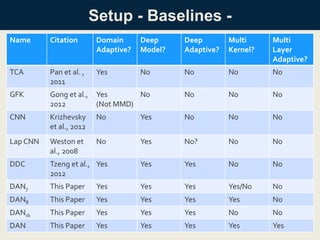
Setup - Baselines-
Name Citation Domain
Adaptive?
Deep
Model?
Deep
Adaptive?
Multi
Kernel?
Multi
Layer
Adaptive?
TCA Pan et al. ,
2011
Yes No No No No
GFK Gong et al.,
2012
Yes
(Not MMD)
No No No No
CNN Krizhevsky
et al., 2012
No Yes No No No
Lap CNN Weston et
al., 2008
No Yes No? No No
DDC Tzeng et al.,
2012
Yes Yes Yes No No
DAN7 This Paper Yes Yes Yes Yes/No No
DAN8 This Paper Yes Yes Yes Yes No
DANsk This Paper Yes Yes Yes No No
DAN This Paper Yes Yes Yes Yes Yes




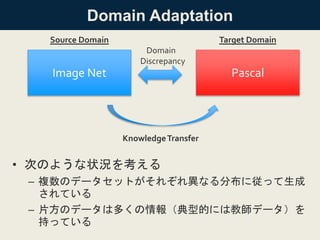
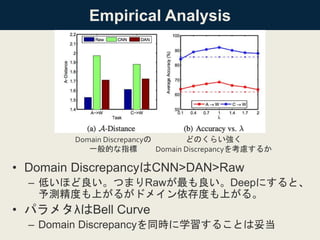
![But How?
• 1つの方法は、複数のドメインで共通の特徴空間を学習する
こと
• ↑は、Domain Disperencyを何らかの方法で
定義して、それを一緒に最適化することで達成される
– いろんな研究がある(知りたい方は論文Intro2パラ
orRelated Workあたりに書いてあります
• Survey: [Pan et al. 2011]
– 最近はDeepにするのが流行(良い精度
• DeCAFなど
– ただし、単にDeepにするだけだといくつか問題
• 深い層に行くほどtransferabilityが下がる[Yosinski, 2014]
• 理論的な下界が決まっていない[Ben-David, 2010]
• 複数の層を転移する方法がない](https://image.slidesharecdn.com/dlhacks-20151105-iwasawa-160204020204/85/DL-Hacks-Learning-Transferable-Features-with-Deep-Adaptation-Networks-5-320.jpg)
![How transferable are features in DNN?
[Yosinski, NIPS2014]
• 層が深いほど転移に
失敗する](https://image.slidesharecdn.com/dlhacks-20151105-iwasawa-160204020204/85/DL-Hacks-Learning-Transferable-Features-with-Deep-Adaptation-Networks-6-320.jpg)
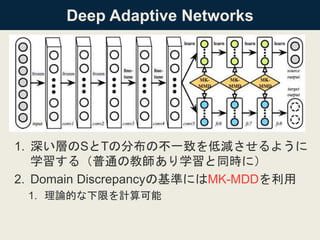





![CNNのパラメタθの学習
• MK-MMDそのままだと平均をとるのに複数のデー
タ点の和を取らなきゃいけない
– 計算がO(N^2)かかる、SGDがあんまり使いやすくない
• [Gretton,2012b]で提案されている方法に従ってMK-
MMDを推定
– これでO(N)になり、普通のSGDでできる
• 多分ここが[Gretton,2012b]
• おそらく2つのデータ点をまとめて1つの
データ点と見て学習する感じ](https://image.slidesharecdn.com/dlhacks-20151105-iwasawa-160204020204/85/DL-Hacks-Learning-Transferable-Features-with-Deep-Adaptation-Networks-13-320.jpg)
![Learning β
• [Gretton,2012b]に従って最適化
• Type2の誤差を最小化するように学習
• QPで解ける
– ここが一番わからない
– 詳細は[Gretton,2012b]を読んでください
Reminder: Multi Kernel
こいつ](https://image.slidesharecdn.com/dlhacks-20151105-iwasawa-160204020204/85/DL-Hacks-Learning-Transferable-Features-with-Deep-Adaptation-Networks-14-320.jpg)


