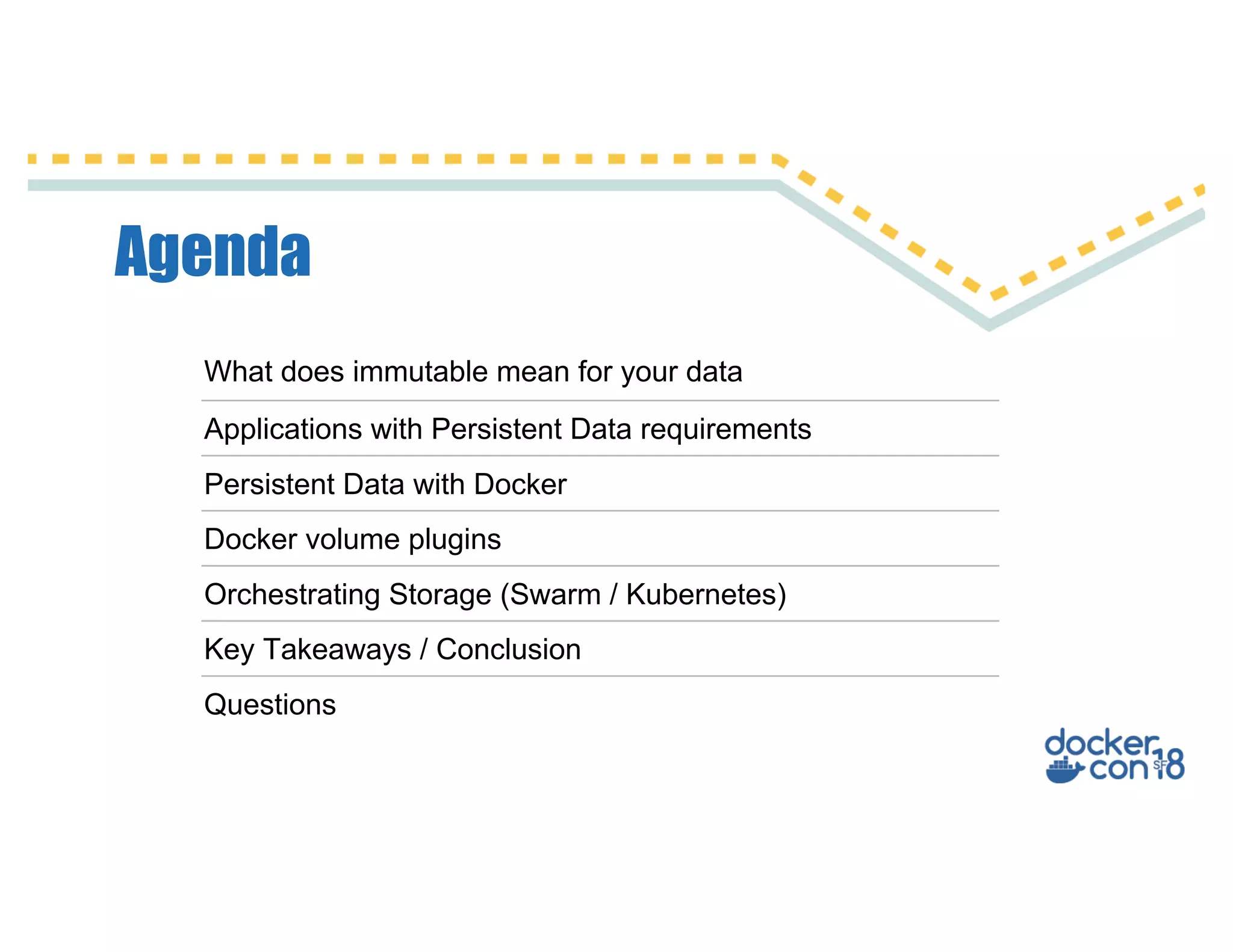
Download as PDF, PPTX














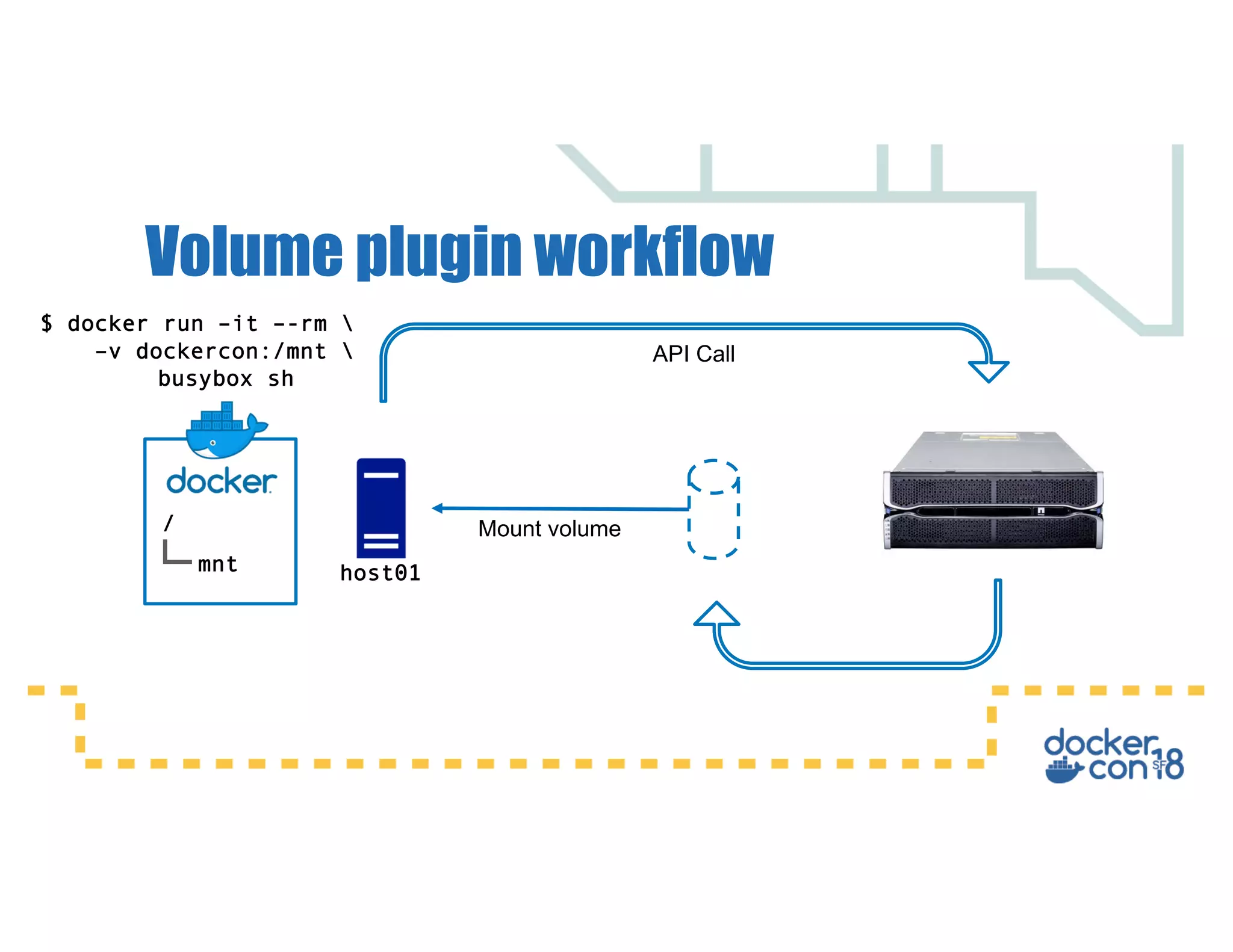
![Volume plugin workflow
[dan@dockercon ~]$ docker volume –d array -o ssd -o 32Gb fast_volume
fast_volume
[dan@dockercon ~]$ docker volume ls
