Downloaded 167 times


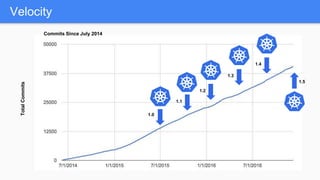





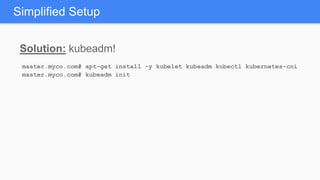
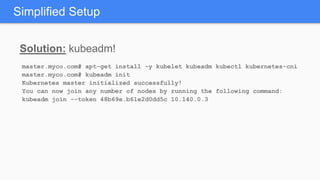
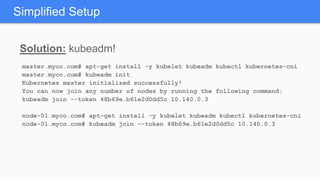
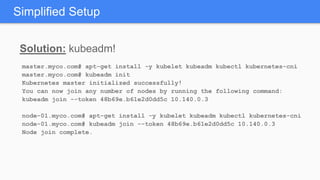
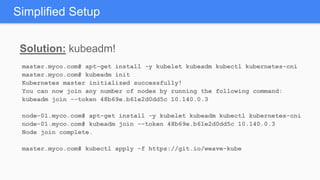
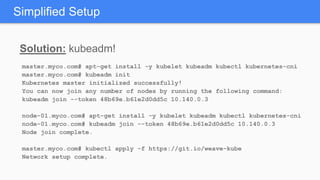

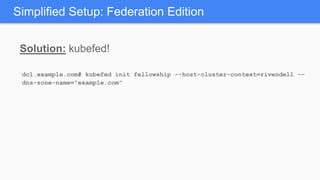
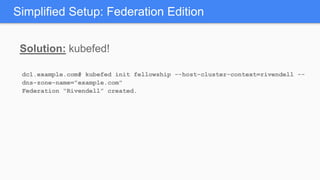
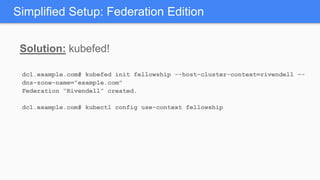
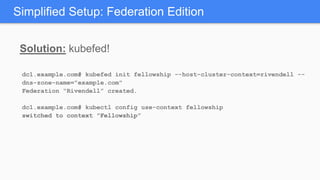
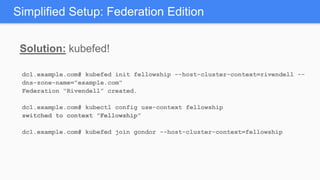
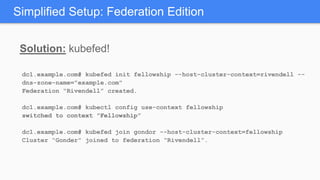
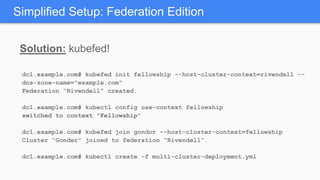
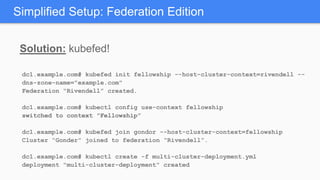

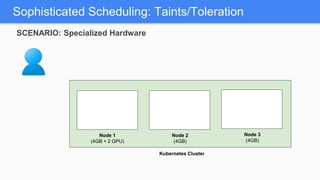
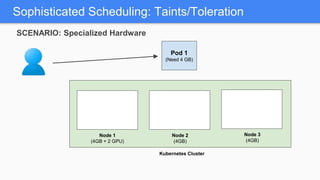
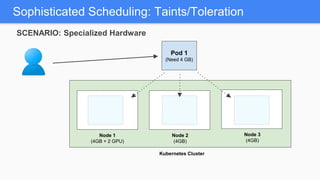
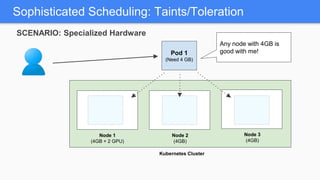
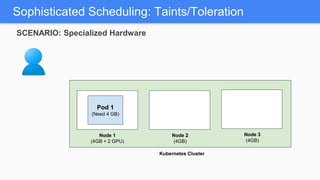
