Download to read offline
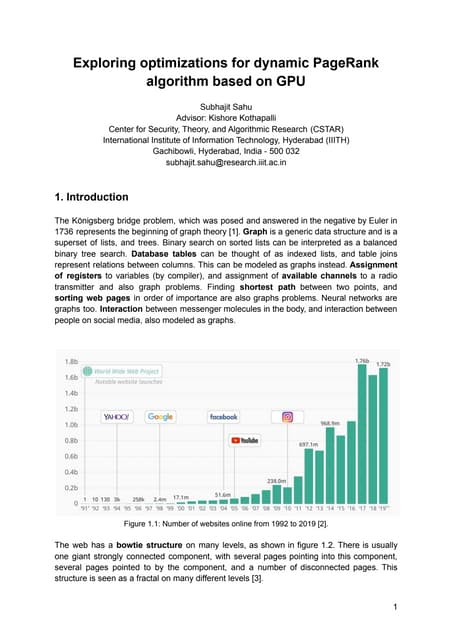
![IOSR Journal of Computer Engineering (IOSR-JCE)
e-ISSN: 2278-0661,p-ISSN: 2278-8727, Volume 18, Issue 3, Ver. V (May-Jun. 2016), PP 77-82
www.iosrjournals.org
DOI: 10.9790/0661-1803057782 www.iosrjournals.org 77 | Page
Associated Edge Weight Approach to Improve Personalized
Ranking
Ms. Pallavi G. Gaikwad1
, Mrs. M. A. Potey2
1
Post Graduate Student of Computer Department, D. Y. Patil College of engg. Akurdi, India
2
HOD of Computer Department, D. Y. Patil College of engg. Akurdi, India
Abstract: Search engine is most leading and valuable tool that collects the data which is extent and it
objectives to offer rising data being reachable to the user. Objective of personalization ranking is to improve
the tradition data search and retrieval procedure as per the user concern. Authority flow is the technique of
conveying the rating of pages for each user. Authority flow approaches like PageRank and ObjectRank can
deal personalized ranking of typed entity-relationship graphs. In entity relationship graph, the authority flow
mechanism adjusted with the provision of edge or relationship type. There are two chief processes to
personalize authority flow ranking: Node based personalization, where authority constructs since a set of
user precise nodes; Edge-based personalization, where the reputation of different edge types is user-specific.
Main concentration of the paper is on Edge-based personalization where the hybridization of ScaleRank with
clustering algorithm i.e., K Mean clustering and express that the Hybrid ScaleRank provides quick and
precise adapted authority flow ranking.
Keywords: Authority Flow, Edge based Personalization approach, Graph, Personalized ranking, ScaleRank
I. Introduction
Various recommendation and retrieval work can be suggested as proximity queries on a labeled
directed graph, with typed nodes indicating documents, terms, and meta-data, and labelled edges indicating the
associations between them. Authority residences vital role in the system by calculating reputation of an object
and authority flow is the method of expressive the rating of pages of each user. Authorities are distributed by
flow based ranking processes and entity relationship graph. The significant feature to entity relationship graph
which deal personalization to the user. In entity relationship graph, the authority flow parameter used with the
help of edge or relation type. In existing system the authority flow ranking can be done with diverse authority
flow methods like PageRank, ObjectRank. Two personalization approaches are castoff for personalize authority
flow of ranking i.e. 1). Node based personalization and 2). Edge-based personalization. Numerous work [1], [2],
[3], [4], is completed on Node based personalization. Main focus is on Edge-based personalization. Using
adapted weight assignment vector (WAV) which deals a weight to each edge (relationship) category. Leading
challenges of personalized ranking is how to identify users search result and another challenge is how to
brilliantly act these interest in the retrieval system to grow search results. The objective of personalized ranking
is to reflect the users search choices and concern in the search process to suggest each user with the result that
are most suitable to his comforts.
