Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Yusuke Iwasawa
PPTX, PDF
2,635 views
Dl hacks輪読: "Unifying distillation and privileged information"
輪読, Vapnik, 蒸留, ICLR2016, privileged information, 特権情報, DL Hacks, 機械学習,
Technology
◦
Read more
3
Save
Share
Embed
Embed presentation
Download
Downloaded 32 times
1
/ 26
2
/ 26
3
/ 26
4
/ 26
5
/ 26
6
/ 26
7
/ 26
8
/ 26
9
/ 26
10
/ 26
11
/ 26
12
/ 26
13
/ 26
14
/ 26
15
/ 26
16
/ 26
17
/ 26
18
/ 26
19
/ 26
20
/ 26
21
/ 26
22
/ 26
23
/ 26
24
/ 26
25
/ 26
26
/ 26
More Related Content
PPTX
【DL輪読会】Responsive Safety in Reinforcement Learning by PID Lagrangian Methods...
by
Deep Learning JP
PDF
深層学習(岡本孝之 著) - Deep Learning chap.1 and 2
by
Masayoshi Kondo
PDF
[DLHacks LT] PytorchのDataLoader -torchtextのソースコードを読んでみた-
by
Deep Learning JP
PDF
[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an...
by
Deep Learning JP
PDF
[DL輪読会]Attention Is All You Need
by
Deep Learning JP
PDF
[DL輪読会]深層強化学習はなぜ難しいのか?Why Deep RL fails? A brief survey of recent works.
by
Deep Learning JP
PPTX
【DL輪読会】SimCSE: Simple Contrastive Learning of Sentence Embeddings (EMNLP 2021)
by
Deep Learning JP
PDF
MixMatch: A Holistic Approach to Semi- Supervised Learning
by
harmonylab
【DL輪読会】Responsive Safety in Reinforcement Learning by PID Lagrangian Methods...
by
Deep Learning JP
深層学習(岡本孝之 著) - Deep Learning chap.1 and 2
by
Masayoshi Kondo
[DLHacks LT] PytorchのDataLoader -torchtextのソースコードを読んでみた-
by
Deep Learning JP
[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an...
by
Deep Learning JP
[DL輪読会]Attention Is All You Need
by
Deep Learning JP
[DL輪読会]深層強化学習はなぜ難しいのか?Why Deep RL fails? A brief survey of recent works.
by
Deep Learning JP
【DL輪読会】SimCSE: Simple Contrastive Learning of Sentence Embeddings (EMNLP 2021)
by
Deep Learning JP
MixMatch: A Holistic Approach to Semi- Supervised Learning
by
harmonylab
What's hot
PDF
最適輸送の計算アルゴリズムの研究動向
by
ohken
PPTX
モデル高速化百選
by
Yusuke Uchida
PDF
Statistical Semantic入門 ~分布仮説からword2vecまで~
by
Yuya Unno
PDF
High-impact Papers in Computer Vision: 歴史を変えた/トレンドを創る論文
by
cvpaper. challenge
PDF
(DL Hacks輪読) How transferable are features in deep neural networks?
by
Masahiro Suzuki
PDF
[DLHacks 実装]Network Dissection: Quantifying Interpretability of Deep Visual R...
by
Deep Learning JP
PPTX
[DL輪読会]EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
by
Deep Learning JP
ODP
卒業論文発表スライド 分割統治法の拡張
by
masakazuyamanaka
PPTX
大域的探索から局所的探索へデータ拡張 (Data Augmentation)を用いた学習の探索テクニック
by
西岡 賢一郎
PDF
DeepLearning 14章 自己符号化器
by
hirono kawashima
PPTX
論文の書き方入門 2017
by
Hironori Washizaki
PDF
[MIRU2018] Global Average Poolingの特性を用いたAttention Branch Network
by
Hiroshi Fukui
PDF
DQNからRainbowまで 〜深層強化学習の最新動向〜
by
Jun Okumura
PPTX
データサイエンス概論第一 5 時系列データの解析
by
Seiichi Uchida
PDF
[DL輪読会]Temporal Abstraction in NeurIPS2019
by
Deep Learning JP
PDF
Contrastive learning 20200607
by
ぱんいち すみもと
PDF
最適輸送の解き方
by
joisino
PPTX
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
PDF
ELBO型VAEのダメなところ
by
KCS Keio Computer Society
PPTX
【論文紹介】Distributed Representations of Sentences and Documents
by
Tomofumi Yoshida
最適輸送の計算アルゴリズムの研究動向
by
ohken
モデル高速化百選
by
Yusuke Uchida
Statistical Semantic入門 ~分布仮説からword2vecまで~
by
Yuya Unno
High-impact Papers in Computer Vision: 歴史を変えた/トレンドを創る論文
by
cvpaper. challenge
(DL Hacks輪読) How transferable are features in deep neural networks?
