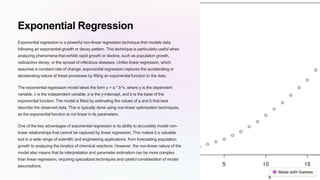
This document introduces several techniques for non-linear regression modeling that go beyond the limitations of traditional linear regression. It discusses polynomial regression, which uses higher-order polynomial functions to capture more complex relationships in data. Logistic regression is described as a technique for binary classification that uses a sigmoid function to estimate the probability of outcomes. Exponential regression uses an exponential function to model phenomena exhibiting rapid growth or decline. Gaussian processes characterize relationships as probability distributions to quantify prediction uncertainty, and kernel regression performs non-parametric function approximation through weighted local data points.