Download to read offline















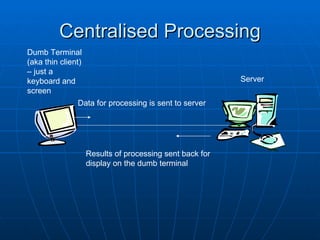
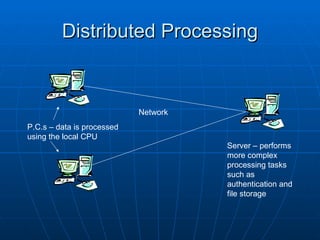
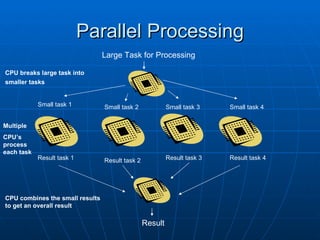



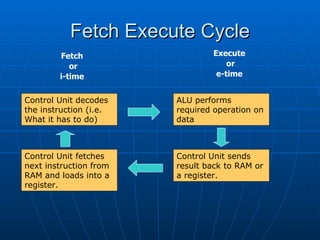



The document discusses information processes, focusing on storing and retrieving as well as processing. It examines how data is stored on different hardware media, both permanently using devices like hard disks, and temporarily in memory. It also discusses software tools for file management, databases, and data transfer. The document then covers different models of processing data, from centralized processing on servers to distributed and parallel processing using multiple CPUs. It describes how the central processing unit works through fetching and executing instructions in an ongoing cycle.





























































