by
Masahiro Suzuki
[DLHacks 実装]Network Dissection: Quantifying Interpretability of Deep Visual R...
by
Deep Learning JP
[DL輪読会]EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
by
Deep Learning JP
卒業論文発表スライド 分割統治法の拡張
by
masakazuyamanaka
大域的探索から局所的探索へデータ拡張 (Data Augmentation)を用いた学習の探索テクニック
by
西岡 賢一郎
DeepLearning 14章 自己符号化器
by
hirono kawashima
論文の書き方入門 2017
by
Hironori Washizaki
[MIRU2018] Global Average Poolingの特性を用いたAttention Branch Network
by
Hiroshi Fukui
DQNからRainbowまで 〜深層強化学習の最新動向〜
by
Jun Okumura
データサイエンス概論第一 5 時系列データの解析
by
Seiichi Uchida
[DL輪読会]Temporal Abstraction in NeurIPS2019
by
Deep Learning JP
Contrastive learning 20200607
by
ぱんいち すみもと
最適輸送の解き方
by
joisino
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
ELBO型VAEのダメなところ
by
KCS Keio Computer Society
【論文紹介】Distributed Representations of Sentences and Documents
by
Tomofumi Yoshida
Viewers also liked
PDF
研究室輪読 Recommending Investors for Crowdfunding Projects
by
Yusuke Iwasawa
PDF
研究室輪読 Feature Learning for Activity Recognition in Ubiquitous Computing
by
Yusuke Iwasawa
PDF
008 20151221 Return of Frustrating Easy Domain Adaptation
by
Ha Phuong
PPTX
[DL Hacks輪読] Semi-Supervised Learning with Ladder Networks (NIPS2015)
by
Yusuke Iwasawa
PDF
[DL輪読会] Semi-Supervised Knowledge Transfer For Deep Learning From Private Tra...
by
Yusuke Iwasawa
PPTX
[ICLR2016] 採録論文の個人的まとめ
by
Yusuke Iwasawa
PPTX
JSAI2017:敵対的訓練を利用したドメイン不変な表現の学習
by
Yusuke Iwasawa
PPTX
[DL輪読会] GAN系の研究まとめ (NIPS2016とICLR2016が中心)
by
Yusuke Iwasawa
PDF
エキスパートGo
by
Takuya Ueda
PDF
先端技術とメディア表現1 #FTMA15
by
Yoichi Ochiai
研究室輪読 Recommending Investors for Crowdfunding Projects
by
Yusuke Iwasawa
研究室輪読 Feature Learning for Activity Recognition in Ubiquitous Computing
by
Yusuke Iwasawa
008 20151221 Return of Frustrating Easy Domain Adaptation
by
Ha Phuong
[DL Hacks輪読] Semi-Supervised Learning with Ladder Networks (NIPS2015)
by
Yusuke Iwasawa
[DL輪読会] Semi-Supervised Knowledge Transfer For Deep Learning From Private Tra...
by
Yusuke Iwasawa
[ICLR2016] 採録論文の個人的まとめ
by
Yusuke Iwasawa
JSAI2017:敵対的訓練を利用したドメイン不変な表現の学習
by
Yusuke Iwasawa
[DL輪読会] GAN系の研究まとめ (NIPS2016とICLR2016が中心)
by
Yusuke Iwasawa
エキスパートGo
by
Takuya Ueda
先端技術とメディア表現1 #FTMA15
by
Yoichi Ochiai
More from Yusuke Iwasawa
PPTX
JSAI2018 類似度学習を用いた敵対的訓練による 特徴表現の検閲
by
Yusuke Iwasawa
PPTX
"Universal Planning Networks" and "Composable Planning with Attributes"
by
Yusuke Iwasawa
PPTX
ICLR2018参加報告
by
Yusuke Iwasawa
PPTX
[DL輪読会] Controllable Invariance through Adversarial Feature Learning” (NIPS2017)
by
Yusuke Iwasawa
PPTX
[DL輪読会] “Asymmetric Tri-training for Unsupervised Domain Adaptation (ICML2017...