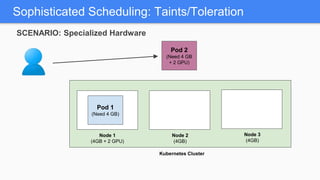
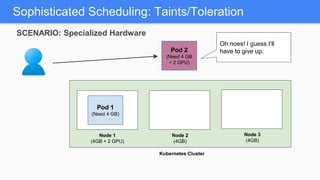
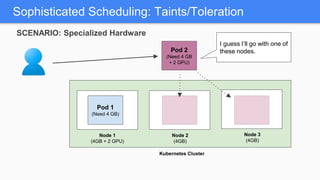
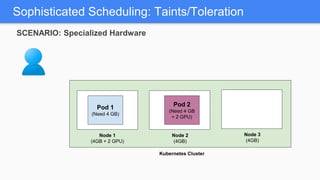
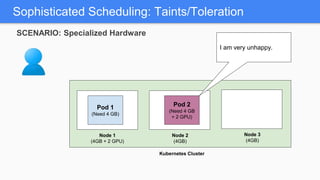
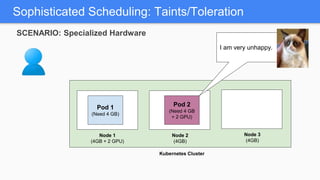
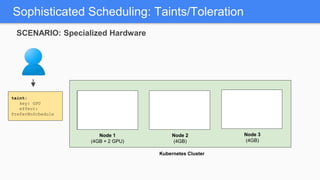
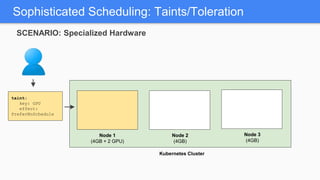
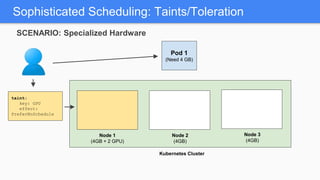
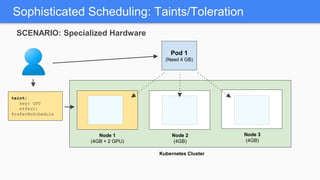
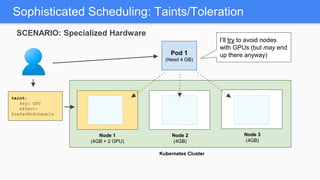
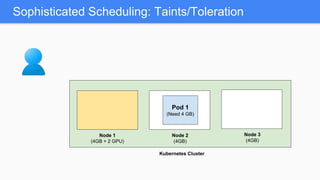
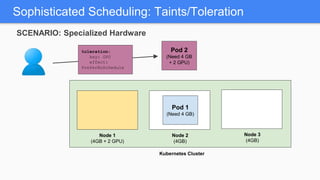
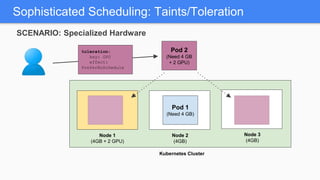
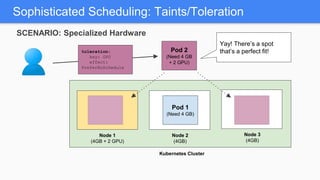
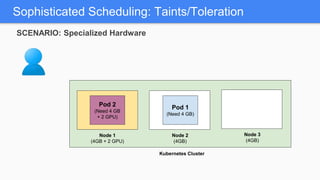
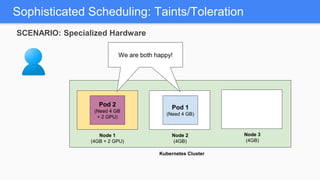
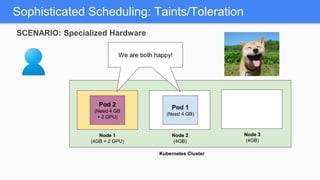
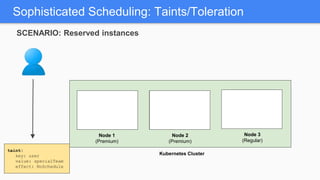
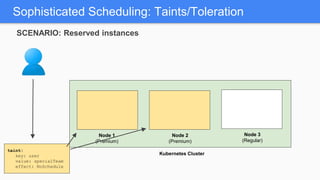
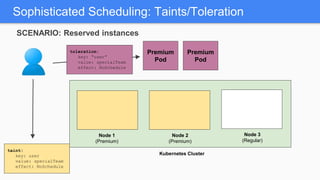
