Download as PDF, PPTX










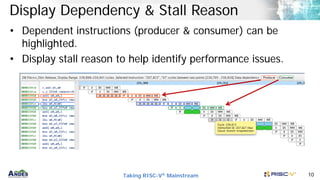

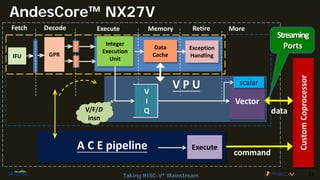




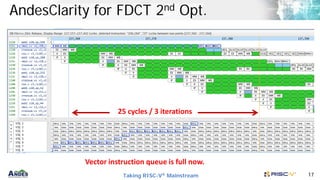








AndesClarity is a pipeline visualizer and analyzer for Andes V5 vector processors. It graphically represents instruction execution and pipeline stages with performance information. It helps optimize algorithms by identifying bottlenecks and stalls. The document provides an example of using AndesClarity to optimize a fast discrete cosine transform algorithm through four iterations. Each optimization interleaves instructions to better utilize the vector processor's functional units and reduce dependencies between iterations.



































![RPendsem_rsm[1]-1 , it is a research on 5 stages pipeline on risc v processor](https://cdn.slidesharecdn.com/ss_thumbnails/rpendsemrsm1-1-260115075908-8ec3c145-thumbnail.jpg?width=640&height=640&fit=bounds)


















































