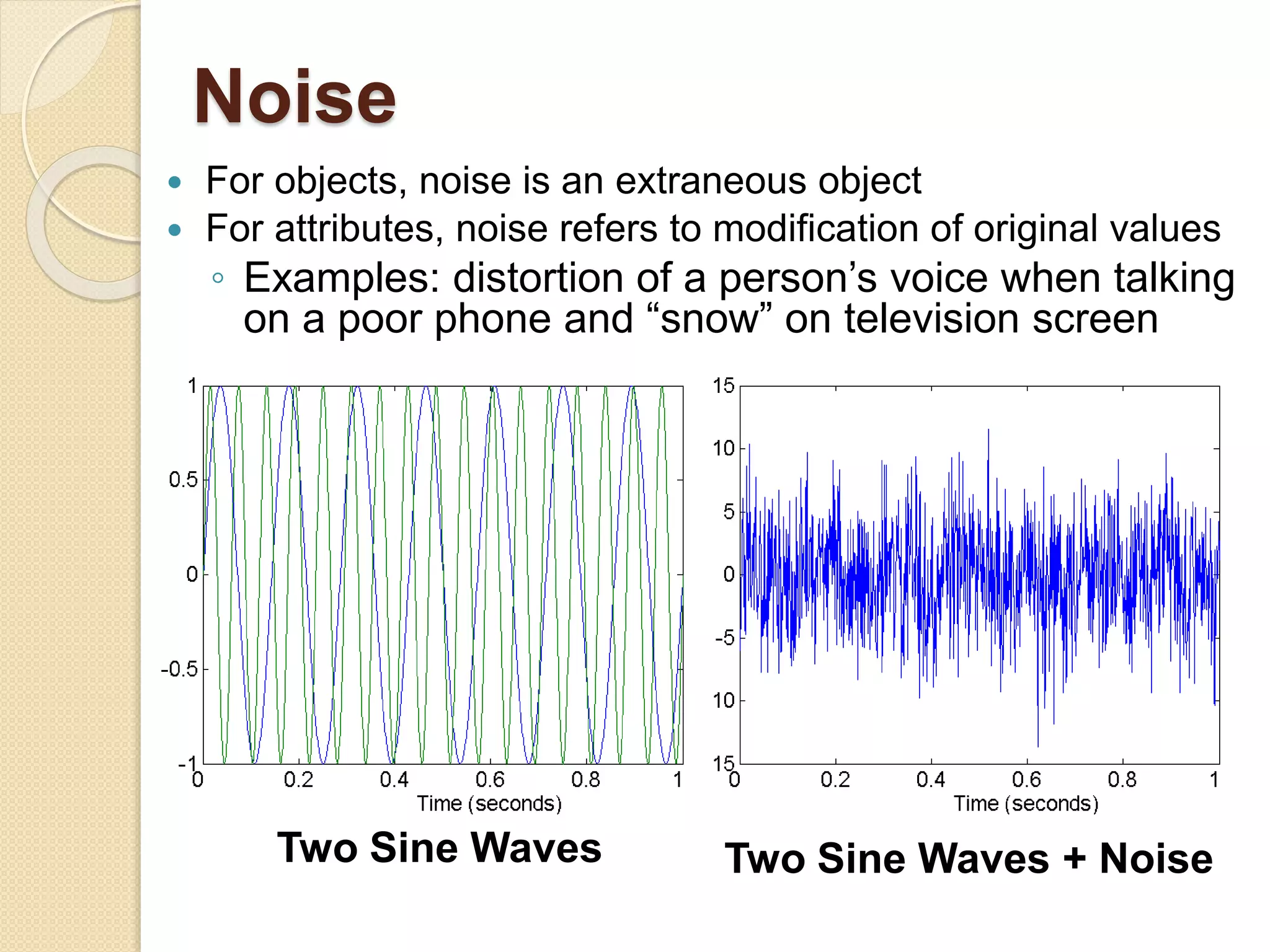
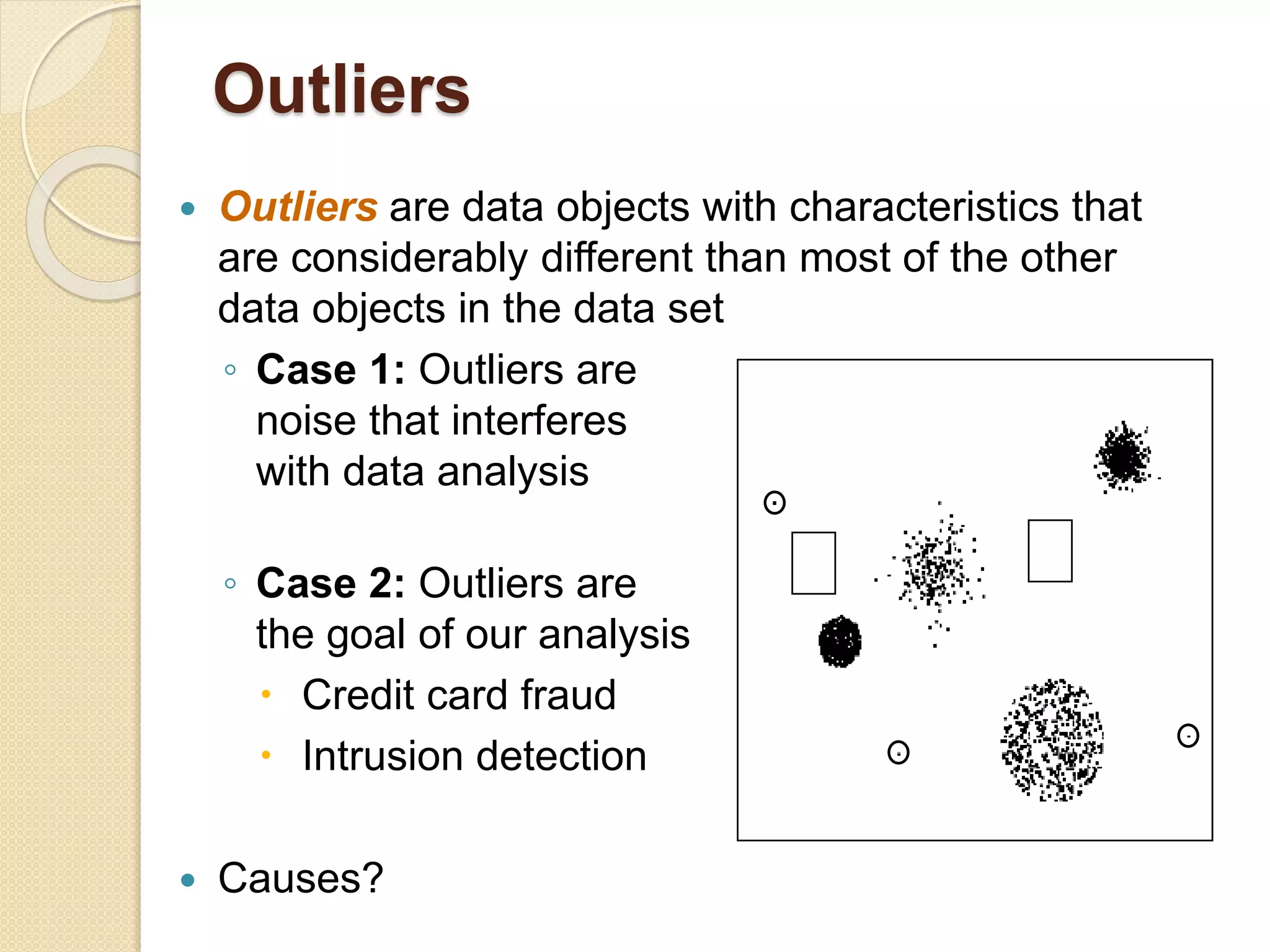
This document provides an overview of getting to know data through data mining and data warehousing. It defines key concepts like data objects, attributes, attribute types, data sets, and data quality issues. Data objects are described by a set of attributes, which can be qualitative like nominal or ordinal, or quantitative like interval or ratio scaled. Different types of data sets are discussed including data matrices, documents, transactions, graphs, and ordered data. Common data quality problems addressed are noise, outliers, missing values, and duplicate data. Methods for measuring similarity and dissimilarity between data objects are also introduced.
























