Downloaded 29 times










































![Testing
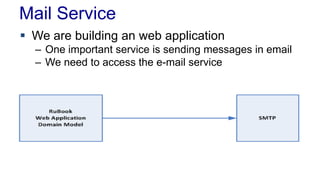
Testing MailService and MainSender is easy
public class TestMail
{
public static void main(String[] args)
{
MailService mail = new MailSender();
mail.send("andri@ru.is", // from
"andri@ru.is", // to
"Hallo", // subject
"So does this stuff work"); // body
}
}](https://image.slidesharecdn.com/l04basepatterns-130907043851-/85/L04-base-patterns-57-320.jpg)
![Testing
What is the problem with clients like this?
public class TestMail
{
public static void main(String[] args)
{
MailService mail = new MailSender();
mail.send("andri@ru.is", // from
"andri@ru.is", // to
"Hallo", // subject
"So does this stuff work"); // body
}
}](https://image.slidesharecdn.com/l04basepatterns-130907043851-/85/L04-base-patterns-59-320.jpg)













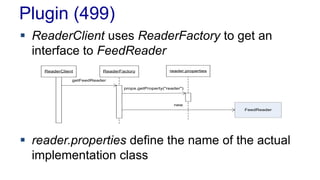
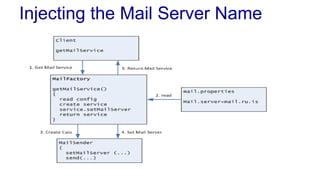
![Testing
Using the MailFactory class
– We can catch the MailServiceException or ignore it
– Notice we have not only abstracted the Mail API but
also the exception handling
public class TestMail
{
public static void main(String[] args)
{
MailFactory mf = new MailFactory();
MailService mail = mf.getMailService();
mail.send("andri@ru.is", "andri@ru.is", "Hello", "Hello");
}
}](https://image.slidesharecdn.com/l04basepatterns-130907043851-/85/L04-base-patterns-74-320.jpg)


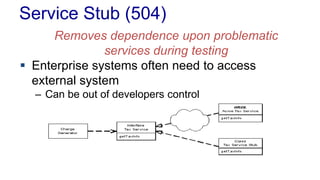











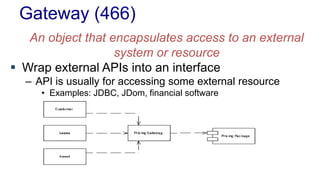
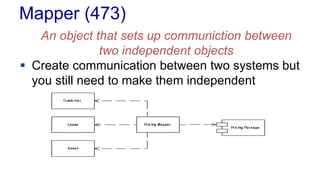
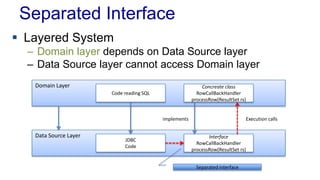
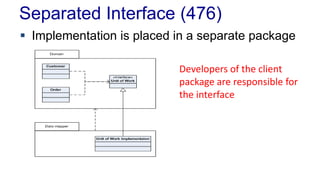
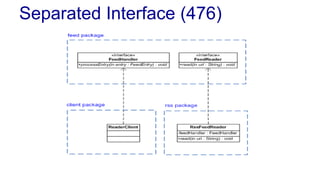
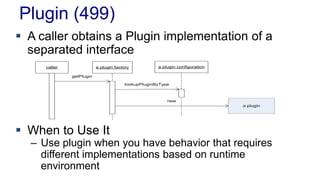
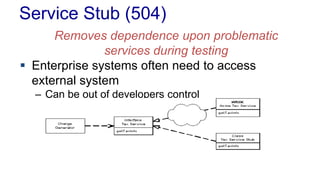
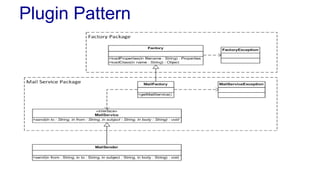
The document outlines various design patterns, including gateways, mappers, separated interfaces, plugins, and service stubs, providing definitions and usage scenarios for each. It emphasizes the importance of decoupling components in a system for improved maintenance and testing, as well as the need for common functionality through layered superclasses. It also offers insights into practical implementations, like handling email services and factory design for configuration-driven class loading.

















































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)


















