Downloaded 12 times









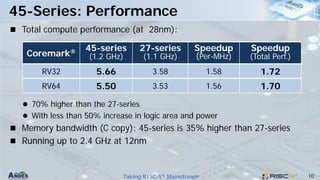
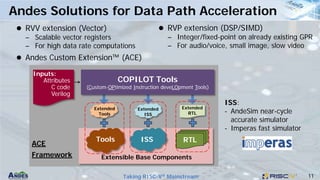


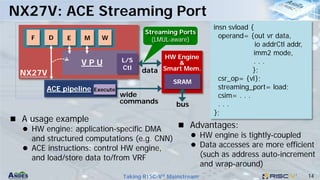

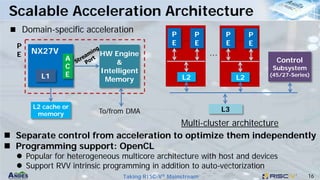



This document discusses Andes Technology Corporation's RISC-V processor IP solutions. It summarizes that Andes is a leading RISC-V CPU IP vendor that provides a portfolio of RISC-V processor cores ranging from embedded control to application processing. It also develops tools like the AndeSight IDE and provides customization services through its AndeSentry security framework and scalable acceleration architecture.














































![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)







