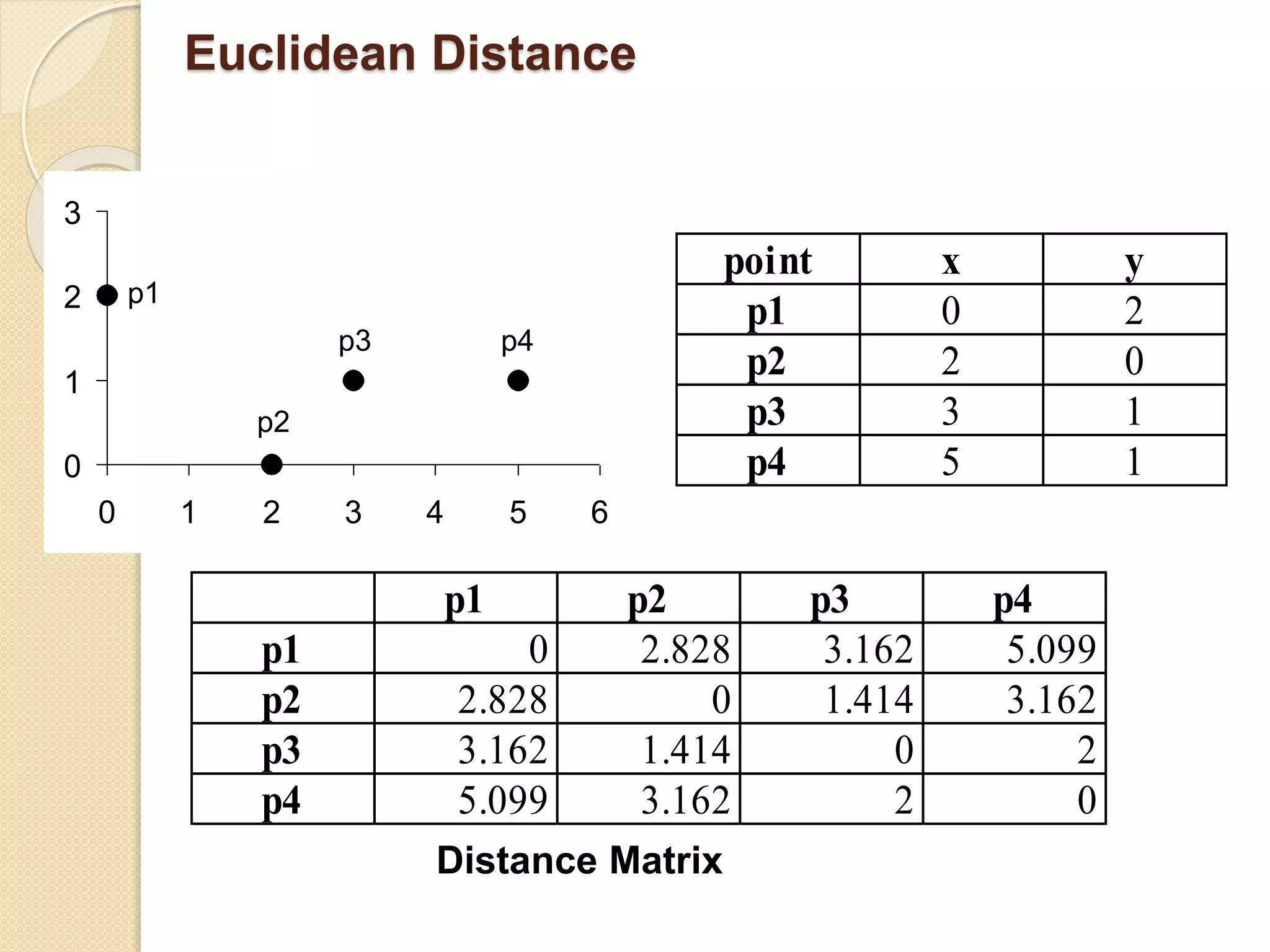
![Similarity and Dissimilarity Measures
Similarity measure
◦ Numerical measure of how alike two data objects
are.
