The document discusses a novel method for improving web image search results through active reranking, which incorporates user interactions to better capture the user's intent when queries are ambiguous. It introduces a structural information-based sample selection strategy and a local-global discriminative dimension reduction algorithm to enhance search performance by reducing labeling efforts and localizing user intentions in visual feature space. Experimental results demonstrate the effectiveness of the proposed techniques on synthetic datasets and real web image search data, indicating significant performance improvements over traditional methods.
![IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 19, NO. 3, MARCH 2010 805
Active Reranking for Web Image Search
Xinmei Tian, Dacheng Tao, Member, IEEE, Xian-Sheng Hua, Member, IEEE, and Xiuqing Wu
Abstract—Image search reranking methods usually fail to cap- “panda” existing in its surrounding text. The other problem is
ture the user’s intention when the query term is ambiguous. There- that the textual information is insufficient to represent the se-
fore, reranking with user interactions, or active reranking, is highly mantic content of the images. The same query words may refer
demanded to effectively improve the search performance. The es-
sential problem in active reranking is how to target the user’s in- to images that are semantically different, e.g., we cannot dif-
tention. To complete this goal, this paper presents a structural in- ferentiate an animal panda image from an image for a person
formation based sample selection strategy to reduce the user’s la- whose name is Panda, just with the text word “panda”.
beling efforts. Furthermore, to localize the user’s intention in the Because the textual information is insufficient for semantic
visual feature space, a novel local-global discriminative dimension image retrieval, a natural recourse is the visual information. Re-
reduction algorithm is proposed. In this algorithm, a submanifold
is learned by transferring the local geometry and the discrimina- cently a dozen of image/video reranking methods [6], [14], [15],
tive information from the labelled images to the whole (global) [17], [34] have been proposed to exploit the usage of the vi-
image database. Experiments on both synthetic datasets and a real sual information for refining the text-based search result. Most
Web image search dataset demonstrate the effectiveness of the pro- of these reranking methods utilize the visual information in an
posed active reranking scheme, including both the structural infor- unsupervised and passive manner. The only exception is the In-
mation based active sample selection strategy and the local-global
discriminative dimension reduction algorithm. tentSearch [6], which reorders the text-based search result by
using query by example (QBE), with the query image specified
Index Terms—Active reranking, local-global discriminative
by the user from the initial text-based search result.
(LGD) dimension reduction, structural information (SInfo) based
active sample selection, web image search reranking. Unsupervised reranking methods, e.g., the clustering based
algorithm [14], the random work [15], the VisualRank [17] and
the Bayesian reranking [34], can only achieve limited perfor-
I. INTRODUCTION mance improvements. This is because the visual information
is insufficient to infer the user’s intention, especially when the
query term is ambiguous. For example, “panda” can be either
C URRENTLY, most of the popular commercial Web image
search engines, e.g., Microsoft’s Live Image Search and
Google Image Search, are built for “query by keywords” sce-
an animal or a person whose name is Panda. Without user inter-
actions, we have no idea which kind of panda images are pre-
nario. That is, a user provides a keyword, e.g., “panda”, then ferred by the user. However, if the user interactions are avail-
the search engine returns corresponding images by processing able, we can learn his/her intention and then rerank the initial
the associated textual information, e.g., file name, surrounding search results to achieve a significant performance improve-
text, URL, etc. ment. For instance, in the query “panda”, if the user labels the
Although text-based search techniques have shown their ef- animal pandas as relevant and other images as irrelevant, dif-
fectiveness in the document search, they are problematic when ferent kinds of animal pandas will be returned to the user. In
applied to the image search. There are two main problems. One this paper, reranking with user’s interactions is named as active
is the mismatching between images and their associated tex- reranking. IntentSearch [6] can be regarded as a simplified ac-
tual information, resulting into irrelevant images appearing in tive reranking method with only one relevant image labelled by
the search results. For example, an image which is irrelevant to the user.
“panda” will be mistaken as a relevant image if there is a word In active reranking, the essential problem is how to capture
the user’s intention, i.e., to distinguish query relevant images
from irrelevant ones. Different from the conventional learning
Manuscript received March 04, 2009; revised October 05, 2009. First problems, in which each sample only has one fixed label, an
published November 03, 2009; current version published February 18, 2010. image may be relevant for one user but irrelevant for another.
This work was supported by the Nanyang Technological University Nanyang In other words, the semantic space is user-driven, according
SUG Grant (M58020010), the Microsoft Operations PTE LTD-NTU Joint
R&D (M48020065), and the K. C. Wong Education Foundation Award. The to their different intentions but with identical query keywords.
associate editor coordinating the review of this manuscript and approving it for Therefore, we propose to target the user-driven intention from
publication was Prof. Sharathchandra Pankanti
two aspects: collecting labeling information from users to obtain
X. Tian and X. Wu are with the Department of Electronic Engineering and
Information Science, University of Science and Technology of China, Hefei the specified semantic space, and localizing the visual charac-
230027, China (e-mail: xinmei@mail.ustc.edu.cn; wuxq@ustc.edu.cn). teristics of the user’s intention in this specific semantic space,
D. Tao is with the School of Computer Engineering, The Nanyang Techno-
as detailed in Sections I-A and B, respectively.
logical University, 50 Nanyang Avenue, Blk N4, Singapore, 639798 (e-mail:
dacheng.tao@gmail.com). Although IntentSearch [6] can be deemed as a simplified ver-
X.-S. Hua is with Microsoft Research Asia, Beijing 100190, China (e-mail: sion of active reranking, i.e., the user’s intention is defined by
xshua@microsoft.com). only one query image, it cannot work well when the user’s inten-
Color versions of one or more of the figures in this paper are available online
at http://ieeexplore.ieee.org. tion is too complex to be represented by one image. As shown
Digital Object Identifier 10.1109/TIP.2009.2035866 in Fig. 3, the query relevant images for “Animal” vary largely
1057-7149/$26.00 © 2010 IEEE
Authorized licensed use limited to: ANNA UNIVERSITY. Downloaded on July 20,2010 at 10:56:33 UTC from IEEE Xplore. Restrictions apply.](https://image.slidesharecdn.com/activererankingforwebimagesearch-110929021214-phpapp01/85/Active-reranking-for-web-image-search-1-320.jpg)
![IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 19, NO. 3, MARCH 2010 805
Active Reranking for Web Image Search
Xinmei Tian, Dacheng Tao, Member, IEEE, Xian-Sheng Hua, Member, IEEE, and Xiuqing Wu
Abstract—Image search reranking methods usually fail to cap- “panda” existing in its surrounding text. The other problem is
ture the user’s intention when the query term is ambiguous. There- that the textual information is insufficient to represent the se-
fore, reranking with user interactions, or active reranking, is highly mantic content of the images. The same query words may refer
demanded to effectively improve the search performance. The es-
sential problem in active reranking is how to target the user’s in- to images that are semantically different, e.g., we cannot dif-
tention. To complete this goal, this paper presents a structural in- ferentiate an animal panda image from an image for a person
formation based sample selection strategy to reduce the user’s la- whose name is Panda, just with the text word “panda”.
beling efforts. Furthermore, to localize the user’s intention in the Because the textual information is insufficient for semantic
visual feature space, a novel local-global discriminative dimension image retrieval, a natural recourse is the visual information. Re-
reduction algorithm is proposed. In this algorithm, a submanifold
is learned by transferring the local geometry and the discrimina- cently a dozen of image/video reranking methods [6], [14], [15],
tive information from the labelled images to the whole (global) [17], [34] have been proposed to exploit the usage of the vi-
image database. Experiments on both synthetic datasets and a real sual information for refining the text-based search result. Most
Web image search dataset demonstrate the effectiveness of the pro- of these reranking methods utilize the visual information in an
posed active reranking scheme, including both the structural infor- unsupervised and passive manner. The only exception is the In-
mation based active sample selection strategy and the local-global
discriminative dimension reduction algorithm. tentSearch [6], which reorders the text-based search result by
using query by example (QBE), with the query image specified
Index Terms—Active reranking, local-global discriminative
by the user from the initial text-based search result.
