Downloaded 26 times






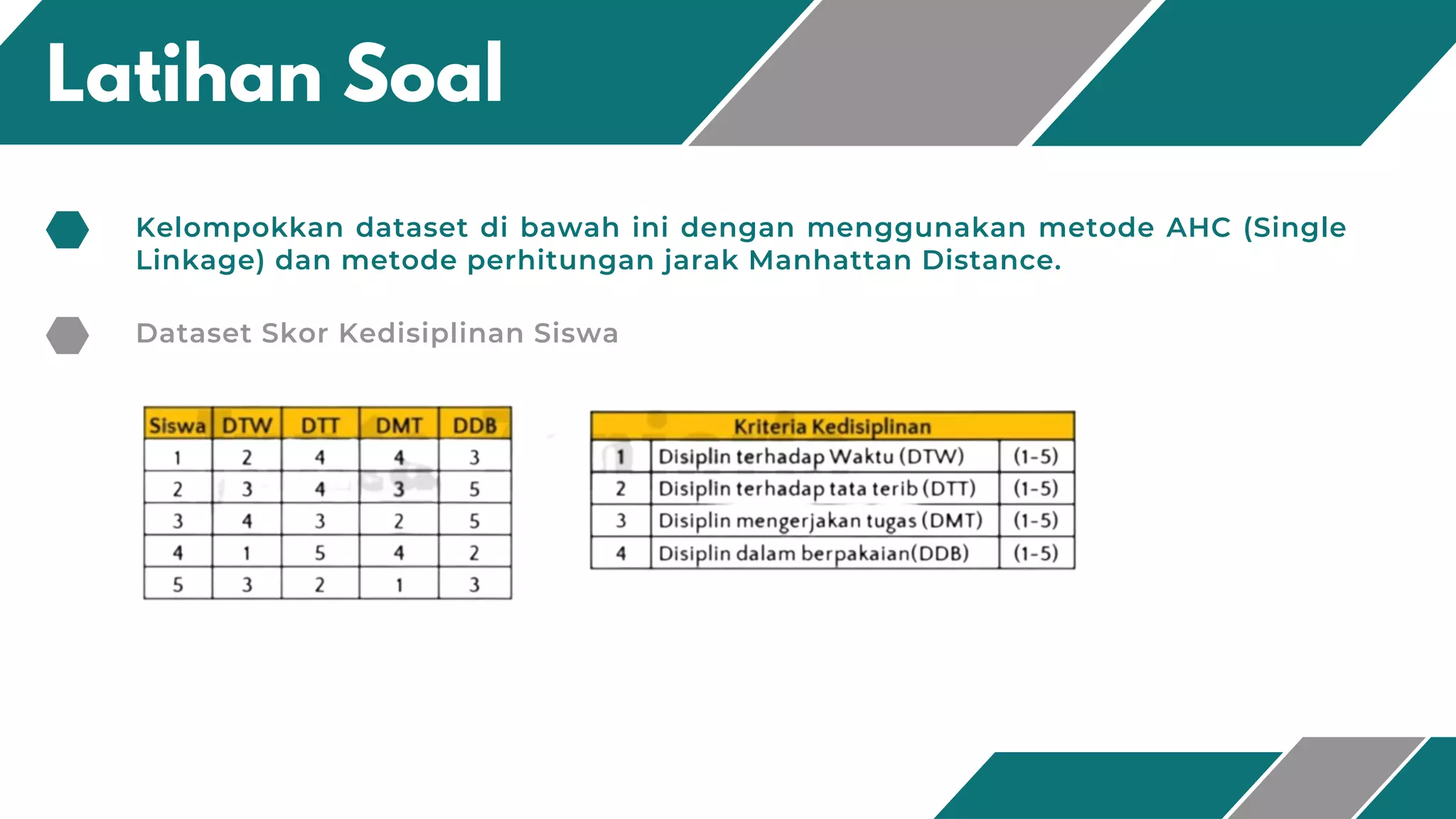













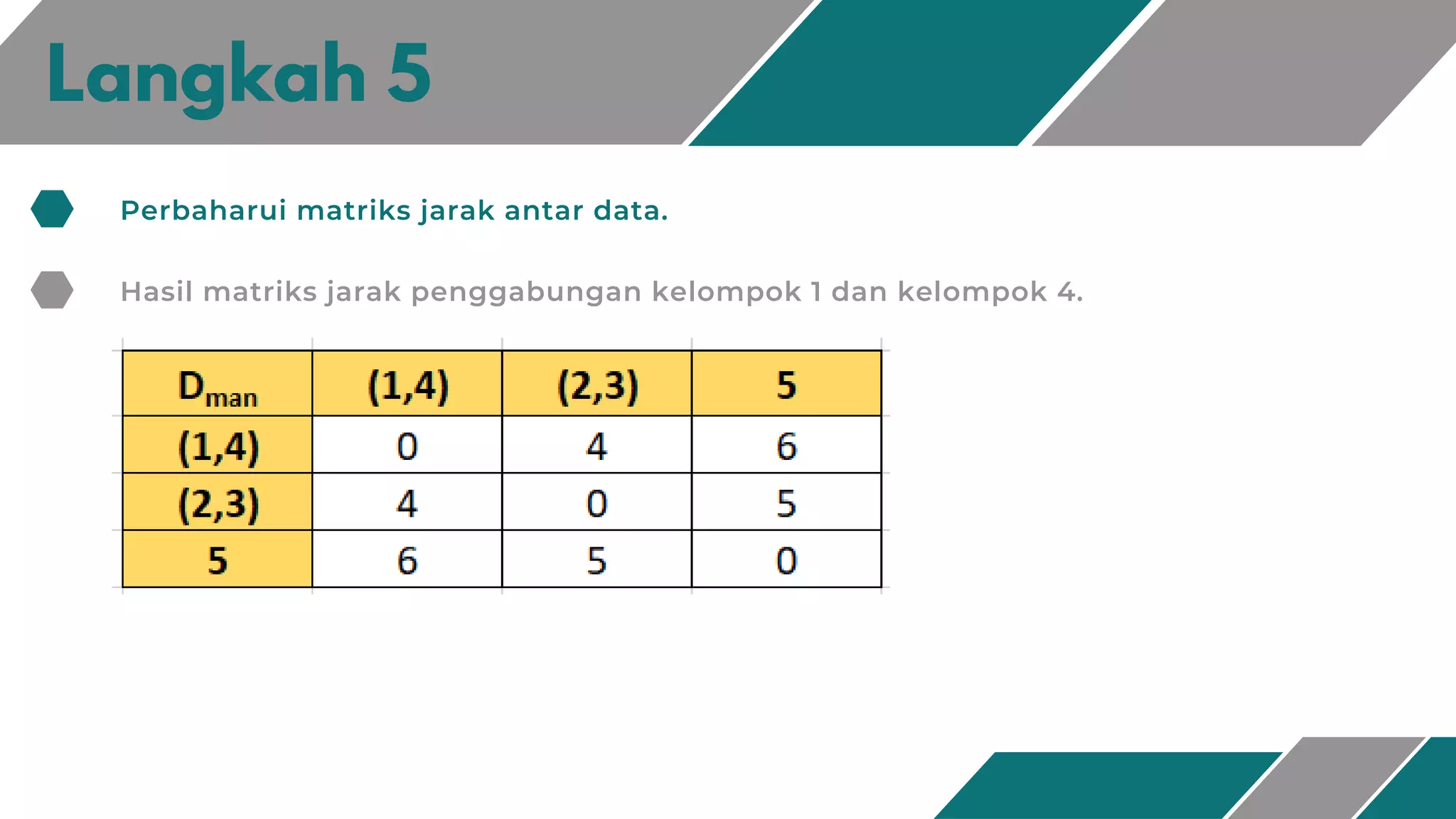




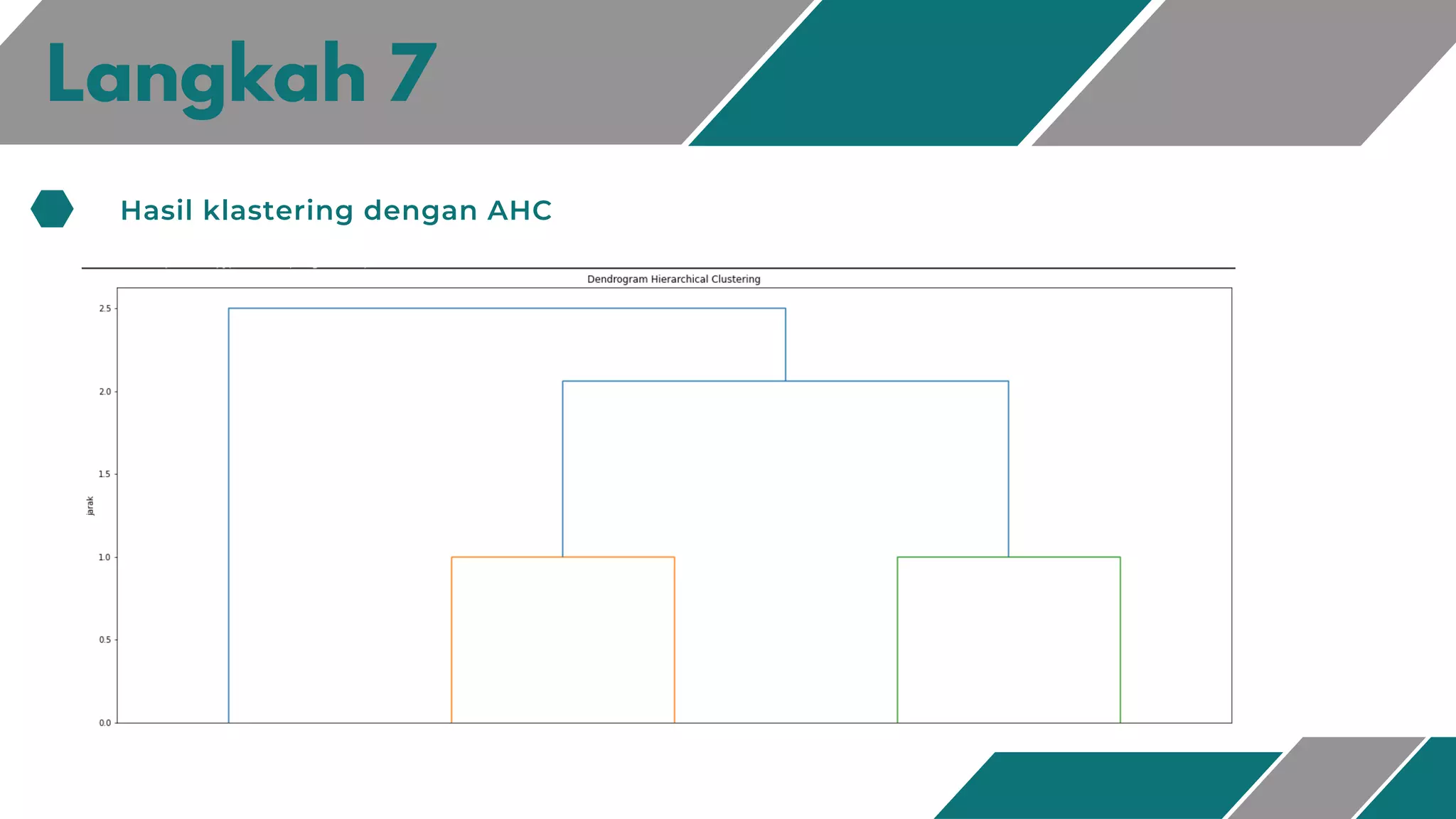


Dokumen ini membahas metode klasterisasi Agglomerative Hierarchical Clustering (AHC). AHC adalah metode klasterisasi berbasis hirarki yang membangun klaster secara bottom-up dimana setiap objek dianggap sebagai klaster dan klaster-klaster digabungkan berdasarkan kemiripan hingga terbentuk satu klaster besar. Dokumen ini juga menjelaskan langkah-langkah algoritma AHC beserta contoh penerapannya untuk mengelompokkan dataset skor ked



























