by
Yusuke Iwasawa
PPTX
[DL輪読会] Hybrid computing using a neural network with dynamic external memory
by
Yusuke Iwasawa
PPTX
Paper Reading, "On Causal and Anticausal Learning", ICML-12
by
Yusuke Iwasawa
PPTX
[DL Hacks] Learning Transferable Features with Deep Adaptation Networks
by
Yusuke Iwasawa
PPTX
[Paper Reading] Learning Distributed Representations for Structured Output Pr...
by
Yusuke Iwasawa
PDF
[DL Hacks] Self Paced Learning with Diversity
by
Yusuke Iwasawa
PDF
DL Hacks輪読 Semi-supervised Learning with Deep Generative Models
by
Yusuke Iwasawa
JSAI2018 類似度学習を用いた敵対的訓練による 特徴表現の検閲
by
Yusuke Iwasawa
"Universal Planning Networks" and "Composable Planning with Attributes"
by
Yusuke Iwasawa
ICLR2018参加報告
by
Yusuke Iwasawa
[DL輪読会] Controllable Invariance through Adversarial Feature Learning” (NIPS2017)
by
Yusuke Iwasawa
[DL輪読会] “Asymmetric Tri-training for Unsupervised Domain Adaptation (ICML2017...
by
Yusuke Iwasawa
[DL輪読会] Hybrid computing using a neural network with dynamic external memory
by
Yusuke Iwasawa
Paper Reading, "On Causal and Anticausal Learning", ICML-12
by
Yusuke Iwasawa
[DL Hacks] Learning Transferable Features with Deep Adaptation Networks
by
Yusuke Iwasawa
[Paper Reading] Learning Distributed Representations for Structured Output Pr...
by
Yusuke Iwasawa
[DL Hacks] Self Paced Learning with Diversity
by
Yusuke Iwasawa
DL Hacks輪読 Semi-supervised Learning with Deep Generative Models
by
Yusuke Iwasawa
Dl hacks輪読: "Unifying distillation and privileged information"
1.
[DL Hacks, Paper
Reading]: Unifying distillation and privileged information 2016.03.18 D2 岩澤
2.
書誌情報など • David Lopez-Paz,
Léon Bottou, Bernhard Schölkopf, Vladimir Vapnik • ICLR 2016 • #Citation: 1 • Machines-Teaching-Machinesのパラダイムの中で 蒸留を説明した論文 • Conclusionの章がない論文 • 注)前提知識が大量に必要 • 特権情報、蒸留、統計的学習理論、Causal Learning • 適宜(私がわかる範囲で)補完しながらしゃべります
3.
Main Theme:Machines-Teaching-Machines • 人間は機械より早く学習することができる •
なぜか? • 1つの答えが、「良い教師」がいるから • “better than a thousand days of diligent study is one day with a great teacher” • 「千日の勤学より一時の名匠」 • RQ: 機械にも「良い教師」がいれば効率的に学習で きるのでは?
4.
本発表の構成 1. 前提知識:LUPIと蒸留 どちらも「教師」の存在をベースにした枠組み/手法 2. 蒸留とLUPIを統合 ->
Generalized Distillation(一般化蒸留)を定義 3. 蒸留がうまくいく理由の1つの理論的な分析 1. なぜ生徒モデルが効率よく学習できるのか 4. 一般化蒸留とその他の領域の関係 1. 一般化蒸留が様々な問題を包括する手法であることを示す 5. 様々な実験化で一般化蒸留がうまくいくかを検証
5.
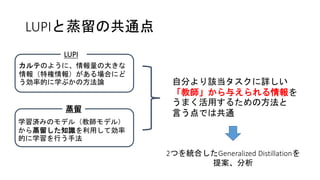
Background: Learning Using Privileged
Information (LUPI) Classical Setting Cancers Healthy • CT画像Xからある患者が ガンかどうか予想する • 期待損失を最小化する • 教師という概念がない LUPI [Vapnik 2009] Cancers Healthy • CT画像の他にカルテ情報 (特権情報)を教える • 期待損失最小化の点では同じ • X*を教師が与えると考える Xi Xi X* i yi yi ※f: 学習する関数、y:理想的な出力
6.