(LGD) dimension reduction, structural information (SInfo) based
active sample selection, web image search reranking. Unsupervised reranking methods, e.g., the clustering based
algorithm [14], the random work [15], the VisualRank [17] and
the Bayesian reranking [34], can only achieve limited perfor-
I. INTRODUCTION mance improvements. This is because the visual information
is insufficient to infer the user’s intention, especially when the
query term is ambiguous. For example, “panda” can be either
C URRENTLY, most of the popular commercial Web image
search engines, e.g., Microsoft’s Live Image Search and
Google Image Search, are built for “query by keywords” sce-
an animal or a person whose name is Panda. Without user inter-
actions, we have no idea which kind of panda images are pre-
nario. That is, a user provides a keyword, e.g., “panda”, then ferred by the user. However, if the user interactions are avail-
the search engine returns corresponding images by processing able, we can learn his/her intention and then rerank the initial
the associated textual information, e.g., file name, surrounding search results to achieve a significant performance improve-
text, URL, etc. ment. For instance, in the query “panda”, if the user labels the
Although text-based search techniques have shown their ef- animal pandas as relevant and other images as irrelevant, dif-
fectiveness in the document search, they are problematic when ferent kinds of animal pandas will be returned to the user. In
applied to the image search. There are two main problems. One this paper, reranking with user’s interactions is named as active
is the mismatching between images and their associated tex- reranking. IntentSearch [6] can be regarded as a simplified ac-
tual information, resulting into irrelevant images appearing in tive reranking method with only one relevant image labelled by
the search results. For example, an image which is irrelevant to the user.
“panda” will be mistaken as a relevant image if there is a word In active reranking, the essential problem is how to capture
the user’s intention, i.e., to distinguish query relevant images
from irrelevant ones. Different from the conventional learning
Manuscript received March 04, 2009; revised October 05, 2009. First problems, in which each sample only has one fixed label, an
published November 03, 2009; current version published February 18, 2010. image may be relevant for one user but irrelevant for another.
This work was supported by the Nanyang Technological University Nanyang In other words, the semantic space is user-driven, according
SUG Grant (M58020010), the Microsoft Operations PTE LTD-NTU Joint
R&D (M48020065), and the K. C. Wong Education Foundation Award. The to their different intentions but with identical query keywords.
associate editor coordinating the review of this manuscript and approving it for Therefore, we propose to target the user-driven intention from
publication was Prof. Sharathchandra Pankanti
two aspects: collecting labeling information from users to obtain
X. Tian and X. Wu are with the Department of Electronic Engineering and
Information Science, University of Science and Technology of China, Hefei the specified semantic space, and localizing the visual charac-
230027, China (e-mail: xinmei@mail.ustc.edu.cn; wuxq@ustc.edu.cn). teristics of the user’s intention in this specific semantic space,
D. Tao is with the School of Computer Engineering, The Nanyang Techno-
as detailed in Sections I-A and B, respectively.
logical University, 50 Nanyang Avenue, Blk N4, Singapore, 639798 (e-mail:
dacheng.tao@gmail.com). Although IntentSearch [6] can be deemed as a simplified ver-
X.-S. Hua is with Microsoft Research Asia, Beijing 100190, China (e-mail: sion of active reranking, i.e., the user’s intention is defined by
xshua@microsoft.com). only one query image, it cannot work well when the user’s inten-
Color versions of one or more of the figures in this paper are available online
at http://ieeexplore.ieee.org. tion is too complex to be represented by one image. As shown
Digital Object Identifier 10.1109/TIP.2009.2035866 in Fig. 3, the query relevant images for “Animal” vary largely
1057-7149/$26.00 © 2010 IEEE
Authorized licensed use limited to: ANNA UNIVERSITY. Downloaded on July 20,2010 at 10:56:33 UTC from IEEE Xplore. Restrictions apply.](https://image.slidesharecdn.com/activererankingforwebimagesearch-110929021214-phpapp01/75/Active-reranking-for-web-image-search-1-2048.jpg)
![806 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 19, NO. 3, MARCH 2010
both in visual appearance and features, thus we cannot repre- high-level semantics to further enhance the reranking perfor-
sent “Animal” only with one image. Instead, our proposed ac- mance on this submanifold.
tive reranking method can learn the user’s intention more exten- In the past decades, a dozen of dimension reduction algo-
sively and completely. rithms have been proposed, e.g., principal components analysis
(PCA) [13], transductive component analysis [23], locally linear
A. Active User’s Labeling Information Collection embedding (LLE) [27], Discriminant LLE [21], ISOMAP [31],
To collect the labeling information from users efficiently, a nonparametric discriminant analysis [29], semi-supervised dis-
new structural information (SInfo) based strategy is proposed criminant analysis (SDA) [3], biased marginal Fisher’s analysis
to actively select the most informative query images. (BMFA) [37], locality preserving projections (LPP) [11], super-
It is boring and unacceptable to keep asking a user to label a vised LPP (SLPP) [2], geometric mean for subspace selection
lot of images in the interaction stage. Thus, it is essential to get [28], local discriminant embedding (LDE) [5], semantic man-
the necessary information by labeling as few images as possible. ifold learning (SML) [22], orthogonal Laplacianface [1], max-
Active learning is well-known for reducing the labeling efforts, imum margin projection (MMP) [10] and the recently devel-
by labeling most informative samples [4], [20]. Conventional oped correlation metric based methods [8], [9]. However, they
active learning strategies can be divided into two categories: the are problematic for active reranking in Web image search for
error reduction strategy [12], [25], [43] and the most uncertain the following reasons. Unsupervised methods, e.g., PCA and
(close-to-boundary) strategy [4], [36]. Both of them suffer from LLE, exploit a subspace or submanifold on the whole image
the small sample size problem, i.e., the unreliable estimation of space but ignore user’s labeling information. As a consequent,
the expected error risk and the uncertainty caused by the insuf- these algorithms fail to capture the user-driven intentions. Su-
ficient labelled samples. pervised linear algorithms, e.g., LDA [7] and biased discrimi-
In active reranking, however, only a few images will be nant analysis (BDA) [41], learn a subspace on the labelled set so
labelled by a user. To avoid or alleviate the influence of the they ignore the submanifold of all relevant images. Supervised
small sample size problem, our proposed SInfo sample se- manifold learning algorithms, e.g., SLPP and BMFA, cannot
lection strategy considers two aspects: the ambiguity and the transfer the learned submanifold from labelled images to unla-
representativeness, simultaneously. belled images. Although some semi-supervised algorithms, e.g.,
The ambiguity denotes the uncertainty whether an image is SML and SDA, have been developed to model both labelled and
relevant or not to the user’s intention. Chang et al. [4] and Wang unlabelled images, they are not designed specifically for active
et al. [36] have demonstrated the effectiveness of the ambiguity reranking in Web image search. They assume both relevant and
in active learning for image retrieval. However, they are not irrelevant unlabelled images are drawn from a nonlinear man-
specified for reranking problem. In this paper, the ambiguity is ifold. In Web image search, however, irrelevant images scatter
considered in a more natural way for reranking; it is derived in the whole space, i.e., they may be distributed uniformly, and
from the ranking scores, which denotes the images’ relevance thus popular manifold regularizations [3], [22] will over-fit to
degrees. Besides the ambiguity, the representativeness, another unlabelled images. As a consequence, the performance obtained
important aspect, is also considered. An image is more represen- by popular semi-supervised learning algorithms is poor. This
tative if it is located in a dense area with many images around paper presents a new algorithm to target user’s intention. Pre-
it. Labeling a representative sample will bring more information liminary experimental results on both synthetic data and a real
than labeling an isolated one. In active reranking, the represen- Web image search dataset demonstrate the effectiveness of the
tativeness is derived in a totally unsupervised fashion and inde- proposed LGD.