◦ Is higher when objects are more alike.
◦ Often falls in the range [0,1]
Dissimilarity measure
◦ Numerical measure of how different two data
objects are
◦ Lower when objects are more alike
◦ Minimum dissimilarity is often 0
◦ Upper limit varies
Proximity refers to a similarity or dissimilarity](https://image.slidesharecdn.com/lect-2gettingtoknowyourdata-190228021629/75/Lect-2-getting-to-know-your-data-32-2048.jpg)




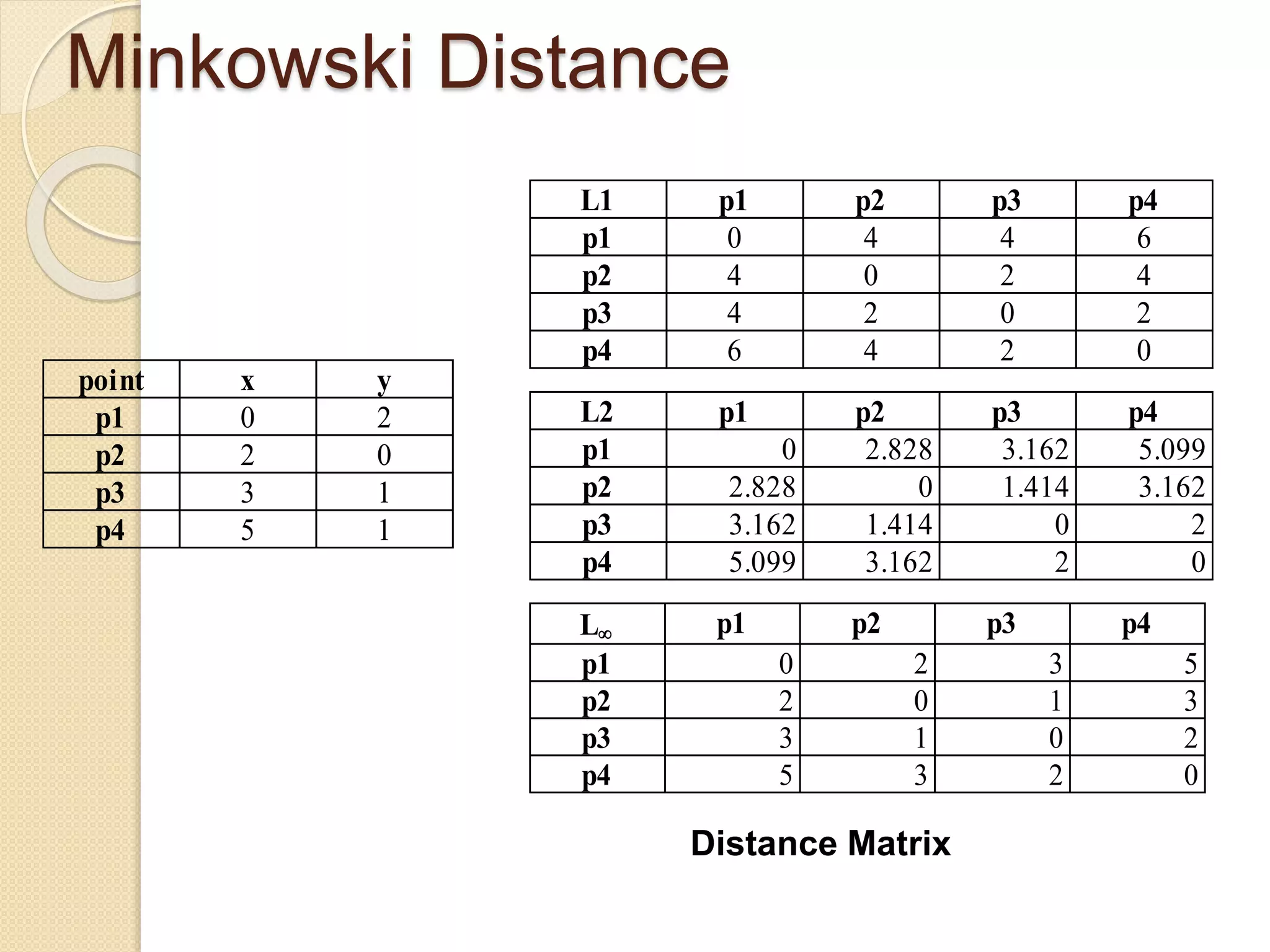
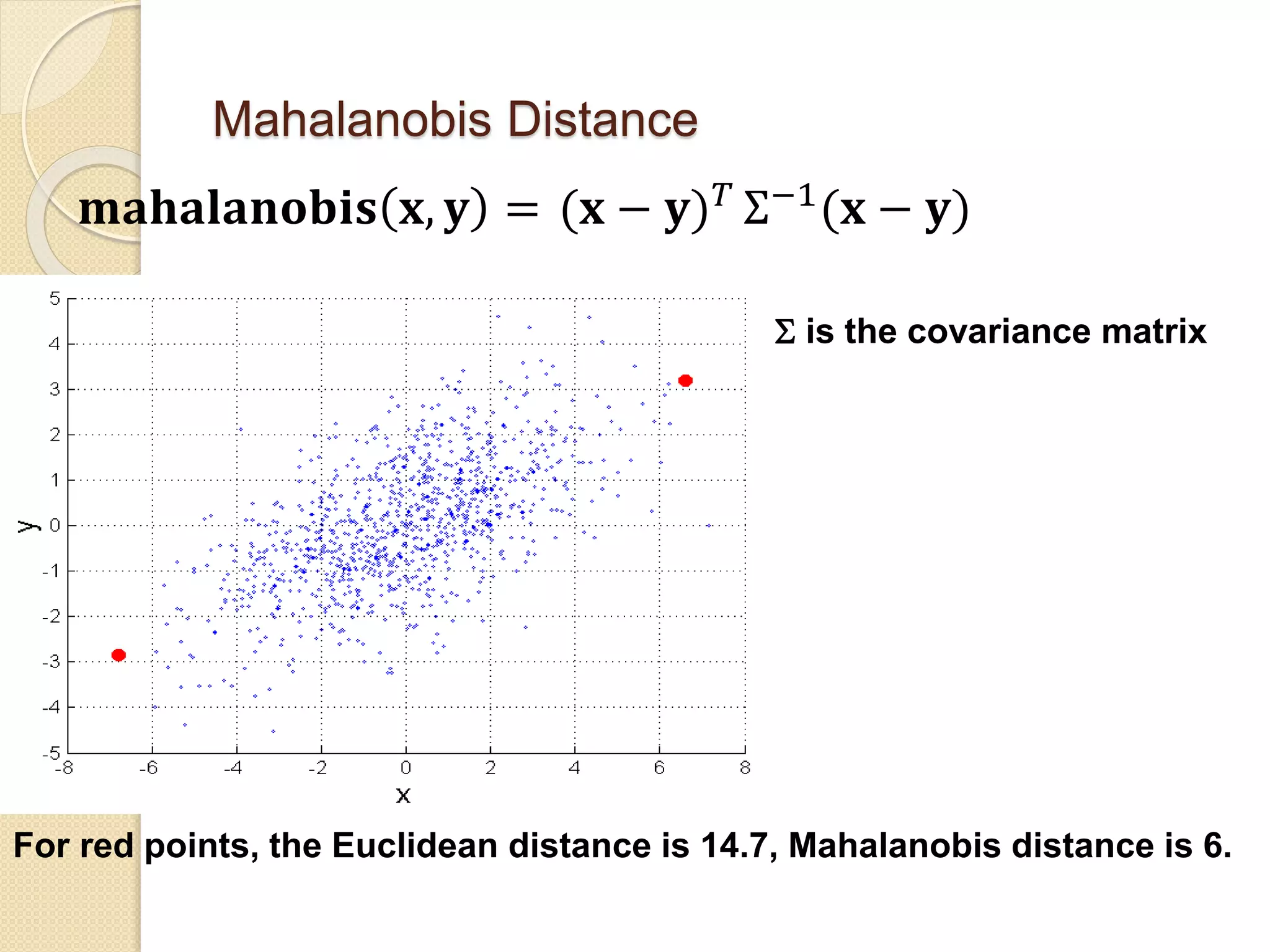
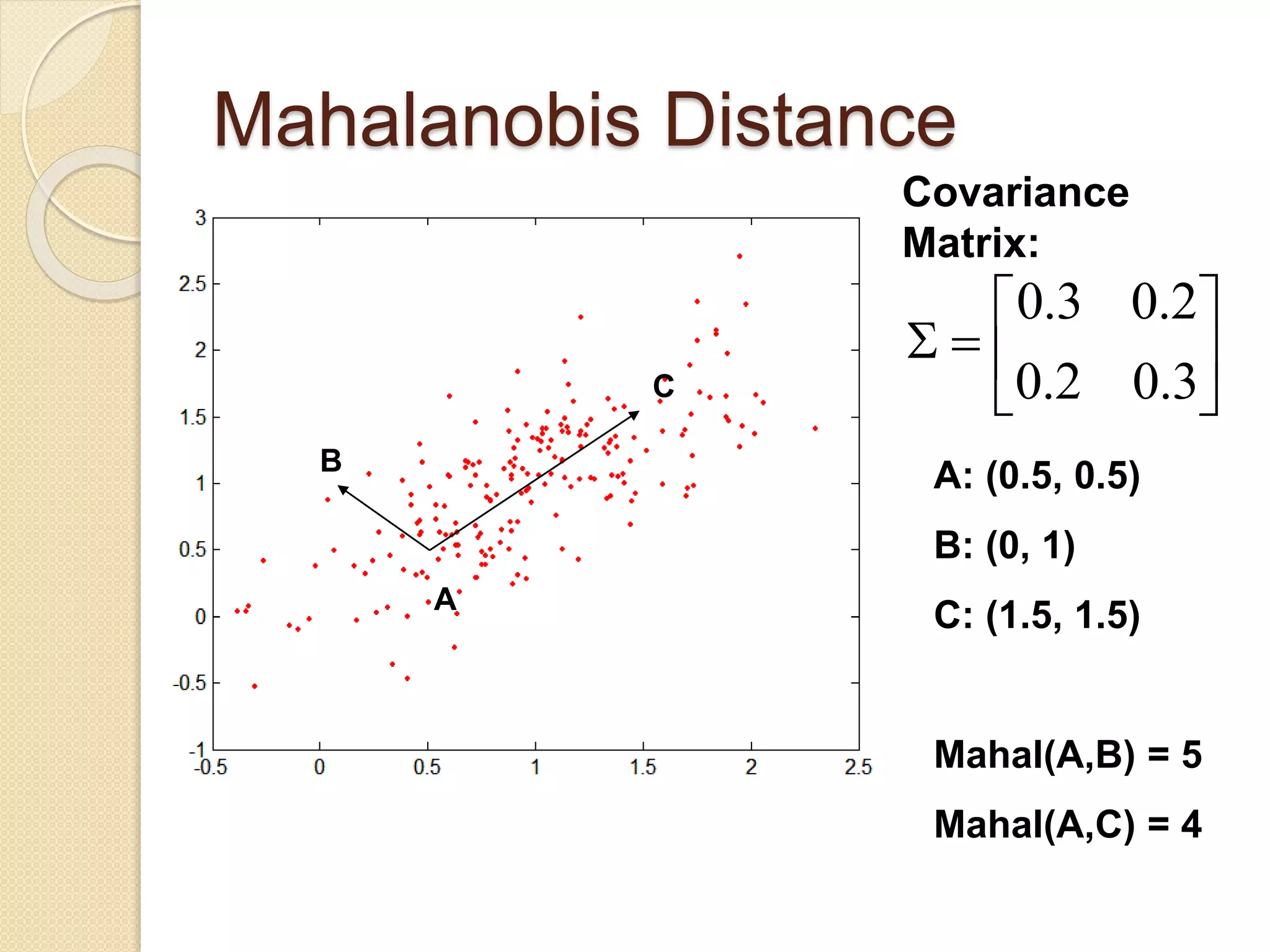








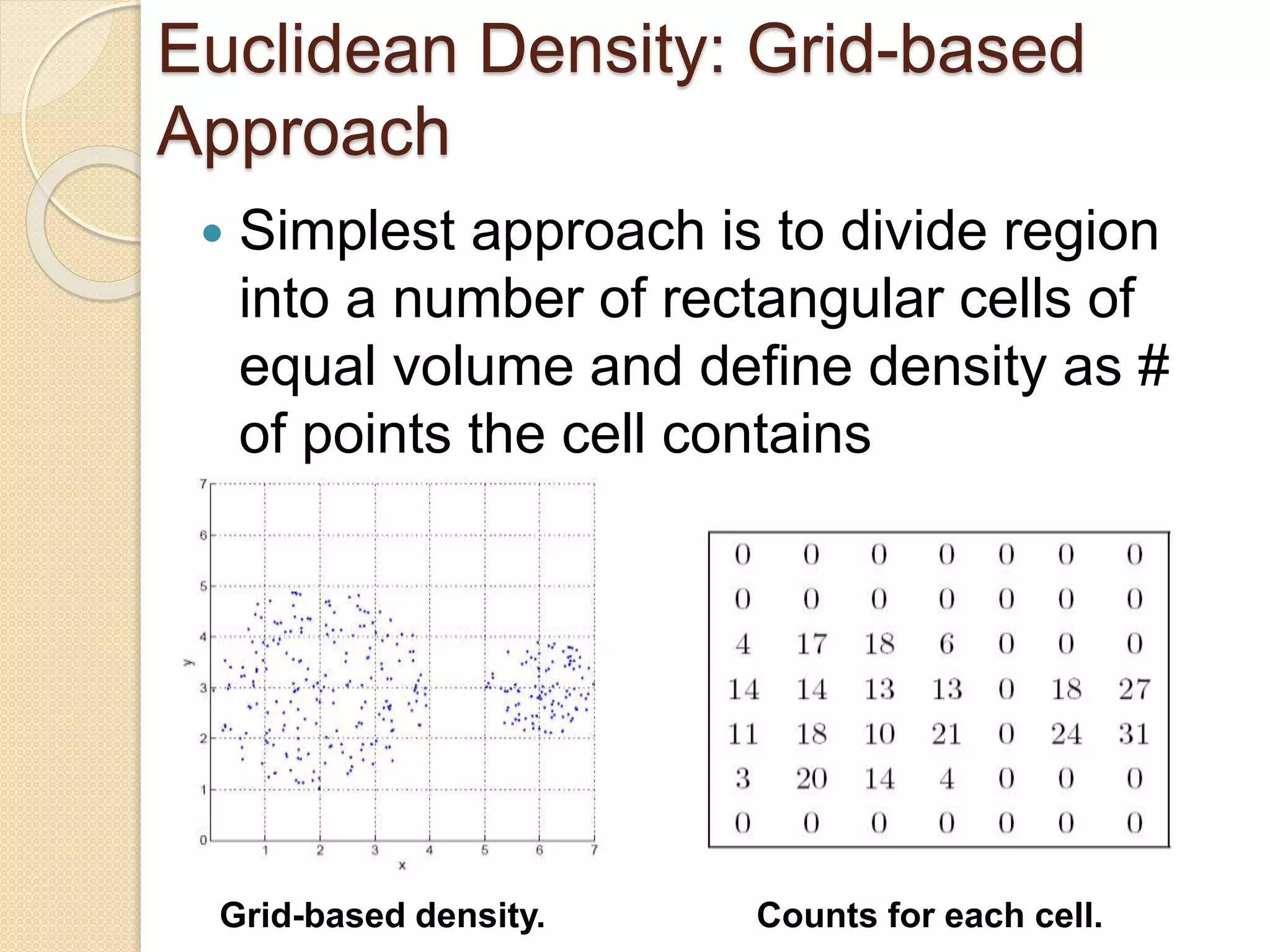
