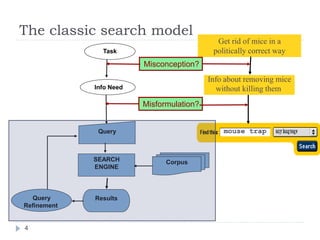
The document discusses Boolean retrieval models and indexing in information retrieval systems. It describes how a Boolean retrieval model views documents as sets of words and uses Boolean operators like AND, OR, and NOT to join query terms. An inverted index data structure is built on the text to speed up searches by storing, for each term, the documents that contain it. The document provides examples of how Boolean queries are processed by intersecting postings lists from the inverted index to retrieve matching documents in linear time. It also discusses some limitations of the Boolean model and advantages of ranking search results.






![Answers to query
Antony and Cleopatra, Act III, Scene ii
Agrippa [Aside to DOMITIUS ENOBARBUS]: Why, Enobarbus,
When Antony found Julius Caesar dead,
He cried almost to roaring; and he wept
When at Philippi he found Brutus slain.
Hamlet, Act III, Scene ii
Lord Polonius: I did enact Julius Caesar I was killed i' the
Capitol; Brutus killed me.
8
Sec. 1.1
Brutus AND Caesar but NOT Calpurnia](https://image.slidesharecdn.com/booleanirandindexing-230520190147-2c0d37b3/85/Boolean-IR-and-Indexing-pptx-8-320.jpg)









![A naïve dictionary
An array of struct:
char[20] int Postings *
Sec. 3.1
18](https://image.slidesharecdn.com/booleanirandindexing-230520190147-2c0d37b3/85/Boolean-IR-and-Indexing-pptx-18-320.jpg)











































