pendent to the learning algorithms, to alleviate the influence of The rest of the paper is organised as follows. Firstly, we in-
the aforementioned small sample size problem. Experiments on troduce the overall framework for active reranking in Section II.
both synthetic data and a real Web image search dataset show The SInfo active sample selection strategy is detailed in Sec-
that the SInfo is much more effective than other strategies, e.g., tion III and the LGD dimension reduction algorithm is presented
the most uncertain strategy and the error reduction strategy, in in Section IV. In Section V, the basic Bayesian reranking algo-
active reranking for Web image search. rithm is briefly introduced and the overall procedure of active
reranking based on it is given. Experimental results on synthetic
B. Visual Characteristic Localization datasets and a real Web image search dataset are reported in Sec-
To localize the visual characteristics of the user’s intention, tion VI and Section VII, respectively. In Section VIII, we give
we propose a novel local-global discriminative (LGD) dimen- some analysis to the important parameters in SInfo and LGD,
sion reduction algorithm. Basically, we assume that the query followed by the conclusion in Section IX.
relevant images, which represent the user’s intention, are lying
on a low-dimensional submanifold of the original ambient (vi- II. ACTIVE RERANKING FOR WEB IMAGE SEARCH
sual feature) space. LGD learns this submanifold by transfer- Fig. 1 shows the proposed general framework for active
ring both the local geometry and the discriminative informa- reranking in Web image search. Take the query term “panda”
tion from labelled images to unlabelled ones. The learned sub- as an example. When “panda” is submitted to the Web image
manifold preserves both the local geometry of labelled relevant search engine, an initial text-based search result is returned to
images and the discriminative information to separate relevant the user, as shown in Fig. 1(a) (only the top nine images are
from irrelevant images. As a consequence, we can eliminate the given for illustration). This result is unsatisfactory because both
well-known semantic gap between low-level visual features and person and animal images are retrieved as top results. This is
Authorized licensed use limited to: ANNA UNIVERSITY. Downloaded on July 20,2010 at 10:56:33 UTC from IEEE Xplore. Restrictions apply.](https://image.slidesharecdn.com/activererankingforwebimagesearch-110929021214-phpapp01/85/Active-reranking-for-web-image-search-2-320.jpg)
![TIAN et al.: ACTIVE RERANKING FOR WEB IMAGE SEARCH 807
Fig. 1. Framework for active reranking illustrated with the query “panda”. When the query is submitted, the text-based image search engine returns a coarse result
(a). Then the active reranking process is adopted to obtain a more satisfactory result (b), by learning the user’s intention.
caused by the ambiguity of the query term. Without the user ambiguity of an image is measured by the entropy of the rel-
interactions, it is impossible to eliminate this ambiguity. In par- evance probability distribution while the representativeness is
ticular, which kind of images, animal panda or person whose measured by the density.
name is Panda, are user’s intention? Therefore, traditional
reranking methods, which improve the initial search results by A. Ambiguity
only utilizing the visual property of images, cannot achieve The ambiguity denotes the uncertainty whether an image is
good performances. relevant or not. It can be estimated via various sophisticated
To solve this problem, active reranking, i.e., reranking with learning methods, e.g., support vector machine (SVM) [35],
user interactions, is proposed. As shown in Fig. 1, four im- transductive SVM (TSVM) [18] and the harmonic Gaussian
ages are first selected according to an active sample selection filed method [42], by conducting a binary classification task.
strategy, and then the user is required to label them. If the user However, in active reranking, it is direct and reasonable to
labels the animal pandas as query relevant (indicated by “ ” in measure the ambiguity with the ranking scores obtained in the
Fig. 1) and other two images (person, car) as query irrelevant. reranking process. There are two reasons. One reason is that
Then we can learn that the animal panda is the user’s intention. the reranking problem is essentially different from classifica-
To represent this intention, i.e., the animal panda, a discrimina- tion [34], thus the ambiguity estimated via conducting classi-
tive submanifold should be exploited to separate query relevant fication task may be not as accurate as that directly derived in
images from irrelevant ones. A dimension reduction step is thus reranking process. The other reason is that additional cost will
introduced to localize the visual characteristics of the user’s in- be introduced if the ambiguity is estimated via other learning
tention. methods. In contrast, measuring ambiguity through the ranking
With the knowledge of the user’s intention, including both scores avoids this additional cost.
the labeling information and the learned discriminative subman- For an image is its ranking score, where
ifold, the reranking process is conducted and different kinds of means is definitely query relevant, while means is
animal pandas are returned, as shown in Fig. 1(b). Sometimes, totally irrelevant. and can be regarded as the prob-
several interaction rounds are preferred to achieve a more satis- ability of to be relevant and irrelevant respectively. Then the
factory performance. ambiguity can be measured via the information entropy, which
In summary, there are two key steps in learning the user’s in- is a widely used measurement in the information theory. The
tention, i.e., the active sample selection strategy and the dimen- ambiguity of is
sion reduction algorithm. This paper implements these two steps
via a new SInfo sample selection strategy and a novel LGD di- (1)
mension reduction algorithm, as will be discussed in Sections III
Because the reranking is conducted based on the initial text-
and IV, respectively.
based search result [34], the ambiguity in the initial text-based
search result should also be taken into account, i.e.,
III. SINFO ACTIVE SAMPLE SELECTION
An SInfo active sample selection strategy is presented to learn (2)
the user’s intention efficiently which selects images by consid-
where is the initial text-based search ranking score
ering not only the ambiguity but also the representativeness in
for .
the whole image database. Ambiguity and representativeness
By combining (1) and (2), the total ambiguity for is
are two important aspects in active sample selection. Labeling
a sample which is more ambiguous will bring more informa- (3)
tion. On the other side, the information provided by individual
sample can be shared by its neighbors. Therefore, the more where is a trade-off parameter to control the influ-
representative samples are preferred for labeling. In SInfo, the ence of the two ambiguity terms.
