Download to read offline





![Taking RISC-V® Mainstream 6
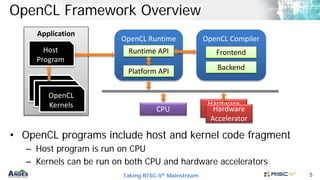
Example: Vector Addition
• A simple C program uses
a loop to add two vectors.
• The “hello world” program
to demonstrate the data
parallel programming
void vadd(float *a, float *b, float *c, int n)
{
int i;
for (i=0; i < n; i++) {
a[i] = b[i] + c[i];
}
return;
}
int main()
{
int a[100], b[100], c[100];
vadd(a, b, c, 100);
return 0;
}](https://image.slidesharecdn.com/andesopenclforrisc-v-210315173212/85/Andes-open-cl-for-RISC-V-6-320.jpg)
![Taking RISC-V® Mainstream 8
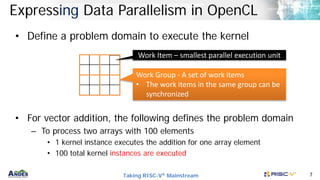
Vector Addition (Kernel)
__kernel void vadd (__global const float *a,
__global const float *b,
__global float *c)
{
int gid = get_global_id(0) ;
c[gid] = a[gid] + b[gid];
}
Function qualifier to identify
the function is kernel
Address space qualifier,
__private, __local, __global, or__constant,
to annotate the data locations
Built-in function returns the unique id for
work item](https://image.slidesharecdn.com/andesopenclforrisc-v-210315173212/85/Andes-open-cl-for-RISC-V-8-320.jpg)
![Taking RISC-V® Mainstream 9
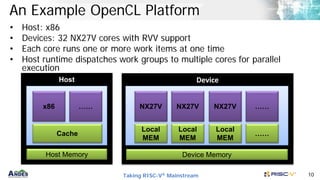
Vector Addition (Host Program)
Execute the kernel
Read result from the device
Setup kernel
Build kernel (or load binary)
Allocate memory buffer
Set the platforms and queues
int main () {
……
clGetContextInfo(context, CL_CONTEXT_DEVICES, 0, NULL, &cb);
clGetContextInfo(context, CL_CONTEXT_DEVICES, cb, devices, NULL);
cmd_queue = clCreateCommandQueue(context, devices[0], 0, NULL);
……
memobjs[0] = clCreateBuffer(context, CL_MEM_COPY_HOST_PTR,…);
……
program = clCreateProgramWithSource(context, 1, &program_source, …);
clBuildProgram(program, 0, NULL, NULL, NULL, NULL);
kernel = clCreateKernel(program, “vadd”, NULL);
clSetKernelArg(kernel, 0, (void *) &memobjs[0], sizeof(cl_mem));
……
global_work_size[0] = n;
clEnqueueNDRangeKernel(cmd_queue, kernel, 1, NULL, global_work_size, …);
clEnqueueReadBuffer(context, memobjs[2], CL_TRUE, 0, …);
……
}](https://image.slidesharecdn.com/andesopenclforrisc-v-210315173212/85/Andes-open-cl-for-RISC-V-9-320.jpg)
![Taking RISC-V® Mainstream 11
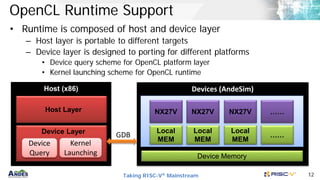
OpenCL C Extension for RVV
• Support RVV intrinsic and new built-in functions
__kernel
void vadd_rvv_cl(__global float *a,
__global float *b,
__global float *c
int n)
{
//return the index of the first element
//to be executed by a workitem
int wi = get_work_id(sizeof(float),n,0);
vfloat32m1_t vb = vle32_v_f32m1(&b[wi]);
vfloat32m1_t vc = vle32_v_f32m1(&c[wi]);
vflaot32m1_t va = vadd_vv_f32m1(vb, vc);
vse32_v_f32m1(&a[wi], va);
}
void vadd_rvv(float *a, float *b, float *c,
int n)
{
int tn = n;
while (tn > 0) {
size_t vl = vsetvl_e32m1(tn);
vfloat32m1_t vb = vle32_v_f32m1(b);
vfloat32m1_t vc = vle32_v_f32m1(c);
vflaot32m1_t va = vadd_vv_f32m1(vb, vc);
vse32_v_f32m1(a, va);
a += vl; b += vl;
c += vl; tn -= vl;
}
}
C with RVV Intrinsic OpenCL Kernel with RVV Intrinsic](https://image.slidesharecdn.com/andesopenclforrisc-v-210315173212/85/Andes-open-cl-for-RISC-V-11-320.jpg)




This document discusses OpenCL support for RISC-V cores. It provides an introduction to OpenCL and describes how it can be used for heterogeneous platforms with RISC-V cores. It outlines an OpenCL framework for RISC-V with the host on x86 and devices as RISC-V cores like the AndeSim NX27V. It also describes OpenCL C extensions for the RISC-V Vector extension and the compilation flow from OpenCL C to LLVM IR to target binaries. Current status includes passing most OpenCL conformance tests on QEMU and work ongoing for the x86+AndeSim platform.






















































































