Downloaded 68 times













































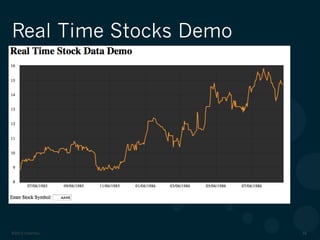






















The document discusses real-time analytics using DataStax Enterprise, which integrates Cassandra, Solr, and Hadoop for effective big data solutions. It highlights the advantages of Cassandra over traditional databases and HBase, particularly in terms of scalability, eventual consistency, and ease of use. Key features of DataStax Enterprise, including indexing, security, and schema updates, are presented along with real-world applications such as real-time stock price analysis.


















































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)