Authorized licensed use limited to: ANNA UNIVERSITY. Downloaded on July 20,2010 at 10:56:33 UTC from IEEE Xplore. Restrictions apply.](https://image.slidesharecdn.com/activererankingforwebimagesearch-110929021214-phpapp01/85/Active-reranking-for-web-image-search-3-320.jpg)
![808 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 19, NO. 3, MARCH 2010
C. Active Sample Selection
Since the most informative images should meet both ambi-
guity and representativeness simultaneously, the structural in-
formation of image , can be measured by the product
of the two terms, i.e.,
Then the most informative image is selected from the un-
Fig. 2. Because “A” and “B” have the same distance to the hyper-plane (dashed labelled image set according to
line), they have an identical ambiguity. However, the more representative sample
“A” is more preferable to “B”.
(5)
In practical applications, to provide a good user experience,
B. Representativeness it would be better to ask users to label a small number of images
Besides the ambiguity, representativeness, an important prop- than only one image in each round. This is because users will
lose their patience after a few rounds. Thus, the batch mode is
erty but not well studied before, is also taken into account. Apart
utilized to select several images in each round. A simple method
from the unreliable estimation led by insufficient labelled im-
is to select the top- most informative images. The disadvantage
ages, the ambiguity measures the importance of the image it-
of this method is that the selected images may be redundant
self only. Once the Web image search system gets the labeling
and cluster in a small area in the high-dimensional feature space.
information of an image, it is very important to consider how Thus, we seek to select a batch of most informative images and
many other images can share the labeling information with the maintain their diversity at the same time.
labelled one. For example, given two unlabelled samples with The angle-diversity criterion [4] is a good choice to achieve
the identical ambiguity, labeling the more representative one, this purpose. This criterion iteratively selects images which are
i.e., many samples are distributed around it, will bring more in- most informative and also be diverse to the already selected
formation and achieve a better reranking performance. image set . For an unlabelled image , the diversity between
To explain this, a simple synthetic dataset is shown in Fig. 2. and is measured by the minimal angle between and each
There are two labelled samples (a big “*” for the query rele- image . Then, the images are selected iteratively ac-
vant sample while a big “o” for the query irrelevant one) and cording to
several unlabelled ones (marked with black big dot “.”). These
six samples distribute along a line and the coordinates on the (6)
horizontal axis denote their positions. By using SVM [35], the
classification hyper-plane , which separates the two labelled
where is a trade-off parameter which is introduced
sample with the largest margin, crosses position 0 as shown in
to balance the effects of the two components: the structural in-
Fig. 2 with the dashed line. According to the most uncertainty
formation and the angle-diversity.
criteria, i.e., the samples closest to having the maximum am-
biguity, we can get that “A” and “B” have the maximum and
IV. LGD DIMENSION REDUCTION
identical ambiguity because they have the same distance, i.e.,
0.4 for both, to the hyper-plane. However, if we can choose only In reranking, the images returned for a
one sample for labeling, it is better to label “A” than “B” because certain query term are represented by low-level visual features,
more unlabelled samples will share the labeling information of i.e., with the -dimensional visual
“A”. feature for image . The performance of reranking is
To avoid the small sample size problem in active sample se- usually poor because of the gap between the low-level visual
lection, the representativeness can be estimated in an unsuper- features and high-level semantics.
vised manner. Intuitively, labeling an image in a dense area will With user interactions, this semantic gap can be reduced sig-
be more helpful than labeling an isolated one because the la- nificantly. By mining user’s labeling information, we can learn
a submanifold to encode the user’s intention. This submanifold
beling information of the image can be shared with other sur-
is embedded in the ambient space, i.e., the high-dimensional vi-
rounding images. As a consequence, we can measure the rep-
sual feature space . In this paper, a linear subspace is used
resentativeness of image via the probability density ,
to approximate this submanifold and then the images can be rep-
which can be estimated by using the kernel density estimation
resented as with
(KDE) [26] for image . By using , an improved reranking per-
formance can be further obtained.
(4) This paper presents an LGD dimension reduction algorithm
to learn such a . LGD considers both the local information
contained in the labelled images and the global information of
where is the set of neighbors of . is the visual feature for the whole image database simultaneously. In detail, LGD trans-
image . is a kernel function that satisfies both fers the local information, including both the local geometry of
and . The Gaussian kernel is adopted in this the labelled relevant images and the discriminative information
paper. For the synthetic dataset in Fig. 2, the estimated repre- in the labelled images, to the global domain (the whole image
sentativeness is given by the curve . database). This cross domain transfer process is completed by
Authorized licensed use limited to: ANNA UNIVERSITY. Downloaded on July 20,2010 at 10:56:33 UTC from IEEE Xplore. Restrictions apply.](https://image.slidesharecdn.com/activererankingforwebimagesearch-110929021214-phpapp01/85/Active-reranking-for-web-image-search-4-320.jpg)
![TIAN et al.: ACTIVE RERANKING FOR WEB IMAGE SEARCH 809
building different local and global patches for each image, and
then aligning those patches together to learn a consistent coor-
dinate. One patch is a local area formed by a set of neighboring
images. We have three types of images: labelled relevant, la-
belled irrelevant, and unlabelled. Therefore, we build 3 types of
patches, which are: 1) local patches for labelled relevant images
to represent the local geometry of them and the discriminative
information to separate relevant images from irrelevant ones,
2) local patches for labelled irrelevant images to represent the
discriminative information to separate irrelevant images from
relevant ones, and 3) global patches for both labelled and unla- Fig. 3. For query “animal”, the query relevant images vary largely in both ap-
pearance (a) and visual features (b). In (b), the utilized 428-D visual features
belled images for transferring both the local geometry and the include 225-D color moment, 128-D wavelet texture and 75-D edge distribu-
discriminative information from all labelled images to the unla- tion histogram.
belled ones.
For convenience, we use superscript “ ” to denote the la-
belled relevant images and “ ” to denote the labelled irrele-
Solving problem (8), we can get
vant ones. If there is no superscript, it refers to an arbitrary
image which may be labelled relevant, labelled irrelevant or un- with the local gram matrix
labelled. .
To rewrite (7) in a more compact form, we consider its two
A. Local Patches for Labelled Relevant Images parts separately. For the first part, which models the local ge-
BDA, a popular dimension reduction algorithm for image re- ometry of relevant images
trieval, assumes that all query relevant samples are alike while
each irrelevant sample is irrelevant in its own way [41]. Thus,
the relevant samples are required to be close to each other in the
projected subspace. However, this assumption is usually unreli-
able in Web image search.
The query relevant samples may vary in appearance and
corresponding visual features. For example, in query “animal”,
query relevant images are different from each other, as shown
in Fig. 3. For this reason, instead of requiring relevant images
to be close to each other in the projected subspace, it is more
proper to remain the local geometry of the relevant images
while separating relevant images from all irrelevant ones. (9)
Therefore, the local patch for a labelled relevant image
should preserve both the local geometry of relevant images and where and
the discriminative information between the relevant images
and all irrelevant images. This paper models the local patch for with .
the low-dimensional representation of the labelled relevant
image as The second part models the discriminative information for
separating relevant image from all irrelevant ones, i.e.,
(7)
are ’s nearest neighbors in the labelled rel-
evant image set “ ”, and The are its
nearest neighbors in the labelled irrelevant image set “ ”. The
combination coefficient is a trade-off factor between the two
parts.
