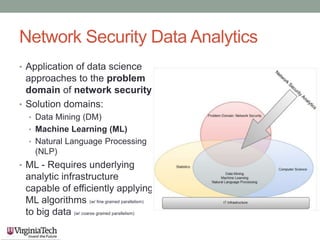
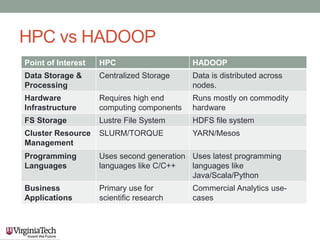
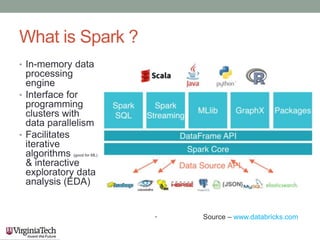
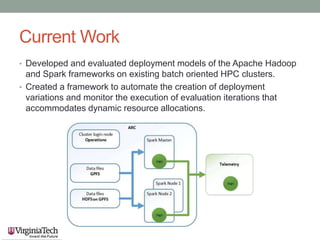
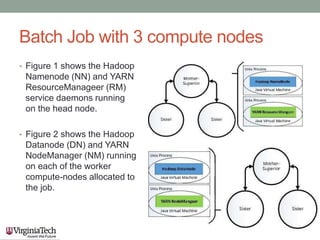
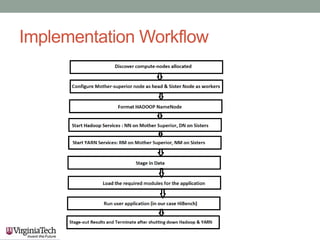
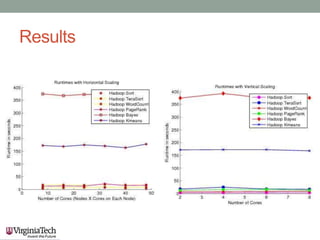
This document discusses running the Apache Spark framework on HPC clusters at Virginia Tech (VT) for big data analytics and machine learning. It describes implementing Spark on the VT Advanced Research Computing (ARC) clusters, which allow both fine-grained parallelism for machine learning algorithms and coarse-grained parallelism for big data. Evaluation results show the resource utilization of Spark deployed in standalone and YARN modes at different scales. Future work aims to examine scheduler overhead, shared resource contention, running machine learning on real network logs, and analyzing performance on streaming data.