II. Literature Review
Hess C, Stein K et al. [5] have presented their work as to present the framework for document rankings
with a widespread personalization scheme. The personalization is through the second source of material also the
document network: a trust network. The trust valuations among authors of documents are used in two
techniques: first, the challenging users trust in the author effects the reflectivity of documents inscribed by this
author. Secondly, the weights of positions are converted by the challenging users trust in the citing author.
Sayyadi H. et al. [6] have presented their work as to cover a social media dataset to achieve the
relations among authors, blog posts, and categories (topics) of the posts. Then relate personalized authority flow
based ranking developments based on the random surfer model. Valuate their personalization processes over a
extensive study on a range of virtual users whose likings are defined created on intuitive criteria. Their
calculation shows that the exactness of their personalized approvals ranges from good to very good for a
majority of users, and beats workable baseline methods.
Gou L., Chen H. et al [7], have presented their work as to present Social Network Document Rank
(SNDocRank), a new ranking outline that imitates a searchers social network, and connect to video search.
SNDocRank gives traditional tfidf ranking with our Multi-level Actor Similarity (MAS) algorithm, which
procedures the similarity among social networks of a searcher and document owners. Results from their
calculation study with a social network and video data from YouTube illustrates that SNDocRank deals search
results more relevant to user’s reliefs than other traditional ranking procedures.](https://image.slidesharecdn.com/k1803057782-160705043745/85/K1803057782-1-320.jpg)
![Associated Edge Weight Approach to Improve Personalized Ranking
DOI: 10.9790/0661-1803057782 www.iosrjournals.org 78 | Page
Kashyap A., Hristidis V. et al [8] have offered their work as to enlarge SonetRank acts to personalize
the Web search possessions based on the mutual relevance feedback of the users in related groups. SonetRank
customize and keeps a rich graph-based model, termed Social Aware Search Graph, containing of groups, users,
queries and results connect over information. SonetRanks personalization scheme interests in a principled way
to control the following three signals, of decreasing strength: the personal document choices of the user, of the
users of her social groups linked to the query, and of the other users in the network. SonetRank also uses a novel
method to extent the amount of personalization with respect to a user and a query, created on the query-specific
fullness of the user’s social profile. Assess SonetRank with users on Amazon Mechanical Turk and show a
major enhancement in ranking related to state-of-the-art skills.
Hanze Liu, Orland Hoeber et al. [9] have present their work as to growth the search result. Web search
personalization has been offered, whereby the prosperities and beloveds of distinct users are recognized and
used to upset the results of their subsequent searches. A common method is to produce vector-based models of
searchers profits, and re-rank the search results constructed on the match of the documents to these models. So a
new approach is offered to automatically decide and reweight major dimensions in vector-based models in order
to advance the personalized order of Web search consequences.
Following section discuss about the related work:
1. Ranking with PageRank algorithm:
PageRank [10] is a scheme for rating the reputation of webpages quantitatively and instinctively using
a link structure. PageRank framework comprise node with and without output links. PageRank execution reside
of five steps: First, URLs are converted into special integers and stored into the database as hyperlinks with this
integer IDs to organize each webpage. Then the classification in link structure can takes place with these
distinctive IDs. Then remove all the dangling links from the database. Then make the primary assignment of
rank and start the iteration. Lastly, add the dangling links back to the database. PageRank criteria are: cleanness
and significance of content, number of visits and time spend on page. For ranking webpages PageRank
algorithm is used.
2. Ranking with ObjectRank Algorithm:
Object Rank is a keyword investigative algorithm. Hristidis et al. [11] mention ObjectRank algorithm
is used for bibliographic database. ObjectRank system contains two models: (1) Offline mode: Here
approximation is over by a materialized sub graph, this can be pre-computed in this mode for support the online
query, (2) Online mode: Once the query achieves, ranking algorithm starts working. The output expanded from
this algorithm is a bin of terms. BinRank algorithm is used for the giving of this bin of terms. BinRank [29] is an
algorithm which approximate ObjectRank using an approach inspired by a traditional query processing. The
objective in construction term bin is that these bins will control the implementation time. The weakness of this
system is that the computation is very expensive.
