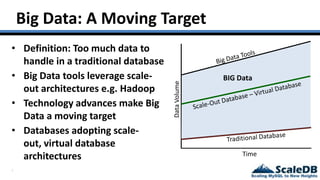
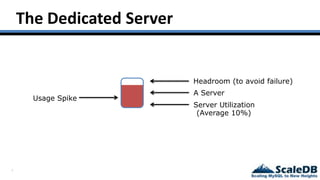
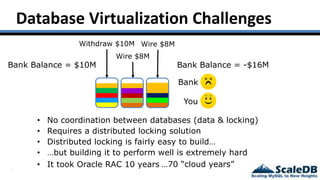
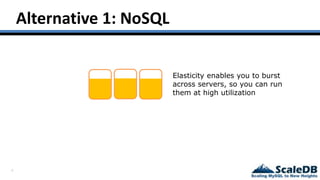
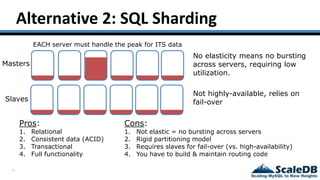
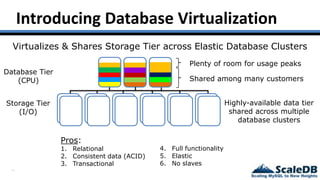
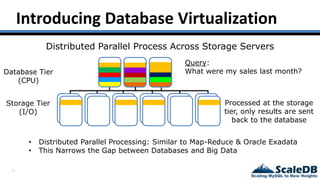
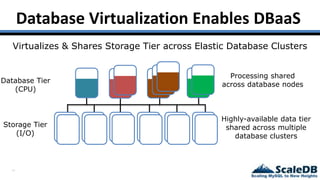
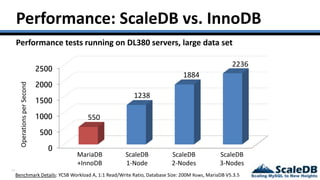
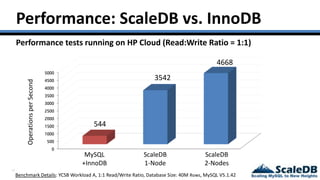
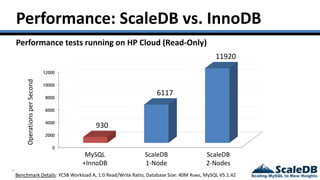
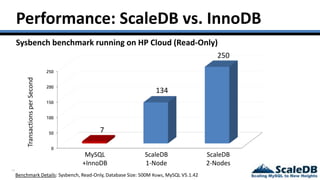
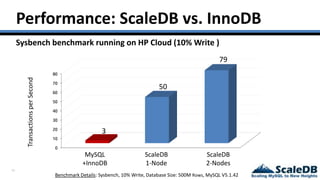
The document discusses database virtualization and its role in managing big data by addressing challenges such as distributed locking and performance scalability. It compares alternatives like NoSQL and SQL sharding, highlighting their limitations and the need for application-level handling. The introduction of database virtualization aims to provide a high-performing, elastic solution that narrows the gap between traditional databases and big data requirements.