Background: Distillation (Dark
Knowledge) [Hinton, 2015] 教師モデル (Teacher Model) • より柔軟 • 典型的にはパラメタが多い • 普通に1-Hotのラベル (ハードターゲット)で学習 生徒モデル (Student Model) y • よりシンプル • 典型的にはパラメタが少ない • ハードターゲットと、教師モデルから得られ るソフトターゲットとの誤差関数を最適化 • 教師を真似ることで効率よく学習 y Lh Lh 蒸留 Ls
7.
LUPIと蒸留の共通点 LUPI カルテのように、情報量の大きな 情報(特権情報)がある場合にど う効率的に学ぶかの方法論 蒸留 学習済みのモデル(教師モデル) から蒸留した知識を利用して効率 的に学習を行う手法 自分より該当タスクに詳しい 「教師」から与えられる情報を うまく活用するための方法と 言う点では共通 2つを統合したGeneralized Distillationを 提案、分析
8.
統合することの利点 1. 特権情報の枠組みで使われていた理論 (計算論的学習理論)を蒸留の分析に使える 2. 様々な問題設定に拡張可能 1.
半教師あり学習 2. Learning with the Universum [Weston et al., 2006] 3. マルチタスク学習 4. カリキュラム学習(強化学習)
9.
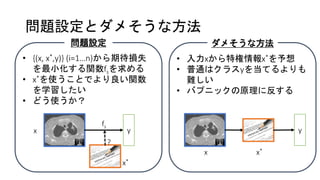
問題設定とダメそうな方法 問題設定 • {(x, x*,y)}
(i=1…n)から期待損失 を最小化する関数fsを求める • x*を使うことでより良い関数 を学習したい • どう使うか? y fs ? x x* ダメそうな方法 • 入力xから特権情報x*を予想 • 普通はクラスyを当てるよりも 難しい • バプニックの原理に反する y x x*
10.
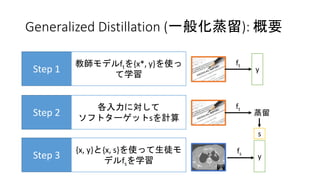
Generalized Distillation (一般化蒸留):
概要 Step 1 教師モデルftを{x*, y}を使っ て学習 Step 2 各入力に対して ソフトターゲットsを計算 Step 3 {x, y}と{x, s}を使って生徒モ デルfsを学習 y ft ft 蒸留 s fs y
11.
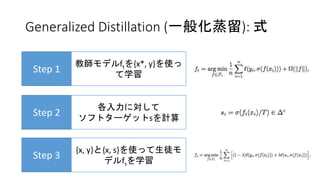
Generalized Distillation (一般化蒸留):
式 Step 1 教師モデルftを{x*, y}を使っ て学習 Step 2 各入力に対して ソフトターゲットsを計算 Step 3 {x, y}と{x, s}を使って生徒モ デルfsを学習
12.
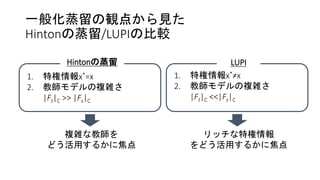
一般化蒸留の観点から見た Hintonの蒸留/LUPIの比較 Hintonの蒸留 1. 特権情報x*=x 2. 教師モデルの複雑さ |Ft|C
>> |Fs|C LUPI 1. 特権情報x*≠x 2. 教師モデルの複雑さ |Ft|C <<|Fs|C 複雑な教師を どう活用するかに焦点 リッチな特権情報 をどう活用するかに焦点
13.
一般的なLUPIの手法との違い Similarity Control • 訓練データにおけるサンプル間 の距離を教師が制御する •
SVM+[Vapnik, 2006] Knowledge Transfer • 特権情報空間の知識を分類平面 を引きたい空間に転移する • [Vapnik, 2015] • SVMに限定されている • SVM+は生徒のパラメタが2倍に 増える • SVM+は教師と生徒が同時に 学ぶ 違い/関係 概要 概要 違い/関係 • 基本的に似ている • Knowledge Transferは完全に 教師を真似する(GDは パラメタで制御できる)
14.
なぜGDがうまくいくのかの理論的分析 • VC次元をベースにした理論+いくつかの仮定を置くこと で1つの説明が可能 VC Theory 学習データ数をn、仮説集合のVC次元を|F|VC、危険率をδとした時に、 ある仮説fの経験誤差Rn(f)と期待誤差R(f)の間には次の関係が成り立つ ※αが重要 α=1/2の時とα=1の時だと同精度を 達成するのに106倍のサンプルが必要
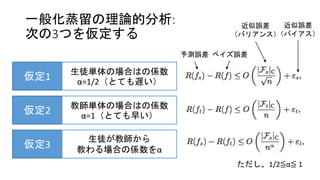
15.