DRIVER VOLUME NAME
array fast_volume
[dan@dockercon ~]$ docker plugin install store/storagedriver/array](https://image.slidesharecdn.com/dockerstoragedesigningaplatformforpersistentdata-180620234956/75/Docker-storage-designing-a-platform-for-persistent-data-32-2048.jpg)



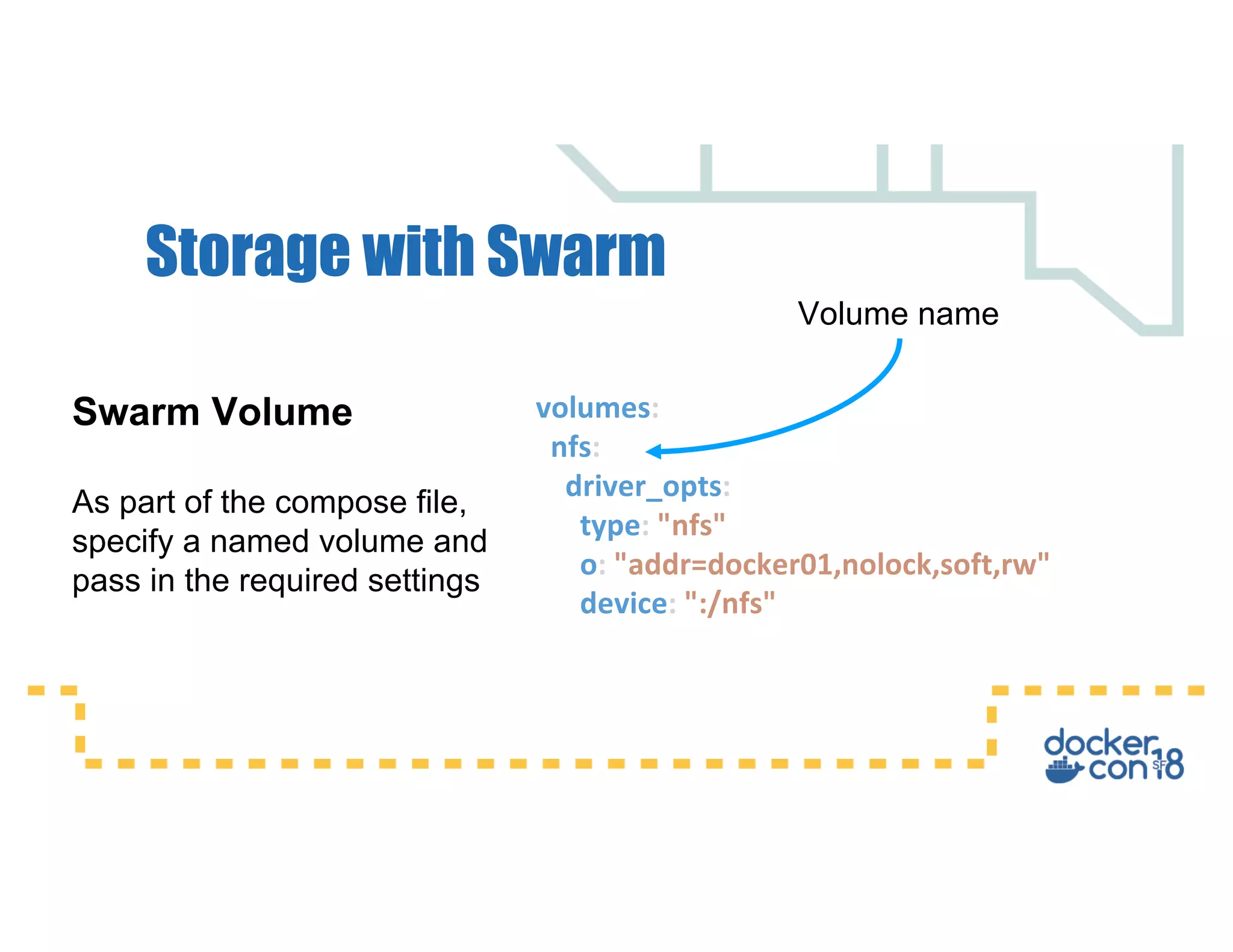
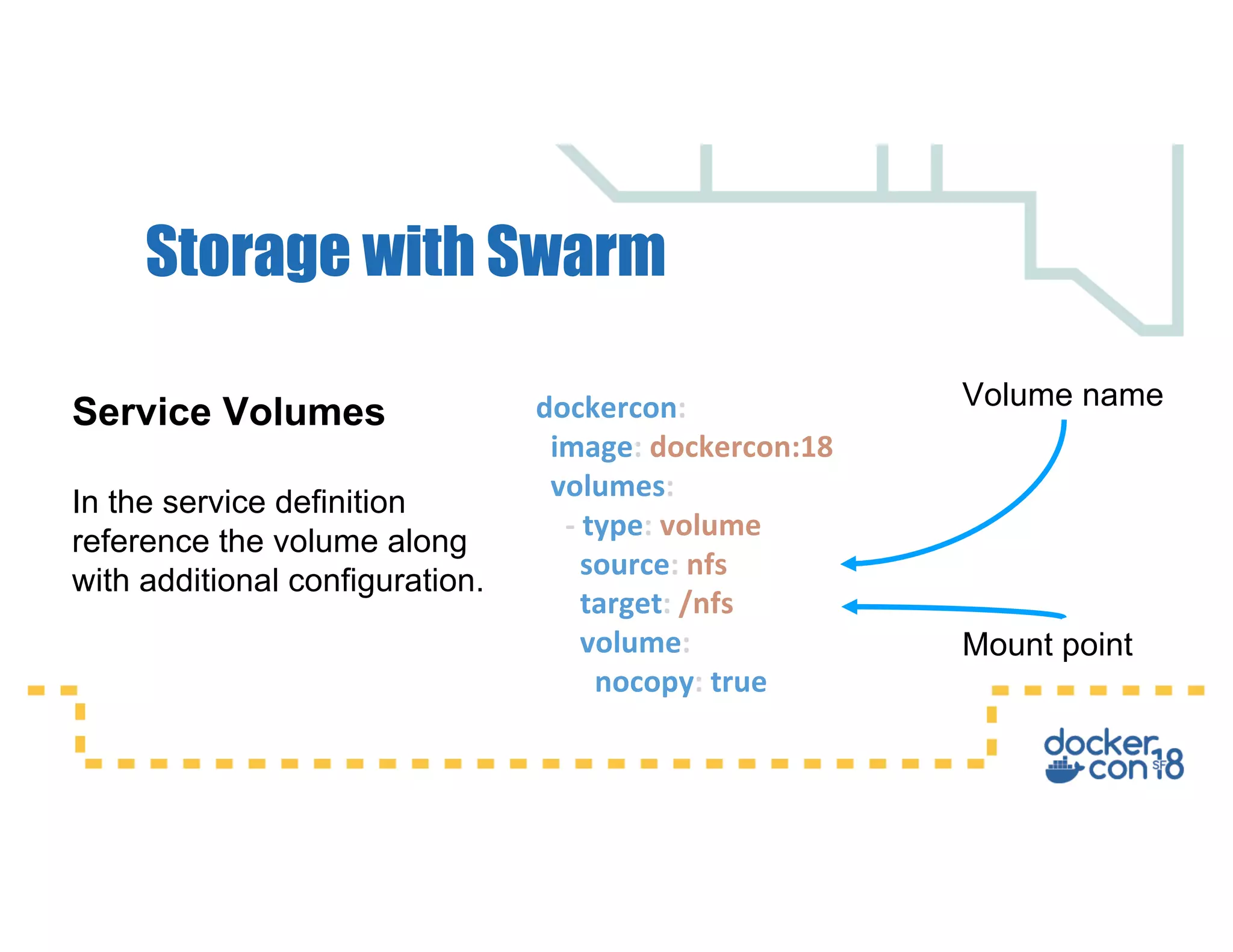
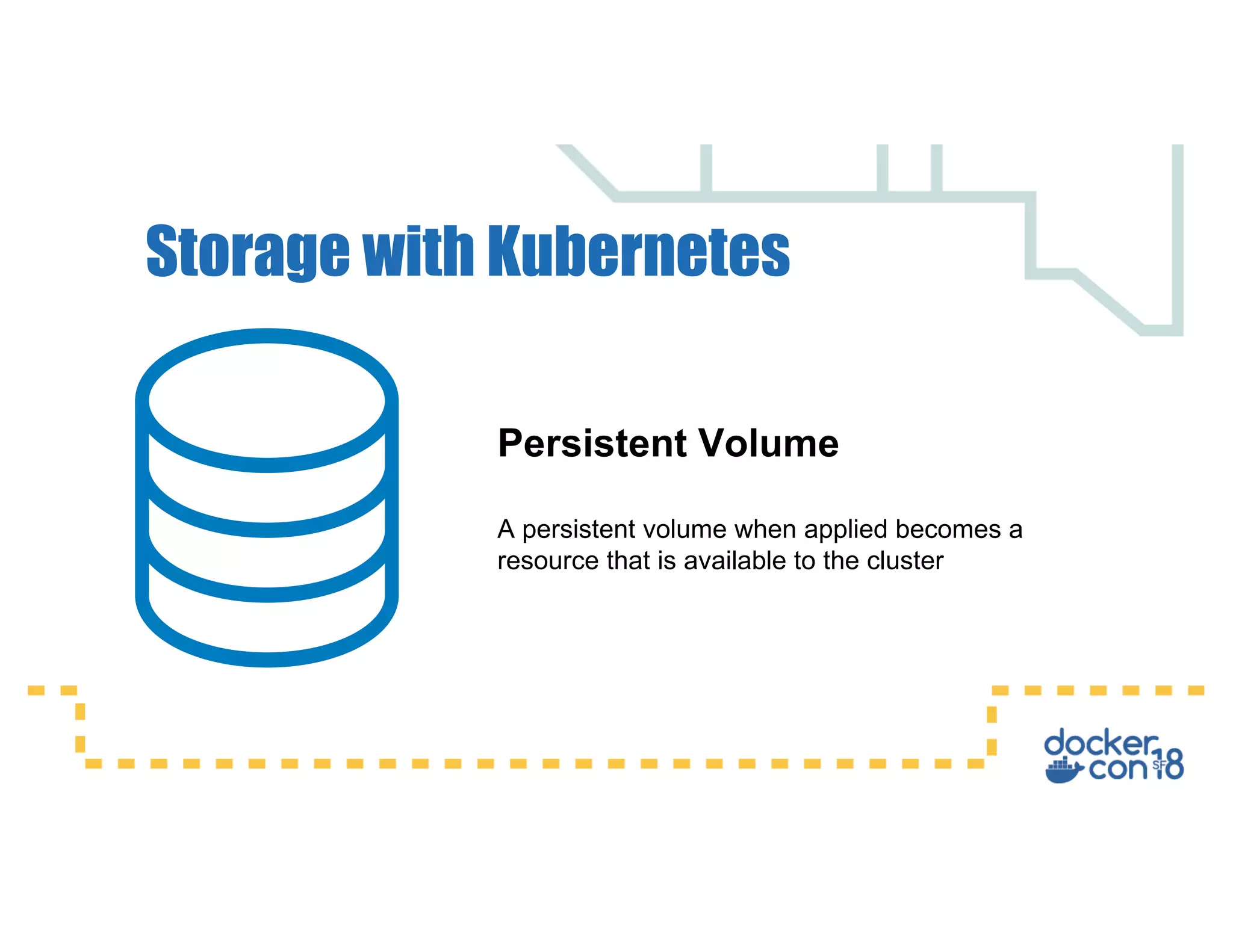
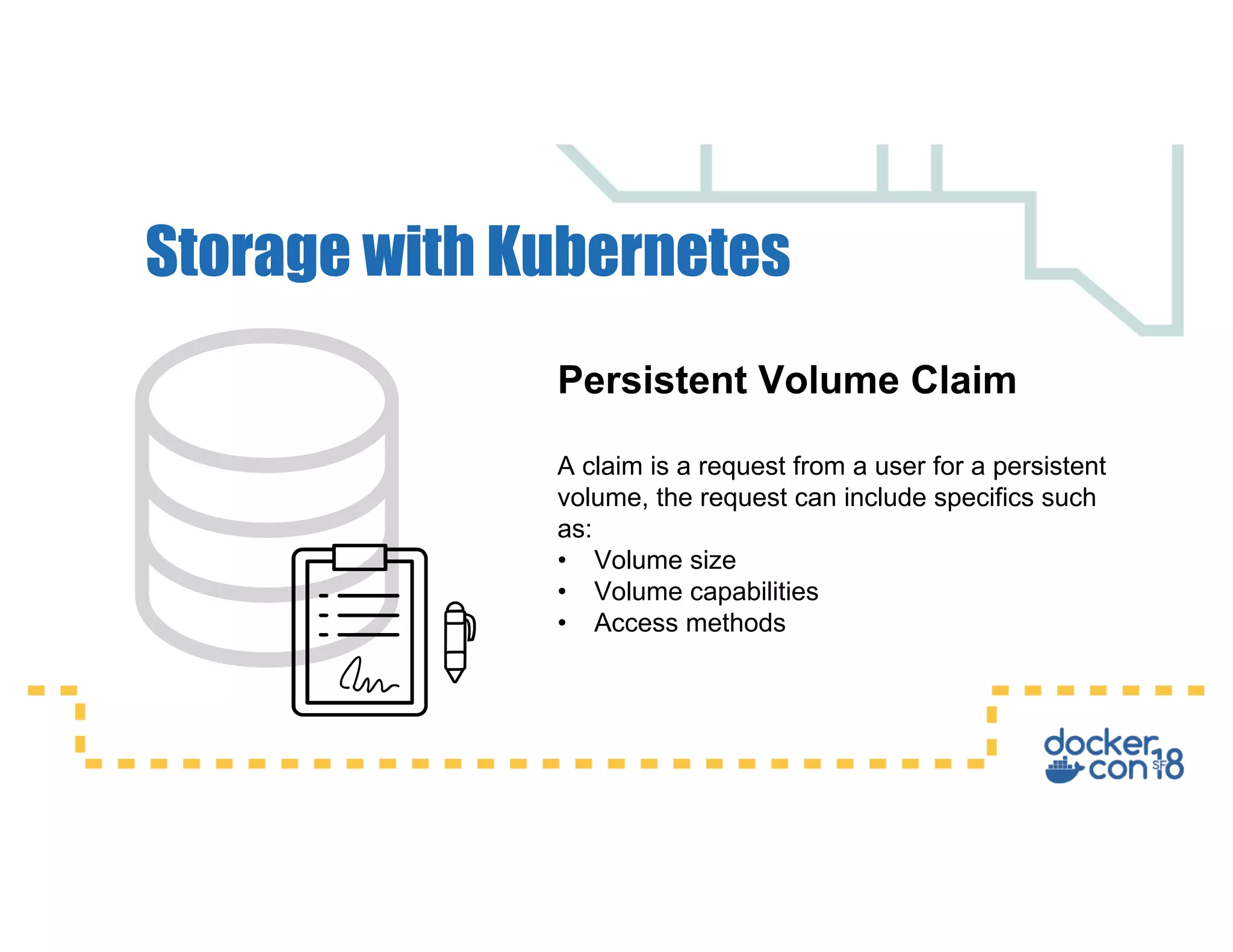
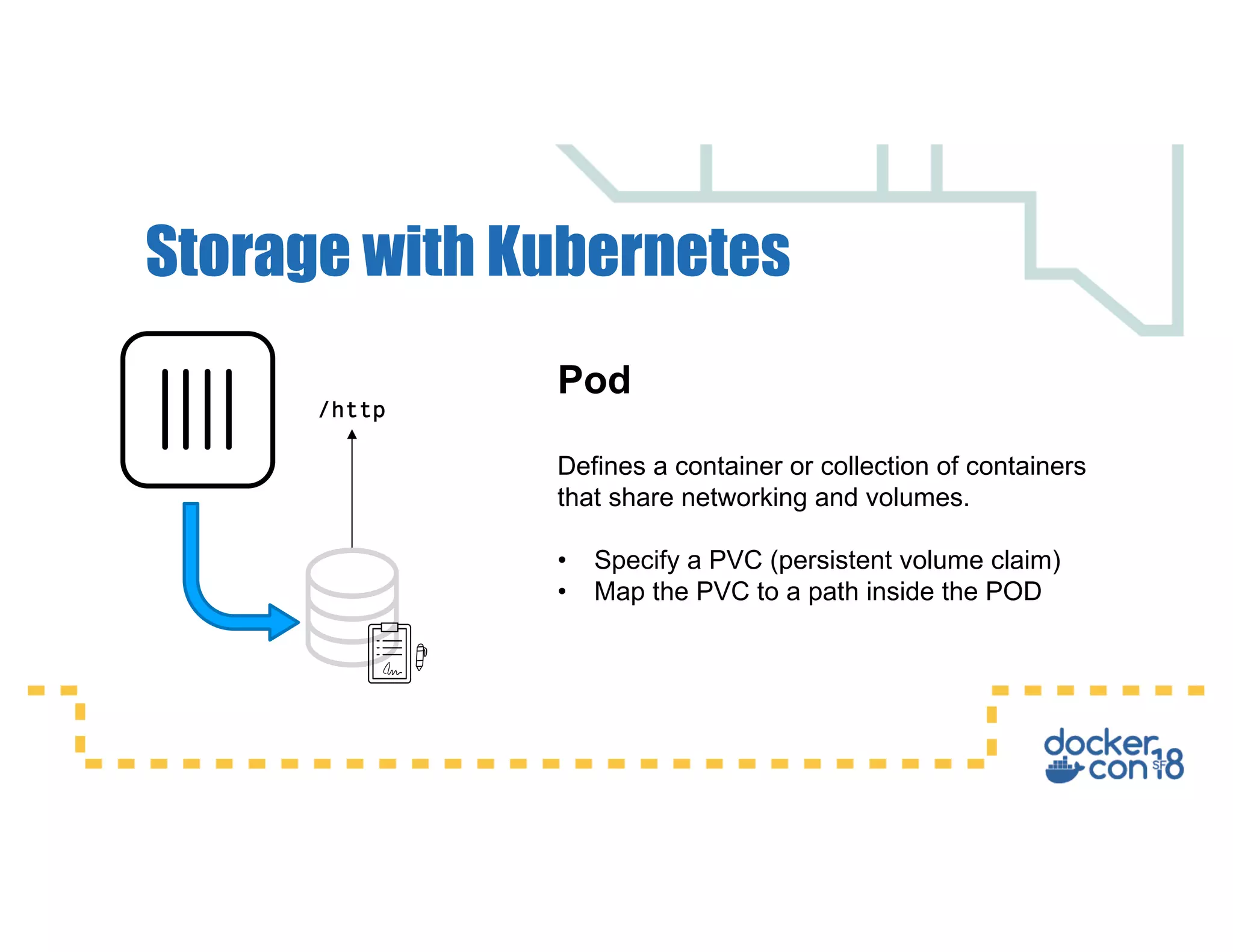
