Downloaded 18 times


































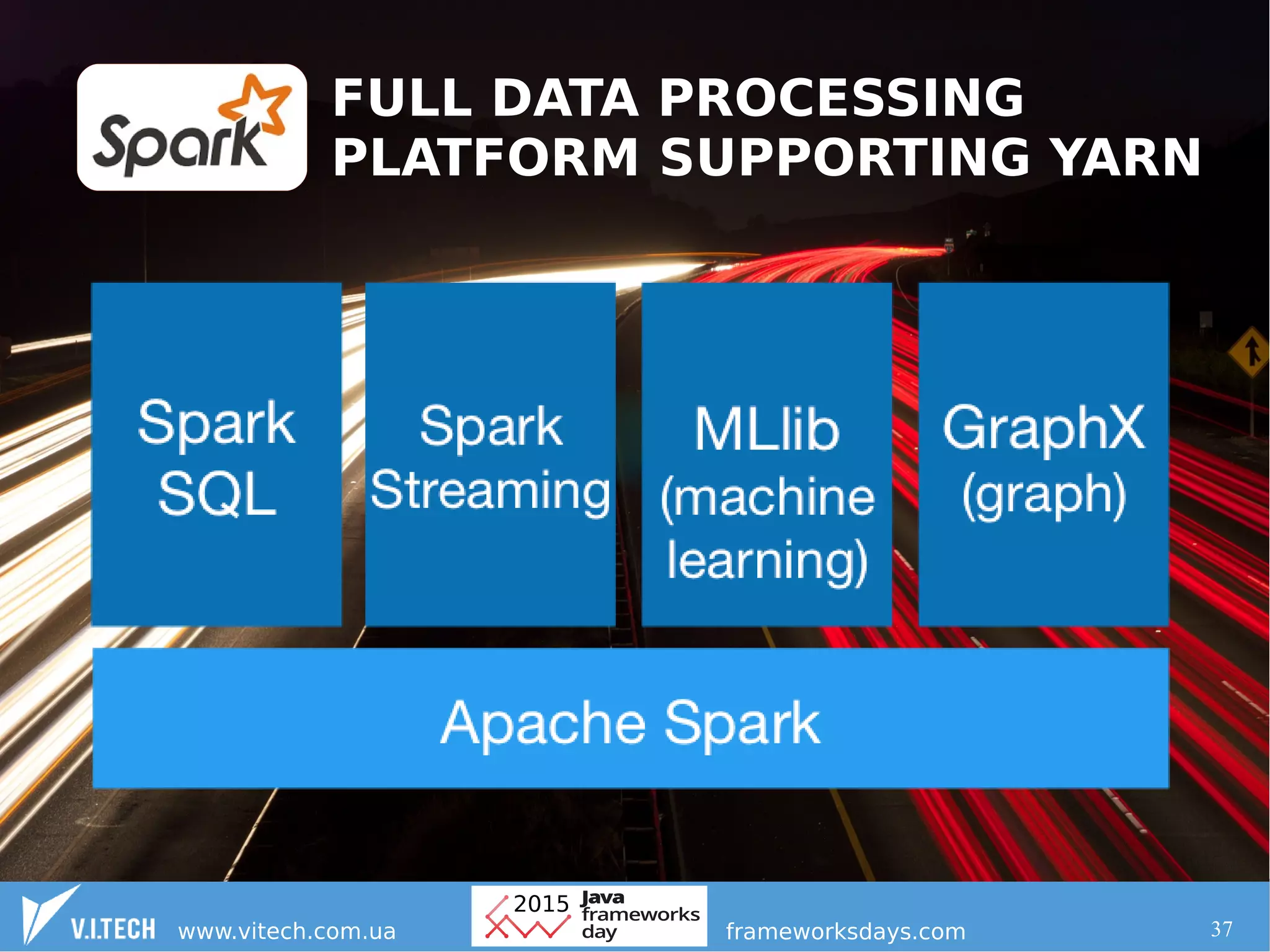





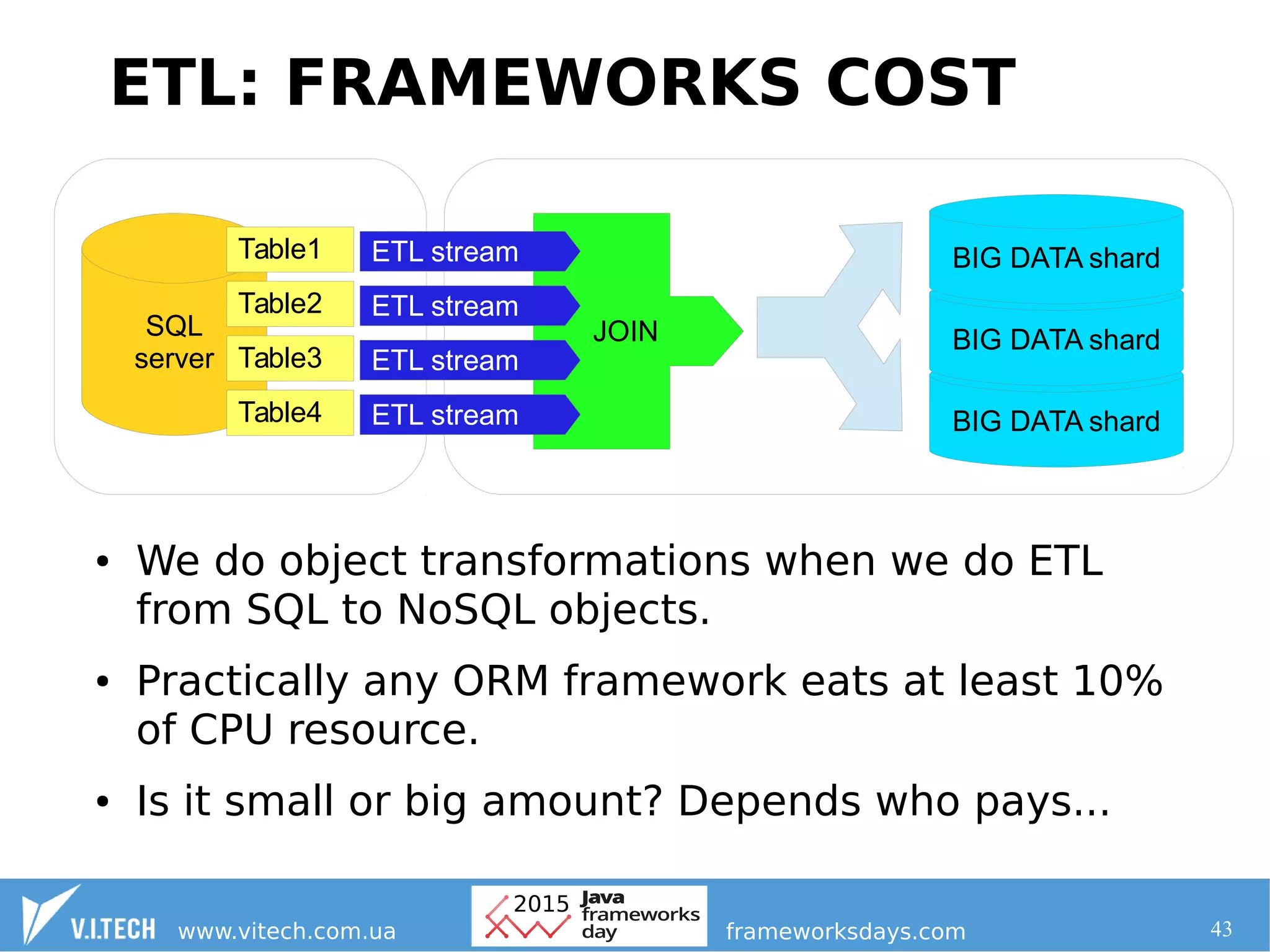














This document discusses frameworks in the context of big data solutions. It makes several key points: 1. Hadoop provides a stable core infrastructure for building big data solutions, with layers for resource management, distributed processing, file system, and coordination. 2. When going beyond the Hadoop core, frameworks should be selected that have a stable approach, flexible functionality, and an active community to contribute to existing solutions rather than creating new ones. 3. Performance overhead from frameworks is directly paid for with additional computing resources in large clusters, so frameworks should be chosen carefully based on their overhead. Creating new frameworks limits future flexibility the more users it has.



































![Resilience: the key requirement of a [big] [data] architecture - StampedeCon...](https://cdn.slidesharecdn.com/ss_thumbnails/resiliencethekeyrequirementofabigdataarchitecture-stampedecon2015-150717135240-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
























![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)







