Download to read offline







![Column-Based Model
Unique Name Value
101 ProductName = "Book 101 Title"
ISBN = "111-1111111111"
Authors = [ "Author 1", "Author 2" ]
201 ProductName = "18-Bicycle 201"
Brand = "Brand-Company A"
Color = [ "Red", "Black" ]
ProductCategory = "Bike"
Examples: Cassandra, Hbase, Vertica](https://image.slidesharecdn.com/introductiontosqlonhadoop-151026132109-lva1-app6891/75/Introduction-to-Sql-on-Hadoop-10-2048.jpg)
![Key-Value Model
{
Id = 101
ProductName = "Book 101 Title"
ISBN = "111-1111111111"
Authors = [ "Author 1", "Author 2" ]
ProductCategory = "Book"
}
{
Id = 201
ProductName = "18-Bicycle 201"
Color = [ "Red", "Black" ]
ProductCategory = "Bike"
} Examples: Amazon DynamoDB, Hive, MemcacheDB,
Redis](https://image.slidesharecdn.com/introductiontosqlonhadoop-151026132109-lva1-app6891/75/Introduction-to-Sql-on-Hadoop-11-2048.jpg)






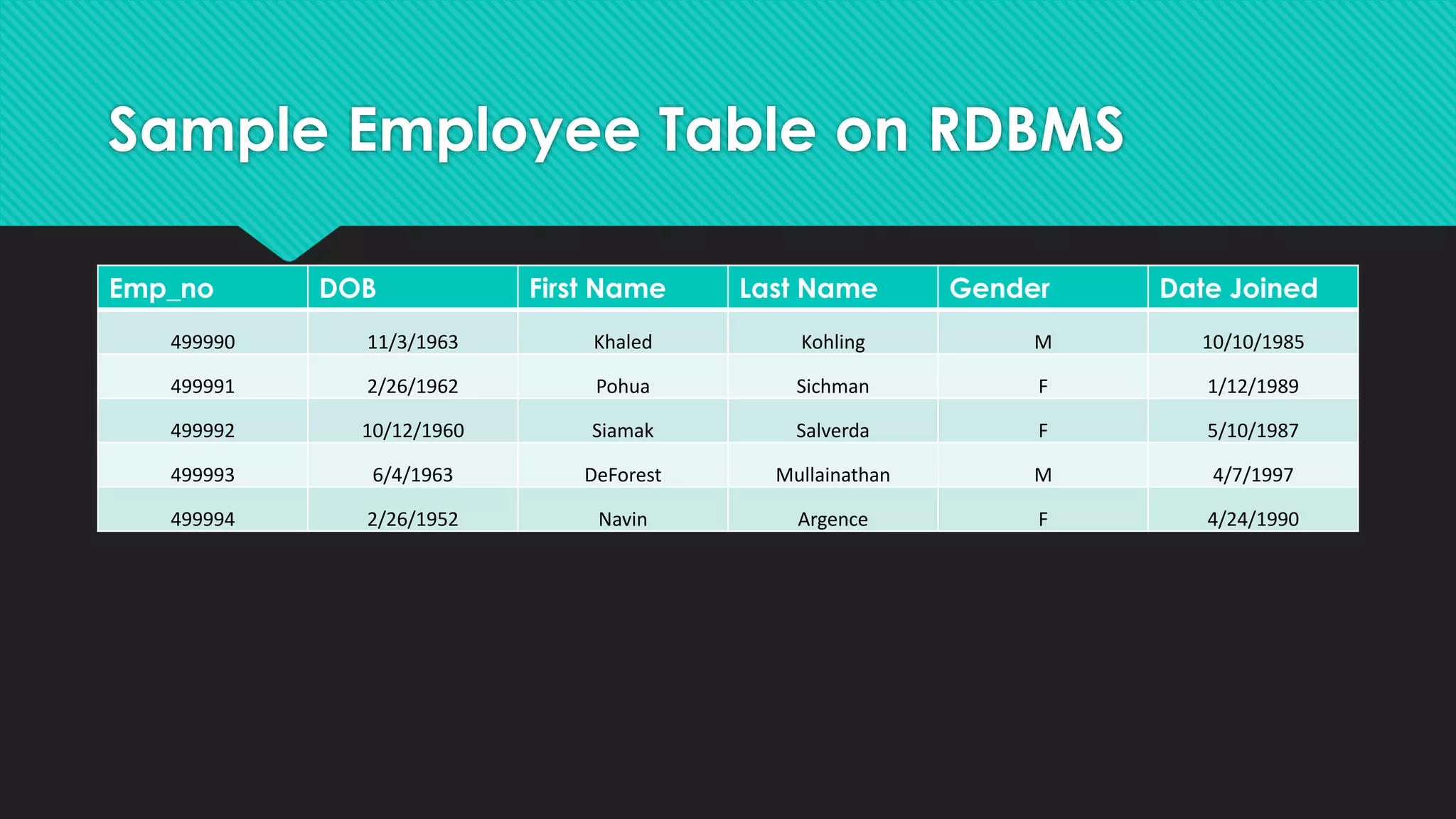
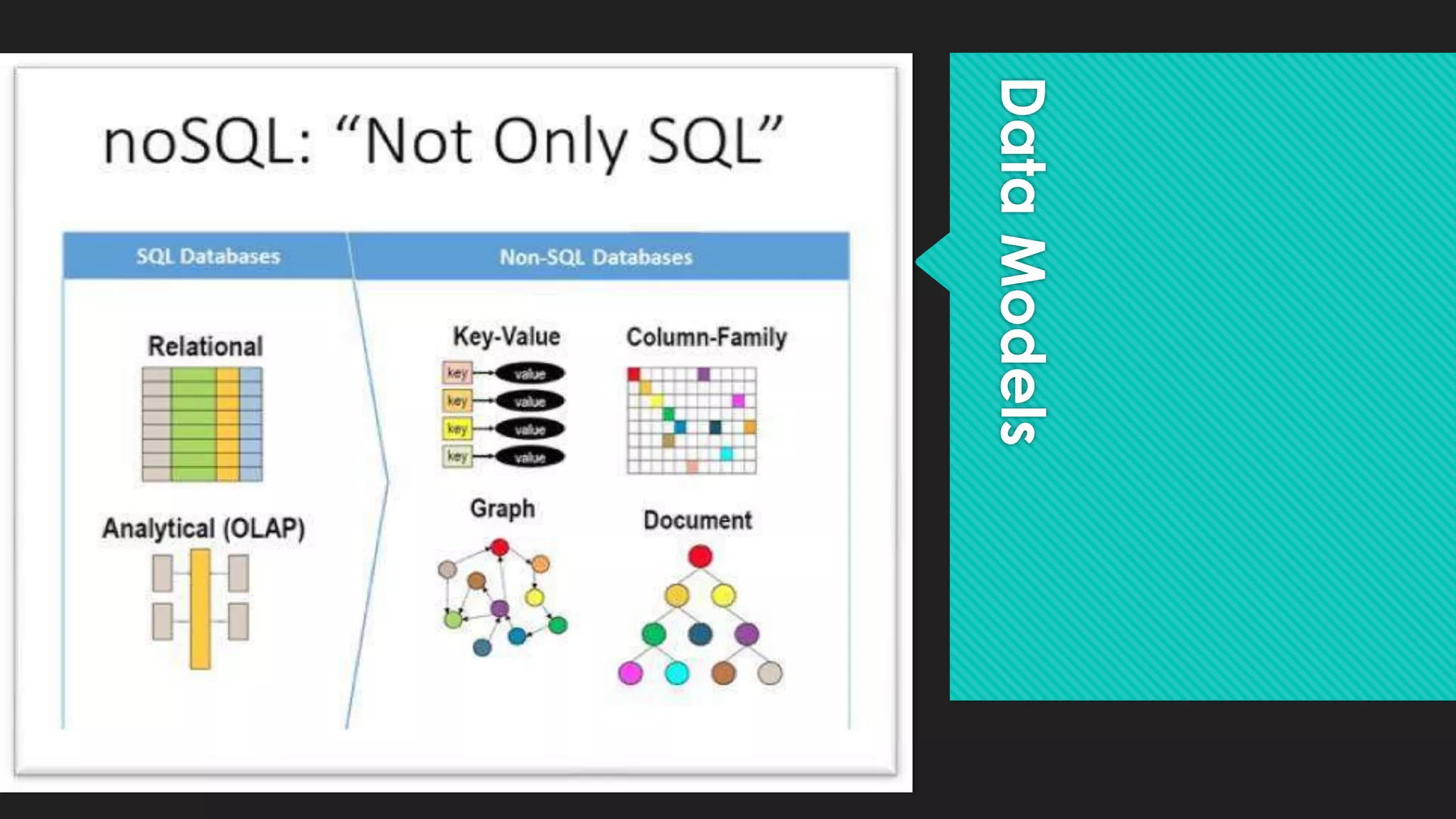
This document introduces SQL and relational databases, and describes how Hadoop addresses some of their limitations for large, unstructured data. It discusses using SQL-like languages like Pig and Hive on Hadoop to perform ETL and analytics. Different data models for NoSQL databases on Hadoop are also presented, including columnar, key-value, document and graph models. The document concludes with a demo of Pig and Hive on Shakespeare's works.





































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)