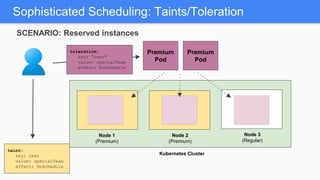
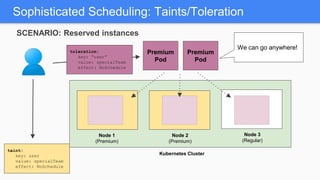
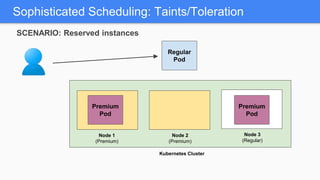
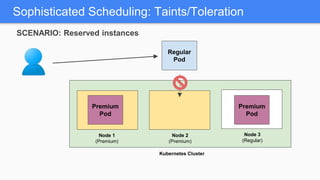
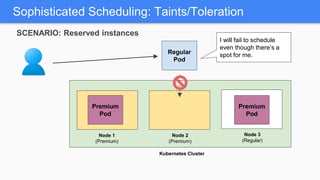
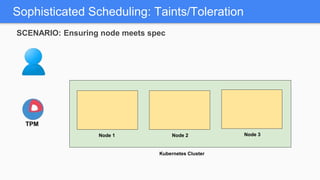
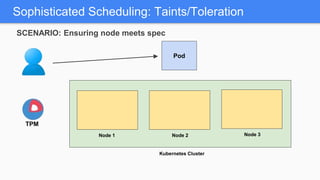
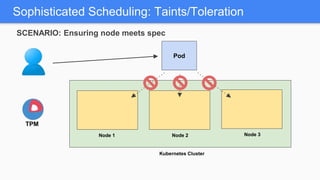
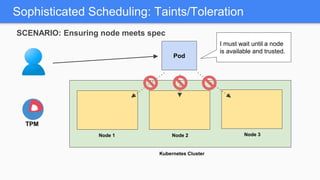
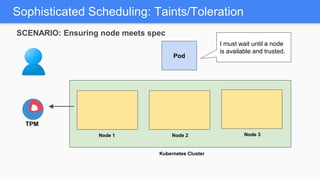
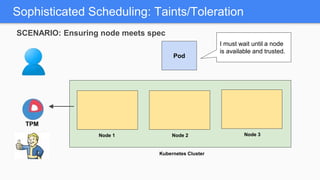
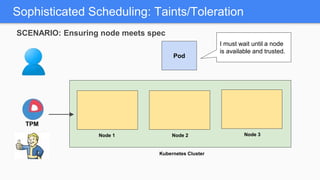
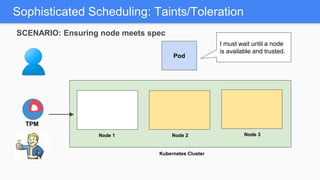
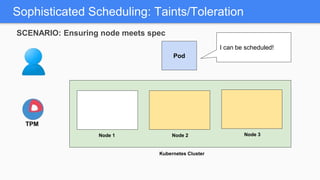
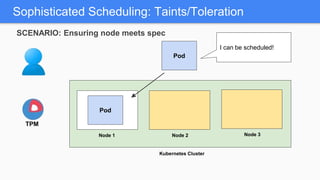
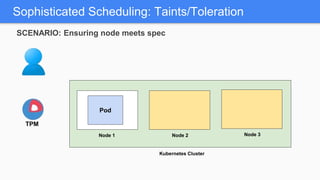
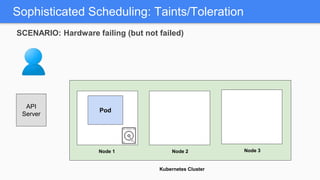
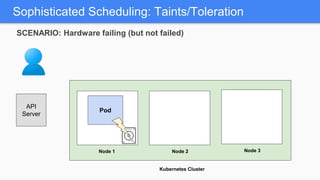
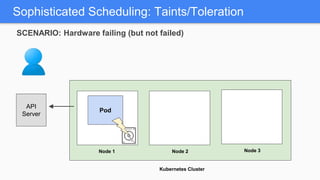
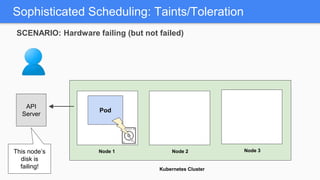