3. Ranking on Entity Relation Graph:
Authorities are supplied by flow based ranking method and entity relationship graph. The key feature
of entity relationship graph which proposal of personalization to the system. In entity relationship graph, the
authority flow factors are familiar with the help of edge or relation type. Here authority can be formulates in two
techniques from a query and a set of objects and range through edges. In an entity relationship graph, all queries
first analyze a base set and from the base set, the authority is spread to the whole graph. For authority flow
personalization in entity relationship graph ObjectRank [11] and HubRank [12], [13] algorithms are used.
In ObjectRank, first determines a base set that cover set of objects, form nodes from objects allowing to
the entity type and edges are formed on the origin of edge type. HubRank is a innovative system presented for
fast and dynamic space well-disciplined familiar search in entity relation graph. A personalized PageRank
vector (PPV) [13] is used for the main determination i.e. personalization. PPV runs a ranking appliance which
constructs a personalized view of distinct user. The PPV can comprise of a hub node (pages indicating to many
essential pages) which is addressed on query logs, elected words and other entity nodes for PPVs. The problem
in this system is that distance scheme is not used and cannot implement distance scheme in entity relationship
graph.
4. Ranking with DataApprox and SchemaApprox:
The above methodologies are not capable for distance method so presenting two approximation
algorithms which is centered on distance method which are DataApprox [12], [14], and SchemaApprox [12],
[14]. SchemaApprox [12], [14] is diverse at schema level and need of a schema level matric. For electing m-
candidates, diminish the distance among different candidates in schema level matric consuming Euclidean
distance. For choosing m-candidates, uses objective functions which lessen the distance between the different](https://image.slidesharecdn.com/k1803057782-160705043745/85/K1803057782-2-320.jpg)
![Associated Edge Weight Approach to Improve Personalized Ranking
DOI: 10.9790/0661-1803057782 www.iosrjournals.org 79 | Page
candidates at the data graph level. Both DataApprox [12], [14] and SchemaApprox [12], [14] are too costly to
facilitate interactive query response.
To reduce the expense there arise the model ScaleRank with binary search [12], [14]. ScaleRank is an
approximation of DataApprox. The ScaleRank algorithm has input which is a weight assignment vector (WAV)
and production are top K objects based on authority score. ScaleRank which preserves a repository and which
contain of WAV and ranking vector for each candidate.
III. Proposed System
In proposed system the hybridization of ScaleRank algorithm with clustering algorithm is discussed.
1. Hybrid ScaleRank algorithm:
The architecture of the ScaleRank system [14] which is an valuation of DataApprox; the algorithm
is in below sections. Fig.1. shows the architecture of Hybrid ScaleRank. Main contribution of this proposed
system is hybridization of ScaleRank with Clustering algorithm such as K-mean.
Fig.1. System Architecture
In proposed system main attention is on Edge weight personalization. The above system architecture
contain Query as input or weight as input. Then select m candidates from the repository which is based on
distance method. Main purpose behind this proposed system is to obtain edge weight and produce Top K
documents. After selecting M candidates use Depth First Search method to navigate nodes. In that current
nodes are navigated and outage will be achieved. Similarity Index function is used to analyze the weight
assignment vector (WAV). Weight is achieved in this function and delivered to term weight. With the help of
Term Processing it proceeds the Term frequency (tf) and Inverse Document Frequency (idf) of that weight. That
weight is transient to function and get the cosine similarity which is return in Sim function. Cosine matrix has
value between [0, 1]. Then by calling the cosine similarity function it proceeds the cosine sim values, that sim
values is reflect for clustering if that values is less than 1, considered as that node to be high i.e. relevant node.
In K-Mean created on the distance value, nodes are aggregated. Distance factor is applied to ScaleRank
algorithm. ScaleRank produces Top K results or objects. Consider one example, suppose we have n no. of
documents and that are connected to each other. Here documents are nodes and connection between nodes are
edges that edges have some weight is assigned. Node traversal is done and associated edge weight is calculated.
