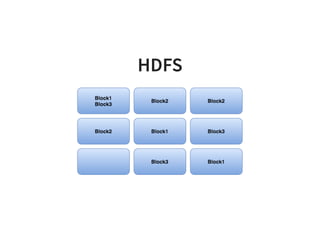
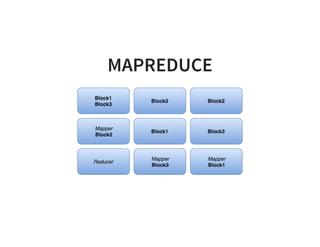
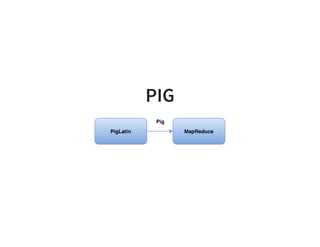
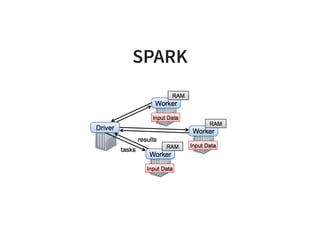
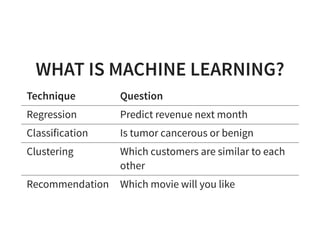
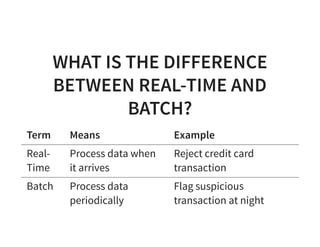
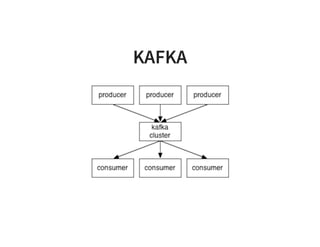
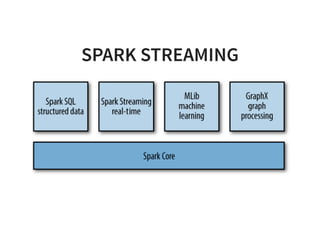
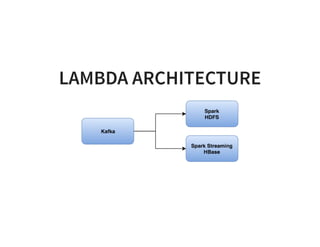
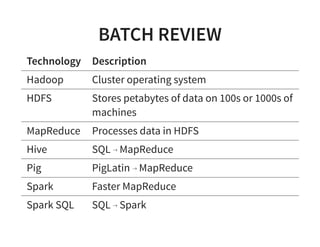
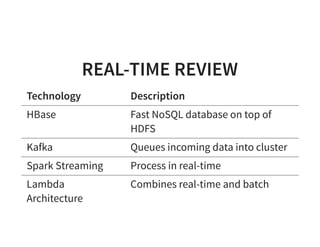
The document serves as a quick guide to data engineering, detailing various technologies such as Hadoop, HDFS, MapReduce, Hive, Pig, Spark, HBase, and Kafka. It explains how these tools facilitate data storage, processing, and real-time analytics, while addressing the challenges of handling large datasets. Additionally, it discusses the Lambda architecture, which integrates both real-time and batch processing to leverage historical and current data.