The first part in (7) is used to preserve the local geometry
of labelled relevant images before and after projection, thus the
linear combination coefficient vector is required to recon-
struct from its neighboring relevant images with minimal
error
(10)
where and
(8) .
Authorized licensed use limited to: ANNA UNIVERSITY. Downloaded on July 20,2010 at 10:56:33 UTC from IEEE Xplore. Restrictions apply.](https://image.slidesharecdn.com/activererankingforwebimagesearch-110929021214-phpapp01/85/Active-reranking-for-web-image-search-5-320.jpg)
![810 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 19, NO. 3, MARCH 2010
By combining (9) and (10) together into (7), we have us to use PCA here is the rule of Occam’s razor [24], i.e., the
utilization of PCA is helpful to avoid the over-fitting caused by
using conventional manifold regularizations.
To illustrate the advantage of global patches for dimension re-
duction, a synthetic example is shown in Fig. 4. Fig. 4(a) shows
the synthetic 3-D dataset and its projection on the 2-D planes
for a nice view. In this dataset, there are 8 labelled samples,
4 relevant and 4 irrelevant, accompanied with abundant unla-
belled samples. The relevant samples are all marked by “*”, with
big red “*” for the 4 labelled relevant samples and small black
“*” for the unlabelled relevant ones. The irrelevant samples are
B. Local Patches for Labelled Irrelevant Images marked by “o”, where big blue “o” and small green “o” denote
Discriminative information is also partially encoded in all ir- the labelled and unlabelled irrelevant samples respectively. The
relevant images, so we construct local patches for labelled irrel- irrelevant samples scatter in the space and the relevant images
evant images by separating each irrelevant image from all rel- are distributed on a manifold approximately.
evant images. Because each irrelevant image is irrelevant in its We have tried many different dimension reduction algo-
own way, it could be unreasonable to keep the local geometry rithms and the results are illustrated in Fig. 4(b)–(k). For
of the irrelevant images. In this paper, we model the local patch each dimension reduction algorithm, we have computed the
for the low-dimensional representation of labelled irrelevant projection plane (the upper part of subfigure) and the projected
image as 2-D data (the lower part of subfigure). With these conventional
algorithms, the relevant and irrelevant samples are overlapped
in the projected subspace and the submanifold of the relevant
(11)
samples is not well preserved, as illustrated in the figure.
This is caused by the problems existing in these algorithms as
The is ’s nearest neighbors in the labelled aforementioned.
relevant image set “ ”. The matrix can be calculated in the To avoid these problems, the proposed LGD learns the
way similar to that of computing in (10) by setting submanifold by transferring both the local geometry and the
and . discriminative information from labelled samples to all un-
labelled samples. Global patches are built for each sample
C. Global Patches for All Images (including both labelled and unlabelled) to complete the cross
In active reranking, users would like to label only a small domain knowledge transferring process. According to the align-
number of images, so it is lavish and unreasonable to abandon a ment scheme in [40], the global patch for the low-dimensional
large number of unlabelled images. With only the labelled im- representation of the image is modeled in a similar way to
ages, the learned subspace will bias to that spanned by these local patches
labelled images and cannot generalize well to the large amount
(12)
of unlabelled data. Therefore, some semi-supervised methods
have been proposed which also take the unlabelled images into where is the centroid of the projected low-dimensional fea-
utilization. However, because only relevant images are lying on ture. Here we use a variant version of the original definition of
an unknown manifold and the distribution of irrelevant images PCA to achieve a formula-level consistency for both local and
is nearly flat, conventional manifold regularizations which as- global patches.
sume both relevant and irrelevant samples are drawn from un- We rewrite (12) as
known manifolds prone to over-fit to unlabelled samples. As a
consequence, another method will be considered in this paper
to model unlabelled images in active reranking.
To make use of both the labelled and unlabelled images, the
most important thing is to exploit the information contained in
them. Inspired by the main idea in the cross domain learning
[16] and the transfer learning [32], in this paper, we introduce
the global patches to both labelled and unlabelled images. The
global patches transfer the local geometry and the discrimina-
tive information, which is exploited in the domain of labelled
images, to the domain of unlabelled images. With the global where with
patches, we aim to preserve the principal subspace to keep the are the rest images beyond , vector
submanifold of relevant images. The noise information con- and
tained in the ambient space should be eliminated. The principal
component analysis (PCA) is a suitable choice, which maxi- .
mizes the mutual information between the ambient space and By combining both local and global patches, LGD approxi-
the corresponding projected subspace [13]. Another reason for mates the intrinsic submanifold of relevant samples, as shown
Authorized licensed use limited to: ANNA UNIVERSITY. Downloaded on July 20,2010 at 10:56:33 UTC from IEEE Xplore. Restrictions apply.](https://image.slidesharecdn.com/activererankingforwebimagesearch-110929021214-phpapp01/85/Active-reranking-for-web-image-search-6-320.jpg)
![TIAN et al.: ACTIVE RERANKING FOR WEB IMAGE SEARCH 811
Fig. 4. Three-dimensional synthetic dataset for dimension reduction illustration. In this dataset, big red “*” and big blue “o” denote labelled relevant and irrelevant
samples, respectively. Small black “*” and small green “o” are unlabelled relevant and irrelevant samples, respectively. As given in (b), LGD reveals the submani-
fold of the relevant samples and separates the relevant samples from the irrelevant ones in the projected 2-D subspace. When other dimension reduction algorithms
are adopted, the relevant and irrelevant samples are overlapped in the projected subspace, as shown in (c)–(k). (a) The 3-D synthetic data and its 2-D projections on
the three planes, i.e., XY, XZ, and YZ, (b) LGD, (c) Local patches, (d) Global patches, (e) LGD-LPP, (f) BDA, (g) BMFA, (h) LDE, (i) SLPP, (j) SDA, (k) SML.
in Fig. 4(b). Relevant samples can be separated from irrelevant Then, we can combine all the patches defined in (7), (11), and
ones in the projected 2-D subspace. Besides, we show results (12) together
of only local patches and only global patches for dimension re-
duction in Fig. 4(c) and (d), respectively. Neither of them can
perform well.
To investigate the effectiveness of the PCA based global
patches, we replace them with LPP based patches, which are
built in a similar way for each sample. We name this LPP based
LGD as LGD-LPP and show its performance in Fig. 4(e). This
result is unsatisfactory because LPP assumes there is a manifold
for both labelled and unlabelled samples which violates the
true distribution of irrelevant samples. On the other hand, by
using PCA based global patches, the subspace with maximum
variance is preserved, so manifold structure of relevant samples
can also be preserved. By integrating global patches and local
patches, we can discover the intrinsic submanifold of relevant
samples, and separate relevant samples from irrelevant samples.
D. Patch Coordinate Alignment
Each patch has its own coordinate system. With the calculated
local and global patches, we can align them together into a con-
sistent coordinate. For each image
can be rewritten as , where and
is the selection matrix. The is defined ac-
cording to [38]–[40] as
(13)
where
where is the index vector for samples in . and is a control parameter.