By using distance it gives Top visited documents.
A personalized WAV ϴq
is the input; the top k objects are the output created on the personalized
authority score. ScaleRank keeps a source of M candidate rankings. WAV ϴq
for each candidate ranking, and
Rcand are its ranking vector stored. Given ϴq, Candidate Ranking choice m candidate from the M in the source.
Place a certain on m candidates since m can influence the running time. ScaleRank then recognizes an operative
result to DataApprox and regulates β1,…., βm, the best method to combine these m rankings to considers the
approximation . of . The top K objects are made by top k algorithm.
The input of ScaleRank algorithm is WAV of a solo object, Elect m-candidate and finds the top K
objects on personalized authority flow. The main highlight of this algorithm is that m-candidates are elected
with respect to the WAV. ScaleRank algorithm is also identified as hybrid algorithm because it resolves](https://image.slidesharecdn.com/k1803057782-160705043745/85/K1803057782-3-320.jpg)
![Associated Edge Weight Approach to Improve Personalized Ranking
DOI: 10.9790/0661-1803057782 www.iosrjournals.org 80 | Page
SchemaApprox [1] distance in the first stage and in the next stage this algorithm resolves DataApprox [12]. But
doesn’t mean that ScaleRank algorithm evaluates SchemaApprox, this only estimated DataApprox. ScaleRank
possess a repository of m-candidate rankings. WAV and ranking vector are kept for each user.
2. Appearing candidate rankings in the source:
Smartness of calculation is affected by set of ranking in the source. For each user’s WAV, pre-compute
rankings. This is not feasible then the number of users may reserve varying their WAVs. A usual way to happen
candidate ranking is to return a grid to characterize all possible weight transfer in ϴ. So yield M candidate
rankings by intuitively producing the values of ϴ; each candidate can be measured to agree to instinctively
certain point of the grid. The random way deals good constant attention of the grid. For each candidate ranking i
in the source, its weight assignment vector and its ranking vector are materialized. The source can be
set .
3. The candidate rankings chooser:
Select m best candidate rankings among the M candidate’s rankings in the source. For to outflow the
extreme cost of linking all candidates in the source, and use the best candidates in the source to return the
mutual ranking vector. Therefor process Euclidean distance || between and each candidates .
4. Process of Hybrid ScaleRank Algorithm:
ScaleRank processes binary search to identifies the minimum with upper bound u = 1 and l = 0. The
search continue until |u-l| < T, where is the user defined accuracy state. Given the candidate rankings S, the data
graph G, the query weight assignment , δ is the whole value of the alteration among two items of the two as
Fig.2. Hybrid ScaleRank Algorithm[1]
transition matrices, it is in series [0; 1] and accuracy state T for δ, working of ScaleRank algorithm as
above.
The algorithm ScaleRank achieves the minimum such that the optimization problem, and provisions
the vector which profits min _δ in Feasibility algorithm. The while loop is generally applied for around 10 times
if we choice accuracy requirement = 0.001. The Feasibility method in algorithm clarifies the Hybridization of
ScaleRank Algorithm with clustering algorithm such as k-mean algorithm which is used for regression to elect
nearest distance among edges.
5. Difficulty of the Feasibility Problem:
Hybrid ScaleRank is express in feasibility function deprived of using linear Programming (LP)
problem. There are |E| non zero matrix proceedings, where |E| is the number of edges in the graph. Recall that m](https://image.slidesharecdn.com/k1803057782-160705043745/85/K1803057782-4-320.jpg)
![Associated Edge Weight Approach to Improve Personalized Ranking
DOI: 10.9790/0661-1803057782 www.iosrjournals.org 81 | Page
is the number of candidate rankings and T be the accuracy state for the LP problem. The binary search to
achieve accuracy condition takes at most [log2 ( )] iterations.