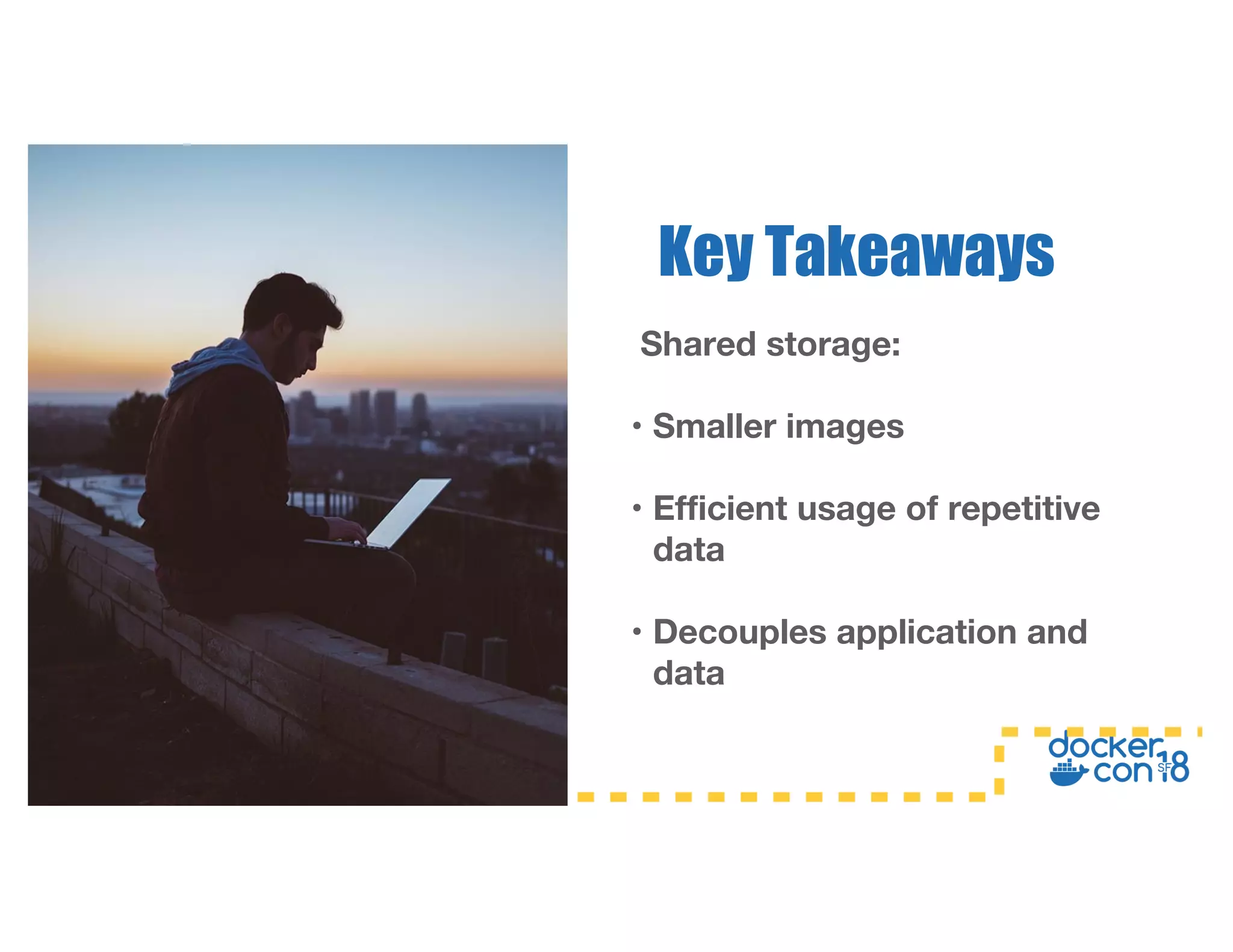


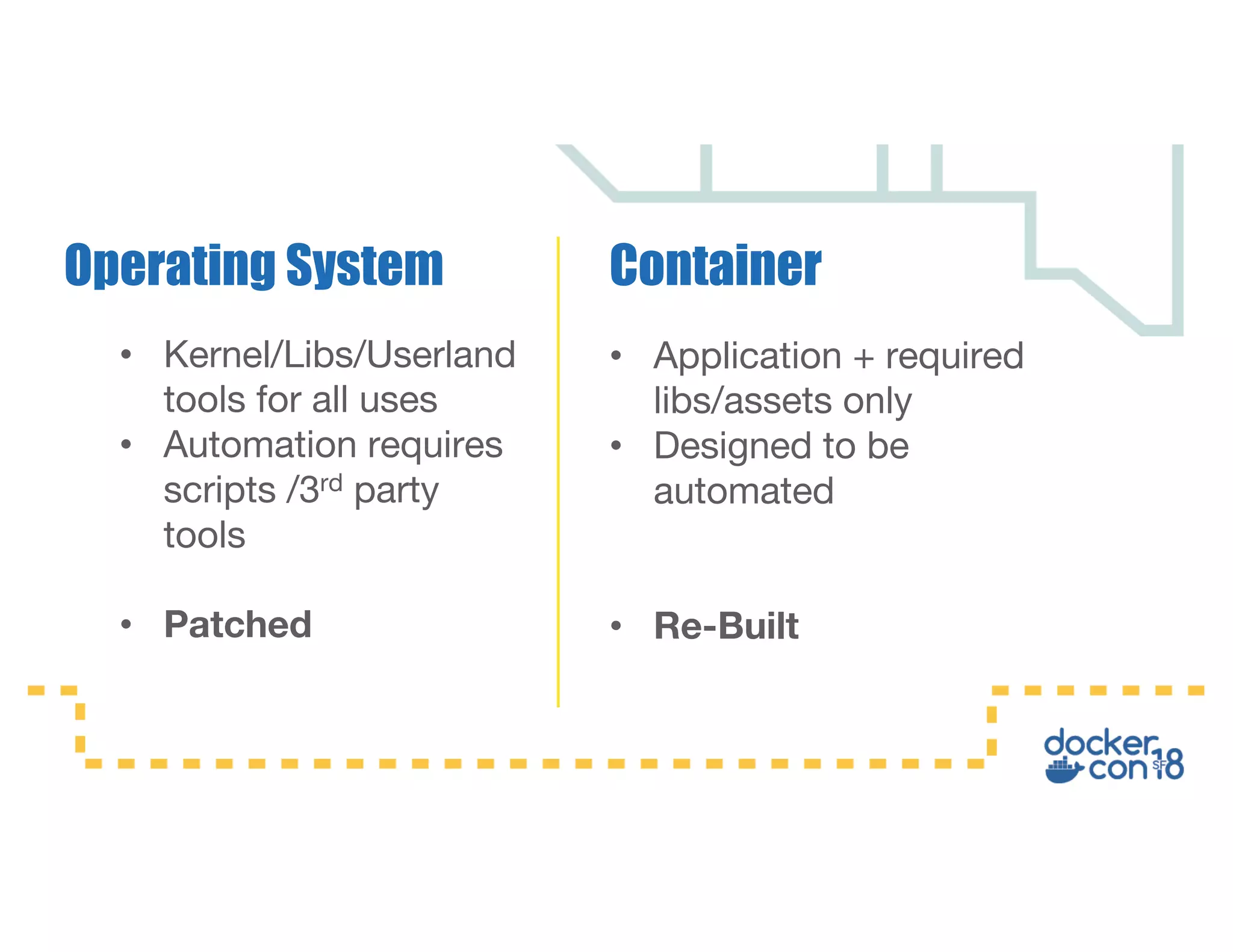
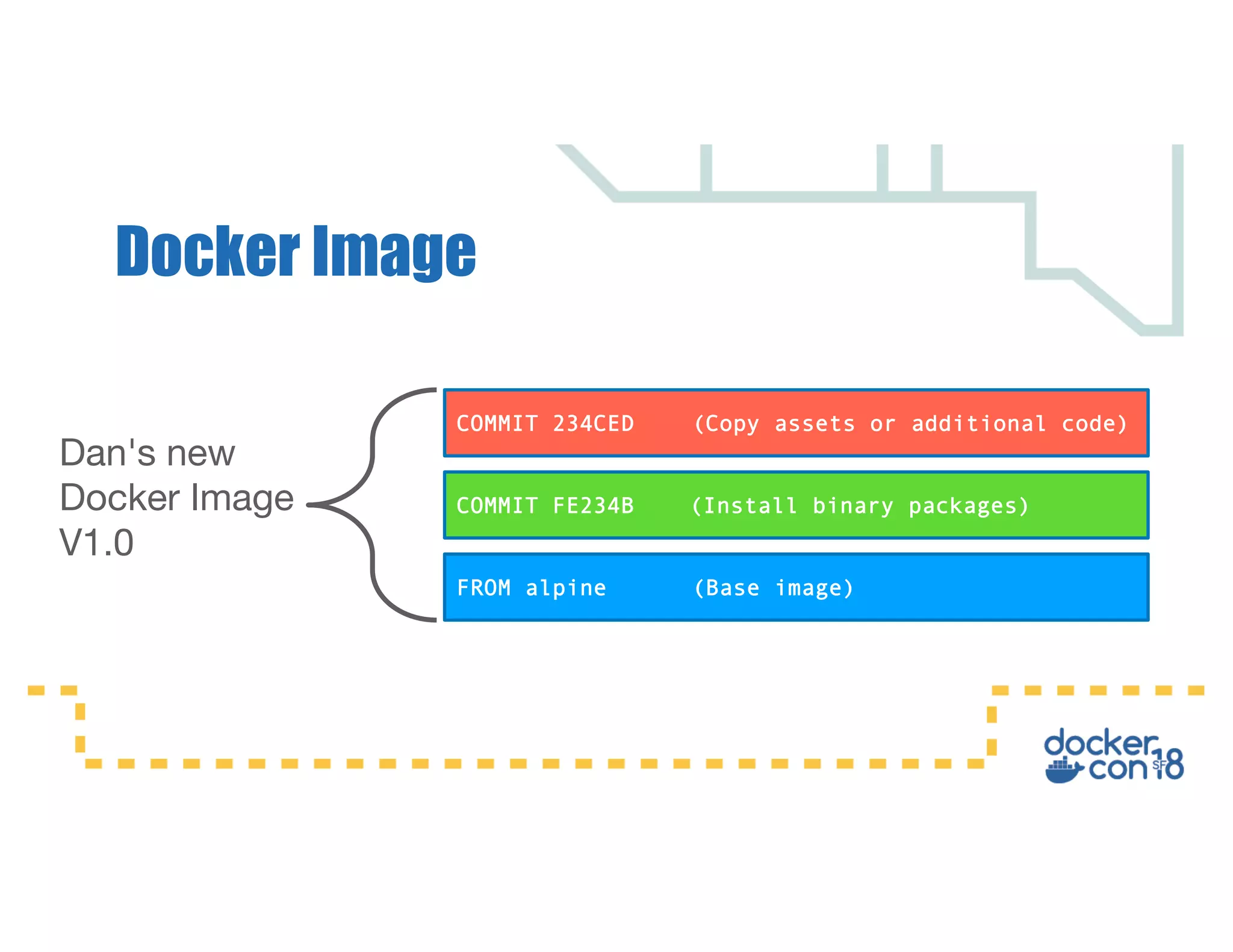
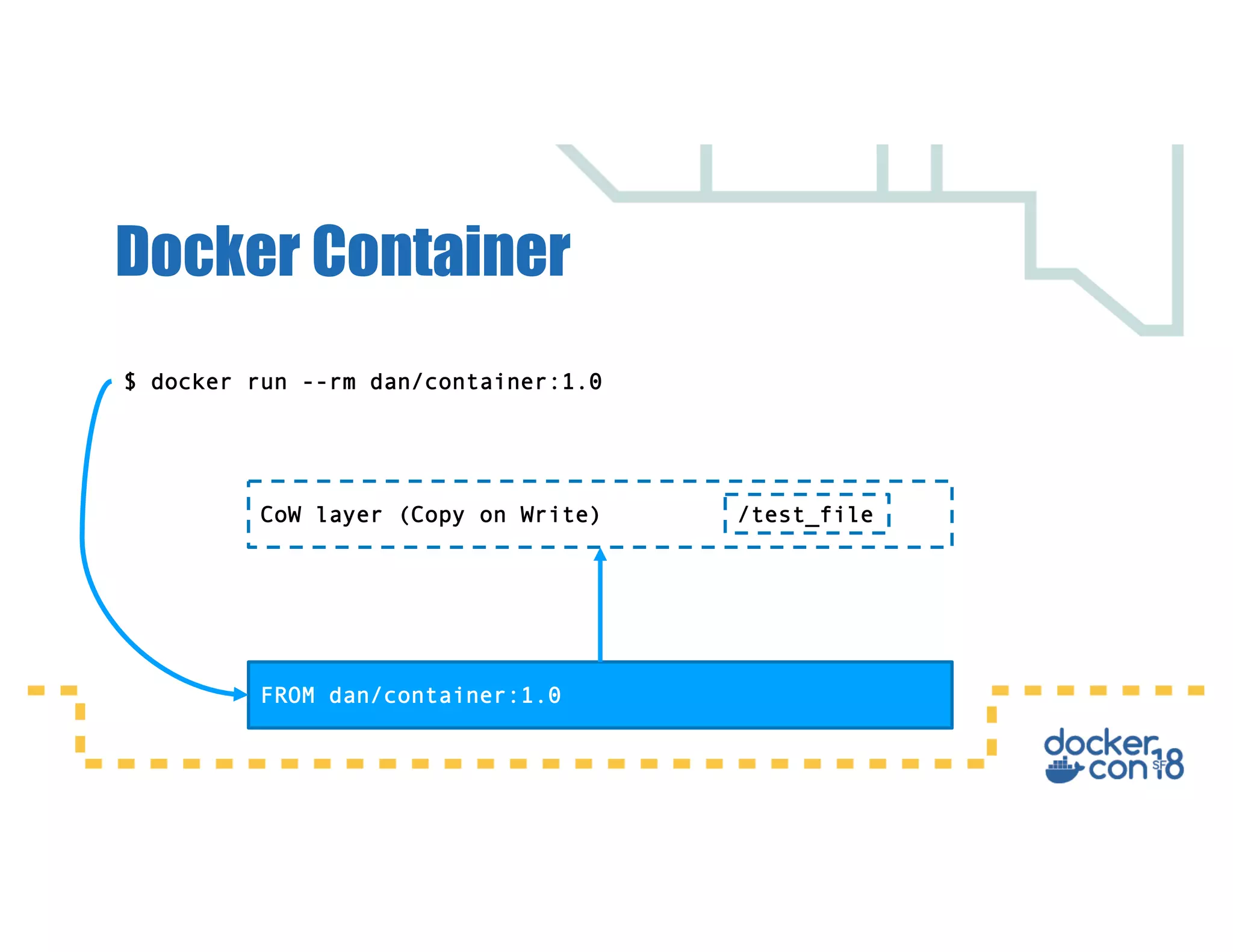
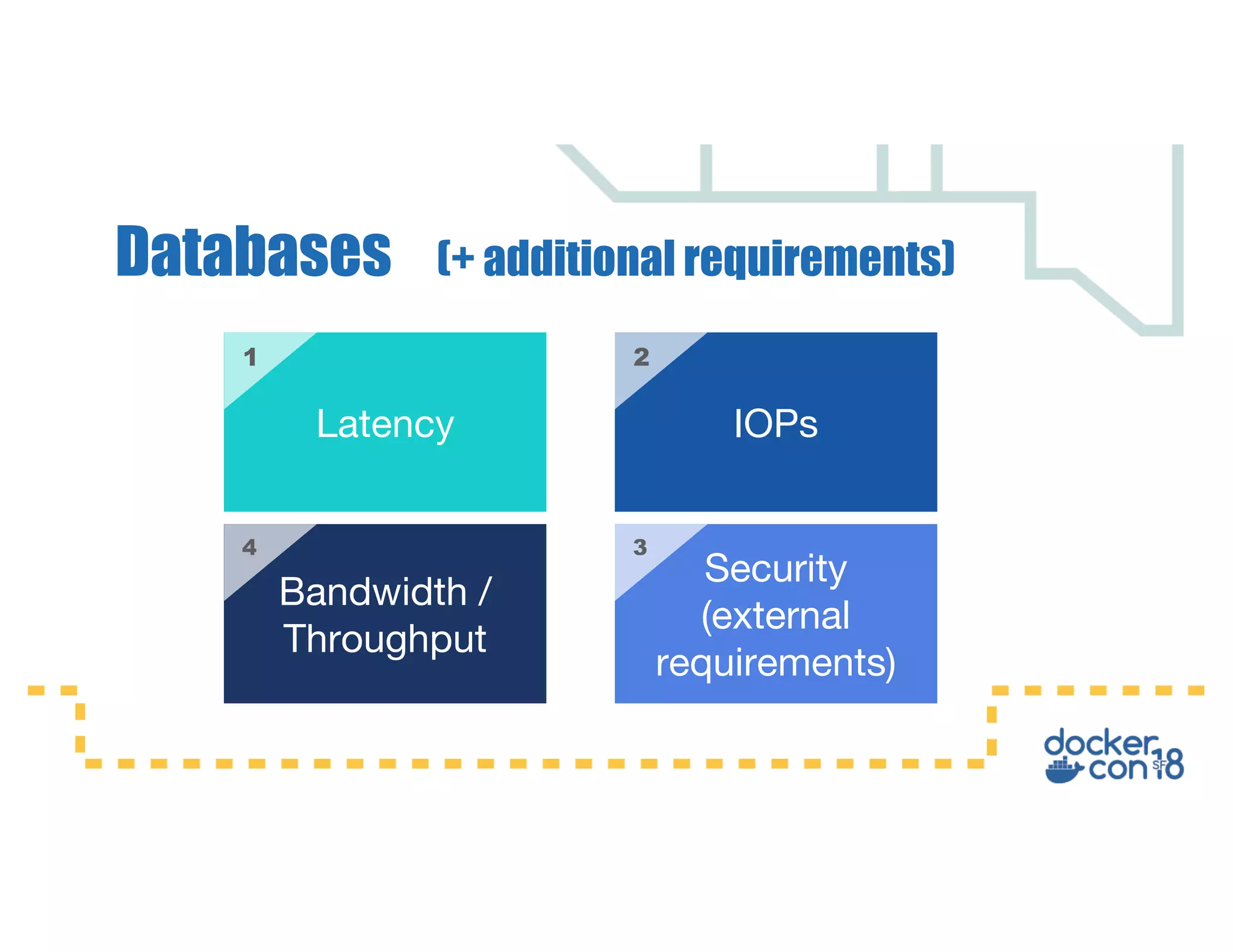
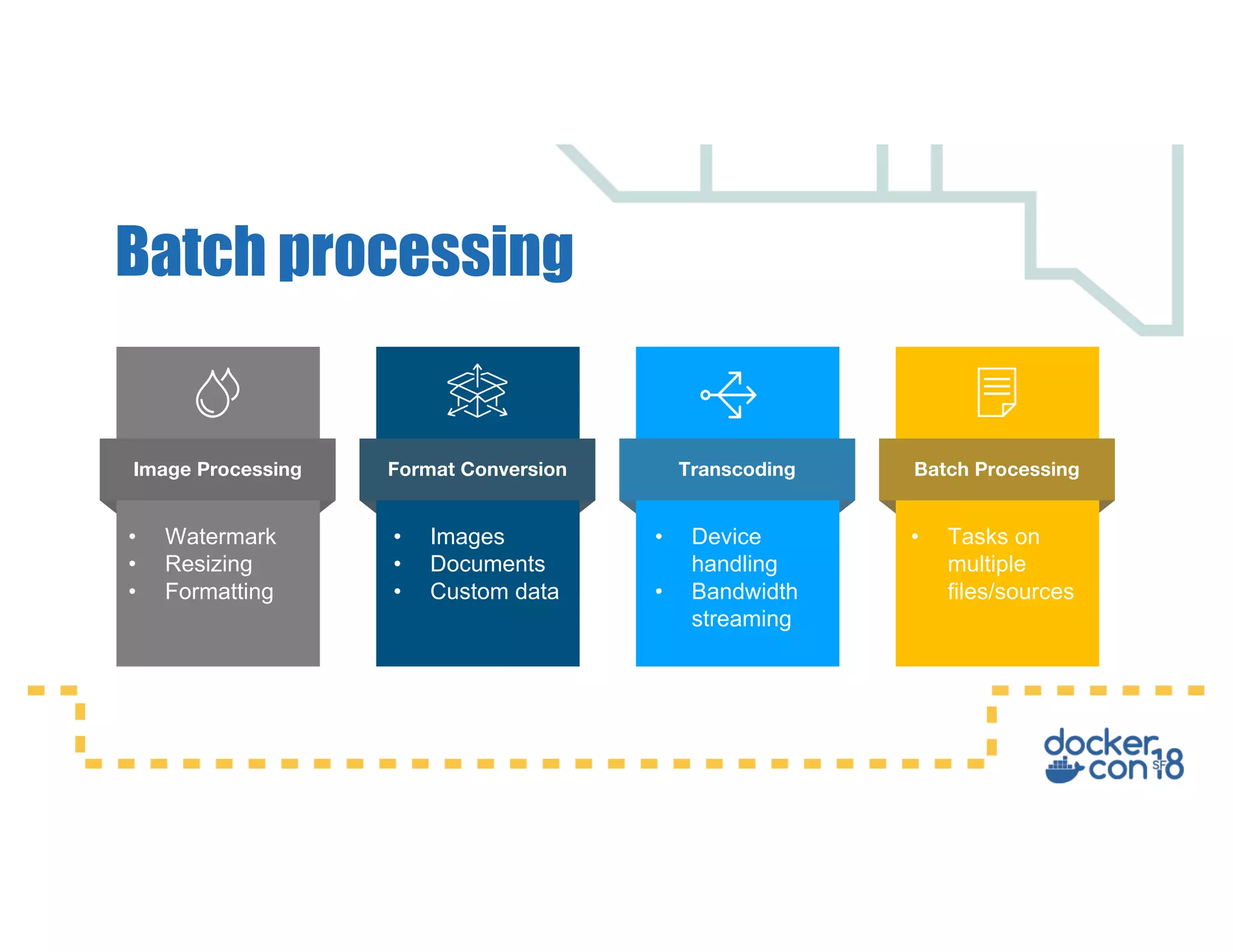
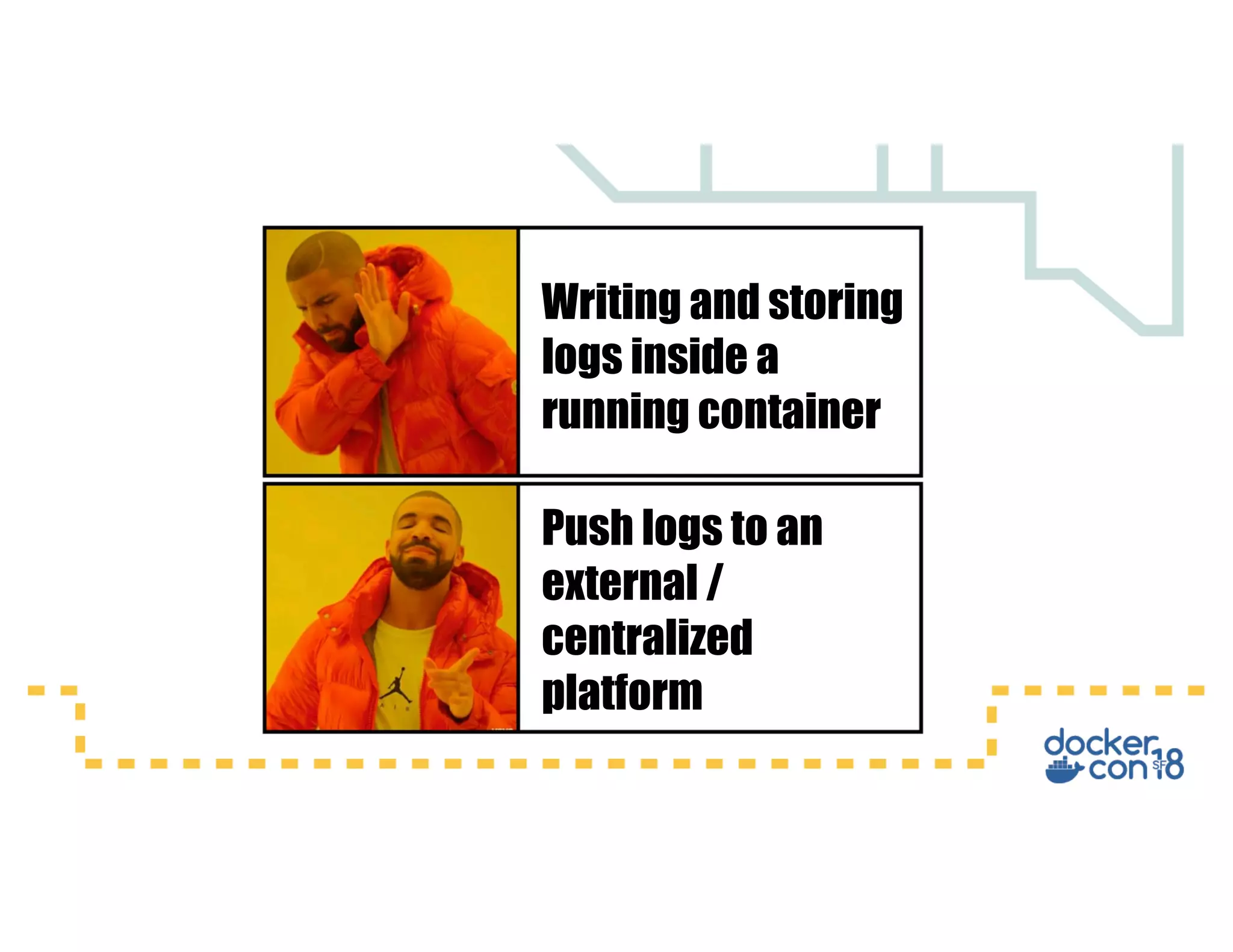