Authorized licensed use limited to: ANNA UNIVERSITY. Downloaded on July 20,2010 at 10:56:33 UTC from IEEE Xplore. Restrictions apply.](https://image.slidesharecdn.com/activererankingforwebimagesearch-110929021214-phpapp01/85/Active-reranking-for-web-image-search-7-320.jpg)
![812 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 19, NO. 3, MARCH 2010
By imposing , the projection matrix When applying the Bayesian reranking for active reranking,
can be obtained by solving the standard eigende- modifications will be made to incorporate the new obtained in-
composition problem formation, i.e., the images’ labels obtained from SInfo and the
effective feature learned via LGD. For a labelled image, its
(14) is set as its ground truth label (“1” for relevant and “0” for
irrelevant) and large (set as 100 in this paper) is adopted to
where is consisting of the eigenvectors corresponding to the ensure equal or very close to its ground truth label. The graph
largest eigenvalues. is built with the learned to model the visual consistency
precisely.
V. BAYESIAN RERANKING In active reranking, at the very beginning, the Bayesian
reranking is performed in the original feature space without
To verify the effectiveness of the proposed active reranking labelled images. Then, with the derived , SInfo is conducted
method, we apply the SInfo active sample selection strategy to select informative images for labeling. By interacting with
and the LGD dimension reduction algorithm to reranking. Both the user, the labels of these images are obtained with which the
SInfo and LGD are general and can be directly applied to var- effective feature is learned via LGD. With the latest labelled
ious reranking algorithms, e.g., VisualRank [17]. In this paper, image set as well as , Bayesian reranking is performed to
we take the Bayesian reranking [34] as the basic reranking al- derive a new . The final reranking result is obtained by sorting
gorithm for illustration. the images according to in a descending order.
We first give a brief introduction for Bayesian reranking. In Usually, several interaction rounds are performed to achieve
this method, reranking is explicitly formulated into a global op- a satisfactory performance. Therefore, in next interaction round,
timization problem. The optimal reranked score list is ob- SInfo and LGD are performed with the new obtained in the last
tained by minimizing the following energy function: round. The overall procedure of our active reranking is summa-
rized as follows:
(15)
1: Initialization: the image set , the number of interaction
where is the initial text search score list, is rounds T, labelled image set and .
a trade-off parameter and is a graph which is constructed with 2: /* Perform Bayesian reranking to get */
nodes being the images and the weights being their visual simi- Bayesian reranking .
larities, and is the regularizer, which will be detailed 3: For to T do
below. 1) /* Perform SInfo to select a set of image */
The two terms on the right hand side of (15) correspond to SInfo
two assumptions, i.e., the visual consistency and the ranking /* Update */
consistency, respectively. The first term, i.e., the regularization
term, penalizes the ranking score inconsistency within visually 2) /* Perform LGD to learn a new */
similar samples. The second term is the ranking distance term
which penalizes the derivation of the reranked results from the 3) /* Perform Bayesian reranking to derive a new */
initial text-based search results. Bayesian reranking
For the regularization term, the local kernel is adopted 4: End for
5: Return
(16)
VI. EXPERIMENTS ON SYNTHETIC DATASETS
where is the local kernel matrix [33]. A point-wise distance In this section, we used three synthetic datasets to illustrate
is adopted for the ranking distance the effectiveness of the SInfo sample selection strategy, as
shown in Fig. 5 (top). In each dataset, the relevant samples
(17) are marked with red stars (“*”) while the irrelevant ones are
marked with blue circles (“o”).
The initial ranking score list was set randomly since we
With (16) and (17), we obtain had no textual information to simulate the text-based search
process. At the beginning stage, one relevant and one irrele-
vant sample were randomly selected as the labelled set and the
rest were taken as the unlabelled. The initial reranked results
[“RerankInitial” curve in Fig. 5 (bottom)] were obtained by
reranking without user interactions. Parameters in each method
were determined empirically in this paper to achieve its best
where with . Then, a closed- performance.
form solution for is given by In each interaction round, only one sample was selected for
labeling. For each dataset, we have given the reranked results
(18) after 4 interaction rounds with different active sample selection
Authorized licensed use limited to: ANNA UNIVERSITY. Downloaded on July 20,2010 at 10:56:33 UTC from IEEE Xplore. Restrictions apply.](https://image.slidesharecdn.com/activererankingforwebimagesearch-110929021214-phpapp01/85/Active-reranking-for-web-image-search-8-320.jpg)
![TIAN et al.: ACTIVE RERANKING FOR WEB IMAGE SEARCH 813
Fig. 5. Active reranking on synthetic datasets.
strategies. We performed 100 random trials and showed the av- Yahoo), we only know ranks of images in the text-based search
eraged performance, measured by the widely used noninterpo- and their scores are not available. According to [14], the nor-
lated Average Precision (AP) [30]. The AP averages the preci- malized rank is adopted as the pseudo score, for
sion values obtained when each relevant image occurs. the th ranked image, where and is the number
We compared SInfo with other three sample selection of images returned by the Web search engine for a query term.
strategies, i.e., “Error Reduction” [43], “Most Uncertain” [4] For active sample selection, five images were selected to in-
and “Random”. In “Most Uncertain”, the most ambiguity teract with the user in each interaction round and four rounds
samples are selected for interaction according to (3). While were considered. Therefore, for each query, there were 20 im-
in “Random”, the query samples are selected randomly. The ages labelled by the user totally. The performance is also mea-
comparison results, as shown in Fig. 5 (bottom), demonstrate sured by average precision (AP) [30]. We calculated the APs at
that the proposed strategy outperforms the rival methods different positions from top-1 to top-100 to obtain the AP curve.
consistently on all three datasets. This is because “Error Reduc- We averaged the APs over all the 105 queries to get the mean
tion” and “Most Uncertain” suffer from the small sample size average precision (MAP) for overall performance evaluation.
problem. SInfo is more robust because it takes both ambiguity
and representativeness into consideration, and thus alleviates A. Active Reranking With SInfo
the influence of the small sample size problem. In this section, we will investigate the effectiveness of SInfo
sample selection strategy and compare it with other three
VII. EXPERIMENTS ON WEB IMAGE SEARCH DATASET methods: “Error Reduction” [43], “Most Uncertain” [4], and
We also conducted experiments on a real Web image search “Random.” To be noted, here both the reranking and the active
dataset. In this dataset, there are 105 queries selected seriously sample selection were conducted in the original feature space.
from a commercial image search engine query log as well as The effectiveness of the LGD dimension reduction algorithm
popular tags of Flickr. These queries cover a large range of will be discussed in Section VII-B, in comparing with other
topics, including named person, named object, general object representative ones.
and scene. For each query, a maximum of 1 000 images returned Fig. 6 summarizes the comparison results. The “Baseline”
by commercial image search engines, i.e., Google, Live and curve gives the performance of the text-based search results and
Yahoo, were collected as the initial text-based search results. the “RerankInitial” curve is the performance of the unsuper-
This dataset contains 94 341 images in total. For each query, vised reranking without user interactions. The “SInfo”, “Error
three participants were asked to judge whether the returned im- Reduction”, “Most Uncertain”, and “Random” curves denote
ages are query relevant or irrelevant. An image is labelled as the performances of the reranked results with query images se-
query relevant if at least two of the three participants judged it lected according to these four strategies respectively.
as relevant, and vice versa. Fig. 6 shows the effectiveness of the proposed active
Images are represented by 428-D low-level visual features, reranking framework as well as the superiority of the proposed
including 225-D color moment in LAB color space, 128-D SInfo sample selection strategy. Curves in this figure show
wavelet texture as well as 75-D edge distribution histogram. that user’s labeling information helps enhance the reranking
For the initial text search score list , because images are all performance. User interactions can improve the average perfor-
downloaded from Web search engines (e.g., Google, Live and mance, no matter which sample selection strategy is adopted.
