Download to read offline








![Information Classification: General
Pagina 16
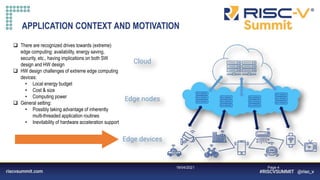
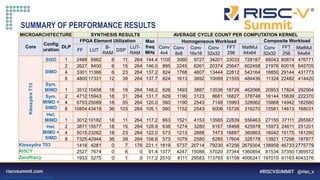
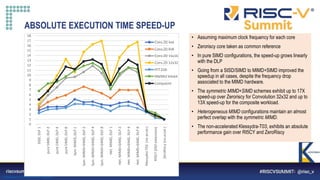
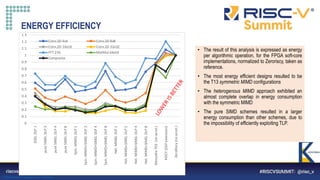
LARGER CONVOLUTION FILTERS
Core DLP
Filter (5x5) Filter (7x7) Filter (9x9) Filter (11x11)
Cycle
Cnt
X1000
T (us) E [uJ]
Cycle
Cnt
X1000
T (us) E [uJ]
Cycle
Cnt
X1000
T
(us)
E [uJ]
Cycle
Cnt
X1000
T
(us)
E [uJ]
T13 SIMD 2 52.7 362 50.6 101.2 694 97.1 165.8 1136 159.1 246.5 1689 236.6
T13 SIMD 8 24.6 179 34.4 46.1 335 64.5 74.7 543 104.7 110.6 803 154.8
T13 Sym MIMD 2 19.5 148 26.9 35.8 272 49.4 57.4 436 79.2 84.4 641 116.5
T13 Sym MIMD 8 11.8 113 28.9 19.2 183 46.9 29.8 284 72.7 42.9 408 104.7
T13 Het MIMD 2 20.5 159 28.3 37.5 291 51.8 60.2 467 83.1 88.5 687 122.1
T03 (no accel.) - 247 1120 215.5 514.8 2328 447.9 881.2 3985 766.6 1369.1 6191 1191.1
RISCY - 180 1971 252.0 385.3 4218 539.4 662.5 7252 927.5 1000.2 10949 1400.3
ZeroRiscy - 318.9 2721 226.4 674.5 5754 478.9 1129.7 9637 802.1 1697.8 14482 1205.4
• The matrix being convoluted is 32x32 elements
• The speed-up and energy efficiency trends continue as the filter dimensions grow, reaching X35 speedup over the Zeroriscy reference](https://image.slidesharecdn.com/klessydra-t-designingvectorcoprocessorsformulti-threadededge-computingcores-210419141709/85/Klessydra-t-designing-vector-coprocessors-for-multi-threaded-edge-computing-cores-16-320.jpg)



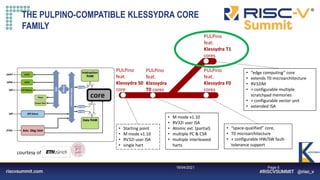
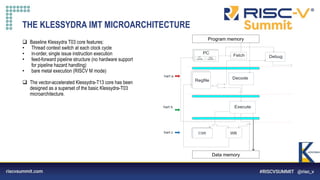
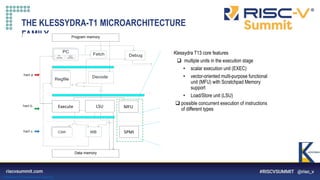
The document describes a proposed Klessydra-T1 vector coprocessor architecture designed for multi-threaded edge computing cores. It achieves a 3x speedup over a baseline core through configurable SIMD and MIMD vector acceleration schemes. Benchmark results show cycle count reductions for workloads like convolution and matrix multiplication when using the coprocessor in various SISD, SIMD, and MIMD configurations. Resource utilization and maximum frequency are also analyzed.


















































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)



