Downloaded 181 times


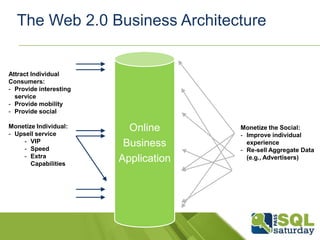
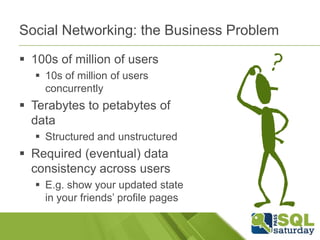





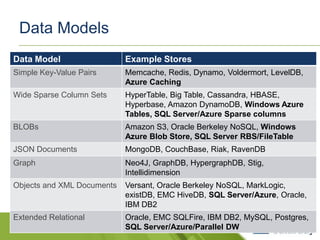





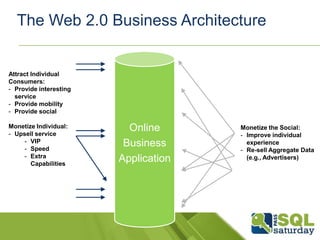
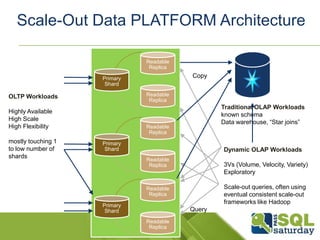


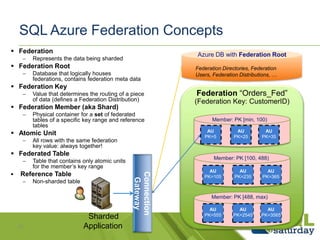





This document discusses SQL and NoSQL approaches to scaling databases. It describes how social networks and other large-scale websites use techniques like sharding and messaging to partition data across many databases. It also discusses how SQL Server is adopting NoSQL paradigms like flexible schemas and federated sharding to provide scalability. The document aims to educate about scaling databases and how SQL Server is evolving to support both SQL and NoSQL approaches.





























![Security best practices for hyper v and server virtualisation [svr307]](https://cdn.slidesharecdn.com/ss_thumbnails/securitybestpracticesforhyper-vandservervirtualisationsvr307-100317030250-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)












































