Authorized licensed use limited to: ANNA UNIVERSITY. Downloaded on July 20,2010 at 10:56:33 UTC from IEEE Xplore. Restrictions apply.](https://image.slidesharecdn.com/activererankingforwebimagesearch-110929021214-phpapp01/85/Active-reranking-for-web-image-search-9-320.jpg)
![814 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 19, NO. 3, MARCH 2010
Fig. 6. MAP over all queries with different sample selection strategies. Fig. 7. MAP over all queries with different dimension reduction algorithms.
Moreover, among these four strategies, SInfo performs best
and achieves a significant performance improvement. This is
because SInfo considers both the ambiguity and the represen-
tativeness while the “Most Uncertain” and “Random” only
take one side of them into account. For “Error Reduction” and
“Most Uncertain”, they both suffer from the small sample size
problem while our method alleviates this influence by taking
representativeness into account in an unsupervised manner.
B. Active Reranking With LGD
To test the effectiveness of LGD discussed in Section IV,
we conducted the active reranking in the projected subspace
by using different dimension reduction algorithms. The SInfo
sample selection strategy was adopted in this experiment.
We compared LGD with several representative algorithms,
including unsupervised algorithm, i.e., PCA [13], supervised Fig. 8. Performance of SML-PCA.
ones, i.e., BDA [41], LDE [5] and SLPP [2], as well as semi-su-
pervised ones, i.e., SML [22], SDA [3] and LGD-LPP. The sub-
space dimension was set to 100 for all algorithms empirically. class are sampled from a Gaussian. However, in Web image
Fig. 7 shows the results. The “SInfo” curve denotes the reranked search, each irrelevant image is irrelevant in its own way and
results of active reranking which is conducted in the original thus images in the irrelevant class are not similar to each other,
feature space without dimension reduction with the samples se- i.e., it is inconvenient to assume that irrelevant images are from
lected via SInfo. This curve is identical to the “SInfo” curve in an identical Gaussian. Therefore, SDA performed poorly. SML
Fig. 6. The performance of reranking via different dimension assumes that all images are sampled from a nonlinear mani-
reduction algorithms is denoted as SInfo+DR algorithm name, fold. In image search, irrelevant images usually scatter in the
e.g., “SInfo LGD” for performance of LGD. whole space, i.e., they may be distributed uniformly. SML is
Fig. 7 shows that LGD performs best among these algorithms prone to over-fit to unlabelled images because of the improper
and achieves a more satisfactory performance than “SInfo”. It manifold regularization assumption. To justify this point, we
reflects the effectiveness of LGD in localizing the visual charac- replaced the Laplacian regularization in SML with the global
teristics of the user intention. For the other dimension reduction patches in LGD. This method is denoted as SML-PCA. The
algorithms, reranked performances are either slightly improved experimental results of SML-PCA with varying trade-off pa-
or dramatically decreased. PCA fails to capture the user-driven rameter (controls the influence of global patches) are given in
intention since it ignores the labeling information. BDA, LDE, Fig. 8. The figure shows that SML-PCA performs much better
and SLPP, which are all supervised dimension reduction algo- than SML, but not as well as LGD. The result of LGD-LPP fur-
rithms, only utilize a few labelled images. Thus, the subspace ther confirms that improper manifold regularization is harmful.
learned by them is biased to that spanned by several labelled In contrast with them, the proposed LGD duly learned the sub-
images and cannot generalize well to the large amount of unla- manifold of the relevant images and overcome the difficulties
belled ones. discussed above by preserving the local geometry of the labelled
For semi-supervised algorithms, SDA is unsuitable for the relevant images through local patches and the global structure
reranking task because it assumes that images in an identical of the whole image set via global patches. In Figs. 19 and 20, we
Authorized licensed use limited to: ANNA UNIVERSITY. Downloaded on July 20,2010 at 10:56:33 UTC from IEEE Xplore. Restrictions apply.](https://image.slidesharecdn.com/activererankingforwebimagesearch-110929021214-phpapp01/85/Active-reranking-for-web-image-search-10-320.jpg)
![TIAN et al.: ACTIVE RERANKING FOR WEB IMAGE SEARCH 815
Fig. 9. Performance of LGD with samples selected via random and SInfo Fig. 10. Performance of SInfo with different . The solid line indicates the
respectively. performance of “RerankInitial”, i.e., reranking without user interactions.
further illustrate the active reranked results on queries “George tors: in (3) for SInfo, in (7) and in (13) for LGD. And then
W. Bush” and “zebra”. For each query, the top-20 ranked im- we investigate the influence of the interaction rounds of active
ages are shown for both the text-based search result and the ac- sample selection and the dimension of the projected feature in
tive reranked result. For a nice view, we mark the query irrele- LGD. The mean AP averaged over AP@1 to AP@100 is uti-
vant images appeared in the result with cross “ ”. These figures lized for overall performance evaluation.
show that the proposed active reranking method is effective to
target user’s intention. A. Evaluation on Ambiguity Trade-Off Parameter
C. LGD With Random Sample Selection The in (3) plays an important role in balancing the am-
biguity estimation, which is one of the two critical aspects
In Section VII-B, we have shown that, when samples are se- in SInfo. With close to 1, the ambiguity is derived entirely
lected via SInfo, the performance of reranking conducted in from the reranked result and the ambiguity contained in the
the original feature space, i.e., the “SInfo” curve in Fig. 7, is text search prior is ignored. Fig. 10 shows the performance of
consistently improved when LGD is utilized. As illustrated in SInfo subject to different . In this experiment, the reranking
Fig. 7, “SInfo+LGD” performed better than “SInfo”. To verify is conducted in the original feature. The “RerankInitial”, i.e.,
the sensitivity of LGD to sample selection strategy, we fur- reranking without user interactions, is also given for compar-
ther conducted experiments for LGD when samples were ran- ison, denoted by the solid line in Fig. 10.
domly selected. The experimental results are given in Fig. 9, in Fig. 10 shows that the performance of SInfo increases when
which the result of LGD with SInfo is also given for compar- growing and arrives at the peak with . This value is
ison. From this figure, we can see that “Random LGD” out- close to the best setup for the text search prior that have been re-
performs “Random” and “SInfo+LGD” outperforms “SInfo”. ported in other applications which is around 0.85 [15], [17]. By
It demonstrates the robustness of LGD to varying sample se- further comparing with “RerankInitial”, we can see that SInfo
lection strategies. Further comparing the performance of LGD outperforms it consistently no matter which is adopted. It il-
with “Random” and “SInfo”, we can see that “SInfo LGD” lustrates the effectiveness of SInfo for reranking.
achieves better performance than “Random+LGD”. This is be-
cause more informative samples are selected in “SInfo” and thus B. Evaluation on Local Patch Trade-Off Parameter
with which LGD can learn the user intentions more effectively.