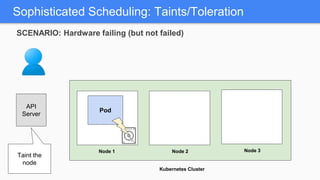
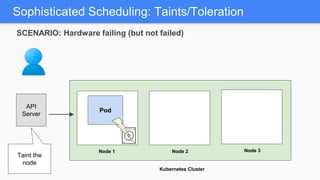
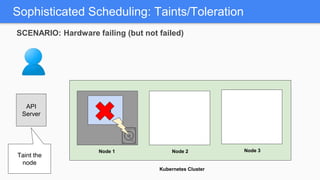
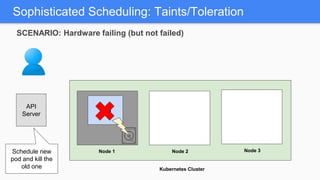
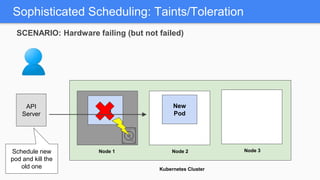
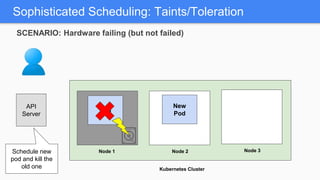
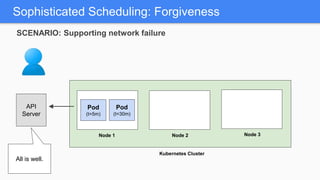
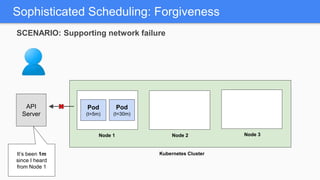
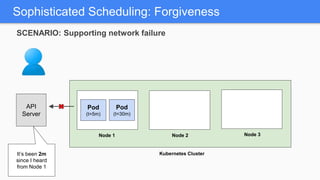
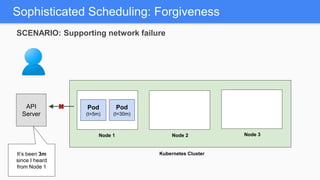
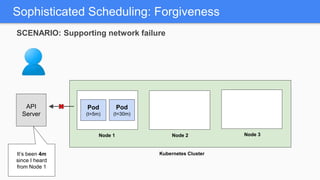
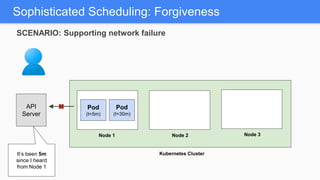
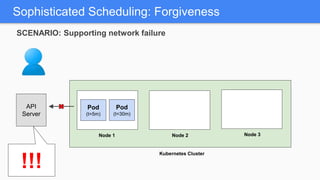
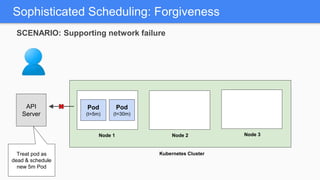
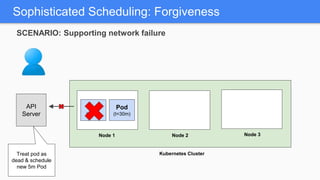
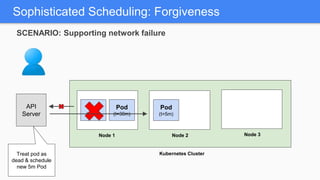
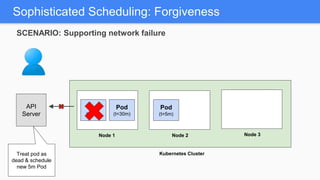
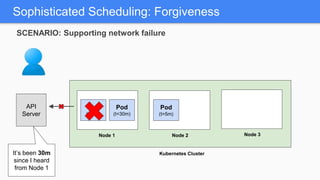
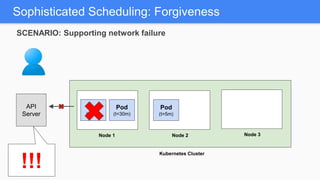
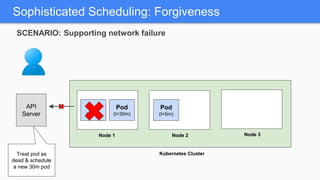
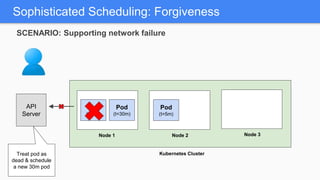
