

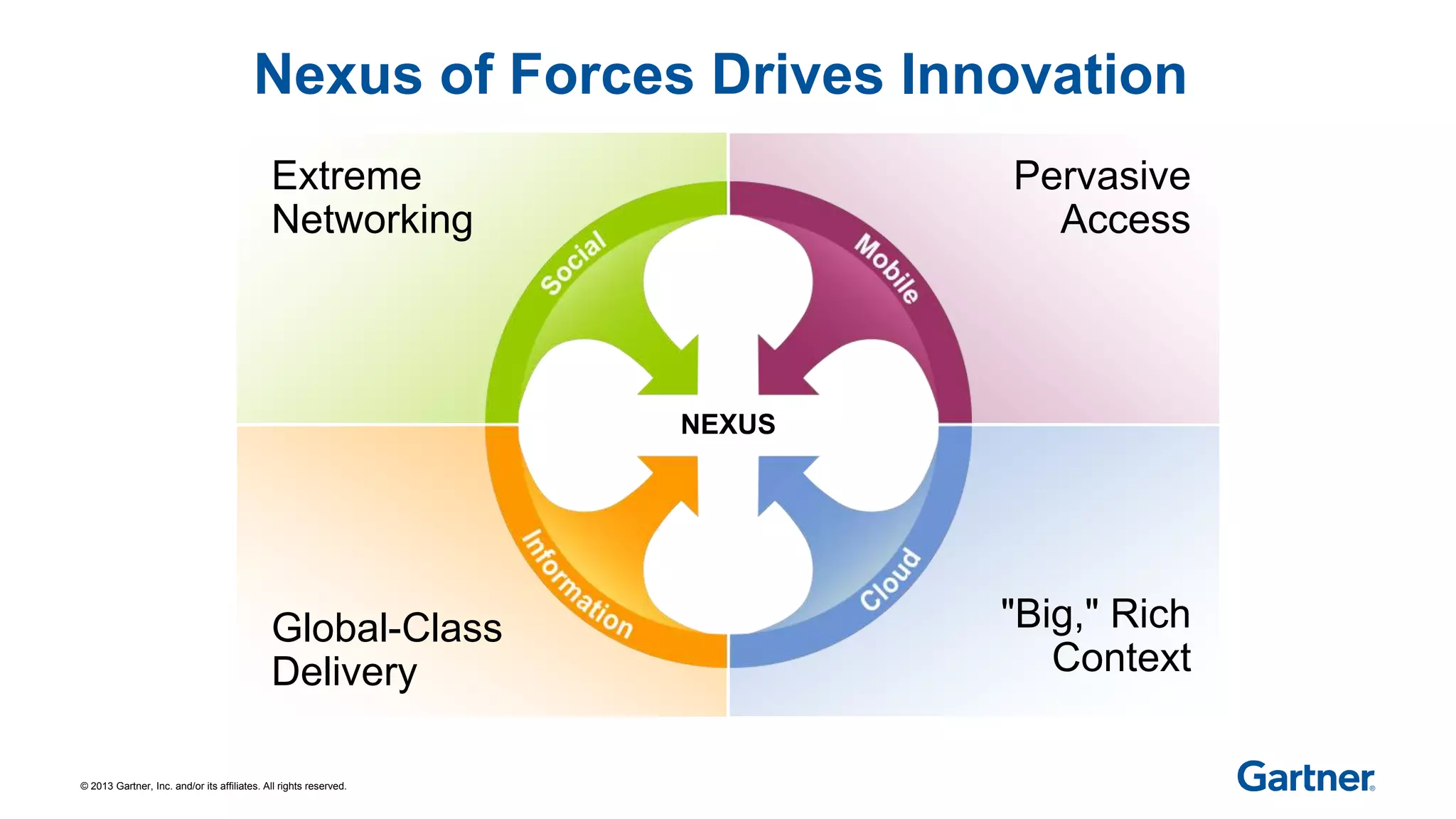


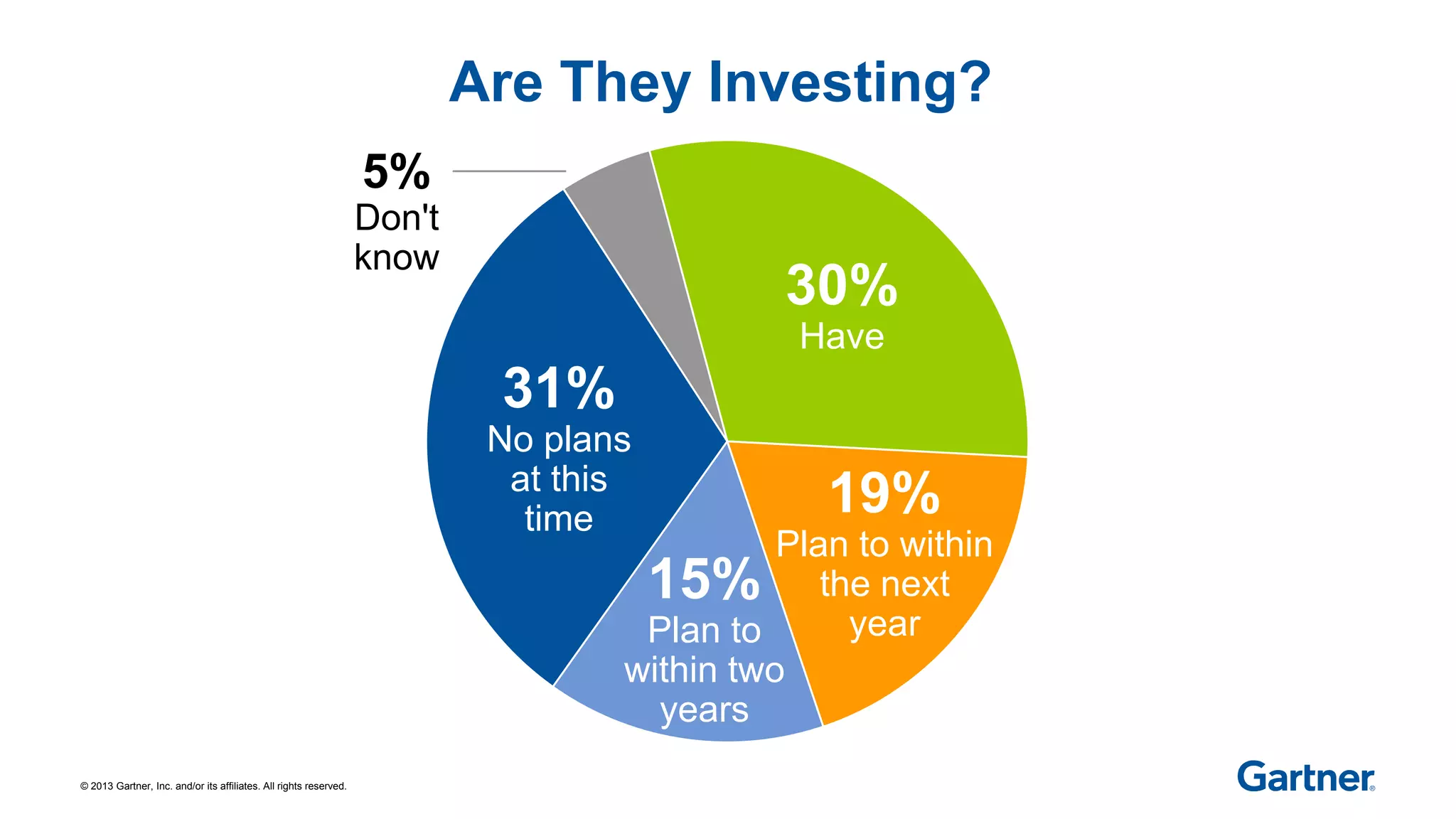















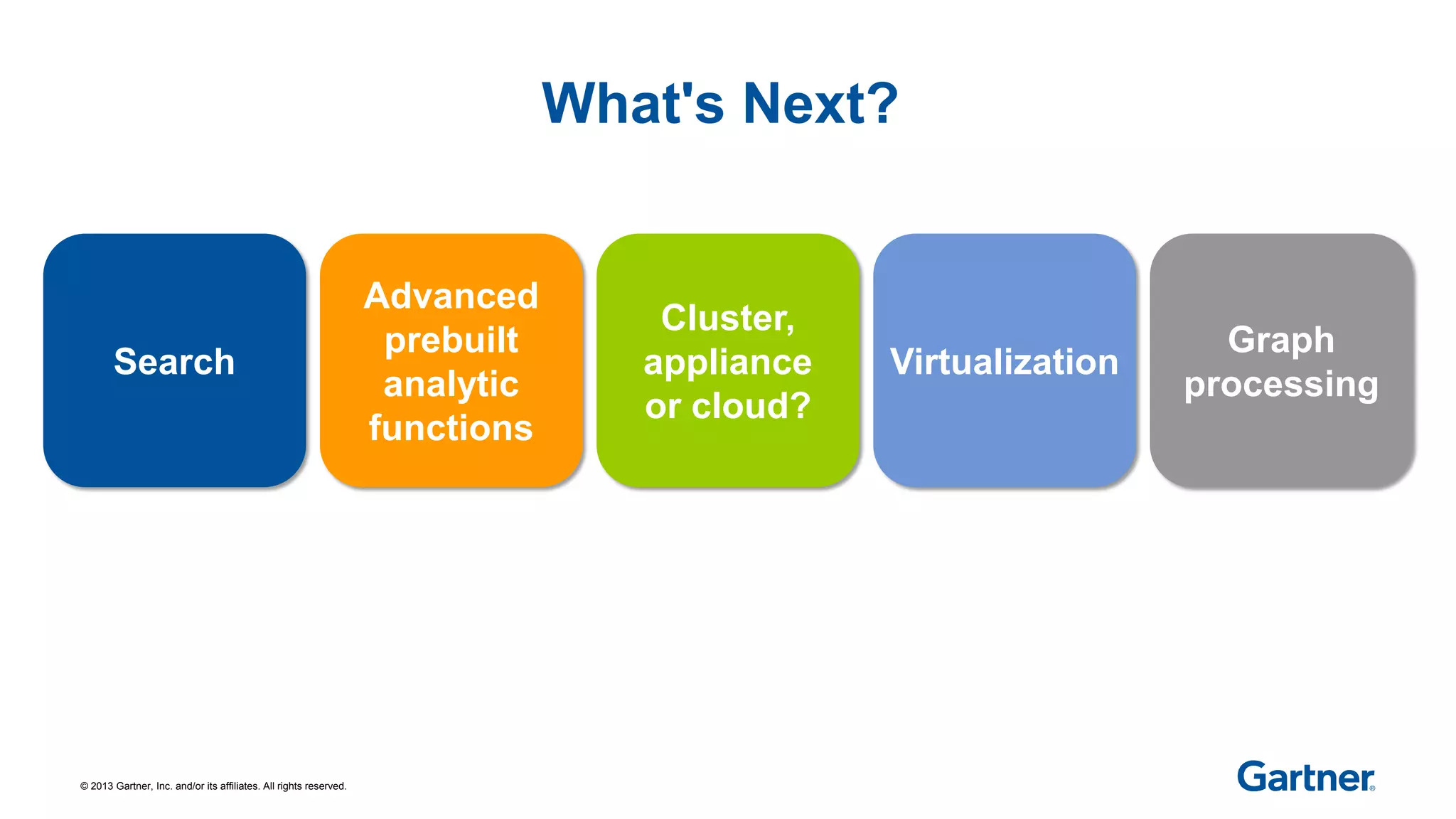
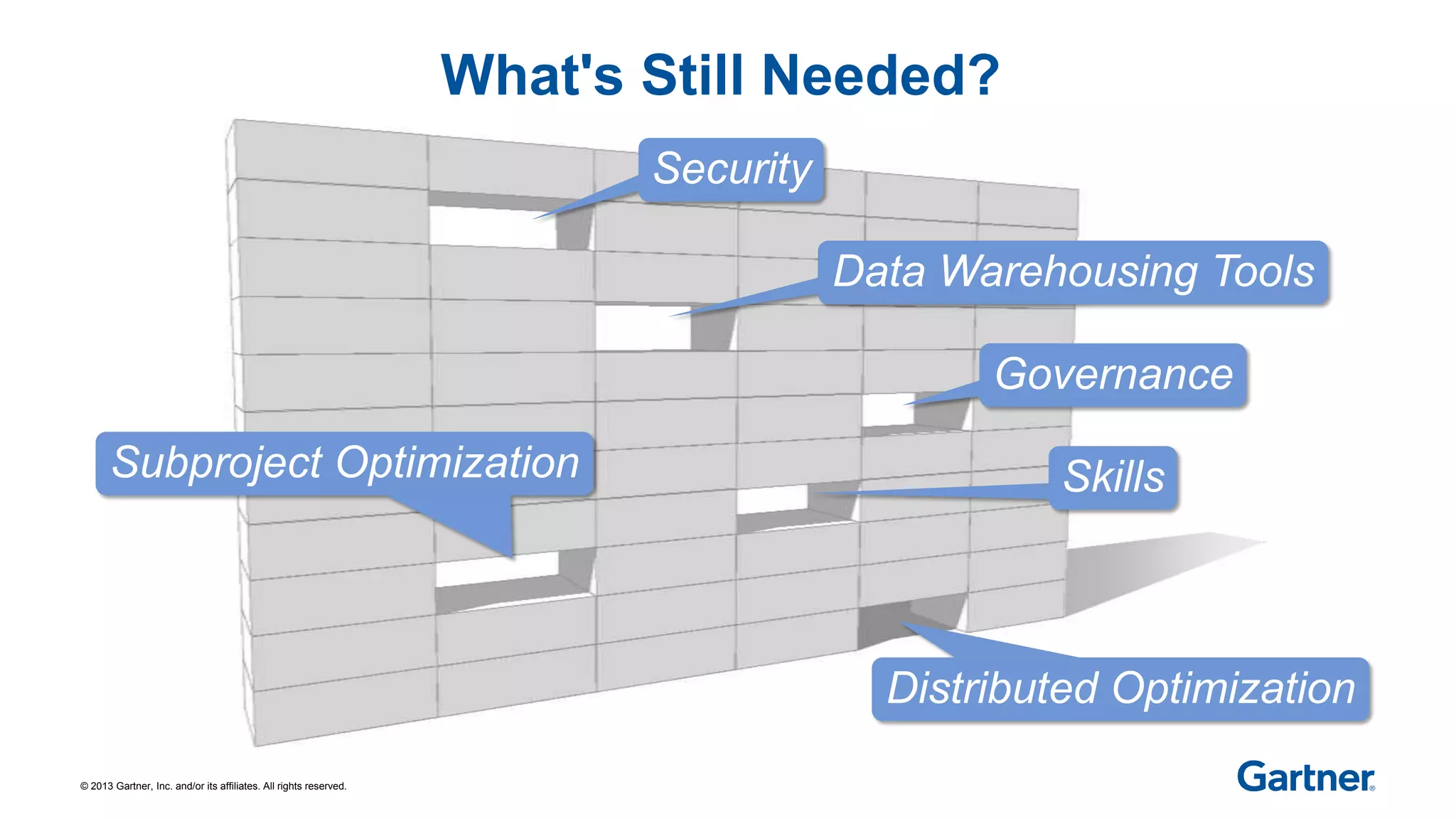