We also investigated the influence of the trade-off parameter
In other words, a better active sample selection algorithm can
in (7) for LGD when building the local patch for labelled
bring more benefits to LGD. This phenomenon shows that both
relevant images. A large reflects the importance of separating
sample selection and dimension reduction are important for ac-
irrelevant samples from relevant ones, i.e., the discriminative
tive reranking and thus should be elaborately developed.
information, with less attention given to the local geometry of
relevant images. Fig. 11 shows the performance of LGD with
VIII. PARAMETER SENSITIVITY different , from which we can have the following observations.
In this section, we analyse the sensitivity of important pa- • When is small, e.g., less than 0.3, the performance is
rameters in SInfo and LGD for active reranking. The analyses unsatisfactory and even worse than “SInfo” (solid line in
are performed based on the experiments conducted on the Web Fig. 11). This is because that in this situation the local ge-
image search dataset. The experiments are conducted with SInfo ometry within labelled relevant images is mainly preserved
active sample selection and LGD dimension reduction, if not ex- while important discriminative information is less consid-
plicitly stated otherwise. We first analyse some important fac- ered. This phenomenon reveals the importance of the dis-
Authorized licensed use limited to: ANNA UNIVERSITY. Downloaded on July 20,2010 at 10:56:33 UTC from IEEE Xplore. Restrictions apply.](https://image.slidesharecdn.com/activererankingforwebimagesearch-110929021214-phpapp01/85/Active-reranking-for-web-image-search-11-320.jpg)
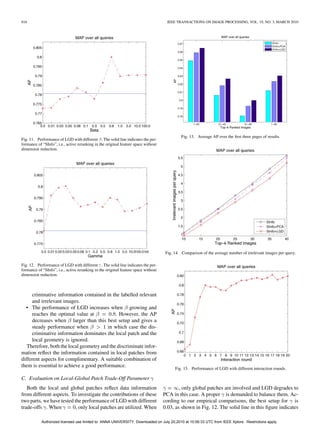

![with different number of labelled images. (a) # Labeled = 5, (b) # Labeled = 10, (c) # Labeled = 15, (d) # Labeled = 20.
the performance of “SInfo”, i.e., reranking in the original fea- D. Evaluation on Number of Interaction Rounds for Active
ture space without dimension reduction. Fig. 12 shows that LGD Sample Selection
outperforms it consistently with various and LGD is robust.
More labelled images will bring more information and thus
As shown in Fig. 12, the improvement of LGD over PCA oc-
a better performance can be achieved. However, users usually
curs in a range of [0.01, 0.05] for . This range seems to be a
lose their patience after a few interaction rounds. Therefore, it
little narrow. However, it is worth emphasizing that only a small
is important to find out a good trade-off between the reranking
part of images (around % in experiments, half for
performance and the number of the interaction rounds. In this
relevant and half for irrelevant images) are labelled. As a con-
experiment, we investigated the performance of reranking with
sequence, the number of global patches is much more than that
interaction rounds varying from 1 to 20. In each round, 5 images
of the labelled relevant and irrelevant patches. After eliminating
are selected via SInfo for labeling. LGD is adopted to learn the
issue of the patch number imbalance, the range for is mod-
effective subspace for reranking.
erate, i.e., it is around [1.0, 5.0].
The experimental results are illustrated in Fig. 15. Zero
For the comparison between LGD and PCA, in Fig. 12, we
interaction round means that the reranking conducted without
only give the overall performance of mean AP averaging over
user interactions, i.e., the “Reranking Initial”. When interaction
top-1 to top-100 ranked images. We refer the reader back to
round increases from 0 to 4, the performance receives dramatic
Fig. 7 for sufficient details. Fig. 7 shows that LGD outperforms
improvements steadily. However, when more interactions
PCA consistently on top-1 to top-100 ranked images. It is worth
are performed, the performance increases slowly and even
emphasizing that it is very difficult to improve the baselines for
shows slightly decreasing at certain rounds. As a consequence,
Web data based applications and 1% improvement is usually ac-
reranking with 4 interaction rounds is a good choice by consid-
knowledged, e.g., TRECVID [19]. The top-20 images are im-
ering both the reranking performance and user tolerance.
portant in Web search because they are displayed on the first
page and dominant the user’s evaluation of the search results.
E. Influence of Labelled Image Size on Model Parameters
Comparing with PCA, much more improvements are obtained
by LGD, i.e., LGD finds at least one more relevant image for In Sections VIII-B and C, we have discussed the influence
top-20 ranked images every five runs. This is practically signif- of parameters and in LGD to the reranking performance
icant. Fig. 13 shows the average performance of LGD versus when 20 images (4 interaction rounds with 5 images labelled
PCA over top-1 to top-20, top-21 to top-40, top-41 to top-60, per round) are labelled. In this section, we turn to investigate
and top-1 to top-60 ranked images, which corresponds to the the influence of the number of labelled images on these model
first 3 pages of results (assuming 20 images are displayed on parameters. Fig. 16 shows the performance curves of with
each page). LGD improves PCA consistently. different number of labelled images while Fig. 17 illustrates that
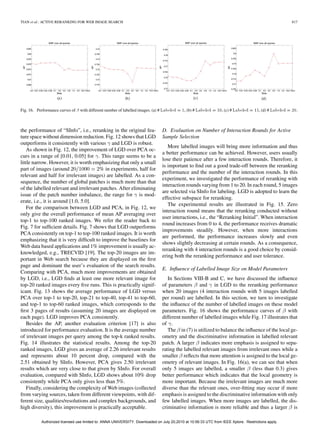
Besides the AP, another evaluation criterion [17] is also of .
introduced for performance evaluation. It is the average number The in (7) is utilized to balance the influence of the local ge-
of irrelevant images per query among the top-k ranked results. ometry and the discriminative information in labelled relevant
Fig. 14 illustrates the statistical results. Among the top-20 patch. A larger indicates more emphasis is assigned to sepa-
ranked images, LGD gives an average of 2.26 irrelevant results rating the labelled relevant images from irrelevant ones while a
and represents about 10 percent drop, compared with the smaller reflects that more attention is assigned to the local ge-
2.51 obtained by SInfo. However, PCA gives 2.50 irrelevant ometry of relevant images. In Fig. 16(a), we can see that when
results which are very close to that given by SInfo. For overall only 5 images are labelled, a smaller (less than 0.3) gives
evaluation, compared with SInfo, LGD shows about 10% drop better performance which indicates that the local geometry is
consistently while PCA only gives less than 5%. more important. Because the irrelevant images are much more
Finally, considering the complexity of Web images (collected diverse than the relevant ones, over-fitting may occur if more
from varying sources, taken from different viewpoints, with dif- emphasis is assigned to the discriminative information with only
ferent size, qualities/resolutions and complex backgrounds, and few labelled images. When more images are labelled, the dis-
high diversity), this improvement is practically acceptable. criminative information is more reliable and thus a larger is
Authorized licensed use limited to: ANNA UNIVERSITY. Downloaded on July 20,2010 at 10:56:33 UTC from IEEE Xplore. Restrictions apply.](https://image.slidesharecdn.com/activererankingforwebimagesearch-110929021214-phpapp01/85/Active-reranking-for-web-image-search-15-320.jpg)
























































