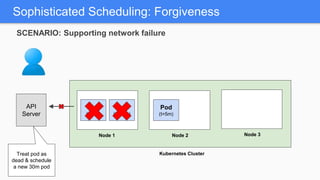
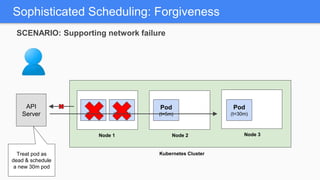
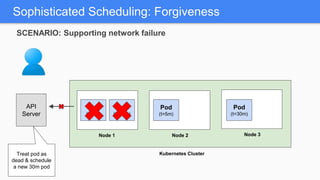
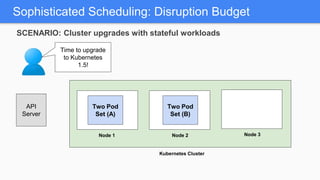
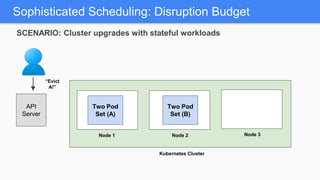
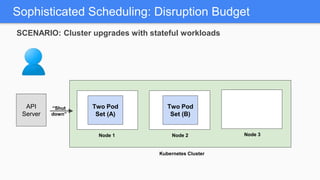
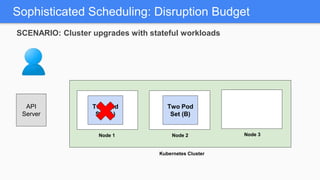
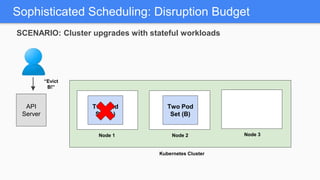
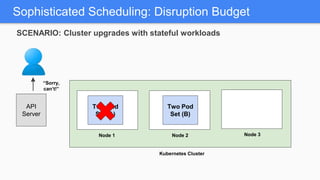
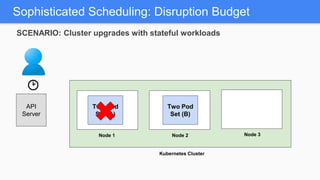
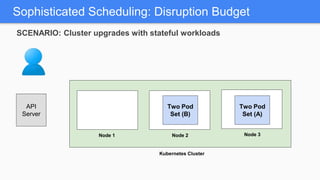
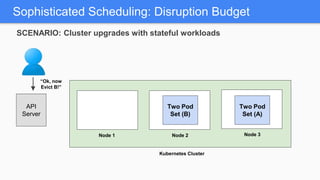
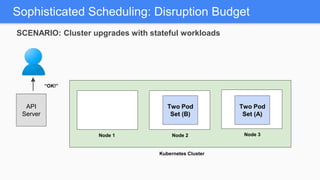
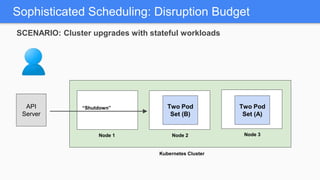
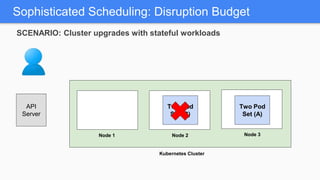





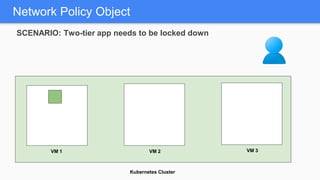
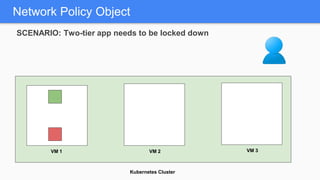
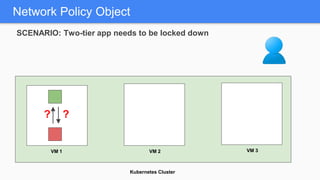
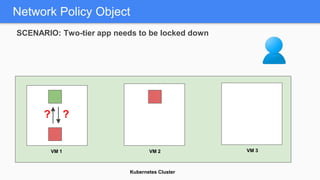
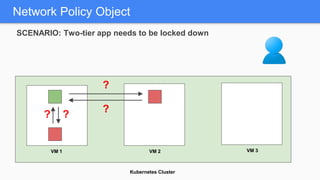
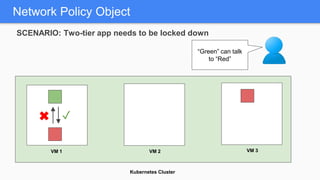