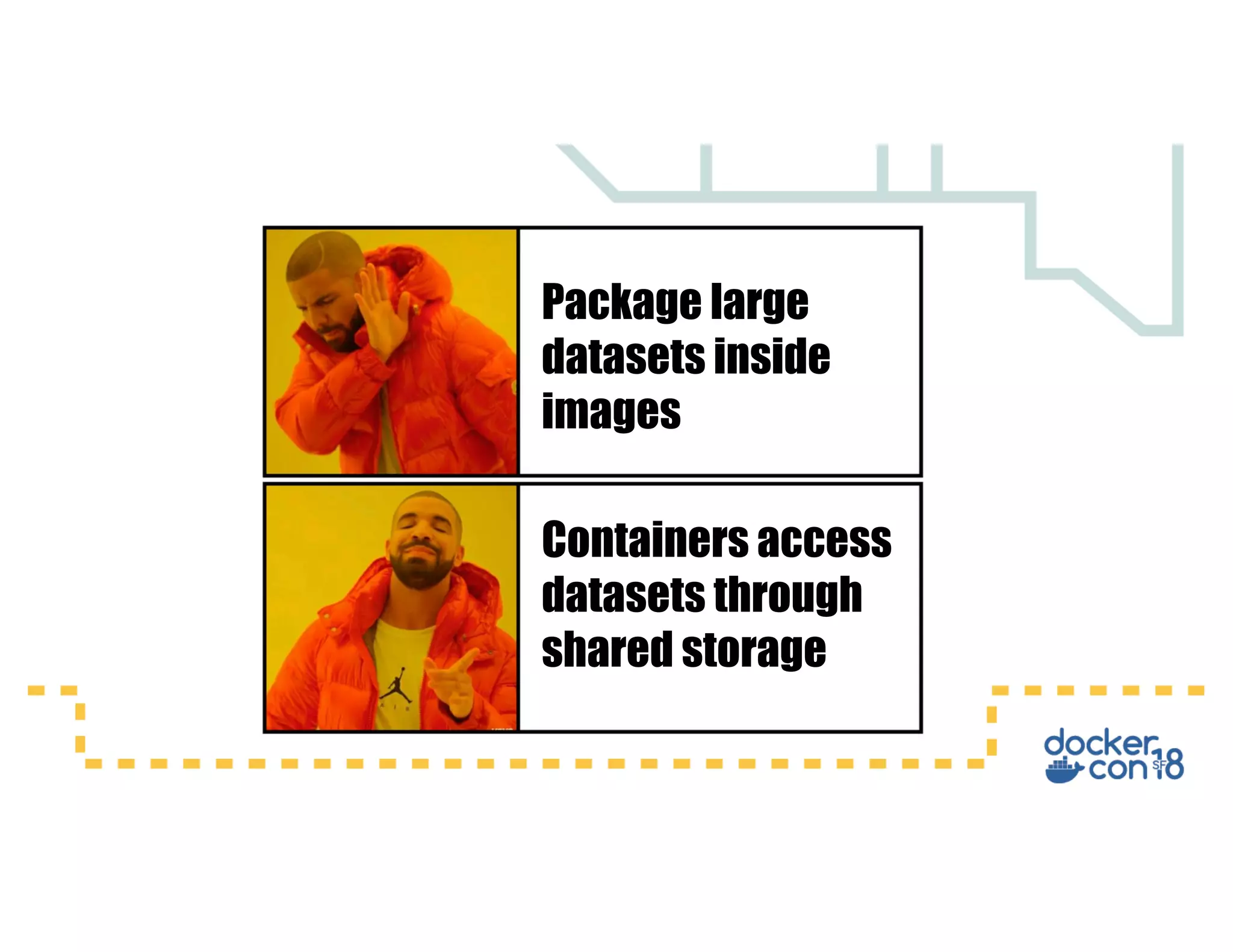
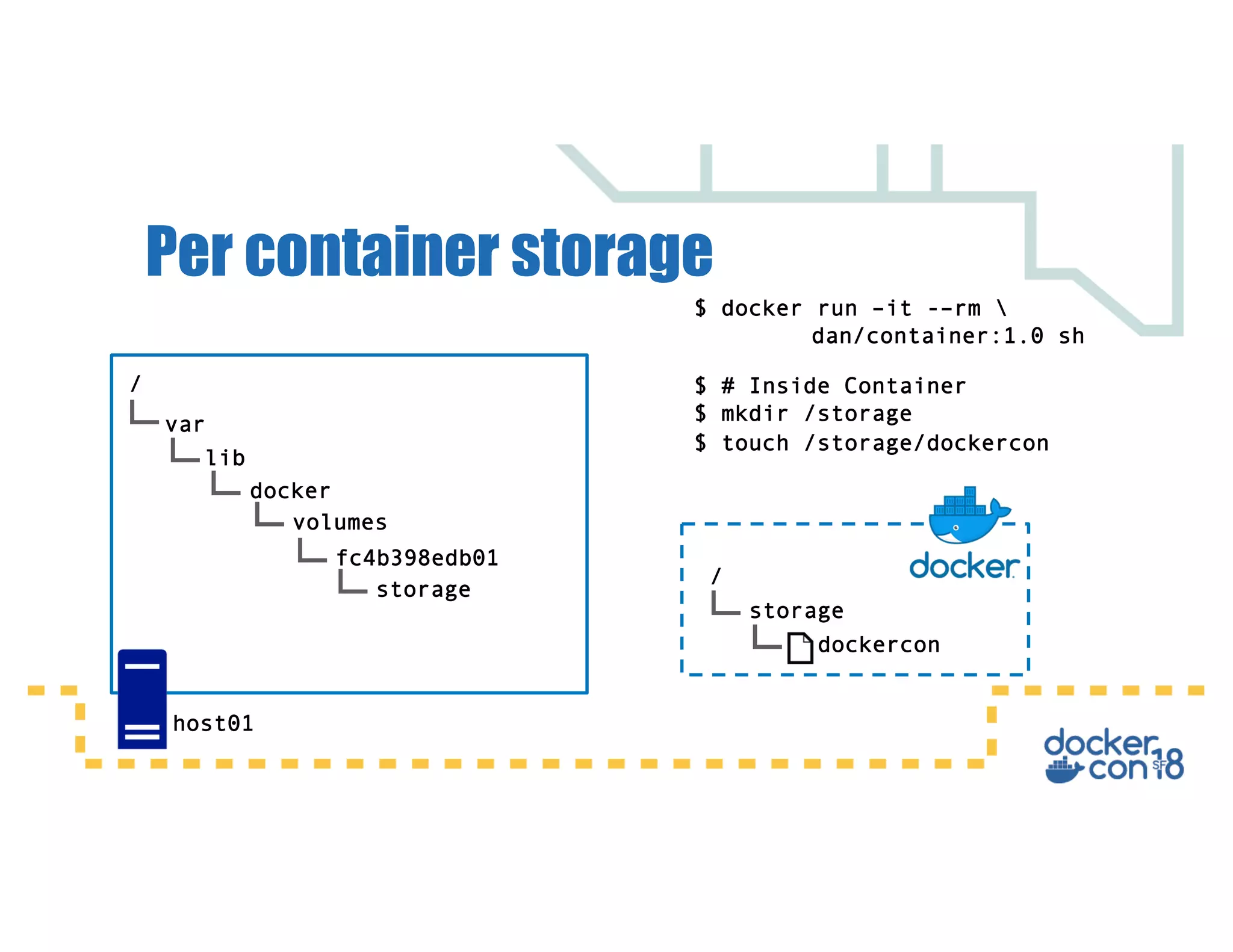
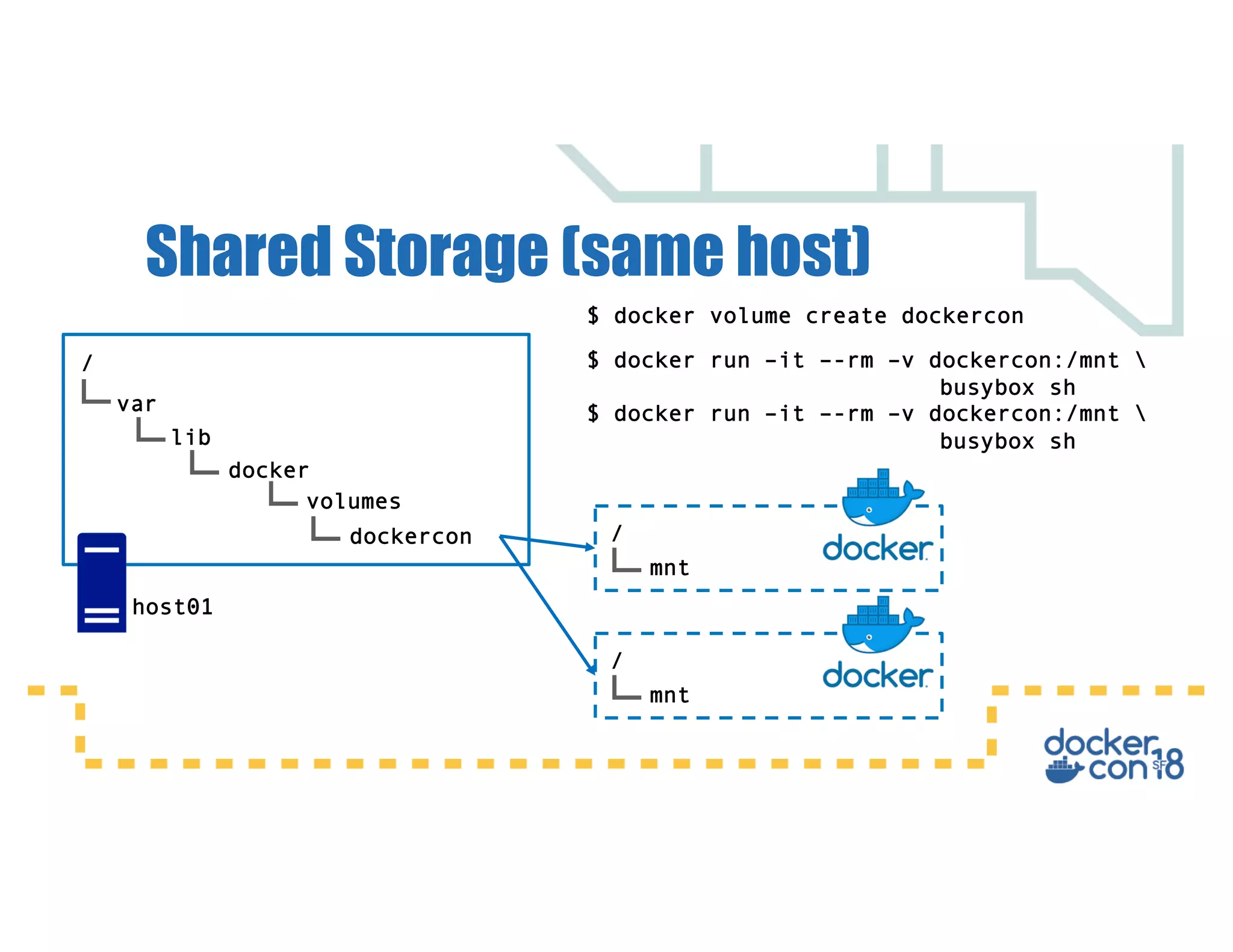
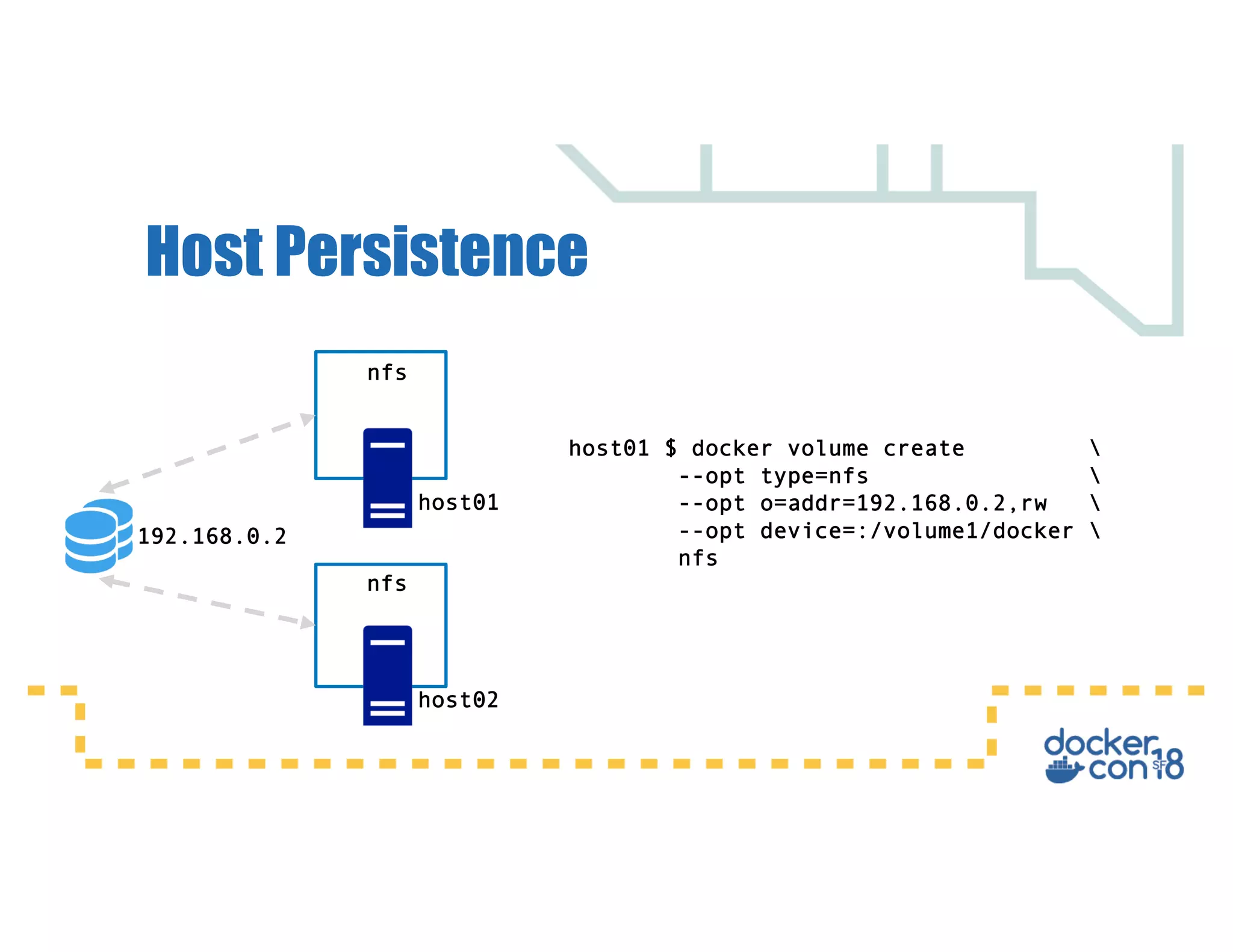
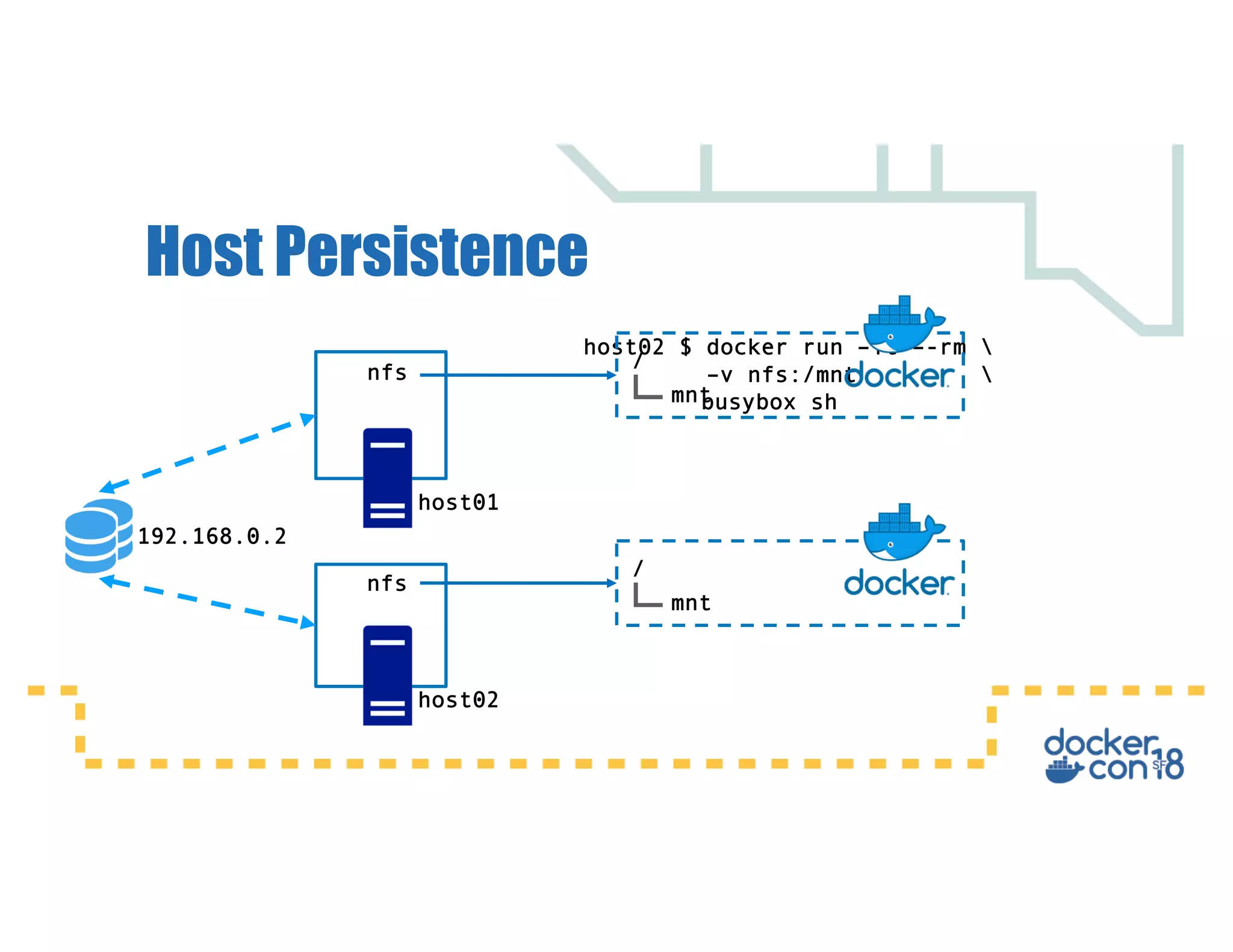
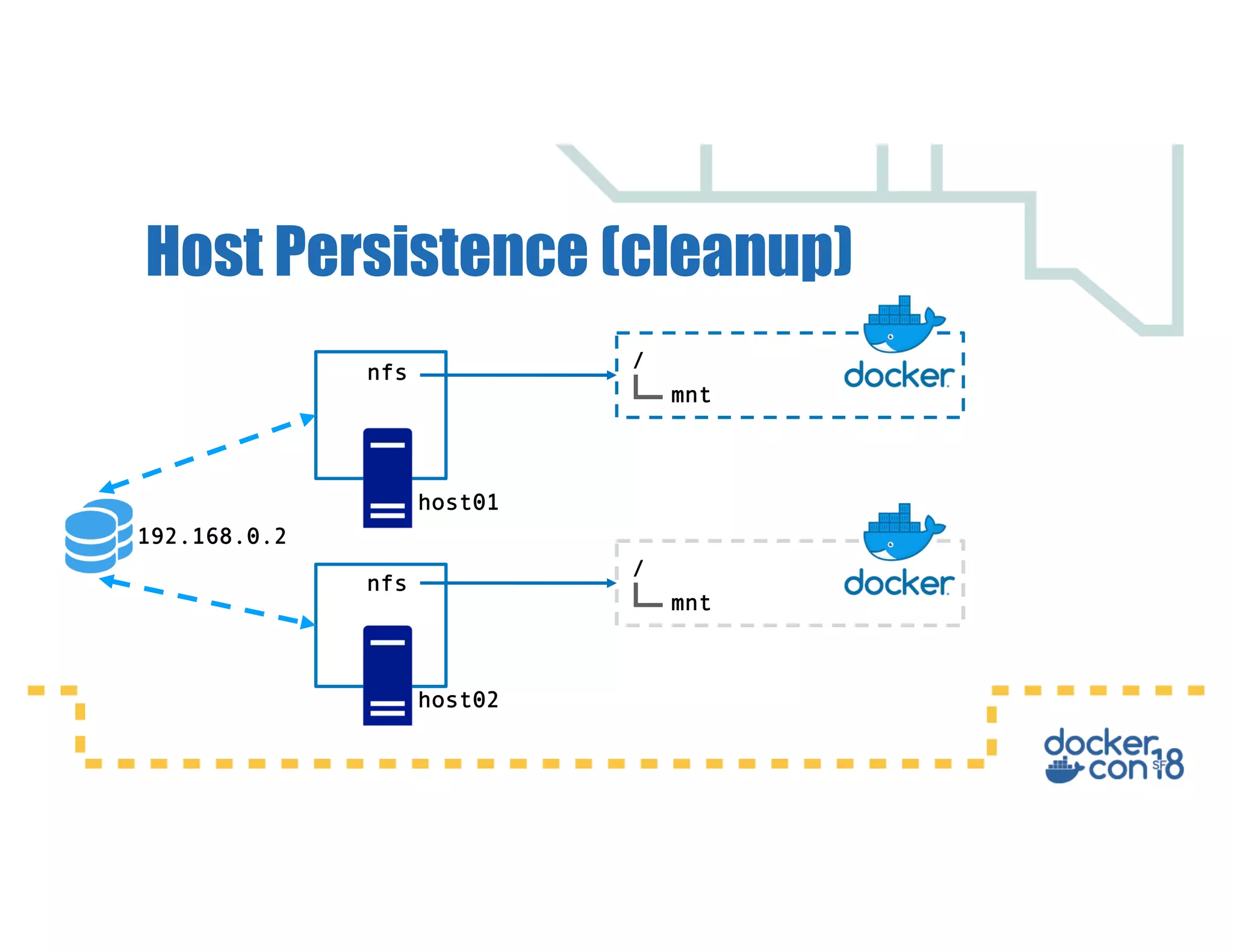
This document summarizes a presentation about Docker storage and persistent data. It discusses immutable Docker images, applications with persistent data requirements, and different approaches to persistent storage with Docker including per-container storage, shared storage on the same host, multi-host shared storage, Docker volume plugins, and orchestrating storage with Swarm and Kubernetes. Key takeaways are that shared storage allows for smaller images, efficient usage of repetitive data, and decoupling of applications and data, and that running databases in containers is acceptable if requirements for latency, IOPS, bandwidth, and security are met.























































