IV. Experimental Evaluation
A. Mathematical Model:
The mathematical model is a explanation of a system by mathematical concepts. The method of
developing a mathematical model is then term as mathematical modelling. Let S is a system used in system
development. The system is signified as: S = {I, F, O}
Where,
I = input as WAV
F = Ranking Function (Hybrid ScaleRank algorithm)
O = output as Top k objects
F is ranking function known as:
(s)[i, j] = ( [ i, j] [ i] ) [i] ) …(1)
(s) is transition matrix and is ranking vector, constant, corresponding transition matrices,
Ranking Vector R =
Sub matrix is defined is defined as follows:
[i, j] ={ if ( ) exists …..(2)
Otherwise
Here, α ( denotes the weight assignment for . OutDeg is the number of
outward edges from page , of type .
The input is a personalized WAV ; the production are the top K objects created on the personalized
authority score. ScaleRank reserve a source of M candidate rankings. For each candidate ranking ϴcand
, and its
ranking vector Rcand, are stored. Given ; the candidate ranking picker chooses m candidate rankings from the
M in the source [3]. ScaleRank then realizes an operative result to DataApprox and normalizes β1,…,βm the best
method to associate these m rankings to determine the approximation { . Of . }
Finally a top K algorithm is used to produce the Top K object.
B. Datasets:
In proposed system DBLP [15] and CiteSeer, Amazon product co-purchasing datasets [16] are
used. CiteSeer dataset and manually created datasets are associate with Hybrid ScaleRank. The DBLP computer
science bibliography offer a complete list of research papers in computer science. Bibliographic databases are
obstinately used to review authority flow Ranking.
DBLP should hold over a varied range of data sets since the DBLP graph grasps the typical power
law edge association of many real world graphs. The DBLP insurances the metadata of over 1.8 million
publication, written by over 1 million authors and numerous thousands of journal or conference proceeding
series, it include Nodes: 317080, Edges: 1049866.
Amazon product co-purchasing network was collected by crawling Amazon website. It is formed on
user or customer who contributed this item also contributed features of Amazon website. If product i often co-
purchased with product j. The graph holds directed edge from i to j.
C. Result:
DBLP and CiteSeer, Amazon product co- purchased data crawled to form data graph that holds
nodes as object and links as Edges. It shows the co-authorship relationship. In this two authors may be related or
linked if they together issue at least one paper, publishing place is conference or Journal and also same as like m
Author relationship, Conference is complete. If two author might publish at same conference then they are
linked. That Co-authorship relationship is presented as on creating graph of their relationship. By consuming
Depth first search (DFS) search started and nodes are visited. On the visited node each node will be iterate.
Analyze the edge between starting node and visited node, that edge and search query either Author or
Conference. Each edge has distributed specific weight i.e., Weight assignment vector. In Amazon dataset it is
formed on user or customer who contributed this item also contributed features of Amazon website. If product i](https://image.slidesharecdn.com/k1803057782-160705043745/85/K1803057782-5-320.jpg)
![Associated Edge Weight Approach to Improve Personalized Ranking
DOI: 10.9790/0661-1803057782 www.iosrjournals.org 82 | Page
often co-purchased with product j. The graph covers directed edge from i to j. The sum of the normalized
ranking scores of the Top k pages compare with Existing system and proposed system. K ranges from 10 to
1500, for data graph with 1707898 nodes. X axis gives the delta values, and Y axis gives the Top k objects. In
creation of proposed system, considers Top K pages in all certain candidate rankings. This way, we do Not
Undervalue the outcome of main pages from any selected candidate rankings.
Fig.3. Result of Proposed Hybrid System for Edge Weight
V. Conclusion
This paper advanced tentative result of ScaleRank for the determination of ranking on entity graphs
with edge-based personalization. Collective tests on the DBLP and CiteSeer, Amazon product co-purchasing
data graph have presenting that ScaleRank is well equipped and has good value. By using ScaleRank algorithm
get firm and exact personalized authority flow ranking.
In future make ScaleRank faster, exact to deal with social networking problems. This system is
beneficial for students, researchers and authors, Ecommerce, Social Networking application while their research
work.
