Download to read offline




























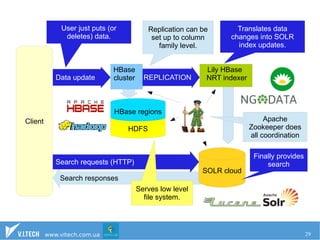


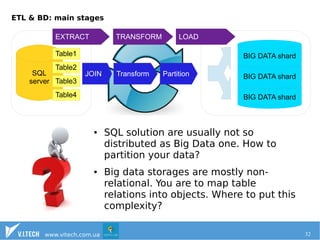
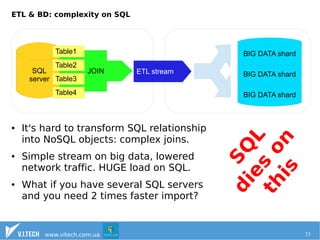
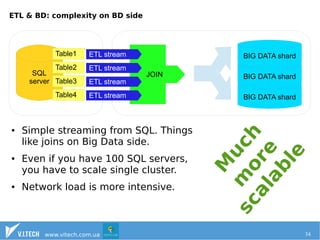
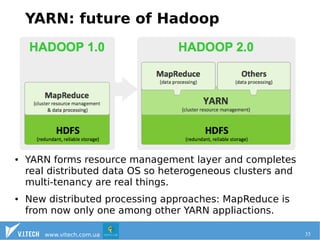











The document discusses the importance of effectively managing big data, emphasizing the need for ample data collection and robust infrastructure rather than limiting data sources. It highlights Hadoop as a key open-source framework for handling big data, along with other technologies like HBase and Solr for data storage and search capabilities. Additionally, it addresses the complexities of integrating big data solutions with traditional SQL databases and points out the advantages of resource management systems like YARN and frameworks such as Apache Spark.























































