![Setup - Others -
• Unsupervised Manner [Gong et al., 2013] & Semi
Supervised Manner [Saenko et al., 2010]
– よくわからないので時間あったら調べる
• MMDをベースにした方法について
– Gaussian Kernelを利用
– パラメタγはmedian heuristic(わからないので以下同
– Multi Kernelの場合には複数のGaussian Kernel
– パラメタは2-8γから28γ
• パラメタλはFine Tuningで決定可能
– MMDの最小化=two-sample classifierでの誤差最大化だから
• [Yosinski et al., 2014]でのFine Tuning Architectureを利
用(ImageNetベース)
– ただし、Conv1-Conv3は固定、Conv4-Conv5, Fc6-Fc8をFine
Tune(with Source Domain)](https://image.slidesharecdn.com/dlhacks-20151105-iwasawa-160204020204/85/DL-Hacks-Learning-Transferable-Features-with-Deep-Adaptation-Networks-18-320.jpg)
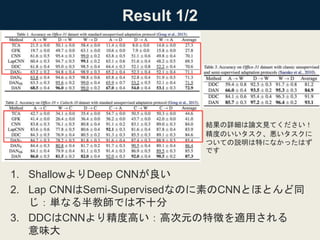
![Result 2/2
1. DAN7とDAN8がどちらもDDCをOutperform
1. Multi-Kernelの有効性が現れている(理由は[Gretton et al. 2012b])
2. DANskがDDCより良い
1. 複数の層を適用させると良さそう
3. DANはさらに精度向上
結果の詳細は論文見てください!
精度のいいタスク、悪いタスクに
ついての説明は特になかったはず
です](https://image.slidesharecdn.com/dlhacks-20151105-iwasawa-160204020204/85/DL-Hacks-Learning-Transferable-Features-with-Deep-Adaptation-Networks-20-320.jpg)




![[DL輪読会]When Does Label Smoothing Help?](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20191227dl-191227001522-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=640&height=640&fit=bounds)


![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)







![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...](https://cdn.slidesharecdn.com/ss_thumbnails/dl20220318dlfin-220322065433-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会] Hybrid computing using a neural network with dynamic external memory](https://cdn.slidesharecdn.com/ss_thumbnails/dliwasawadnc-161220014044-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会] GAN系の研究まとめ (NIPS2016とICLR2016が中心)](https://cdn.slidesharecdn.com/ss_thumbnails/dliwasawagansurvey-161220014753-thumbnail.jpg?width=640&height=640&fit=bounds)




![[ICLR2016] 採録論文の個人的まとめ](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2016-acceptedpapers-160209033749-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Dl輪読会]Censoring Representation with Adversary](https://cdn.slidesharecdn.com/ss_thumbnails/dlcensoringrepresentationwithadversary-160907082053-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Learning What and Where to Draw (NIPS’16)](https://cdn.slidesharecdn.com/ss_thumbnails/20170120misono-170215035536-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会] “Asymmetric Tri-training for Unsupervised Domain Adaptation (ICML2017...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170728-170728025901-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Unsupervised Cross-Domain Image Generation](https://cdn.slidesharecdn.com/ss_thumbnails/readingpaper20170310-170310051823-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20191220readingpaperconvcnp-191220034420-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Deep Face Recognition: A Survey](https://cdn.slidesharecdn.com/ss_thumbnails/20181221-181221023935-thumbnail.jpg?width=640&height=640&fit=bounds)









![ICLR'19 読み会 in 京都 [LT枠] Domain Adaptationの研究動向](https://cdn.slidesharecdn.com/ss_thumbnails/iclr19inkyotolt-190528091335-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会] Controllable Invariance through Adversarial Feature Learning” (NIPS2017)](https://cdn.slidesharecdn.com/ss_thumbnails/20171121iwasawa-171120061515-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会] Semi-Supervised Knowledge Transfer For Deep Learning From Private Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170414iwasawa-170414094134-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper Reading] Learning Distributed Representations for Structured Output Pr...](https://cdn.slidesharecdn.com/ss_thumbnails/iwasawa-paperreading-20151014-160204014222-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL Hacks輪読] Semi-Supervised Learning with Ladder Networks (NIPS2015)](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks-paper-reading-160107093848-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL Hacks] Self Paced Learning with Diversity](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks0813-150820004116-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)