一般化蒸留の理論的分析: 次の3つを仮定する 仮定1 生徒単体の場合はの係数 α=1/2(とても遅い) 仮定2 教師単体の場合はの係数 α=1(とても早い) 仮定3 生徒が教師から 教わる場合の係数をα ベイズ誤差予測誤差 近似誤差 (バイアス) 近似誤差 (バリアンス) ただし、1/2≦α≦
1
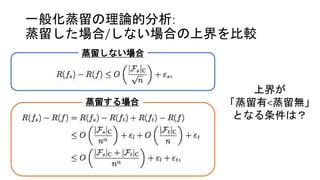
16.
一般化蒸留の理論的分析: 蒸留した場合/しない場合の上界を比較 蒸留しない場合 蒸留する場合 上界が 「蒸留有<蒸留無」 となる条件は?
17.
一般化蒸留の理論的分析: 蒸留がうまくいく条件 i. 教師が小さい(|Ft|cが小さい) ii. 教師の推定誤差εtが生徒の推定誤差εsより小さい iii.
係数αが1/2より大きい ついでに、nが小さいときほどこの蒸留が有効であることも言える (nが無限のときはどちらもバリアンスの項を無視できるので) 蒸留がうまくいく 条件(全部が成り立つ必要はない)
18.
一般化蒸留の拡張/有効な場面 半教師あり 学習 ラベル無しの場合に 特権情報を使う ユニバーサム 学習 カリキュラム 学習 蒸留の際に ユニバーサムは無視 特権情報を重み付け に利用1 マルチタスク 学習 ソースタスクのX/yを 特権情報として使う 強化学習 模倣学習に似た形 c.f. Policy Distillation2 1.
[M. P. Kumar, 2010] 2. [A. A. Rusu, 2016]
19.
数値シミュレーション: 7つの設定で実験 • 最初の4つは人工データ • 残りは実データ •
MNISTで教師あり蒸留 • CIFAR10で半教師あり蒸留 • SARCOSでマルチタスク学習 • 分類器はロジスティック回帰 • 1) 普通にXとyを使って訓練した場合と、 2) X*を蒸留したものを使って学習した場合を比較
20.
実験の前提: [Schokkopf et
al., 2012] Causal and Anti-causal Learning Causal Learning Anticausal Learning • 入力Xが原因、出力Yが結果と 見なせる場合(矢印が逆) • P(X)を学んでも意味がない • なのでSSLとかもうまくいかない • 入力Xが結果、出力Yが原因と 見なせる場合(矢印が逆) • P(X)を学ぶとP(Y|X)を予想しやすく なる ※詳しくは上の文献読んでください!
21.
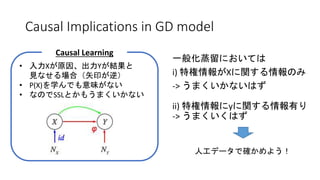
Causal Implications in
GD model 一般化蒸留においては i) 特権情報がXに関する情報のみ -> うまくいかないはず ii) 特権情報にyに関する情報有り -> うまくいくはず • 入力Xが原因、出力Yが結果と 見なせる場合(矢印が逆) • P(X)を学んでも意味がない • なのでSSLとかもうまくいかない Causal Learning 人工データで確かめよう!
22.
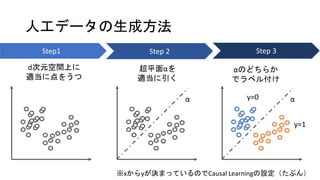
人工データの生成方法 超平面αを 適当に引く αのどちらか でラベル付け α α y=1 y=0 Step1 d次元空間上に 適当に点をうつ Step 2
Step 3 ※xからyが決まっているのでCausal Learningの設定(たぶん)
23.
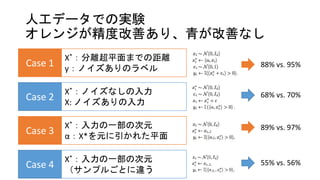
人工データでの実験 オレンジが精度改善あり、青が改善なし Case 1 X*:分離超平面までの距離 y:ノイズありのラベル Case 2 X*:ノイズなしの入力 X:
ノイズありの入力 Case 3 X*:入力の一部の次元 α:X*を元に引かれた平面 Case 4 X*:入力の一部の次元 (サンプルごとに違う 88% vs. 95% 68% vs. 70% 89% vs. 97% 55% vs. 56%
24.