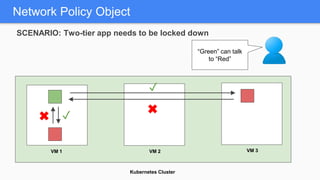


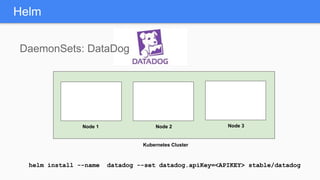
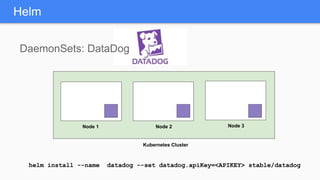
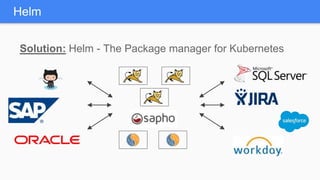
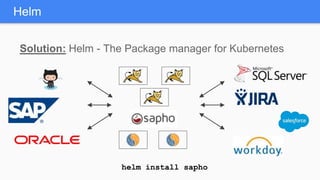










Kubernetes 1.5 introduces several new features to simplify cluster setup and improve scheduling. It provides an easy way to initialize a Kubernetes cluster with a single command using kubeadm. Multiple clusters can also be easily federated together using kubefed. Additionally, Kubernetes 1.5 enhances scheduling capabilities with taints and tolerations, which allow pods to be selectively scheduled to nodes based on hardware requirements like GPUs. This helps optimize workload placement on large, heterogeneous clusters.


































































































