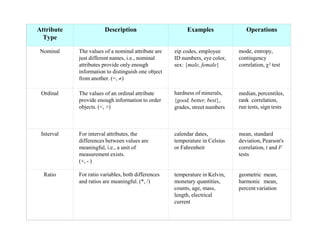
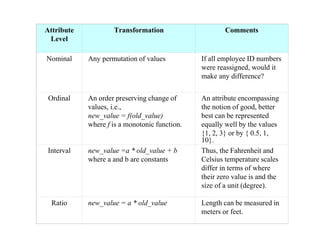
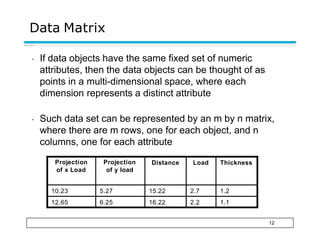
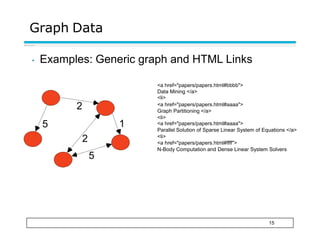
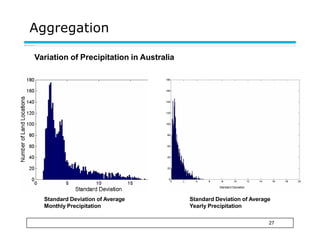
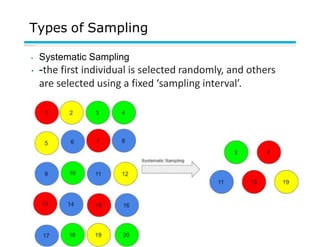
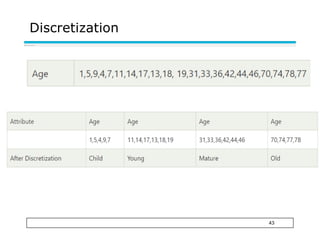
This document provides an overview of key concepts related to data and data preprocessing. It defines data as a collection of objects and their attributes. Attributes can be nominal, ordinal, interval, or ratio. Data can take the form of records, graphs, ordered sequences, or other types. The document discusses attribute values, data quality issues like noise, outliers, and missing values. It also covers common preprocessing techniques like aggregation, sampling, dimensionality reduction, feature selection and creation, and discretization. Finally, it introduces concepts of similarity and dissimilarity measures between data objects.










































![Similarity and Dissimilarity
45
• Similarity
– Numerical measure of how alike two data objects are.
– Is higher when objects are more alike.
– Often falls in the range [0,1]
• Dissimilarity
– Numerical measure of how different are two data
objects
– Lower when objects are more alike
– Minimum dissimilarity is often 0
– Upper limit varies
• Proximity refers to a similarity or dissimilarity](https://image.slidesharecdn.com/datatypesandattributes11-230705035749-72a94dc3/85/Data-types-and-Attributes1-1-pptx-50-320.jpg)





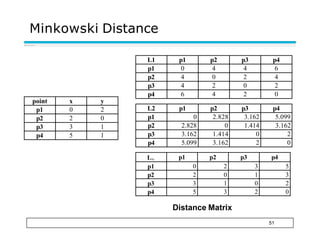

![Mahalanobis Distance
Covariance Matrix:
「
0.3 0.2
53
|0.2 0.3|
]
A: (0.5, 0.5)
B: (0, 1)
C: (1.5, 1.5)
B
A
C
Mahal(A,B) = 5
Mahal(A,C) = 4](https://image.slidesharecdn.com/datatypesandattributes11-230705035749-72a94dc3/85/Data-types-and-Attributes1-1-pptx-58-320.jpg)











































![Wk. 3. Data [12-05-2021] (2).ppt](https://cdn.slidesharecdn.com/ss_thumbnails/wk-240205070901-8f81e253-thumbnail.jpg?width=640&height=640&fit=bounds)





















