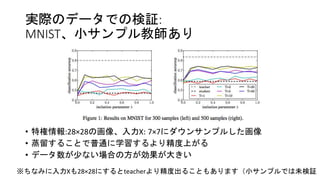
実際のデータでの検証: MNIST、小サンプル教師あり • 特権情報:28×28の画像、入力X: 7×7にダウンサンプルした画像 •
蒸留することで普通に学習するより精度上がる • データ数が少ない場合の方が効果が大きい ※ちなみに入力Xも28×28にするとteacherより精度出ることもあります(小サンプルでは未検証
25.
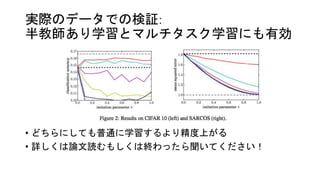
実際のデータでの検証: 半教師あり学習とマルチタスク学習にも有効 • どちらにしても普通に学習するより精度上がる • 詳しくは論文読むもしくは終わったら聞いてください!
26.
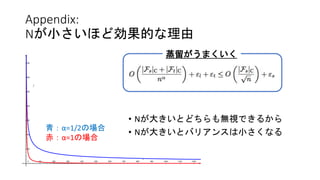
Appendix: Nが小さいほど効果的な理由 • Nが大きいとどちらも無視できるから • Nが大きいとバリアンスは小さくなる 青:α=1/2の場合 赤:α=1の場合 蒸留がうまくいく
Download
![[DL Hacks, Paper Reading]:
Unifying distillation and privileged information
2016.03.18 D2 岩澤](https://image.slidesharecdn.com/dlhacks20160318-160318065622/85/Dl-hacks-Unifying-distillation-and-privileged-information-1-320.jpg)
![[DL Hacks, Paper Reading]:
Unifying distillation and privileged information
2016.03.18 D2 岩澤](https://image.slidesharecdn.com/dlhacks20160318-160318065622/75/Dl-hacks-Unifying-distillation-and-privileged-information-1-2048.jpg)



![Background:
Learning Using Privileged Information (LUPI)
Classical Setting
Cancers
Healthy
• CT画像Xからある患者が
ガンかどうか予想する
• 期待損失を最小化する
• 教師という概念がない
LUPI [Vapnik 2009]
Cancers
Healthy
• CT画像の他にカルテ情報
(特権情報)を教える
• 期待損失最小化の点では同じ
• X*を教師が与えると考える
Xi
Xi
X*
i
yi
yi
※f: 学習する関数、y:理想的な出力](https://image.slidesharecdn.com/dlhacks20160318-160318065622/85/Dl-hacks-Unifying-distillation-and-privileged-information-5-320.jpg)
![Background: Distillation (Dark Knowledge)
[Hinton, 2015]
教師モデル (Teacher Model)
• より柔軟
• 典型的にはパラメタが多い
• 普通に1-Hotのラベル
(ハードターゲット)で学習
生徒モデル (Student Model)
y
• よりシンプル
• 典型的にはパラメタが少ない
• ハードターゲットと、教師モデルから得られ
るソフトターゲットとの誤差関数を最適化
• 教師を真似ることで効率よく学習
y
Lh Lh
蒸留 Ls](https://image.slidesharecdn.com/dlhacks20160318-160318065622/85/Dl-hacks-Unifying-distillation-and-privileged-information-6-320.jpg)
![統合することの利点
1. 特権情報の枠組みで使われていた理論
(計算論的学習理論)を蒸留の分析に使える
2. 様々な問題設定に拡張可能
1. 半教師あり学習
2. Learning with the Universum [Weston et al., 2006]
3. マルチタスク学習
4. カリキュラム学習(強化学習)](https://image.slidesharecdn.com/dlhacks20160318-160318065622/85/Dl-hacks-Unifying-distillation-and-privileged-information-8-320.jpg)
![一般的なLUPIの手法との違い
Similarity Control
• 訓練データにおけるサンプル間
の距離を教師が制御する
• SVM+[Vapnik, 2006]
Knowledge Transfer
• 特権情報空間の知識を分類平面
を引きたい空間に転移する
• [Vapnik, 2015]
• SVMに限定されている
• SVM+は生徒のパラメタが2倍に
増える
• SVM+は教師と生徒が同時に
学ぶ
違い/関係
概要 概要
違い/関係
• 基本的に似ている
• Knowledge Transferは完全に
教師を真似する(GDは
パラメタで制御できる)](https://image.slidesharecdn.com/dlhacks20160318-160318065622/85/Dl-hacks-Unifying-distillation-and-privileged-information-13-320.jpg)


![一般化蒸留の拡張/有効な場面
半教師あり
学習
ラベル無しの場合に
特権情報を使う
ユニバーサム
学習
カリキュラム
学習
蒸留の際に
ユニバーサムは無視
特権情報を重み付け
に利用1
マルチタスク
学習
ソースタスクのX/yを
特権情報として使う
強化学習
模倣学習に似た形
c.f. Policy Distillation2
1. [M. P. Kumar, 2010]
2. [A. A. Rusu, 2016]](https://image.slidesharecdn.com/dlhacks20160318-160318065622/85/Dl-hacks-Unifying-distillation-and-privileged-information-18-320.jpg)

![実験の前提: [Schokkopf et al., 2012]
Causal and Anti-causal Learning
Causal Learning Anticausal Learning
• 入力Xが原因、出力Yが結果と
見なせる場合(矢印が逆)
• P(X)を学んでも意味がない
• なのでSSLとかもうまくいかない
• 入力Xが結果、出力Yが原因と
見なせる場合(矢印が逆)
• P(X)を学ぶとP(Y|X)を予想しやすく
なる
※詳しくは上の文献読んでください!](https://image.slidesharecdn.com/dlhacks20160318-160318065622/85/Dl-hacks-Unifying-distillation-and-privileged-information-20-320.jpg)