References
Examples follow:
Journal Papers:
[1] Amjad, Tehmina, et al. “Topic-based heterogeneous rank.” Scientometrics (2015): 1-22.
[2] Gupta, Manish, Amit Pathak, and Soumen Chakrabarti. “Fast algorithms for top k personalized page rank queries.” Proceedings of
the 17th international conference on World Wide Web. ACM, 2008.
[3] Haveliwala, Taher H. “Topic-sensitive pagerank: A context-sensitive ranking algorithm for web search.” Knowledge and Data
Engineering, IEEE Transactions on 15.4 (2003): 784-796.
[4] Hristidis, Vagelis, Heasoo Hwang, and Yannis Papakonstantinou. “Authority-based keyword search in databases.” ACM
Transactions on Database Systems (TODS) 33.1 (2008): 1.
[5] Hess, Claudia, and Klaus Stein. “Personalized document rankings by incorporating trust information from social network data into
link-based measures.” Proceedings of the IJCAI 2007 Workshop on Text Mining and Link Analysis.Vol. 103. 2007.
[6] Sayyadi, Hassan, et al. “Challenges in personalized authority flow based ranking of social media.” Proceedings of the 19th ACM
international conference on Information and knowledge management. ACM, 2010.
[7] Gou, Liang, et al. “SNDocRank: document ranking based on social networks.” Proceedings of the 19th international conference on
World Wide Web. ACM, 2010.
[8] Kashyap, Abhijith, Reza Amini, and Vagelis Hristidis. “SonetRank: leveraging social networks to personalize search.” Proceedings
of the 21st ACM international conference on Information and knowledge management. ACM, 2012.
[9] Liu, Hanze, and Orland Hoeber. “A luhn-inspired vector re-weighting approach for improving personalized web search.”
Proceedings of the 2011 IEEE/WIC/ACM International Conferences on Web Intelligence and Intelligent Agent Technology-
Volume 03. IEEE Computer Society, 2011
[10] Heasoo Hwang, Andrey Balmin, Berthold Reinwald and Erik Niikamp, “BinRank: Scaling Dynamic Authority Based Search using
Materialized Sudgraph”, IEEE International Conference on Data Engineering, pp. 66-77, 2009.
[11] Balmin, Andrey, Vagelis Hristidis, and Yannis Papakonstantinou. “Objectrank: Authority-based keyword search in databases.”
Proceedings of the Thirtieth international conference on Very large data bases-Volume 30. VLDB Endowment, 2004.
[12] Hristidis, Vagelis, Yao Wu, and Louiqa Raschid. “Efficient Ranking on Entity Graphs with Personalized Relationships.”
Knowledge and Data Engineering, IEEE Transactions on 26.4 (2014): 850-863.
[13] Soumen Chakrabathi, “Dynamic Personalized PageRank in Entity Relation Graph”, International World Wide Web Conference
Committee, pp. 571-580, 2007.
[14] Varghese, Tinku, and Subha Sreekumar. “Efficient Ranking on Websites Using ScaleRank with Interpolation Search.”
[15] https://snap.stanford.edu/data/com-DBLP.html
[16] https://snap.stanford.edu/data/amazon-meta.html](https://image.slidesharecdn.com/k1803057782-160705043745/85/K1803057782-6-320.jpg)

This document summarizes an approach to improve personalized ranking using associated edge weights. The key points are: 1) Personalized ranking aims to improve traditional search and retrieval by tailoring results to a user's interests. Authority flow approaches like PageRank and ObjectRank can be used for personalized ranking on entity-relationship graphs. 2) Edge-based personalization assigns different weights to edge types based on the user, affecting authority flow. The paper focuses on improving edge-based personalization by hybridizing the ScaleRank algorithm with k-means clustering. 3) ScaleRank approximates the DataApprox algorithm for ranking. The hybrid approach uses k-means clustering on ScaleRank output to further group related nodes,