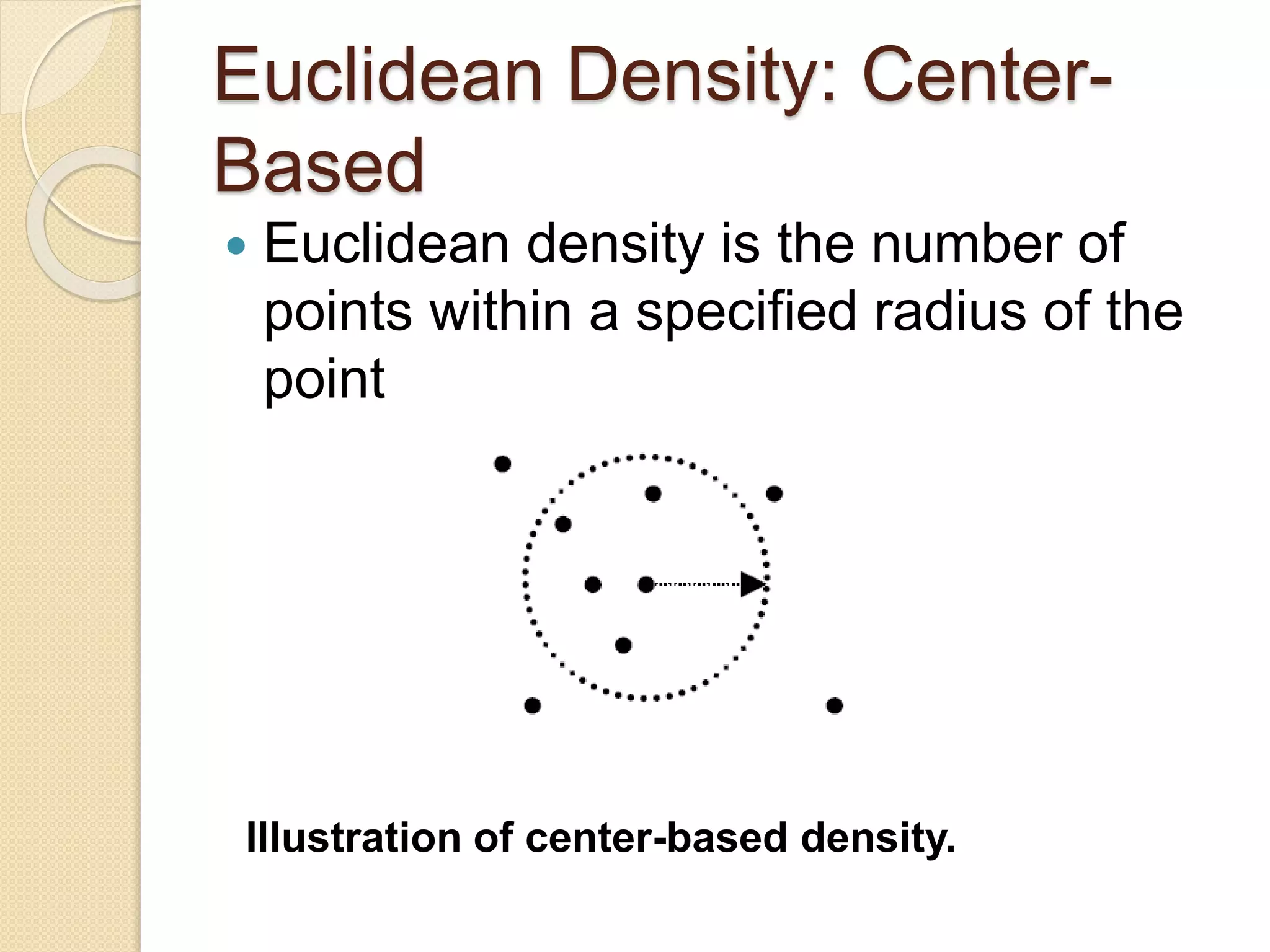



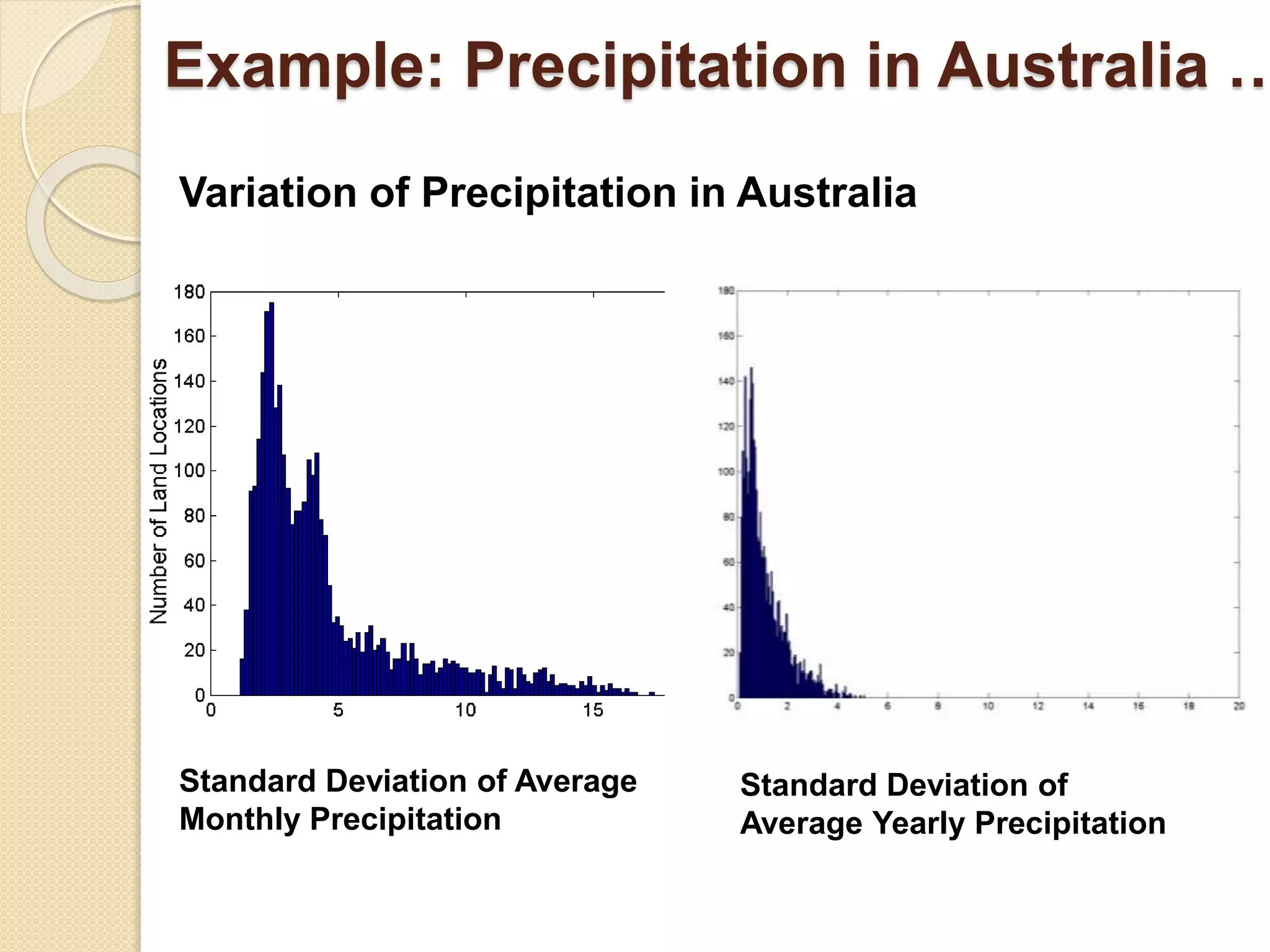




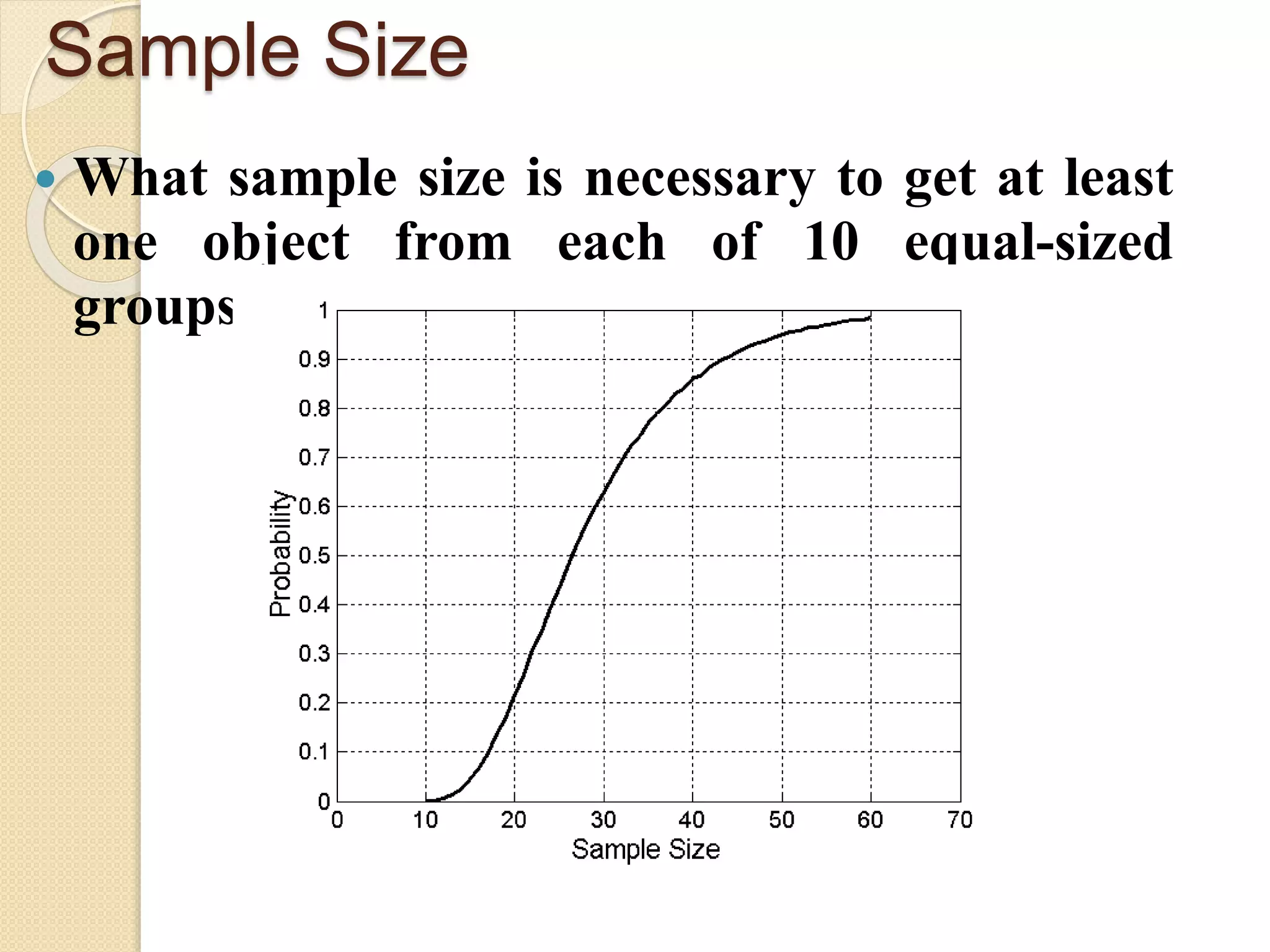
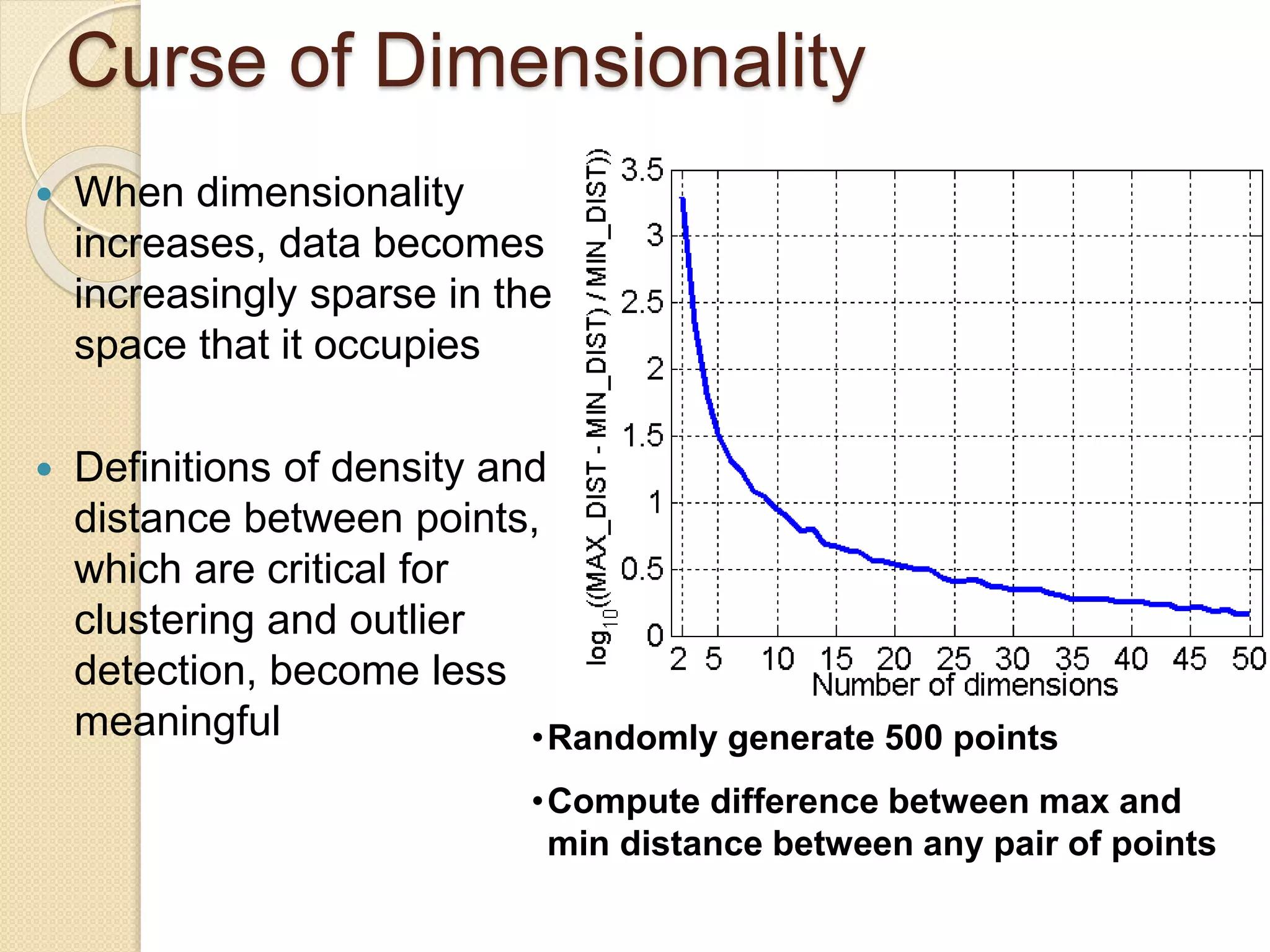