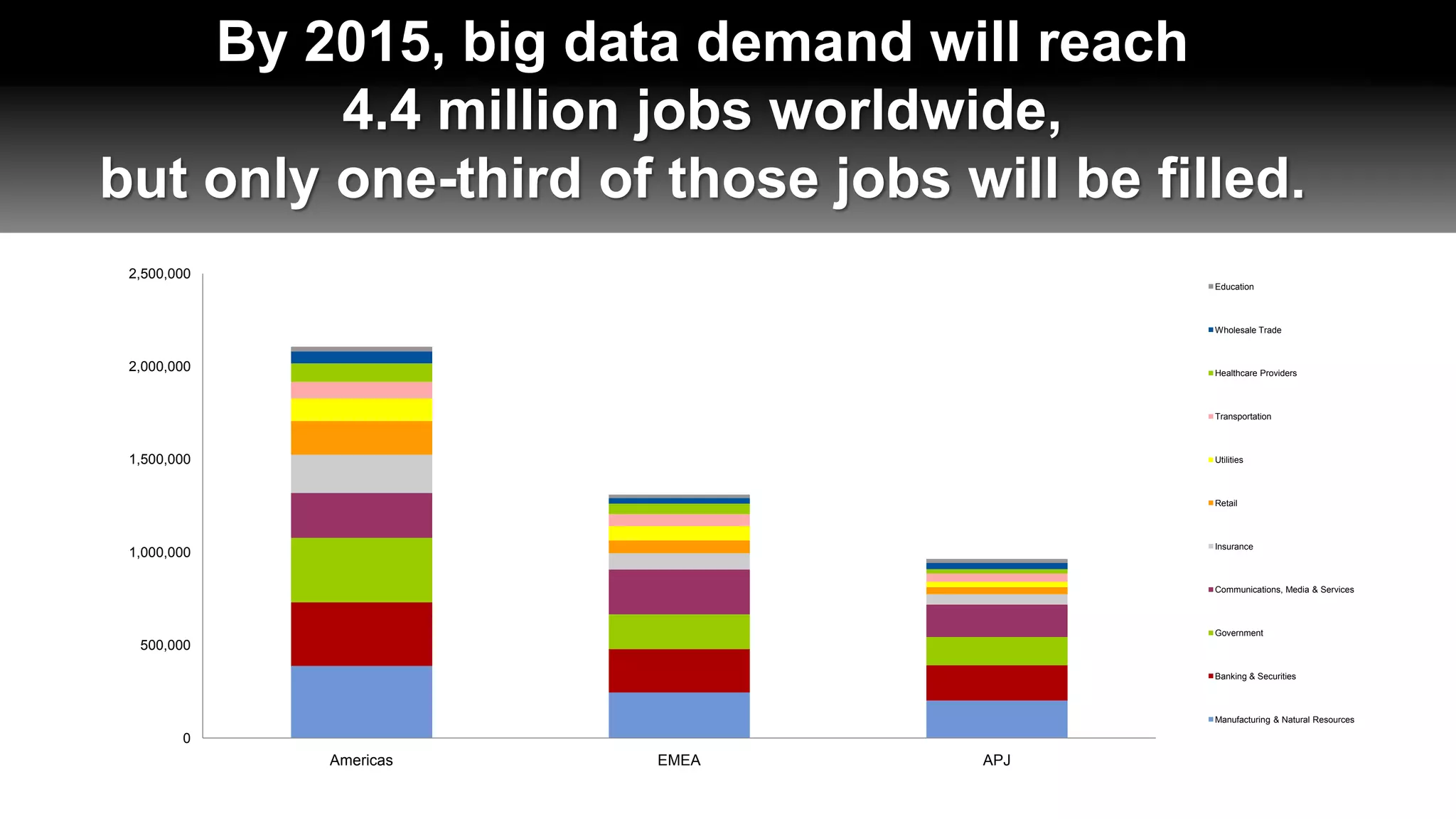




The document discusses Apache Hadoop, an open-source software framework for distributed storage and processing of large datasets across clusters of computers. It describes the core components of Hadoop, the many related projects that can work with it, and the ecosystem of distributions provided by different vendors. It also outlines the evolution of Hadoop from early batch processing to more interactive capabilities, and identifies areas that still need development like security, data warehousing tools, and skills.






































































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)



