Download as PDF, PPTX









![MULIADD, MULI and ADDIADD
uint32 get_element(uint8 index) {
return
array_base[index].element1.element2
}
02002a96 <get_element>:
02002a96 47d1 li a5,20
02002a98 02f50533 mul a0,a0,a5
02002a9c 010057b7 lui a5,0x1005
02002aa0 74478793 addi a5,a5,1860
02002aa4 953e add a0,a0,a5
02002aa6 4548 lw a0,12(a0)
02002aa8 8082 ret
The code above get compiled into
the following assembly code
Rationale:
Indexing arrays of structures in C often
requires 3 instructions:
• Load immediate to get element size
• Multiplication by index to get location of
the required element
•Addition to the base address of the array
Proposed Solution:
• Create a new instruction (MULIADD)
to fuse the 3 Instructions into
a single instruction
• Similarly we can fuse mul and li to create
MULI and add and addi to create ADDIADD.](https://image.slidesharecdn.com/iakrvpresentation-210505114157/85/RISC-V-Zce-Extension-14-320.jpg)
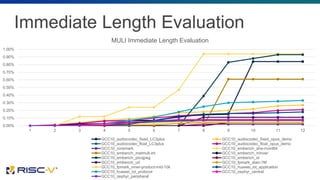
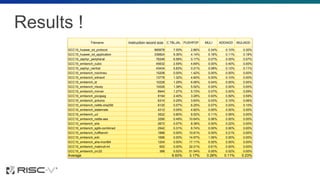




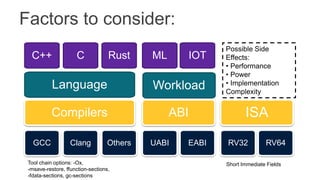
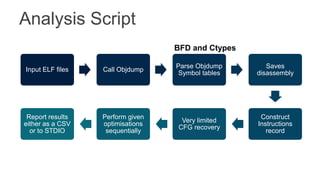
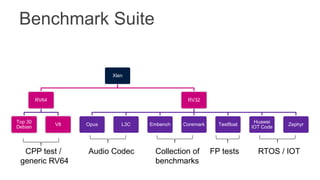
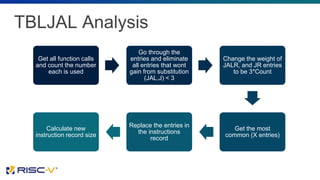
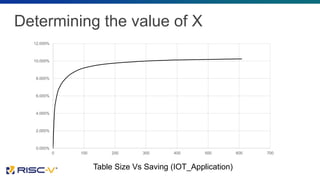
The document proposes several extensions to the RISC-V ISA to improve code size efficiency. It analyzes benchmark programs to identify optimization opportunities where common instruction sequences can be fused into single instructions. New instructions proposed include TBLJAL for table-based function calls and jumps, PUSHPOP for saving/restoring multiple registers, and MULIADD for fusing load, multiply and add instructions. Evaluation shows the proposed instructions reduce code size by up to 10% on average across benchmarks when implemented in the compiler.






















































































