Downloaded 80 times







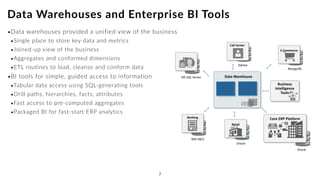

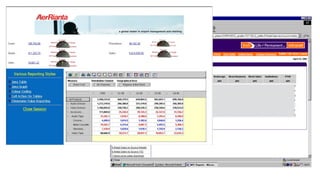






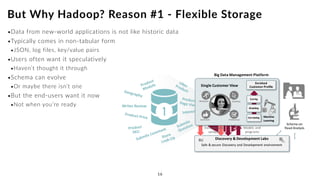
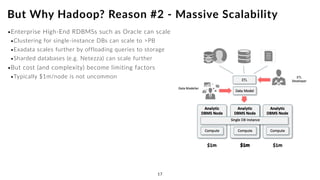
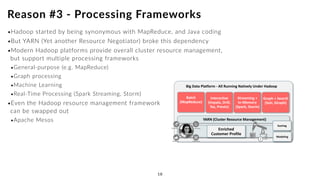
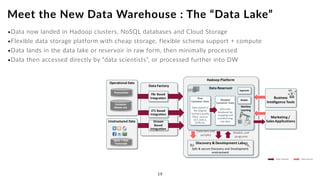

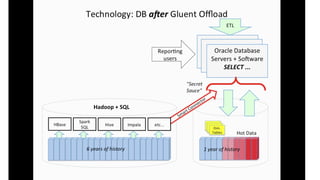

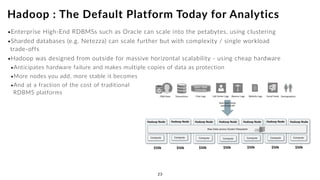

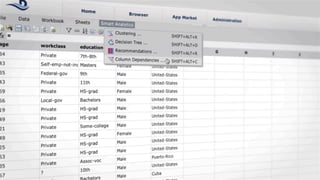
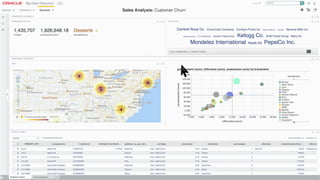











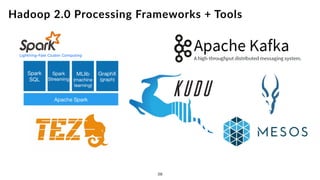






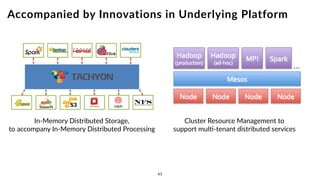


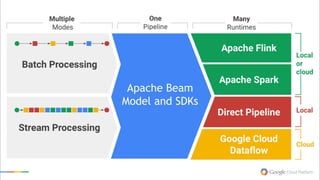

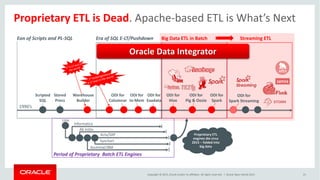


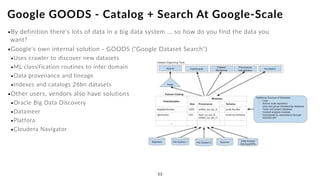



The document discusses the future of analytics, data integration, and business intelligence (BI) on big data platforms like Hadoop. It covers how BI has evolved from old-school data warehousing to enterprise BI tools to utilizing big data platforms. New technologies like Impala, Kudu, and dataflow pipelines have made Hadoop fast and suitable for analytics. Machine learning can be used for automatic schema discovery. Emerging open-source BI tools and platforms, along with notebooks, bring new approaches to BI. Hadoop has become the default platform and future for analytics.






























































