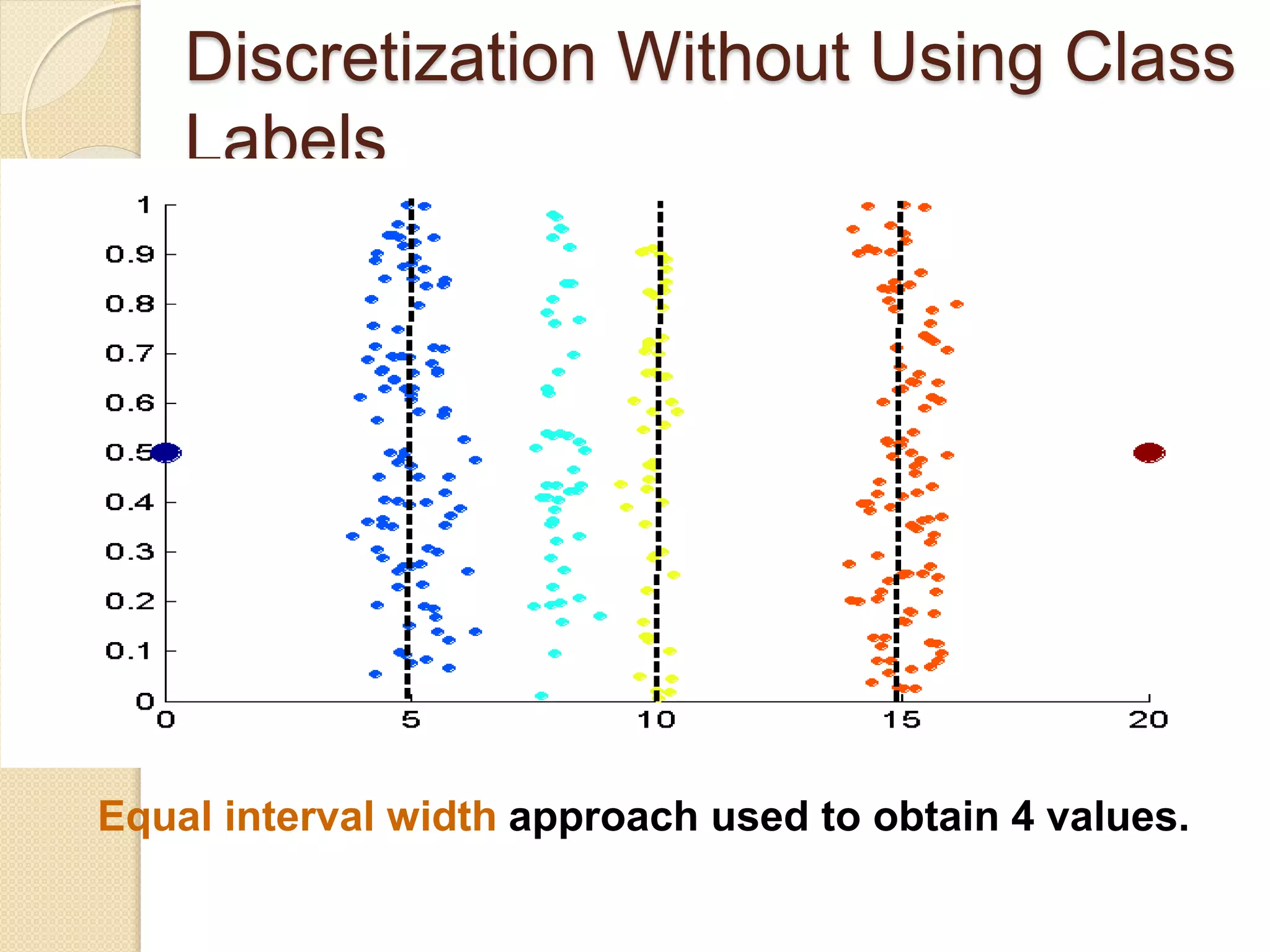
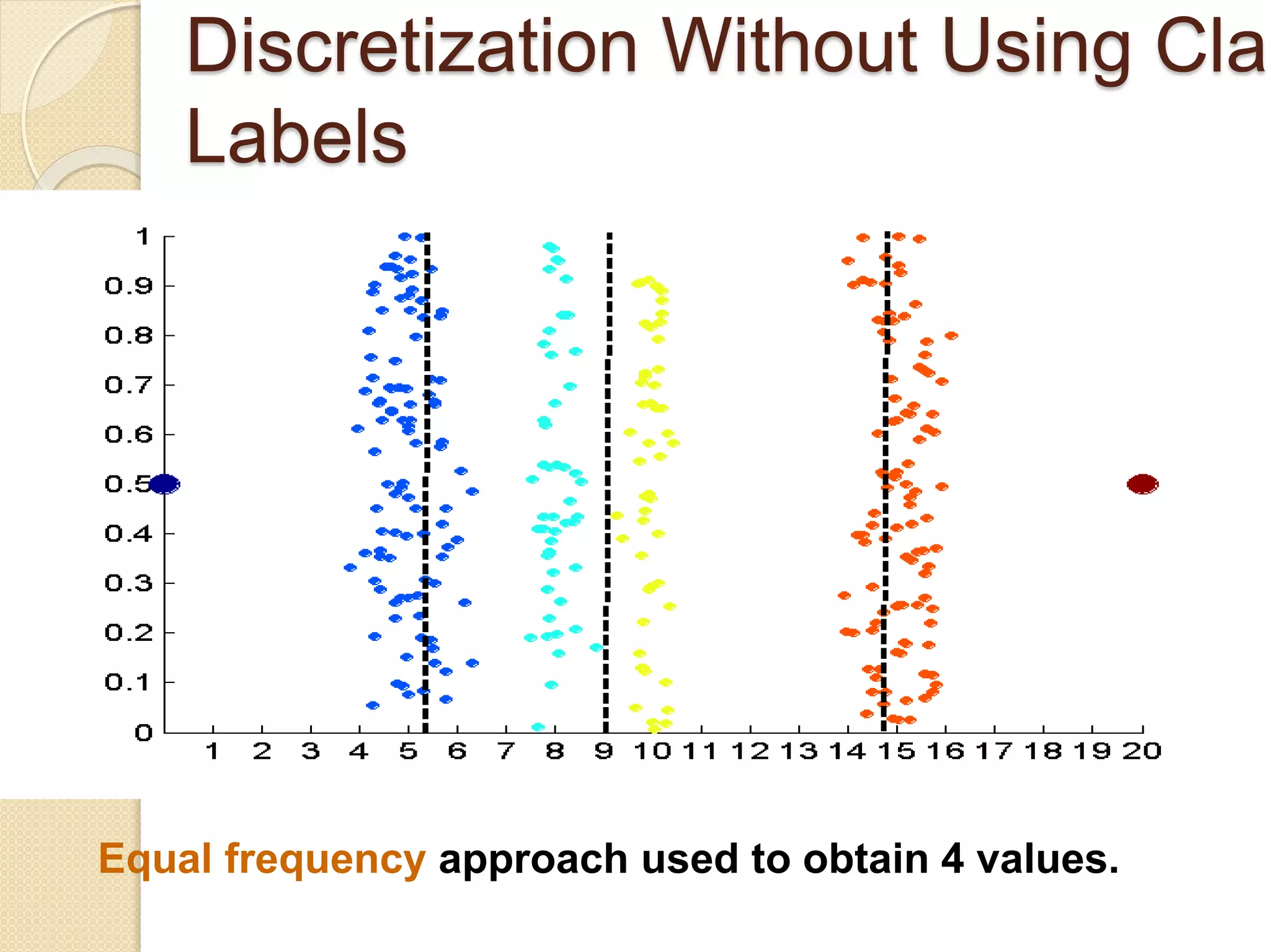
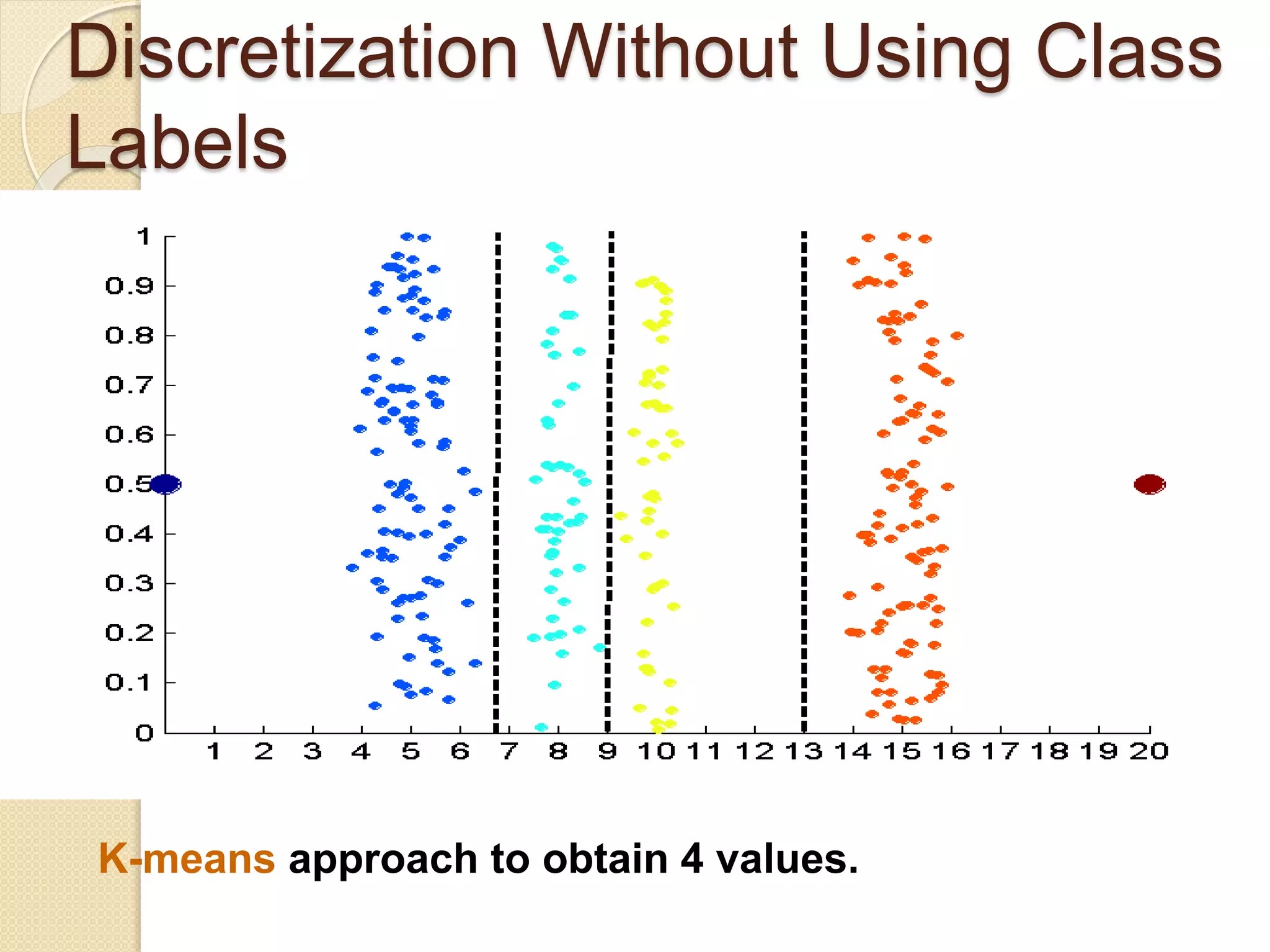


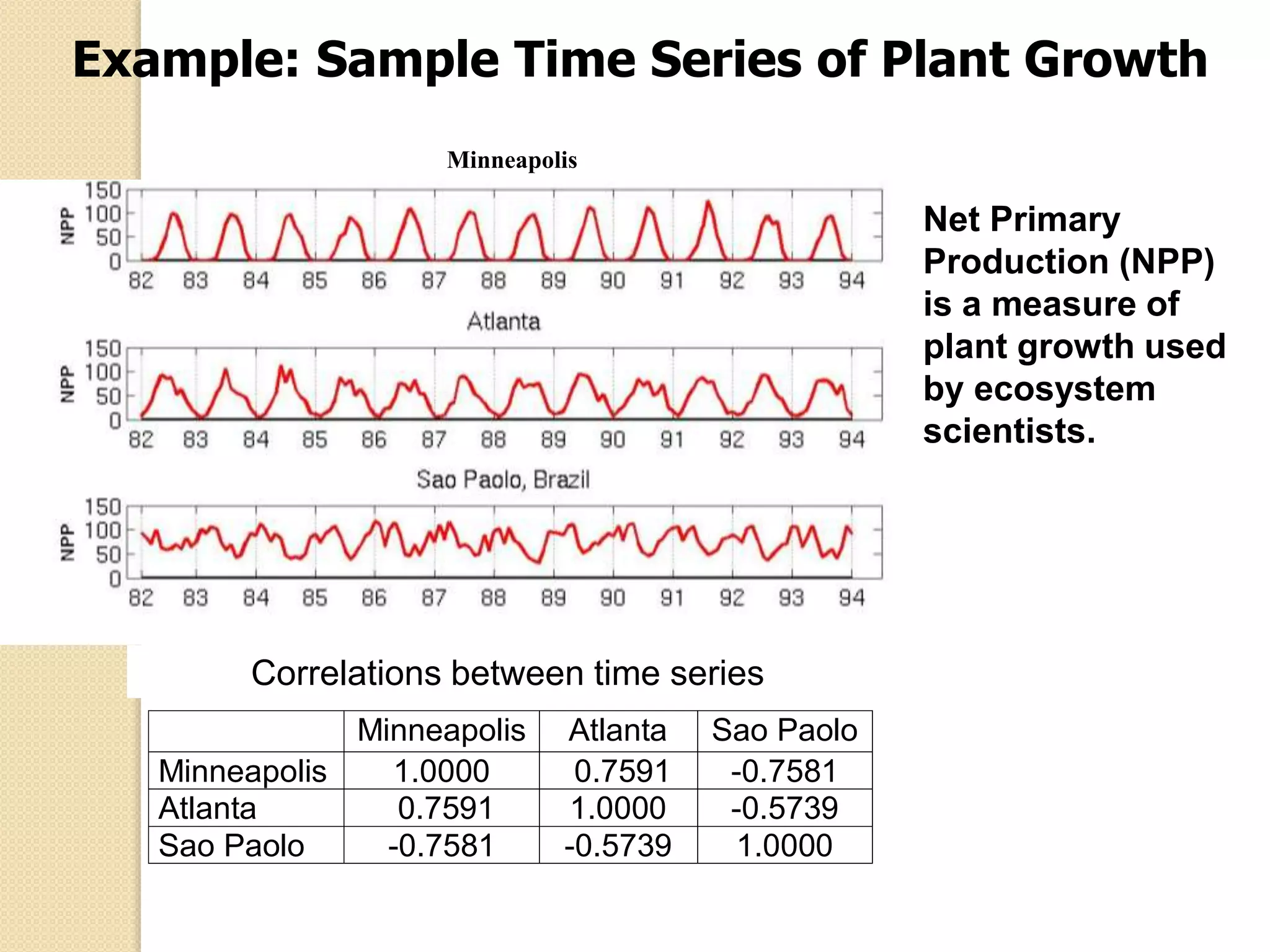









































![Wk. 3. Data [12-05-2021] (2).ppt](https://cdn.slidesharecdn.com/ss_thumbnails/wk-240205070901-8f81e253-thumbnail.jpg?width=640&height=640&fit=bounds)










