![[DLHacks LT] PytorchのDataLoader -torchtextのソースコードを読んでみた-](https://cdn.slidesharecdn.com/ss_thumbnails/torchtextupload-170918235754-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an...](https://cdn.slidesharecdn.com/ss_thumbnails/20200626journalclubpub-200630064755-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Attention Is All You Need](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks170714-170714005330-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]深層強化学習はなぜ難しいのか?Why Deep RL fails? A brief survey of recent works.](https://cdn.slidesharecdn.com/ss_thumbnails/20210115dlohta-210115054939-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DLHacks 実装]Network Dissection: Quantifying Interpretability of Deep Visual R...](https://cdn.slidesharecdn.com/ss_thumbnails/171030netdissectimple1-171030120240-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20190621dlhack-190621022108-thumbnail.jpg?width=640&height=640&fit=bounds)




![[MIRU2018] Global Average Poolingの特性を用いたAttention Branch Network](https://cdn.slidesharecdn.com/ss_thumbnails/miru2018longorl-v3-180810062528-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Temporal Abstraction in NeurIPS2019](https://cdn.slidesharecdn.com/ss_thumbnails/20191115-191112082849-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL Hacks輪読] Semi-Supervised Learning with Ladder Networks (NIPS2015)](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks-paper-reading-160107093848-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会] Semi-Supervised Knowledge Transfer For Deep Learning From Private Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170414iwasawa-170414094134-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ICLR2016] 採録論文の個人的まとめ](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2016-acceptedpapers-160209033749-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会] GAN系の研究まとめ (NIPS2016とICLR2016が中心)](https://cdn.slidesharecdn.com/ss_thumbnails/dliwasawagansurvey-161220014753-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会] Controllable Invariance through Adversarial Feature Learning” (NIPS2017)](https://cdn.slidesharecdn.com/ss_thumbnails/20171121iwasawa-171120061515-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会] “Asymmetric Tri-training for Unsupervised Domain Adaptation (ICML2017...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170728-170728025901-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会] Hybrid computing using a neural network with dynamic external memory](https://cdn.slidesharecdn.com/ss_thumbnails/dliwasawadnc-161220014044-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL Hacks] Learning Transferable Features with Deep Adaptation Networks](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks-20151105-iwasawa-160204020204-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper Reading] Learning Distributed Representations for Structured Output Pr...](https://cdn.slidesharecdn.com/ss_thumbnails/iwasawa-paperreading-20151014-160204014222-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL Hacks] Self Paced Learning with Diversity](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks0813-150820004116-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
